







 本文介绍了基于前端JavaScript和后端Java实现文件上传的方案。实现了文件分块上传、断点续传、请求队列和上传进度展示等功能,但未实现文件秒传、限制文件格式等。阐述了实现思路,包括文件分片、请求队列等代码解析,还给出了源代码地址和参考文献。
本文介绍了基于前端JavaScript和后端Java实现文件上传的方案。实现了文件分块上传、断点续传、请求队列和上传进度展示等功能,但未实现文件秒传、限制文件格式等。阐述了实现思路,包括文件分片、请求队列等代码解析,还给出了源代码地址和参考文献。
一、前言
文件上传是一个非常热的领域,与之对应的是文件下载,目前只实现了文件的上传,还未实现文件的下载,与上传相比,文件的下载更加复杂。
先简单说一下几个关于文件传输的名词:
- 文件分片(分块):将一个文件分割成许多小
分片,然后将这些小分片发送到服务器。文件分片的目的是将一个文件上传请求划分为多个请求,使用多线程上传文件,提高上传的效率。

- 断点续传:断点续传是在文件分片的基础上实现的。断点续传的作用是极大程度的避免了由于用户网络不稳定的问题,以及其他原因导致的文件上传的请求的中断,使得文件上传的失败,没有断点续传就需要重新上传,如果是一个 G 的文件的重新上传,这对于任何人来说都是无法忍受的。断点续传可以实现文件上传的暂停。

- 文件秒传:文件秒传是用户在上传一个文件时,如果在服务器上找得到相同的文件,就将这个文件的 uri 给到客户端,省去了上传的过程。文件上传的实现,在文件比较少时以及文件大小不大时比较可靠,因为它的实现需要比较大的算力,当文件特别大时,无论是在客户端还是服务端都是非常消耗算力资源的(因为要计算文件数据的 hash 值,hash 值一般是唯一的,难以重复)。

二、主要使用的编程语言
主要使用的编程语言:
-
前端:原生 JavaScript(发送请求使用的是 XMLHttpRequest,这里我对它进行了简单封装),使用了 Sass 简化 CSS 编写。
-
后端:使用 Java 开发,粗略使用了 SpringBoot(只是处理请求),使用了 Hutool 进行了 MD5 编码。
为什么使用 Java 开发后端?因为没学 node.js,不会…😅
三、实现结果
由于实现的结果可能与大家想象的不一样,所以这里先给大家说一下实现的结果如何。
上传页面展示(页面丑陋还请见谅😅):

已实现:
-
实现文件分块上传:根据指定的分块大小来上传文件,每个分块分别作为一个
单独的请求发送,服务器则会使用单独的线程接收。由于分块必然需要分块文件的合并,所以服务端需要实现文件的合并。 -
实现文件断点续传:基于文件分块,可以实现
上传的暂停,即中断正在上传的请求,服务器会保存已经上传的分块,可以记录这些分块的 hash 值,然后客户端下次上传时,服务器会告诉客户端还有哪些分块未上传(或者哪些分块已上传),客户端只要上传未上传的分块就可以了,不用从头开始上传。 -
实现请求队列:由于文件分片后会生成非常多的小分块,如果同时将这些分块发送到服务器,客户端和服务器都会承受巨大的压力。这里思想与“限流”类似,就是
限制请求。 -
实现上传进度展示:由于上传的是文件的分片,所以需要将进度以某种计算方式累加,进而计算总进度。由于请求可以被中断,所以有些进度的实现会出现
进度条的回退现象,比如哔哩哔哩投稿上传就有这个现象。 -
其他基本实现:分块上传的配套实现要求有:后端支持接收文件分片、分片合并。
未实现:
-
未实现文件秒传:这个没有实现是有原因的,开头介绍它时说过实现它需要计算上传的文件的 hash,然后在服务器上需要保存文件(不是分块的 hash)的 hash,服务器上如果有文件的 hash 值与上传的文件的 hash 值相同,直接返回文件的 URI 就可以了,让用户感觉上传了文件一样。但是计算 hash 时比较耗时的,就暂时放一放😋。
-
未限制上传的文件的格式:正常来讲需要服务端限制上传的文件格式,比如只能上传视频,就限制上传的文件格式只能是 mp4,或者其他视频格式。格式为 exe 的文件没有特殊要求是一定不能上传到服务器的,这种格式的文件危险性很高。
-
未实现多文件上传:多文件上传并没有考虑,感觉单文件能成功上传,多文件上传应该是类似的。只要为每个上传的文件设定一个唯一的 ID 防止冲突应该就行了。
-
未实现文件分片上传后的重试:当文件分片上传失败后,没有实现请求失败重新上传。这个如果要做的话,主要是前端的作业,请求失败报错,捕获错误后再创建一个请求加入请求队列应该就行了。
-
未实现根据网络状况调节分片大小:当用户网络状况良好时,可以将分片的大小设置的大一点,网络状况较差时可以将分片的大小设置小一点。
-
更多的想法:如果读者们有更多奇思妙想的想法,可以在评论区留言,或者是喜欢动手的朋友可以自己写一个类似的上传程序。
PS:下载文件就更加复杂了,我们平时看的直播,视频都是文件的下载,这个难度高,使用到的是流式传输,就是边下载边处理。要编写下载程序,那得了解一下 HTTP 协议提供的流式传输协议。
四、实现思路
下面给出文件上传的基本实现思路。
1、全局的思考
