







 本文详细介绍了如何在Eclipse环境中配置MapReduce开发环境,包括添加Hadoop插件,配置Hadoop集群连接,以及创建MapReduce工程。此外,还提供了词频统计实例,通过WordCount程序演示MapReduce的工作流程。
本文详细介绍了如何在Eclipse环境中配置MapReduce开发环境,包括添加Hadoop插件,配置Hadoop集群连接,以及创建MapReduce工程。此外,还提供了词频统计实例,通过WordCount程序演示MapReduce的工作流程。
1.实训目标
(1)掌握以Exlipse创建MapReduce工程
2.实训环境
(1)使用CentOS的Linux操作系统搭建的3个节点
(2)使用Eclipse软件作为编程软件
(3)使用插件hadoop-eclipse-plugin-2.x.x.jar
3.实训内容
(1)配置MapReduce环境
(2)新建MapReduce工程
4.实训步骤
4.1配置MapReduce环境
(1)添加Hadoop插件

找到eclipse的安装路径,然后将插件移动到这个路径下

(2)增加Map/Reduce功能区
打开eclipse进行以下操作
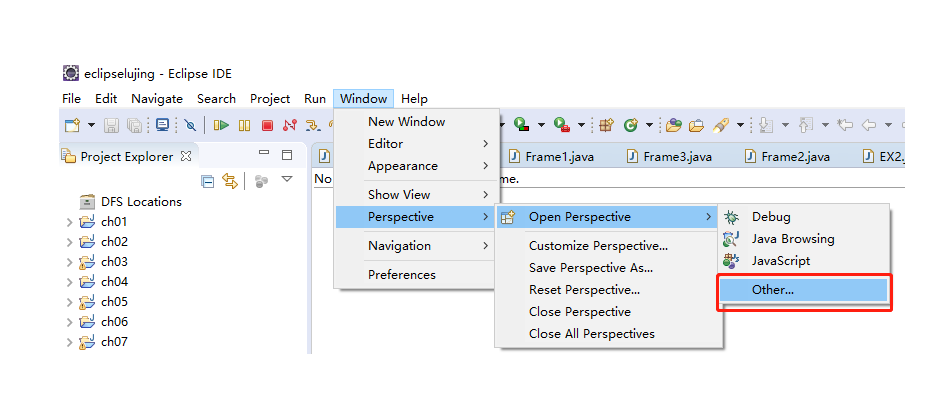
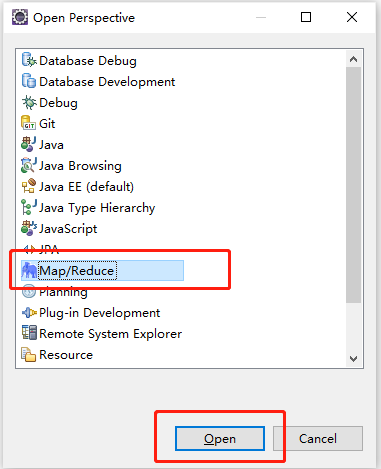
(3)增加Hadoop集群的连接
单击下图所示界面右下方的蓝色小象图标(其右上方右+号),就会弹出连接Hadoop集群的配置窗口。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 8650
8650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











