






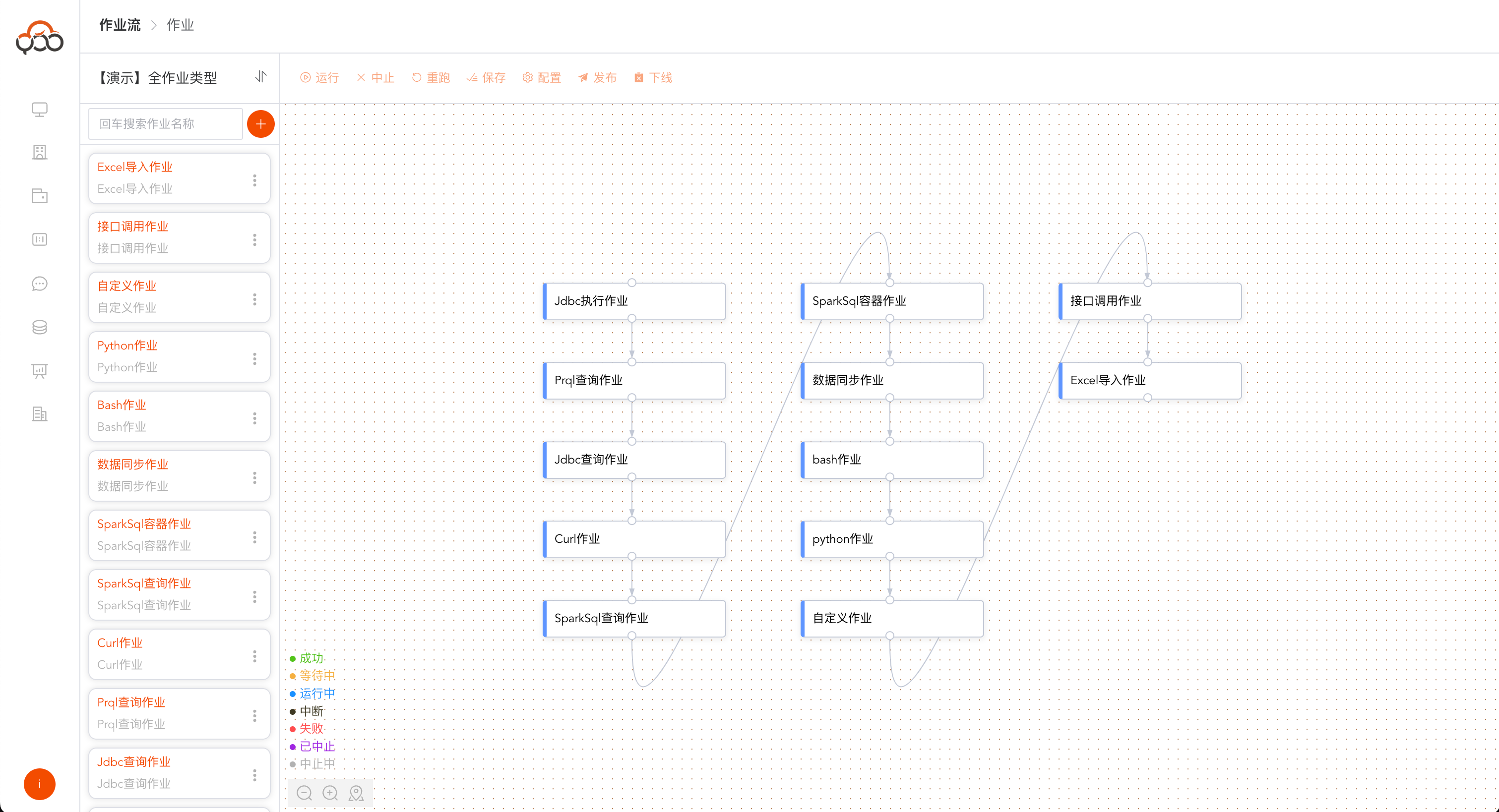
作业流类型
查看作业列表
点击
作业流的名称,进入作业编辑列表
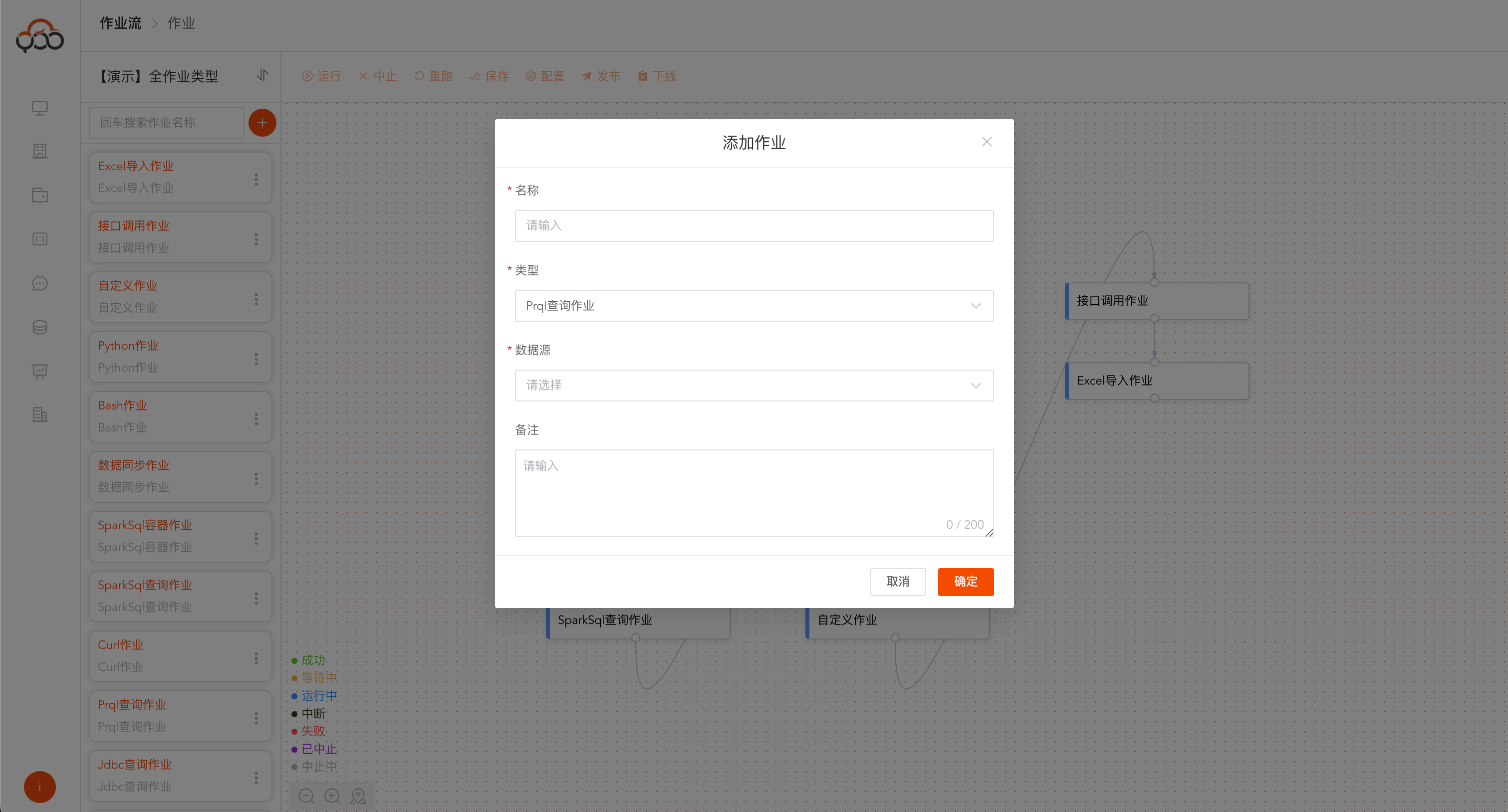
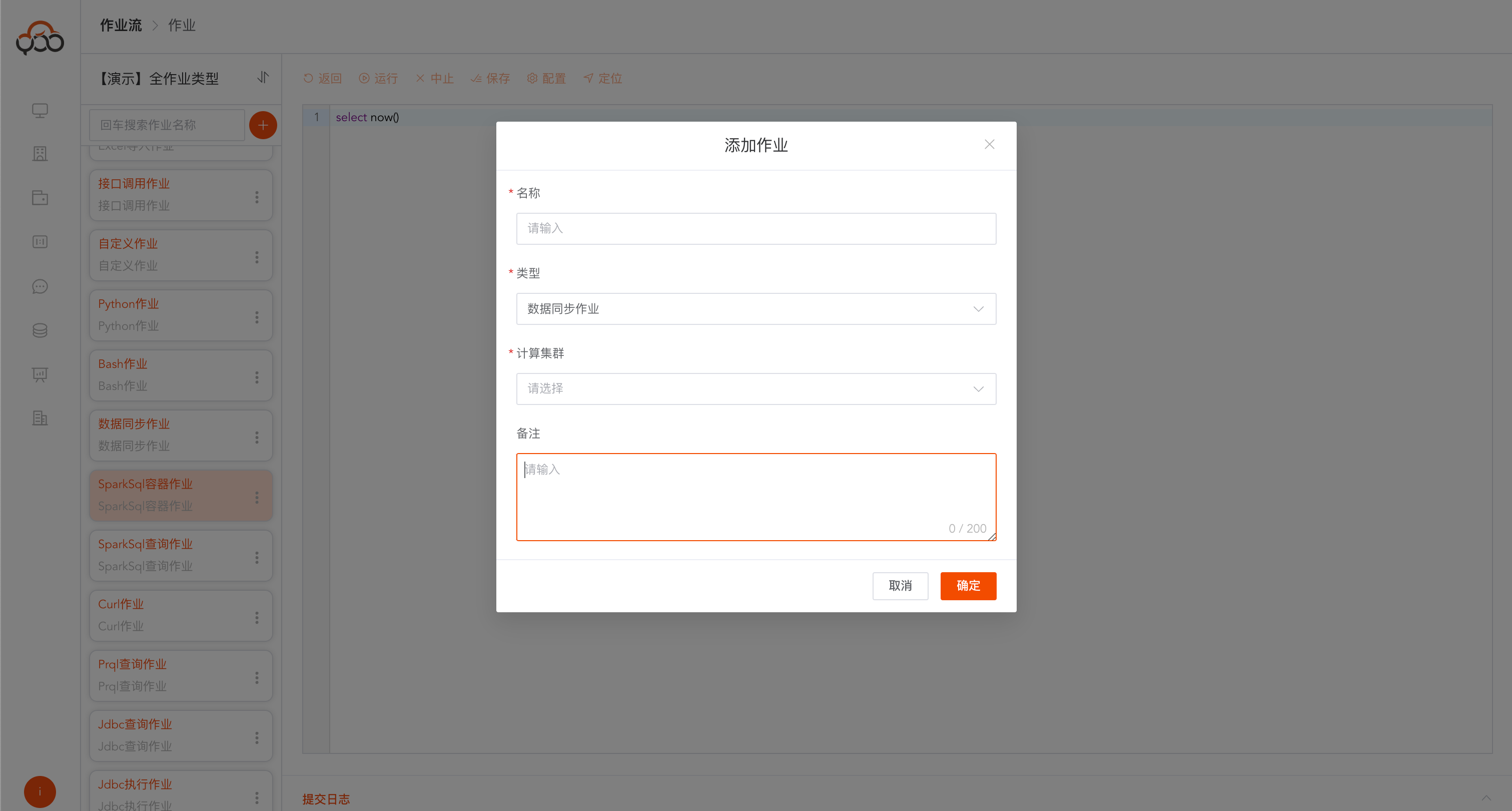
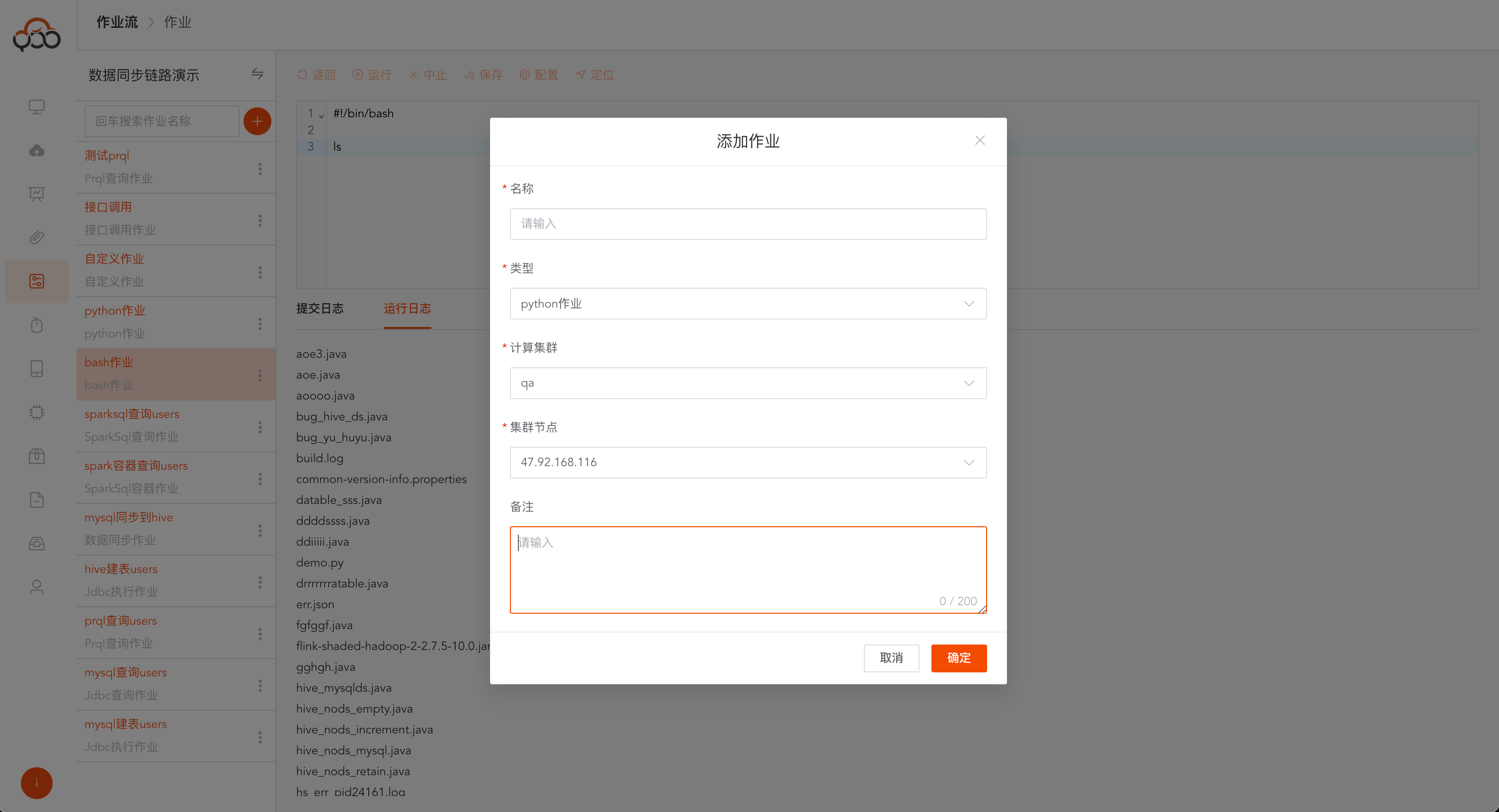
新建作业
点击
