






一、awk 简介
awk 是一个功能强大的文本处理工具,在 Linux 及 Unix 环境中堪称最强大的数据处理引擎之一 。其名称源于它的创始人阿尔佛雷德・艾侯(Alfred Aho)、彼得・温伯格(Peter Weinberger)和布莱恩・柯林汉(Brian Kernighan)姓氏的首个字母。如今,默认在 Linux 系统下日常使用的是 gawk,可通过ls -l /bin/awk命令查看正在应用的 awk 的来源。
awk 提供了丰富且强大的功能,涵盖样式装入、流控制、数学运算符、进程控制语句,甚至还拥有内置的变量和函数,具备一个完整语言所应有的几乎所有精美特性 。实际上,awk 拥有自己的程序设计语言,被正式定义为 “样式扫描和处理语言” 。它允许用户创建简短的程序,这些程序能够读取输入文件、对数据排序、处理数据、对输入执行计算以及生成报表等,功能十分丰富。简单来说,awk 是一种用于处理文本的编程语言工具 。
二、awk 基本用法
(一)模糊查询
awk 可以轻松实现模糊查询,比如我们有一个存储学生成绩的文件score.txt,想要搜索名字中含有zhang和li的学生成绩,可使用如下命令:
awk '/搜索字符/' score.txt
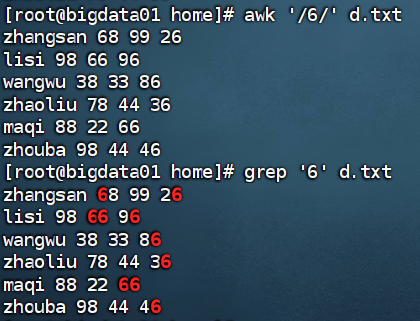
这里的搜索字符可以是zhang或者li等,该命令会在score.txt文件中模糊匹配包含指定字符的行。例如,若文件中有张三、张三三、李四等名字,当搜索zhang时,包含张三、张三三的行就会被匹配出来;搜索li时,包含李四的行将被匹配。
(二)指定分隔符与字段获取
- 指定分隔符并按下标显示内容:
在处理文本数据时,常常需要根据特定的分隔符来分割数据行,并获取其中的某些字段。awk 通过-F选项来指定分隔符。例如,对于文件1.txt,若想根据逗号(, )分割,并打印第一段、第二段和第三段内容,命令如下:
awk -F ',' '{print $1,$2, $3}' 1.txt

这里的-F ','表示使用逗号作为字段分隔符,$1、$2、$3分别代表分割后的第一段、第二段和第三段内容。
- 常用选项及含义:
-
- -F ',':英文为field - separator,作用是使用指定字符(这里是逗号)分割数据行。
-
- $ + 数字:用于获取第几段内容,如$1获取第一段,$2获取第二段,以此类推。
-
- $0:获取当前行的完整内容。
-
- NF:英文为field,表示当前行共有多少个字段。例如,若某行数据按指定分隔符分割后有 5 个字段,那么NF的值就是 5。
-
- $NF:代表当前行的最后一个字段。假设某行有 4 个字段,$NF就等同于$4。
-
- $(NF - 1):代表倒数第二个字段。若某行有 4 个字段,$(NF - 1)就等同于$3。
-
- NR:代表处理的是第几行。比如处理到第 3 行时,NR的值就是 3。
例如,要打印4.txt中每个学生的姓名以及前两门的成绩,假设文件中数据是以空格分隔,命令如下:
awk -F ' ' '{OFS="==="}{print $2, $3}' 1.txt
此命令中,-F ' '指定以空格为分隔符,OFS="==="表示向外输出时,使用===作为段分割字符串,print $2, $3表示打印分割后的第二段(姓名)和第三段(第一门成绩)以及第四段(第二门成绩)内容 。
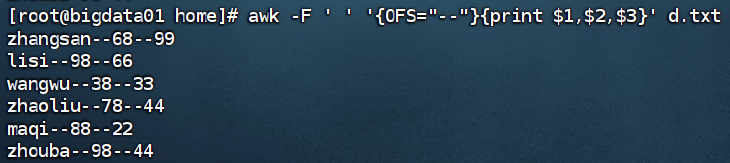
awk -F ' ' '{print '内容',$2, $3}' 1.txt
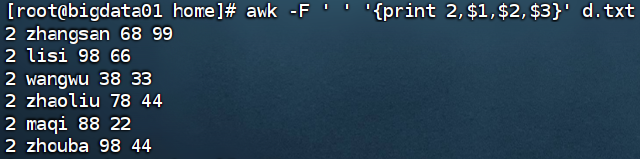
在每行前面加提示内容:
(三)awk 中使用函数
awk 提供了一些实用的函数来处理数据。例如,若要将1.txt文件中某一列的数据变为大写,可使用toupper()函数,命令如下:
awk -F ',' '{print toupper($2)}' 1.txt
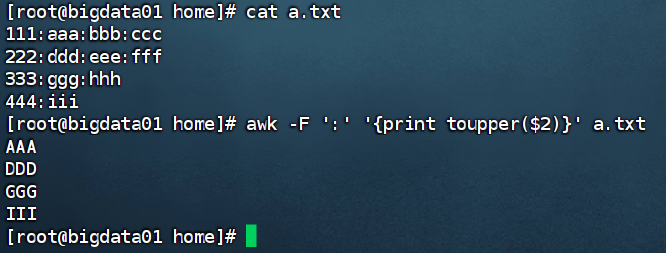
这里-F ','指定逗号为分隔符,toupper($2)将分割后的第二段内容转换为大写并打印。
常用函数如下:
| 函数名 | 含义 | 作用 |
| toupper() | upper | 将字符转成大写 |
| tolower() | lower | 将字符转成小写 |
| length() | length | 返回字符长度 |
三、awk 实战
(一)条件判断
awk 中可以添加条件判断语句,从而根据不同的条件执行不同的操作。例如,假设有一个成绩文件,要打印出成绩大于 80 分的学生信息,假设文件格式为姓名 成绩,以空格分隔,命令如下:
awk -F ' ' '$2>80{print $0}' score.txt
这里-F ' '指定空格为分隔符,$2>80是条件判断,表示当第二个字段(成绩)大于 80 时,执行print $0操作,即打印当前行的所有内容。

