






一. 实验目的
(1)掌握虚拟机内Hadoop的安装方法;
(2)掌握Hadoop单机模式的使用;
(3)掌握Hadoop伪分布式安装方法;
(4)熟悉Hadoop的常用操作。
二. 实验内容
在完成以下基础生态配置后:
1)VMware和Linux操作系统(Ubuntu)安装
2)实现文件互传和文字复制粘贴
3)普通用户 hadoop创建(验证:id hadoop)、APT更新、vim下载
4)ssh安装和免密登录
验证:ssh localhost
5)Java环境安装
验证:java -version
实践以下内容
(一)安装Hadoop
(二)Hadoop3.3.5配置与运行——基于单机配置(非分布式)
(三)Hadoop3.3.5配置与运行——基于伪分布式配置
(四)熟悉常用的Hadoop操作(选做,教材P44页)
三. 实验主要步骤(主要操作过程截图)
前期铺垫:查看第一次实验内容
(1) VMware和Linux操作系统(Ubuntu)安装
(2) 实现文件互传和文字复制粘贴
(3) 普通用户 hadoop创建(验证:id hadoop)、APT更新、vim下载
(4) ssh安装和免密登录
(5) 验证:ssh localhost
(6) Java环境安装
(7) 验证:java -version
1. 安装hadoop3.3.5
(1) 下载hadoop-3.3.5.tar.gz
(2) 解压hadoop:sudo tar -zxvf ~/Downloads/hadoop-3.3.5.tar.gz -C/usr/local
(3) 切换到/usr/local目录,查看hadoop-3.3.5目录是否存在:cd /usr/local,再ls查看

(4) 将解压好的hadoop-3.3.5目录重命名为hadoop:sudo mv ./hadoop-3.3.5/ ./hadoop
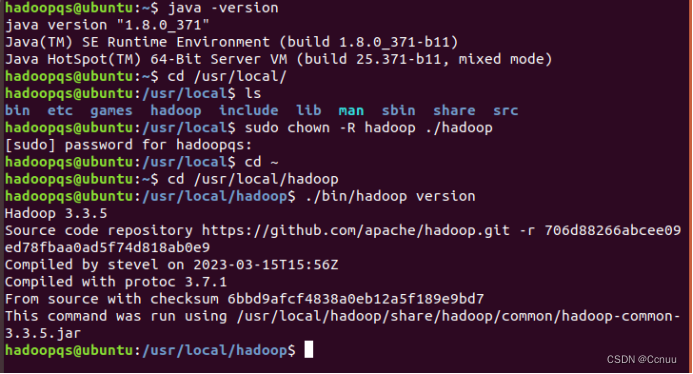
(5) 更改./hadoop目录的所有者为hadoop用户:sudo chown -R hadoop ./hadoop
(6) 切换到hadoop目录

(7) 查看hadoop版本,这个命令通常在Hadoop的安装目录下的bin子目录中执行:./bin/hadoop version
2. Hadoop3.3.5 配置与运行---- 基于单机配置(非分布式)
(1) cd /usr/local/hadoop

(2) 创建input目录:mkdir ./input

(3) 将.etc/hadoop/目录下所有扩展名为.xml的文件,即hadoop配置文件,复制到当前目录下的./input文件中作为输入文件:cp ./etc/hadoop/*.xml ./input
(4) 运行hadoop mapreduce程序:./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar grep ./input ./output 'dfs[a-z.]+'
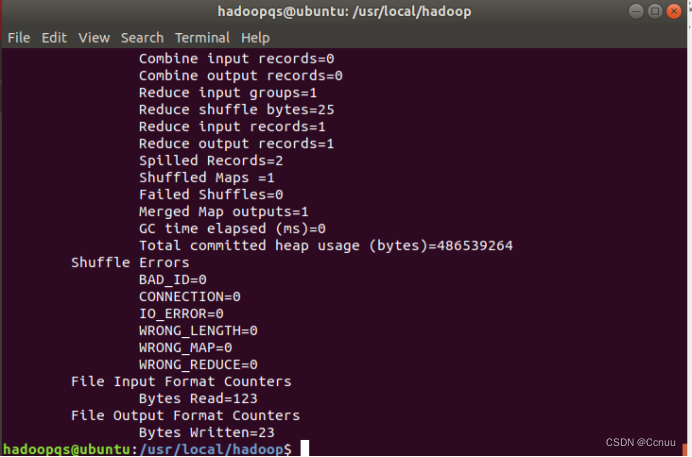
(5) 查看输出结果:cat ./output/*