首先得有一个大局的判断,需要用到什么技术,需要实现哪些功能,然后再写代码,虽然我大多数情况下都不是这样的😂(纯靠感觉👍),因为从来没做过嘛,我一般都是百度,CSDN 找找,掘金上找找文章,站在巨人的肩膀上真的很妙哇~
文章最后给出了几篇我参考的文章。
既然做出来了就可以说一下要实现文件上传的基本步骤有哪些了:
-
确定你要实现的是大文件上传,还是小文件上传,像 20 M 以下都算比较小的文件,基本可以采用单个请求来发送整个文件,如果失败重试即可。
-
上传大文件由于用户网络的不确定性,我们需要考虑将文件进行
分片处理,另外发送多个请求使用到了多线程,能大大提高上传的效率。 -
使用到分片后,我们需要在服务端将这些
分片文件合并成一个完整的文件,由于我们不能保证分片上传的有序性,所以需要给每个分片设置一个唯一标识,这里可以使用分片的 hash 值作为分片的唯一标识。(我使用的是每个分片在文件中的索引,这个要方便一些,但安全性要更差,也验证不了文件的完整性) -
分片文件的上传就引出了一个新的问题(解决问题会产生问题😂),同时上传这些分片会导致客户端卡顿,也会消耗服务端的线程资源。如果文件非常大,上传时间非常长,会导致
浏览器卡顿甚至未响应,对服务端也会造成压力。所以我们需要创建一个请求队列,限制最大请求数量,达到最大的请求任务数量时,其他的任务等待正在执行的任务执行完毕。 -
由于大文件上传使用分片上传,每个分片的上传,我们都可以给它中断,所以这里就可以设置一个
暂停的功能,手动中断请求,清空请求队列。这时客户端和服务端都保存着上传记录。客户端点击开始上传,会从上次的上传位置继续上传。 -
当所有文件分片上传完成后,通知服务端
合并文件,或者在上传文件分片前告诉服务端有多少个分片,让服务端在所有分片上传之后自动合并文件。合并后删除所有分片文件。
大体的文件上传的思路就是上述这些,当然你可以增加更多的功能。
2、部分代码解析
源代码下载地址见文末。
下面只列出了我觉得比较重要的代码片段,其他的部分请查看源代码(源代码中给出了必要的解释,解释不好的地方还请见谅!)。
a. 将文件进行分片处理
文件分片使用 Blob.prototype.slice() 来处理,Blob 是 File 的父类(超类),可以直接调用 slice 方法,关于 Blob 的详情请查看 MDN —— Blob Web API。
我是使用文件分片在文件中的索引作为分片的唯一标识的。下图中的方块就是一个文件分块。其中的数字就是它的索引。使用 hash 值作为唯一索引,如果在客户端计算可以使用 spark-md5 来计算 hash,使用的是 MD5 算法。
下面的代码是将一个文件进行分片处理。
/**
* 将文件分片处理, 根据是否服务端给的分片索引, 以及取消上传的分片索引获取还未上传的分片索引
* @param file {File} 要分片的文件
* @param chunkIndex {[number]} 服务端给的已上传的分片索引数组
* @return {[{file: File, index: number}]} 返回对象数组, 对象中包括分片后的 Blob 以及该分片在文件中的位置, 也就是索引
*/
createChunk(file, chunkIndex) {
const chunkArr = [];
const size = file.size;
let start = 0;
// 分片的索引
let index = 0;
// cancelChunkIndex 是取消上传的分片的索引数组, 在暂停时取消的请求, 其代表的分片索引会存在其中, 下次重传
// 如果服务端有这个索引, 则将其过滤掉
chunkIndex = chunkIndex.filter((item) => !this.cancelChunkIndex.includes(item));
this.cancelChunkIndex = [];
while (start < size) {
// 如果分片已经上传, 则跳过
if (chunkIndex.includes(index)) {
start += chunkSize;
index++;
continue;
}
// chunkSize 是每个分片的大小, 以字节为单位, 我设置的是 1M, 1<<20 字节
let end = start + chunkSize;
// 添加分片
chunkArr.push({
file: file.slice(start, end),
index,
});
start = end;
index++;
}
return chunkArr;
}
b. 请求队列
请求队列限制请求的数量,任务排队执行,这个请求队列基于 Promise 和 递归 来实现,不使用循环判断,所以不影响主线程的执行。并且该任务队列具有一定的通用性,只要任务以函数形式传入,都能使用该队列。自个认为这个请求队列是有一定的参考价值的。
我画了一张图,不知道是否能解释的了请求队列的执行过程。
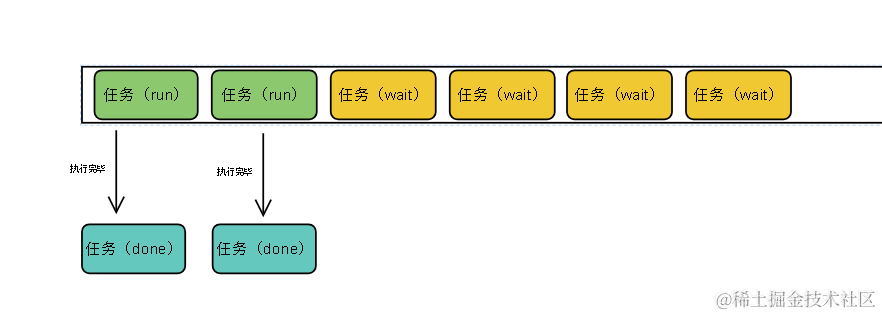
注意:在未使用闭包的前提下,在 Promise 的 then 方法中使用递归不会导致栈溢出(但会阻塞主线程)。