圆框加号创建新作业
作业名称在作业流中唯一
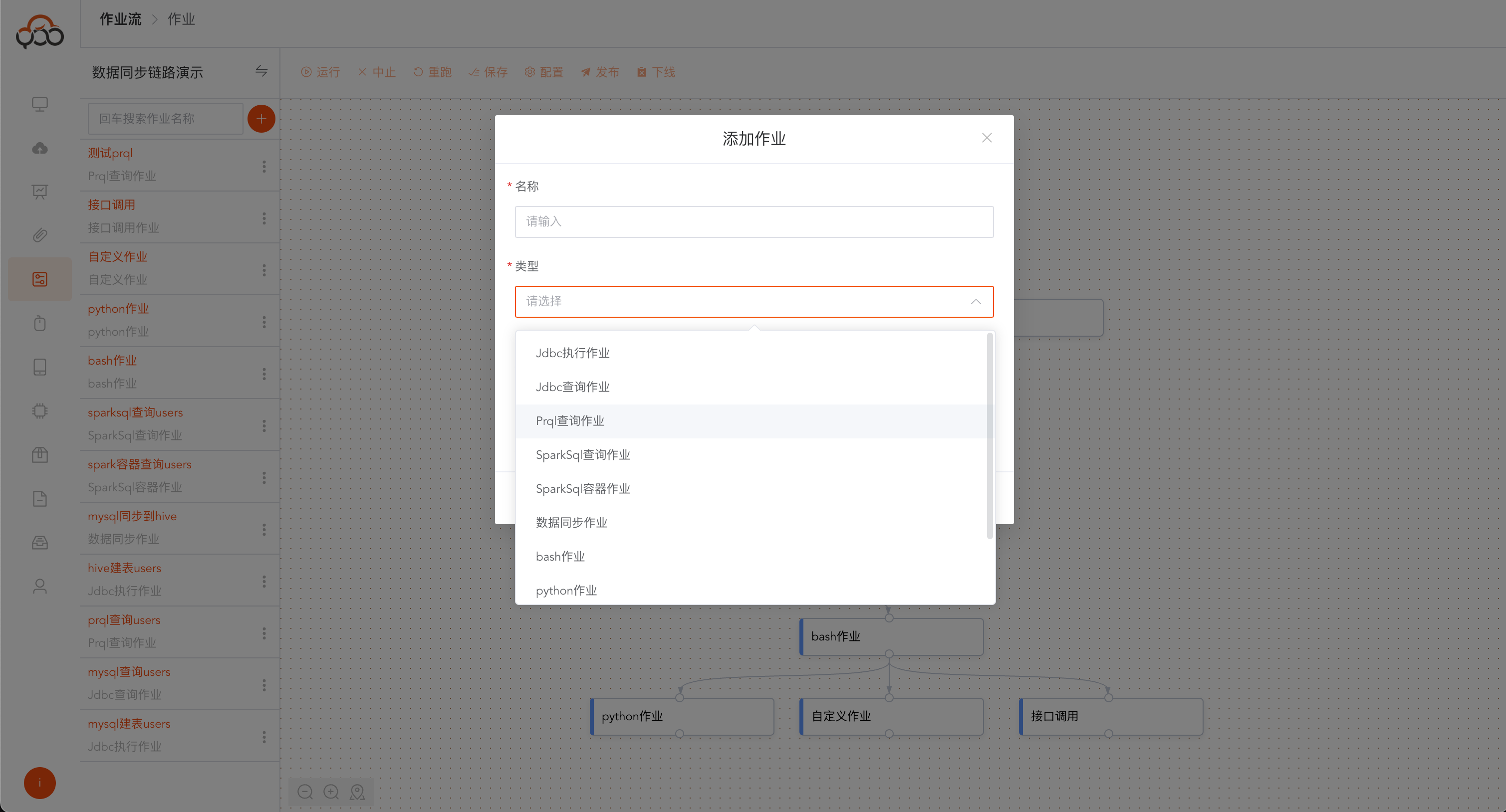
作业类型包括:
- Jdbc执行作业: 选择数据源,执行sql返回
提交日志 - Jdbc查询作业: 选择数据源,执行sql返回
提交日志、数据返回 - Prql查询作业: 选择数据源,执行prql返回
提交日志、运行结果,prql网址:https://prql-lang.org/ - SparkSql查询作业: 选择计算集群,执行sparksql返回