3. Hadoop3.3.5配置与运行---基于伪分布配置
(1) 修改配置文件:伪分布式需要修改的core-site.xml和hdfs-site.xml:
cd /usr/local/hadoop
再接着分别依次输入命令打开修改配置文件:gedit ./etc/hadoop/core-site.xml、gedit ./etc/hadoop/hdfs-site.xml
core-site.xml中将
<configuration>
</configuration>
替换为
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration> 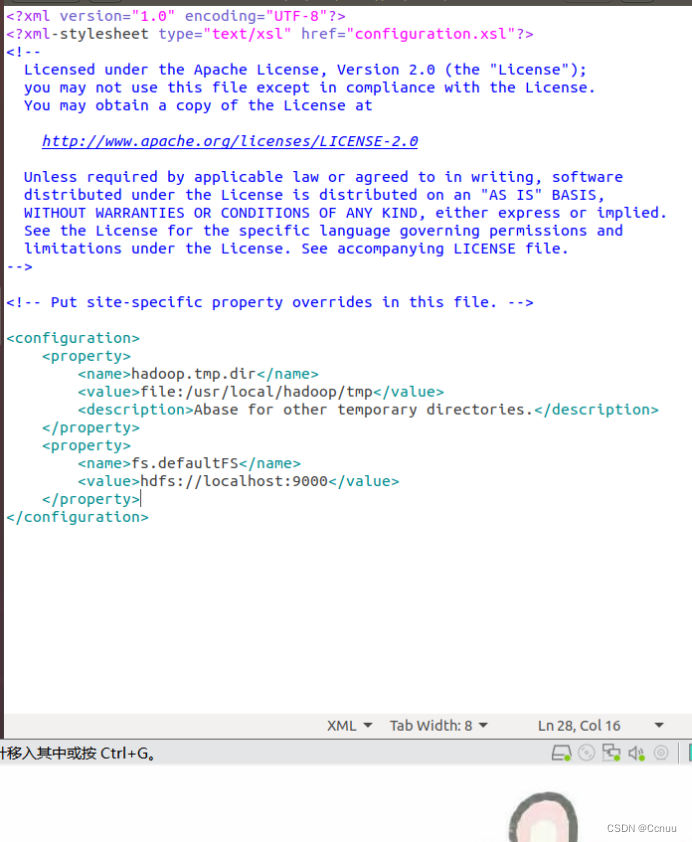
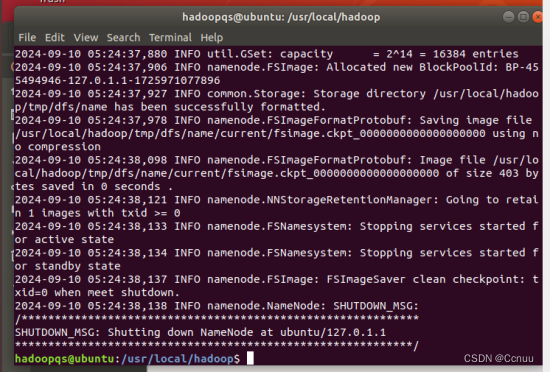
(2) 执行namenode的格式化:cd /usr/local/hadoop,./bin/hdfs namenode-format
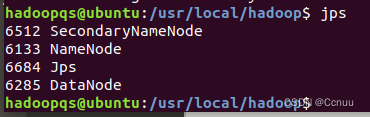
(3) 启动HDFS,开启NameNode和DataNodes守护进程:cd /usr/local/hadoop,启动HDFS:./sbin/start-dfs.sh

启动完成后,输入jps判断是否成功启动
(4) 运行hadoop伪分布式实例
① 创建HDFS上的目录:./bin/hdfs dfs -mkdir -p /user/hadoop,./bin/hdfs dfs -mkdir input