function ruc() {
new Promise((resolve) => {
resolve();
}).then(() => {
console.log("持续运行...");
// 未使用闭包, 不会造成栈溢出
// 因为之前的的函数已经从栈中移除, 而 then 的参数(函数)会在
// promise 完成后加入到浏览器的事件队列中执行。
// 作用域无嵌套, 如果使用了闭包我就不得而知了
ruc();
});
}
ruc();
稍微介绍了一下其他方面,请求队列的相关代码如下:
/**
* 任务队列, 实现单位时间内执行指定最大数量的任务的执行
* 即在正在执行的任务执行完成前, 其他的任务必须等待, 当然正在执行的任务的数量可以指定
*/
class TaskQueue {
/**
* 函数返回值
* @type {[*]}
*/
result;
/**
* 任务数组
* @type {[function]}
*/
taskList;
/**
* 用 Promise 包裹任务
* @type {[Promise]}
*/
taskPromiseArray;
/**
* 任务执行的索引
* @type {number}
*/
taskIndex;
/**
* 最大并发数
* @type {number}
*/
maximumConcurrency;
/**
* 是否运行结束, 这个属性的作用是防止多次执行运行结束回调
* @type {boolean}
*/
runOver;
/**
* 运行结束回调
* @type {function}
*/
runOverCallback;
constructor(maximumConcurrency = 2) {
this.maximumConcurrency = maximumConcurrency;
this.setRunOver(true);
this.initial();
}
/**
* 添加任务, 任务是函数形式
* @param task {function} 任务, 函数
*/
addTask(...task) {
this.taskList.push(...task);
}
/**
* 运行队列中的任务, 运行结束后重置执行队列
* @param args 每个任务要执行时需要的参数, 可变参数
*/
run(...args) {
this.setRunOver(false);
let maximumConcurrency = Math.min(this.maximumConcurrency, this.taskList.length);
for (let index = 0; index < maximumConcurrency; index++) {
this.executeSingleTask(args);
}
}
/**
* 每个请求结束后都会判断是否执行结束
* @param args 每个任务要执行时需要的参数, 可变参数
*/
judgeExecuteEnd(args) {
let taskList = this.taskList;
let taskPromiseArray = this.taskPromiseArray;
// 当所有的任务都得到执行, 但部分任务还没有执行完毕
// 这里 !this.getRunOver() 可以替换为 this.taskList.length === 0
// 这是由于执行了 initial()
if (this.taskIndex >= taskList.length && !this.getRunOver()) {
this.setRunOver(true);
let result = this.getResult();
// 等待所有的任务执行完毕后执行回调
Promise.all(taskPromiseArray).then(() => {
this.runOverCallback && this.runOverCallback(result);
});
this.initial();
return;
}
// 如果还有任务则继续执行
this.executeSingleTask(args);
}
/**
* 执行一个任务
* @param args 每个任务要执行时需要的参数, 可变参数
*/
executeSingleTask(args) {
let taskList = this.taskList;
let taskPromiseArray = this.taskPromiseArray;
let promise = new Promise((resolve, reject) => {
// 执行任务并将返回值保存
this.result.push(taskList[this.taskIndex++](resolve, reject, ...args));
}).then(() => {
this.judgeExecuteEnd(args);
}).catch(() => {
this.initial();
});