提交日志、运行结果、运行日志 - SparkSql容器作业: 选择计算容器,执行sparksql返回
提交日志、运行结果 - 数据同步作业: 选择计算集群,实现将A表数据同步到B表中
- bash作业: 选择计算集群中的一个节点,执行bash脚本
- python作业: 选择计算集群中的一个节点,执行python脚本
- 自定义作业: 选择计算集群,提交
资源中心的作业类型的jar文件,执行用户自定义的jar包 - 接口调用作业: 可视化界面,让用户调用
POST和GET接口 - Excel导入作业: 选择计算集群,提交
资源中心的Excel类型的文件,同步到执行的表中
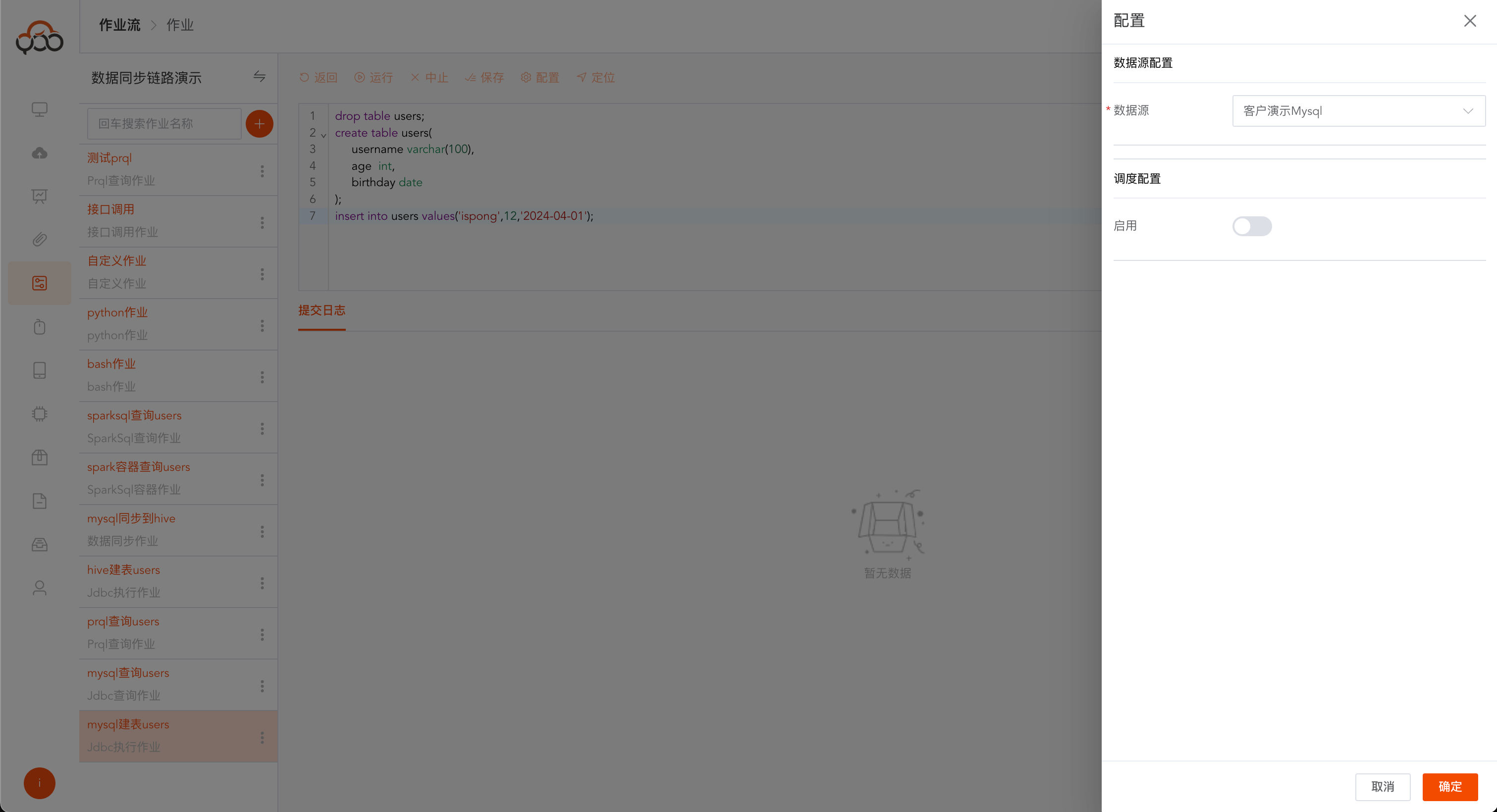
Jdbc执行作业
选择jdbc执行作业类型
- 名称: 必填,作业流内名称唯一
- 类型: 必填,数据源的类型
- 数据源: 必填,选择执行sql的数据源