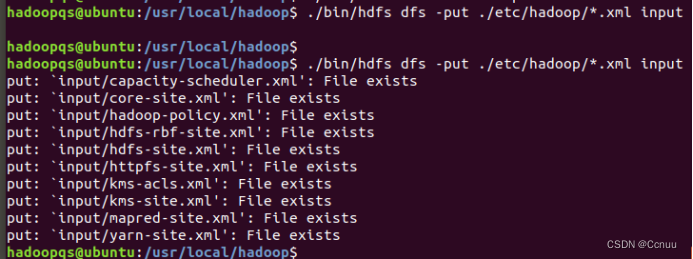
② 将本地hadoop配置文件上传到HDFS的input目录:./bin/hdfs dfs -put ./etc/hadoop/*.xml input
③ 查看HDFS上的input目录内容:./bin/hdfs dfs -ls input
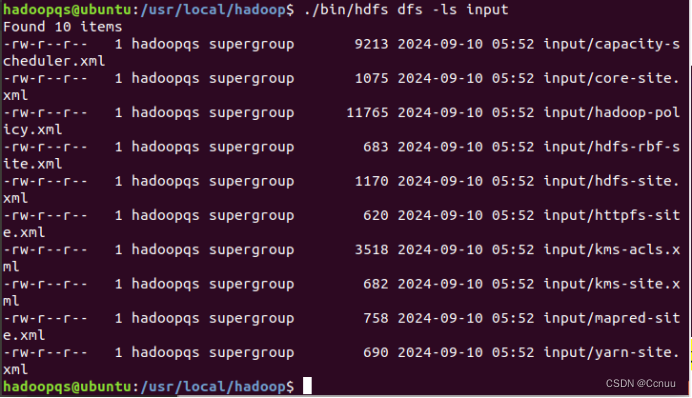
④ 运行Hadoop MapReduce示例程序:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop
-mapreduce-examples-3.3.5.jar grep input output 'dfs[a-z.]+' 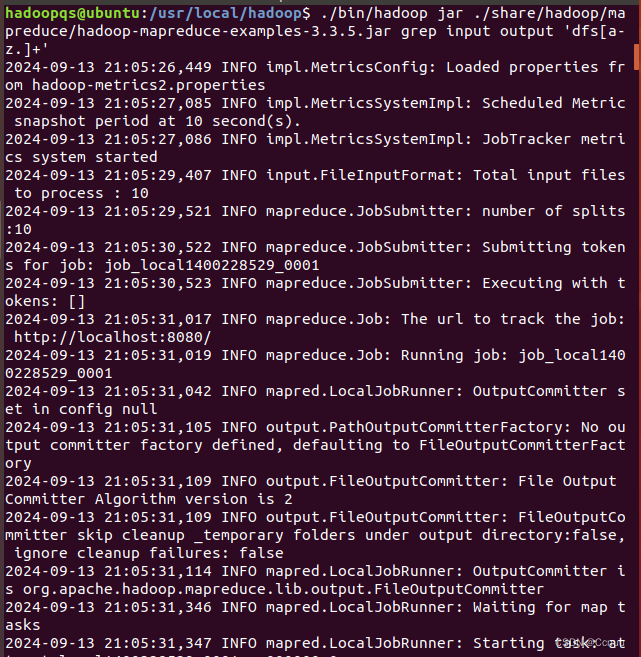
⑤ 查看HDFS上的输出结果:./bin/hdfs dfs -cat output/*

⑥ 删除本地output目录:rm -r ./output

(已删除)
⑦ 将HDFS上的output目录内容下载到本地output目录:./bin/hdfs dfs -get output ./output
⑧ 查看你本地output目录内容:cat ./output/*

⑨ 停止HDFS:./sbin/stop-dfs.sh

(5)
关闭与重启hadoop:./sbin/stop-dfs.sh;./sbin/start-dfs.sh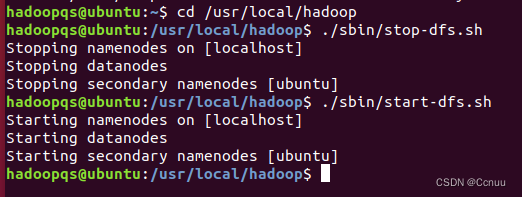















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