taskPromiseArray.push(promise);
}
getResult() {
return this.result;
}
/**
* 设置任务执行完成回调
* @param callback 回调函数
*/
setRunOverCallback(callback) {
this.runOverCallback = callback;
}
getRunOver() {
return this.runOver;
}
setRunOver(runOver) {
this.runOver = runOver;
}
initial() {
this.result = [];
this.taskList = [];
this.taskPromiseArray = [];
this.taskIndex = 0;
}
}
c. 简单封装 XMLHttpRequest
封装 XMLHttpRequest 主要是为了减少重复代码的编写, 这里简单对其进行了封装,这个封装代码考虑到的地方还是不充分的。如果要发送请求,可以使用 alova(号称取代 axios),或者使用 axios。
/**
* 请求封装
*/
request({url, method = "get", params, data, progressHandler, abortHandler}) {
return new Promise((resolve, reject) => {
let xh = new XMLHttpRequest();
let paramArr = [];
// 收集 params
for (let key in params) {
if (Object.prototype.hasOwnProperty.call(params, key)) {
paramArr.push(`${key}=${params[key]}`);
}
}
if (paramArr.length !== 0) {
url += `?${paramArr.join("&")}`;
}
xh.open(method, url);
// 收集 data
let formData = new FormData();
for (let key in data) {
if (Object.prototype.hasOwnProperty.call(data, key)) {
formData.append(key, data[key]);
}
}
// 上传完成
xh.onload = (e) => {
resolve(JSON.parse(xh.responseText));
};
// 产生错误
xh.onerror = (e) => {
reject(e);
};
// 请求监控
xh.upload.onprogress = (e) => {
progressHandler && progressHandler(e);
};
// 中断请求
xh.onabort = (e) => {
reject(e);
};
// 请求终止处理
abortHandler && abortHandler(() => {
xh.abort();
});
// cookie 跨域
xh.withCredentials = true;
xh.send(formData);
});
}
d. 上传文件分片
基于上述实现,现在我们可以实现具有基本功能的文件上传了。
我将文件的上传分为了三个阶段(这里参考了哔哩哔哩的投稿上传),分别设置了上传前,上传中,上传完成三个请求阶段:
-
上传前:这个阶段主要对文件进行
预解析,服务端根据文件的大小设置每个分片的大小(当然网络也是要考虑的方面),然后服务端会给这个文件定下一个唯一的标识,客户端上传时携带这个唯一标识就能确定客户端上传的是哪个文件了。 -
上传中:这个阶段主要任务是上传每个分片,这时可以
监控每个分片的上传进度,通过下面的 uploadFile() 中的某种计算方法,可以监控文件上传的总进度,保存之前的上传进度,可以避免出现进度条的回退。这个阶段中断请求即可实现上传的暂停,取消上传与暂停类似,只是页面变化了,并通知服务端这个文件应该删除。 -
上传完成:这个阶段所有的分片都已经上传完毕,客户端这时携带必要的参数并发送一个文件合并的请求,服务端就会开始进行文件的合并,合并完成通知客户端上传成功。客户端可以继续上传他文件。
主要的代码如下所示:
/**
* 上传前, 预热
* @param file {File} 要上传的文件
*/
preUpload(file) {
this.request({
url: PRE_UPLOAD_URL,
params: {
filename: file.name,
size: file.size,
},
}).then((response) => {
// filename 是服务端给文件的标识, size 是一个分片的大小(字节), chunkIndex 是已经上传的分片索引数组
let {filename, size, chunkIndex} = response.data;
this.filename = filename;