- 备注: 非必填
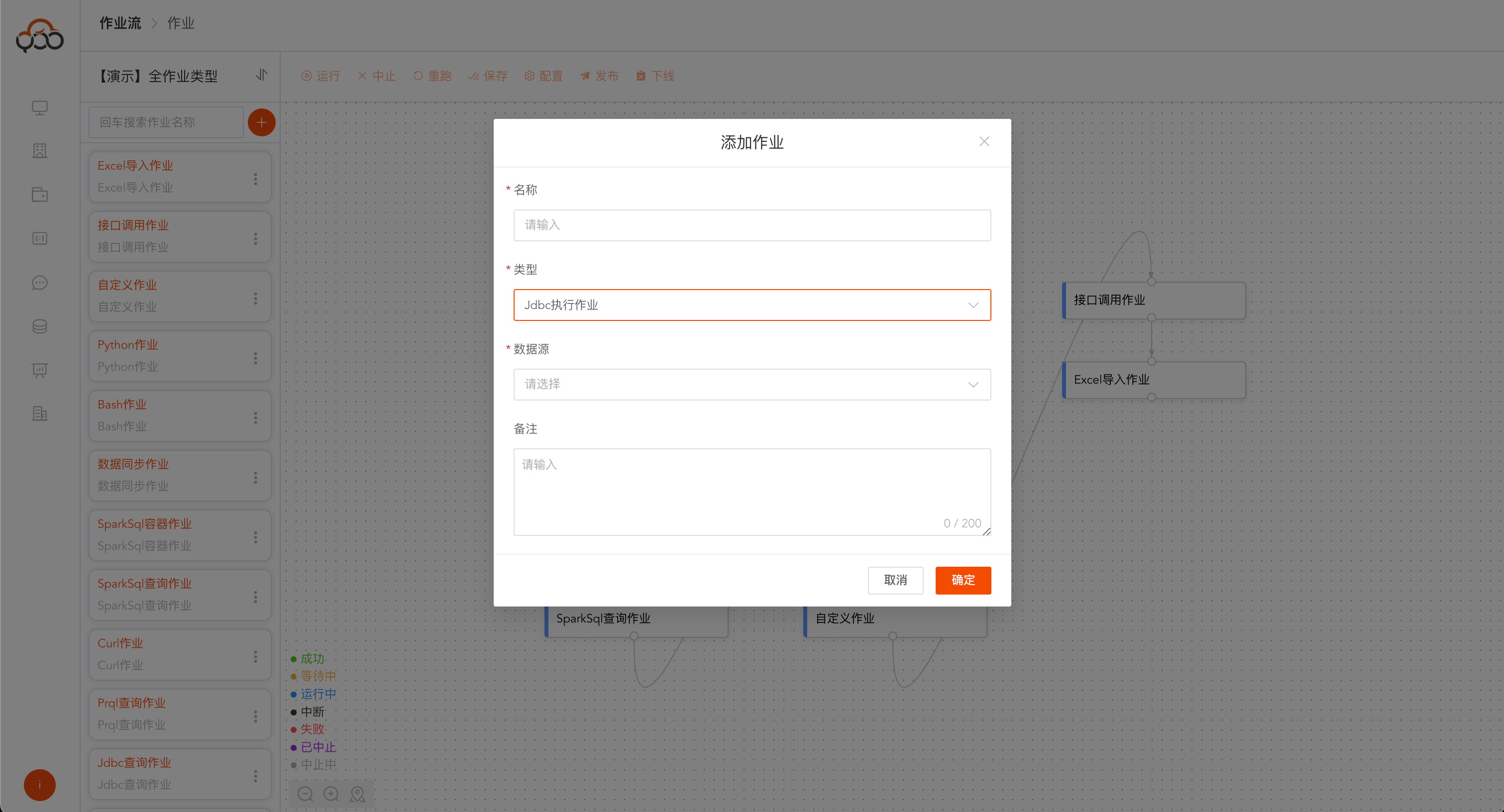
作业配置,支持数据源切换
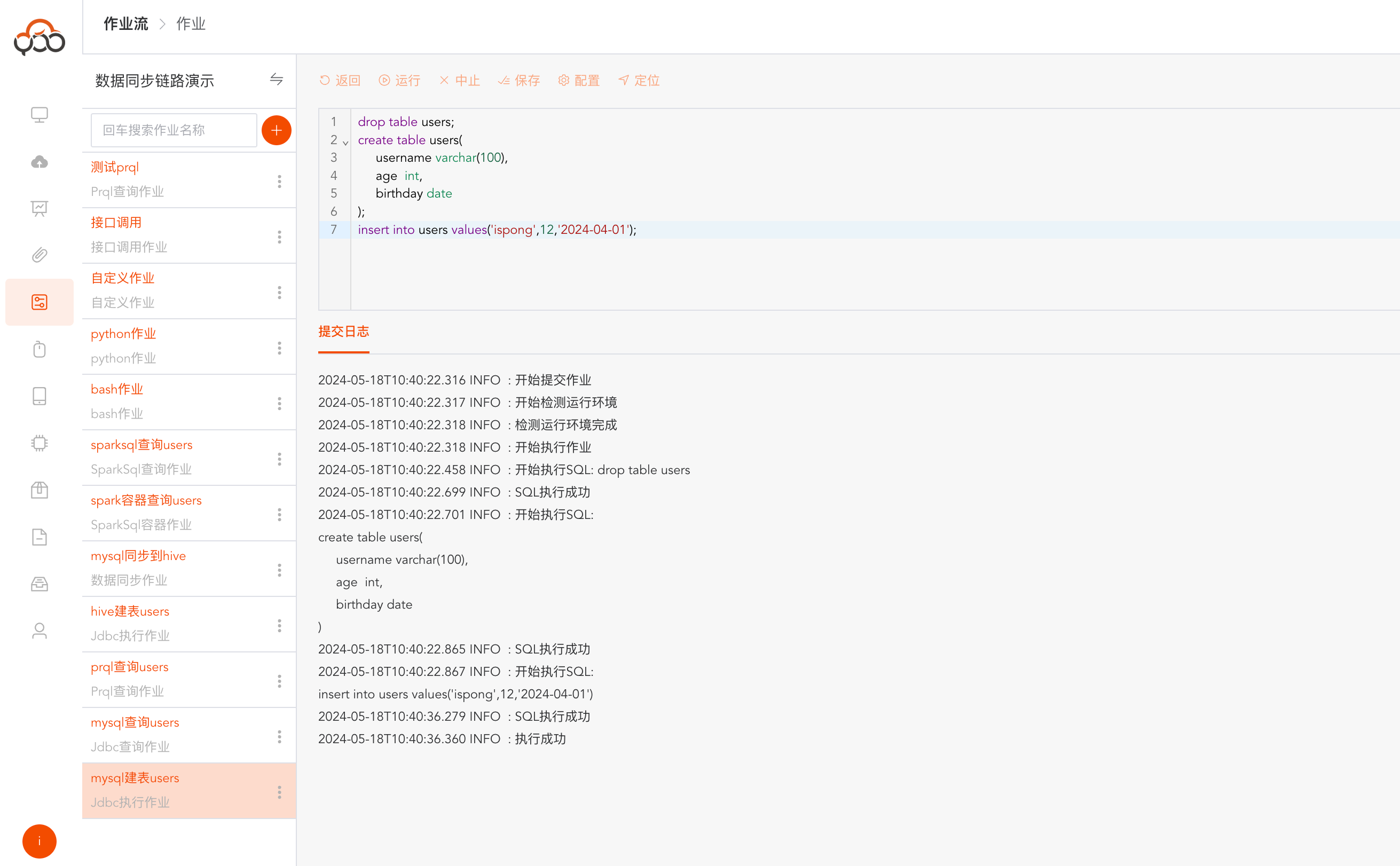
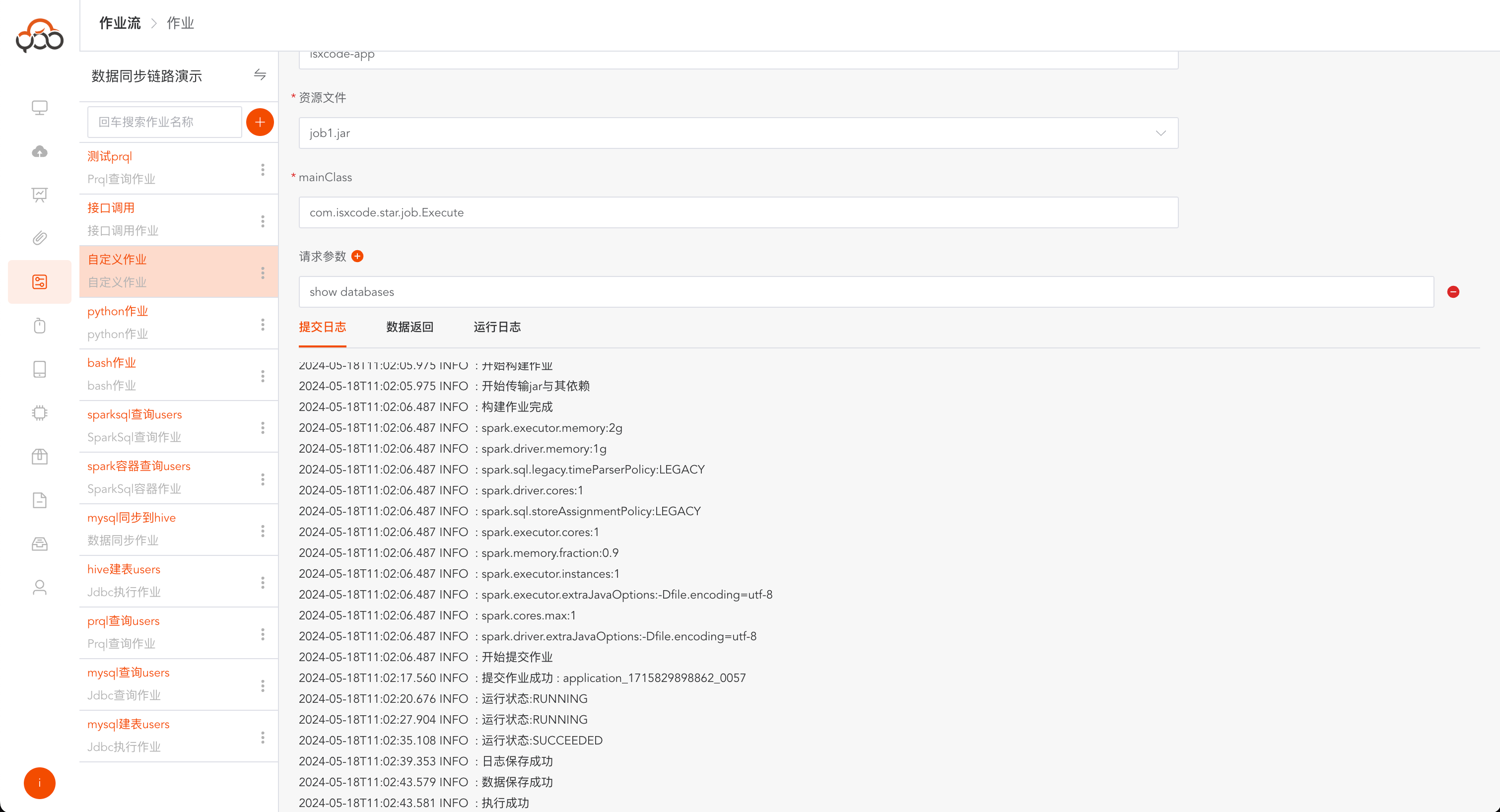
点击运行,在日志中可以得到sql执行语句和每条sql的运行状态
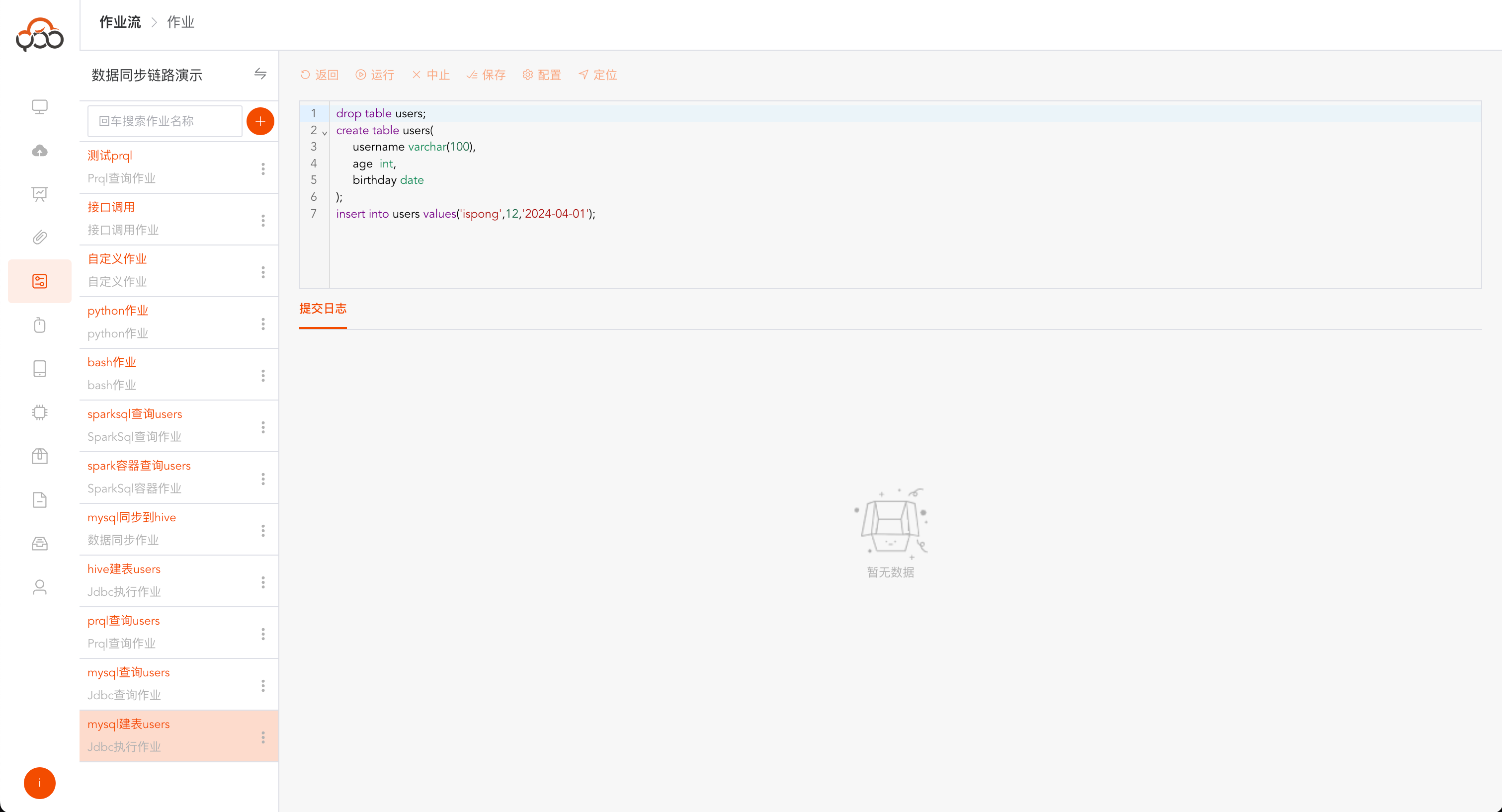