cat d.txt | awk -F ' ' '{if($4>60) print $1,$4}'

cat d.txt | awk -F ' ' '{if($4>60) print $1,$4,"及格";else print $1,$4,"不及 格"}'
 (二)BEGIN 和 END 语句
(二)BEGIN 和 END 语句
awk 中的BEGIN和END语句用于在处理文件前后执行特定的操作。其语法格式为:
awk 'BEGIN{初始化操作}{每行都执行} END{结束时操作}' 文件名
其中,BEGIN{ 这里面放的是执行前的语句 },在读取文件内容之前执行,只执行一次;{这里面放的是处理每一行时要执行的语句},每读取一行数据,就执行一次;END {这里面放的是处理完所有的行后要执行的语句 },在处理完所有行数据之后执行,也只执行一次 。
求最后一列成绩的总分:
假设有一个成绩文件4.txt,数据格式为姓名 成绩1 成绩2 成绩3,以空格分隔,要计算最后一列成绩的总分,命令如下:
cat 4.txt | awk -F ' ' 'BEGIN{print "开始计算成绩总和"}{total=total+$4}END{print total}'
这里BEGIN部分打印提示信息 “开始计算成绩总和”;中间部分{total=total+$4},每读取一行,将该行的第四列成绩累加到total变量中;END部分打印最终计算得到的总分。

获取记录条数:
同样对于4.txt文件,若要在计算总分的同时获取记录条数,命令如下:
cat 4.txt | awk -F ' ' 'BEGIN{print "开始计算成绩总和"}{total=total+$4}END{print total,NR}'
这里NR是 awk 的内置变量,表示当前处理的行号,在END部分打印总分的同时,也打印NR,即文件的总行数。

获取平均分:
计算4.txt文件中最后一列成绩的平均分,命令如下:
cat 4.txt | awk -F ' ' 'BEGIN{print "开始计算成绩总和"}{total=total+$4}END{print total,NR,(total/NR)}'
在前面计算总分和记录条数的基础上,通过(total/NR)计算并打印出平均分。

又如:
awk -F ' ' 'BEGIN{print "开始计算最后一个学科的总成绩"}{total=total+$4;print NR}END{print total/NR}' 4.txt
BEGIN部分打印开始提示信息;中间部分每读取一行,将当前行第四列成绩累加到total,并打印当前行号NR;END部分计算并打印最后一个学科成绩的平均分。

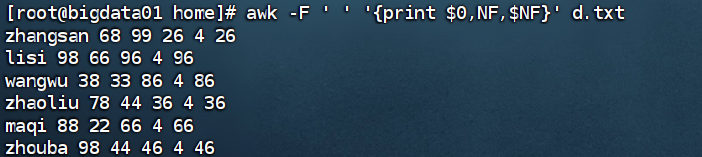
在处理过程中,$0表示当前行的内容,NF表示当前行有多少个字段,$NF表示当前行的最后一个字段 。例如:
awk -F ' ' '{print $0,NF,$NF}' 4.txt
该命令会逐行打印4.txt文件中每行的全部内容、字段个数以及最后一个字段的内容。
通过上述对 awk 命令的详细介绍,希望能帮助大家更好地掌握这个强大的文本处理工具,在日常的文本处理和数据处理任务中更加得心应手。无论是简单的数据提取,还是复杂的数据统计分析,awk 都能发挥出巨大的作用 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