chunkSize = size;
this.uploadFile(file, chunkIndex);
}).catch((error) => {
console.log(error);
});
}
/**
* 上传文件, 实现断点续传, 可暂停
* @param file {File} 要上传的文件
* @param chunkIndex {[number]} 服务器给的未上传的分片索引
*/
uploadFile(file, chunkIndex) {
let chunkArr = this.createChunk(file, chunkIndex);
this.changeDragBoard(UPLOADING);
let filename = this.filename;
let itemArr = new Array(chunkArr.length);
let chunkArrLength = chunkArr.length;
let requestArray = this.requestArray;
chunkArr.forEach((item, index) => {
// 添加任务
this.taskQueue.addTask((resolve, reject) => {
let size = item.file.size;
let chunkIndex = item.index;
let requestItem;
this.request({
url: UPLOAD_URL,
method: "post",
params: {
index: chunkIndex,
name: filename,
size,
},
data: {
file: chunkArr[index].file,
},
progressHandler: (e) => {
// 每个分片的上传进度
itemArr[index] = e.loaded / e.total * 100;
// 分片进度之和 (可能大于 100, 正常)
let sum = itemArr.reduce((pre, cur) => pre + cur, 0);
// 计算总进度, 如果之前暂停过, preProgress 不为 0, sum / chunkArrLength 会达到百分之一百
// 如果暂停过, 需要计算未上传的部分的进度, 这就是 remainProgressPercent 的作用
// remainProgressPercent 指的是未上传的部分与所有文件的占比(小数形式)
// preProgress 是之前上传的百分比
let progress = (sum / chunkArrLength * this.remainProgressPercent) + this.preProgress;
this.progress = progress;
this.setProgress(progress);
},
abortHandler(abort) {
requestItem = {abort, index: chunkIndex};
requestArray.push(requestItem);
}
}).then(() => {
resolve();
// 请求完成后删除请求数组中的对象
requestArray.splice(requestArray.indexOf(requestItem), 1);
}).catch(() => {
// 请求中断
reject();
});
});
});
// 添加上传完成回调
this.taskQueue.setRunOverCallback(() => {
this.doms.uploadProgressContainer.classList.add(WAIT_MERGE);
this.uploaded(filename);
});
this.taskQueue.run();
}
/**
* 上传完成, 请求服务器合并分片
*/
uploaded() {
let filename = this.filename;
this.request({
url: UPLOADED_URL,
params: {
name: filename
}
}).then(() => {
this.changeDragBoard(UPLOADED);
this.reset();
}).catch((error) => {
console.log(error);
});
}
e. 暂停和继续上传
由于这个部分是基于分片上传的,暂停就是中断一下请求,清空其他请求,相对来说比较简单。不过需要记录一下被中断的请求,下次上传时需要重新请求。这里就不附上源码了,简单说一下实现原理。
/**
* 实现暂停主要是借助 XMLHttpRequest 提供的 abort() 方法,在请求未完成发送前
* 将其中断,这时会触发中断回调,需要监听,中断后清空请求队列, 停止发送请求。
*/
let xh = new XMLHttpRequest();
xh.onabort = () => {};
...