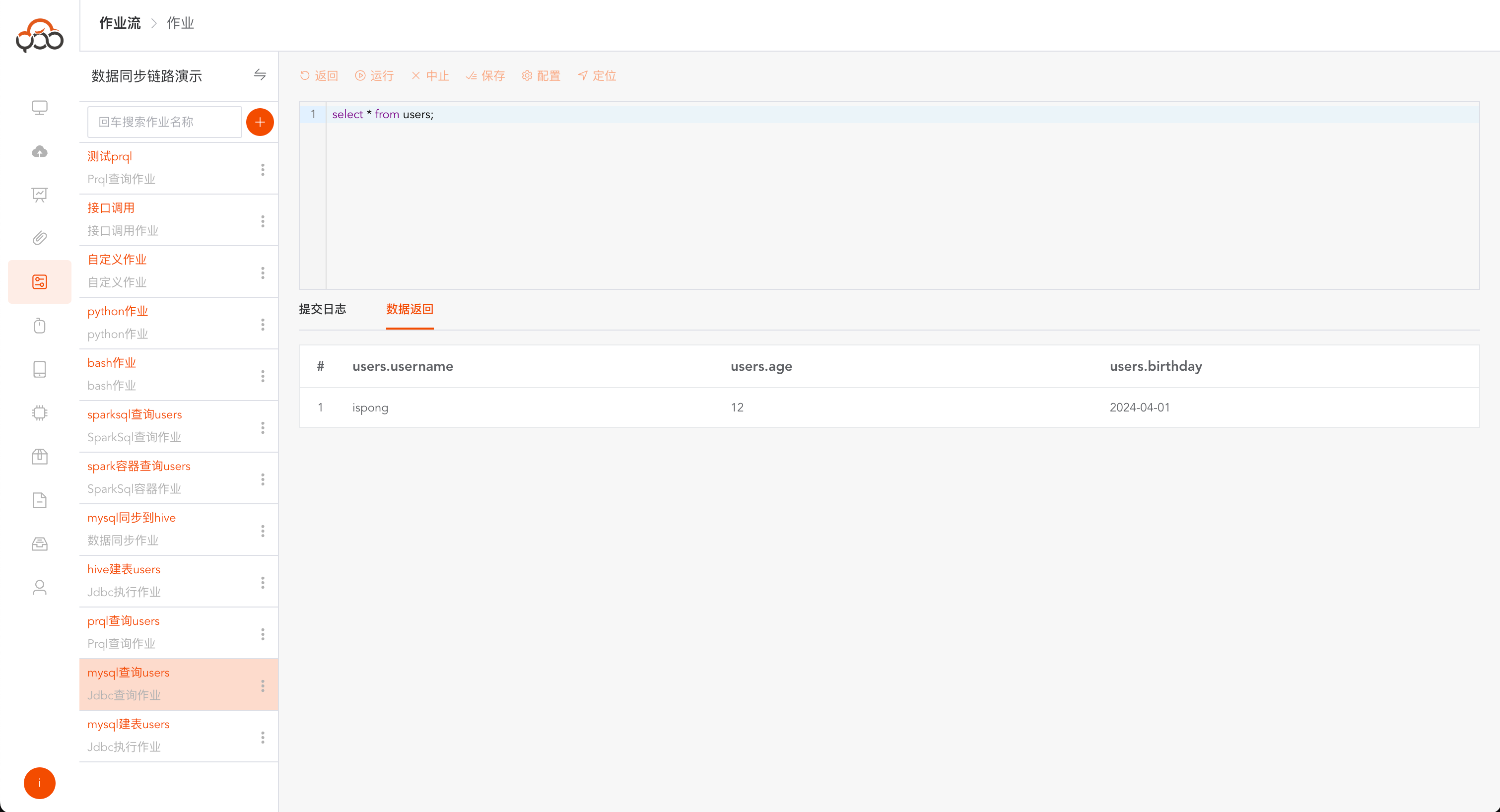
Jdbc查询作业
选择Jdbc查询作业类型
- 名称: 必填,作业流内名称唯一
- 类型: 必填,数据源的类型
- 数据源: 必填,选择查询sql的数据源
- 备注: 非必填
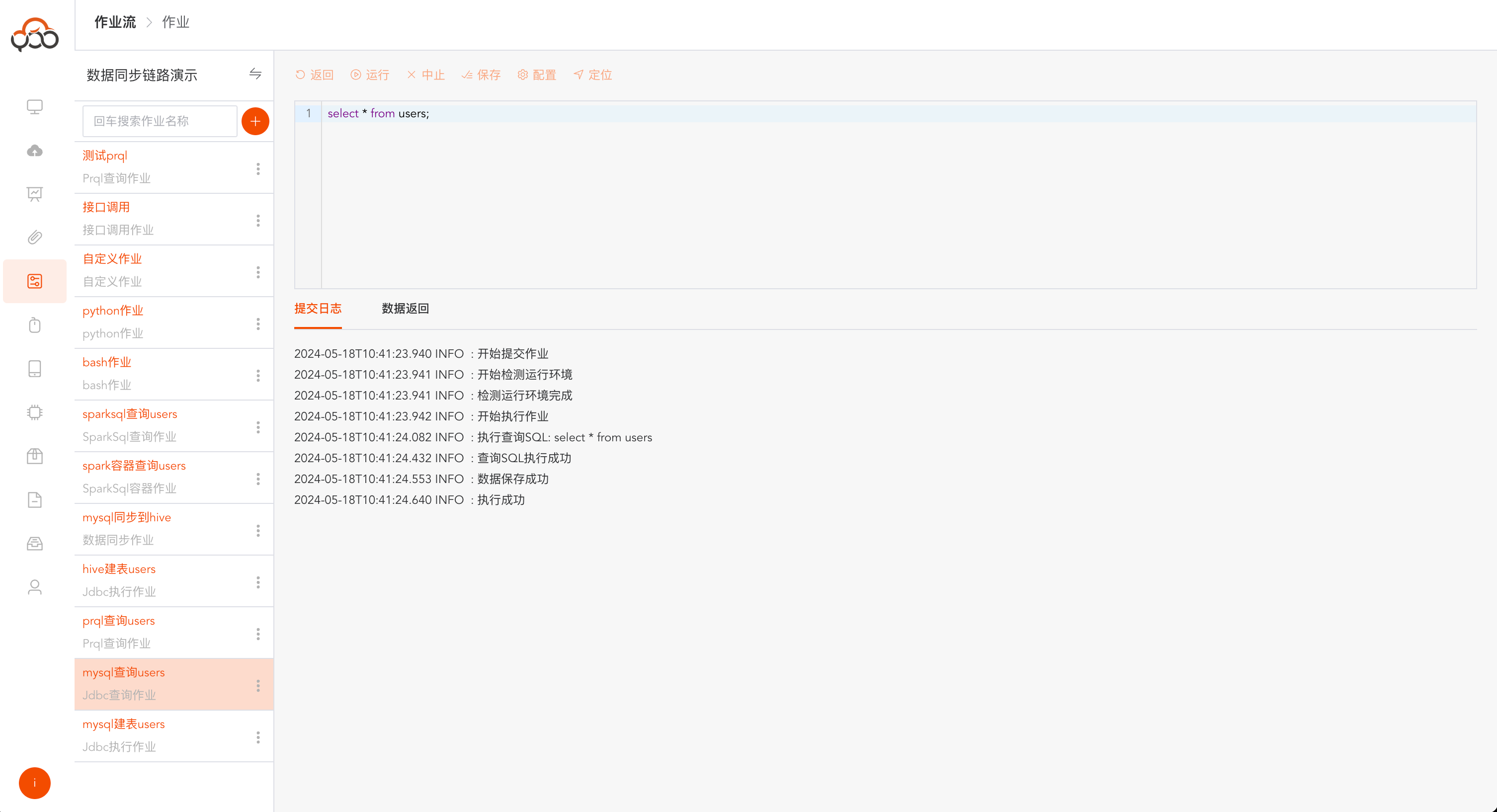
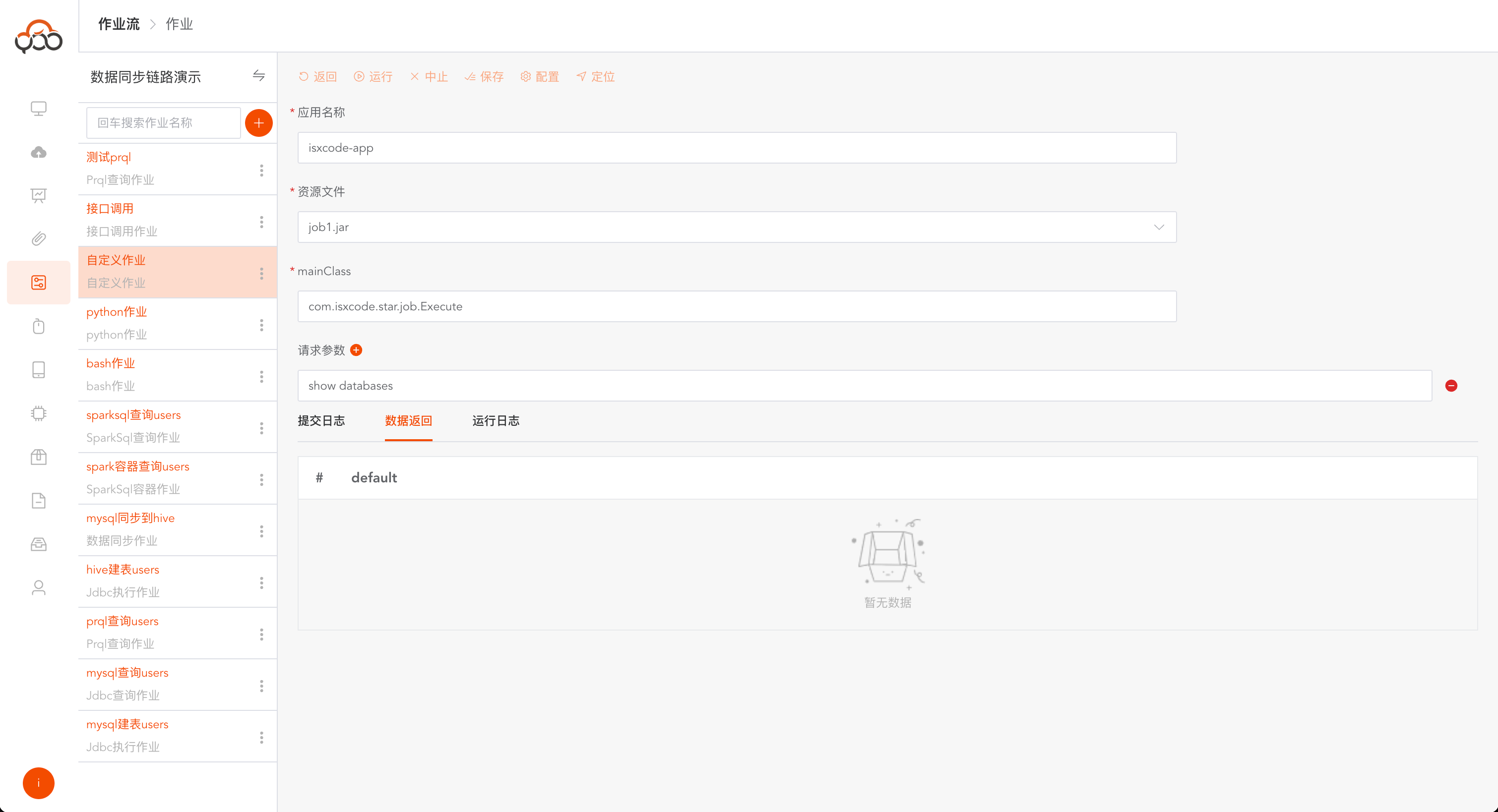
运行成功后,会多出一个
数据返回的tab,可看查询返回的具体数据
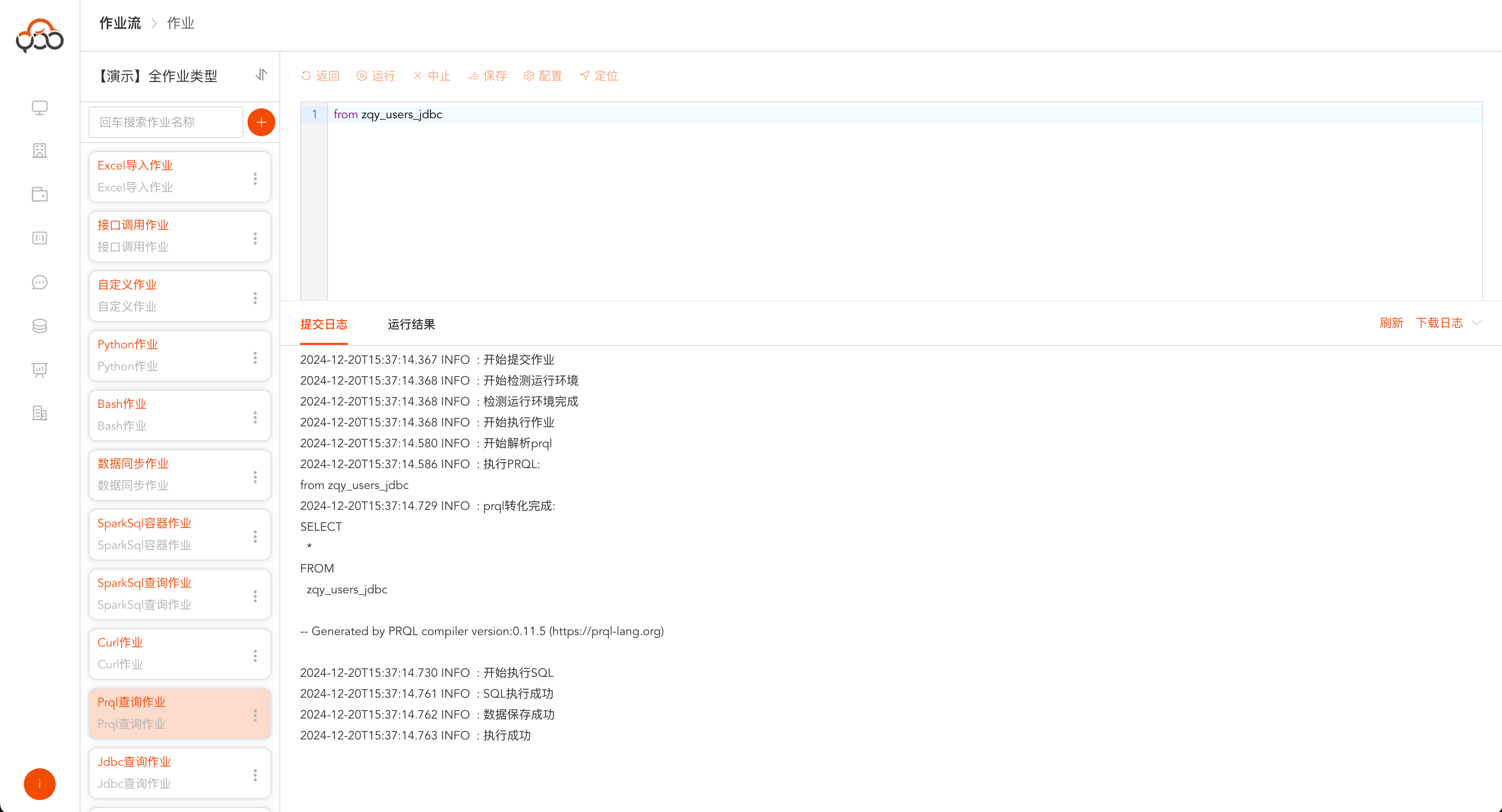
Prql查询作业
选择Prql查询作业类型
- 名称: 必填,作业流内名称唯一
- 类型: 必填,数据源的类型
- 数据源: 必填,选择查询prql的数据源
- 备注: 非必填
prql官网说明: https://prql-lang.org/