xh.abort();
/**
* 实现开始上传与刚开始上传时是一样的,还是进行了那三个上传阶段,只是在
* preUpload 时服务端会告诉客户端哪些分片已经上传了,客户端只需要上传未上
* 传的分片即可。这里我是使用分片的索引确定其唯一性,当然你可以使用 hash。
* 这三个阶段层层递进,上一个阶段结束才会执行下一个阶段。
*/
preload();
uploadFile();
uploaded();
d. 服务端处理
这里我用的服务端语言是 Java,可能有人是没学过的,但会用 node.js,这个会的话那也好办,前端可以参考一下本文章,你可以做你喜欢的修改,增加你想要的功能。服务端也没什么晦涩难懂的代码,就是简单接受了请求,处理一下文件,合并完成将分片删除即可(上传出错或者浏览器刷新需要重启服务器,因为客户端刷新后之前的上传记录会消失,服务端却保存着,会出错)。
这里粗略说一下用 Java 写服务端(源代码可以在文章末尾找到)。
这里我使用了 SpringBoot 来处理请求,主要是图方便(因为真的很方便)。
下面是进行文件分片上传的代码:
/**
* 存在的问题:可能会抛出 java.io.EOFException,表示读取到文件的末尾,当客户端
* 中断请求时可能会发生,这个错误是 SpringBoot 内嵌的 Tomcat 抛出的,
* 局部异常捕获器并不能捕获,全局的捕获器修改这个类的内部变量又比较麻烦,
* 所以中断的请求对应的分片索引在服务端会存在,所以需要客户端记录一下
*/
@PostMapping("/upload")
public Result<?> upload(@RequestParam("file") MultipartFile file, Integer index, Integer size, String name) throws IOException {
Result<?> result = this.checkFilename(name);
if (!result.success()) {
return Result.error();
}
// 判断当前索引对应的分片是否存在
if (this.fileHash[index] != null) {
return Result.error();
}
// 以索引作为分片名, 如索引为 1 则文件名为 1
File chunk = new File(this.dir, index + "");
chunk.createNewFile();
// 获取该分片的文件 hash, 分片的 hash 可以做文件秒传
String md5 = SecureUtil.md5(chunk);
fileHash[index] = md5;
file.transferTo(chunk);
return Result.ok(null);
}
下面是合并文件分片的代码:
/**
* 文件合并是将多个文件合并成一个文件。
* 这里我使用了 RandomAccessFile 随机读写,通过 seek() 设置其文件指针
* 文件上传几乎是模版式的代码,这里就不解释了
*/
@GetMapping("/uploaded")
public Result<?> uploaded(String name) throws IOException {
Result<?> result = this.checkFilename(name);
if (!result.success()) {
return Result.error();
}
File[] files = this.dir.listFiles();
RandomAccessFile writeFile = new RandomAccessFile(new File("B:/" + this.resultFileName + this.suffix), "rw");
RandomAccessFile readFile;
byte[] bytes = new byte[this.bufferLength];
for (File file : files) {
int pos = this.CHUNK_SIZE * Integer.parseInt(file.getName());
writeFile.seek(pos);
readFile = new RandomAccessFile(file, "r");
while (readFile.read(bytes) != -1) {
writeFile.write(bytes);
}
readFile.close();
}
writeFile.close();
for (File file : files) {
file.delete();
}
this.reset();
return Result.ok(null);
}
五、项目讨论
由于个人考虑不周,如果有地方实现的让客官您不满意,比如如果有代码冗余,设计不好的地方,请在评论区留言~~~
1、文件秒传
文件秒传是需要耗费挺大的算力的,并且比较麻烦,需要保存之前的上传过的记录。服务端我并没有使用 Mysql,或者 Redis 等数据库,自己用 java.util.Map 实现存储就比较繁琐。就暂时不考虑了。通俗来讲就是懒~
2、未设置文件 URI
还有一个地方就是上传文件后,如何访问这个文件。服务端我并没有设置文件的访问路径,所以客户端上传了文件时无法通过 URI 访问到的。
3、其他
客户端页面设计的不是很好看,主要考虑到的是功能实现,所以就随便做了一个简单的上传页面。
六、源代码地址
下面给出了几个可以下载源代码的地址:
七、参考文献
参考的主要文章如下所示:
字节跳动面试官:请你实现一个大文件上传和断点续传 - 掘金 (juejin.cn)
【JavaScript】文件分片上传_js分片上传_等时钟成长的博客-CSDN博客
字节跳动面试官,我也实现了大文件上传和断点续传 - 掘金 (juejin.cn)
此外还查阅了其他的文章,属于细枝末节,就不列出来了。
八、有话说
代码中如果有什么瑕疵让客官您不满意,可以在评论中留言。另外本人水平不高,表达能力较差,代码中如果有 bug,有什么地方没有解释明白还请谅解~。
感谢您的浏览!!!

















 2511
2511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