提交日志中会打印,真实执行的sql语句,并返回
运行结果
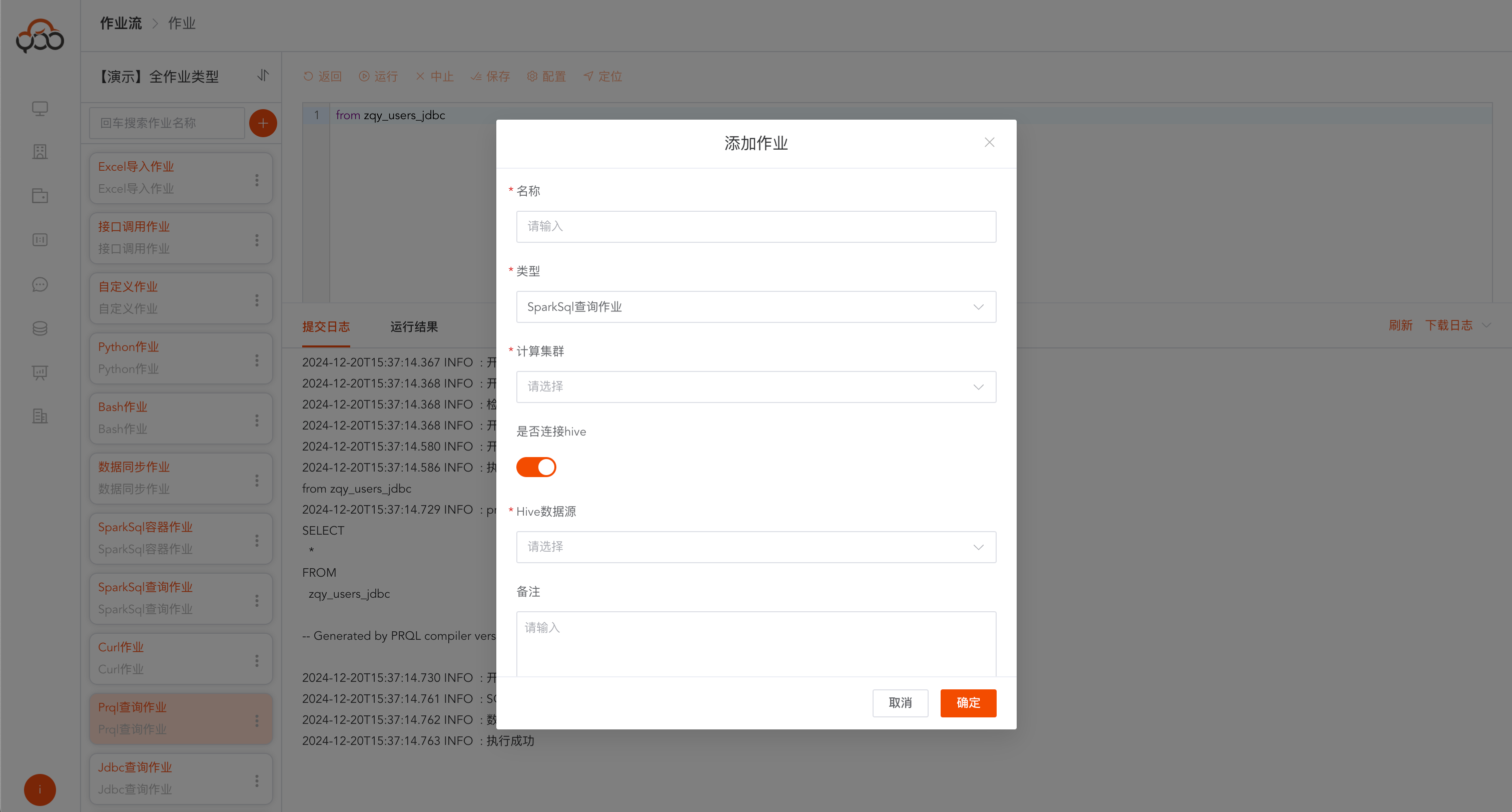
SparkSql查询作业
选择SparkSql查询作业类型
- 名称: 必填,作业流内名称唯一
- 计算集群: 必填,指定需要提交作业运行的计算集群
- 是否连接hive: 必填,默认是不选中
- Hive数据源: 必填,如果开启连接hive,则需要选择一个可用的hive数据源
- 备注: 非必填
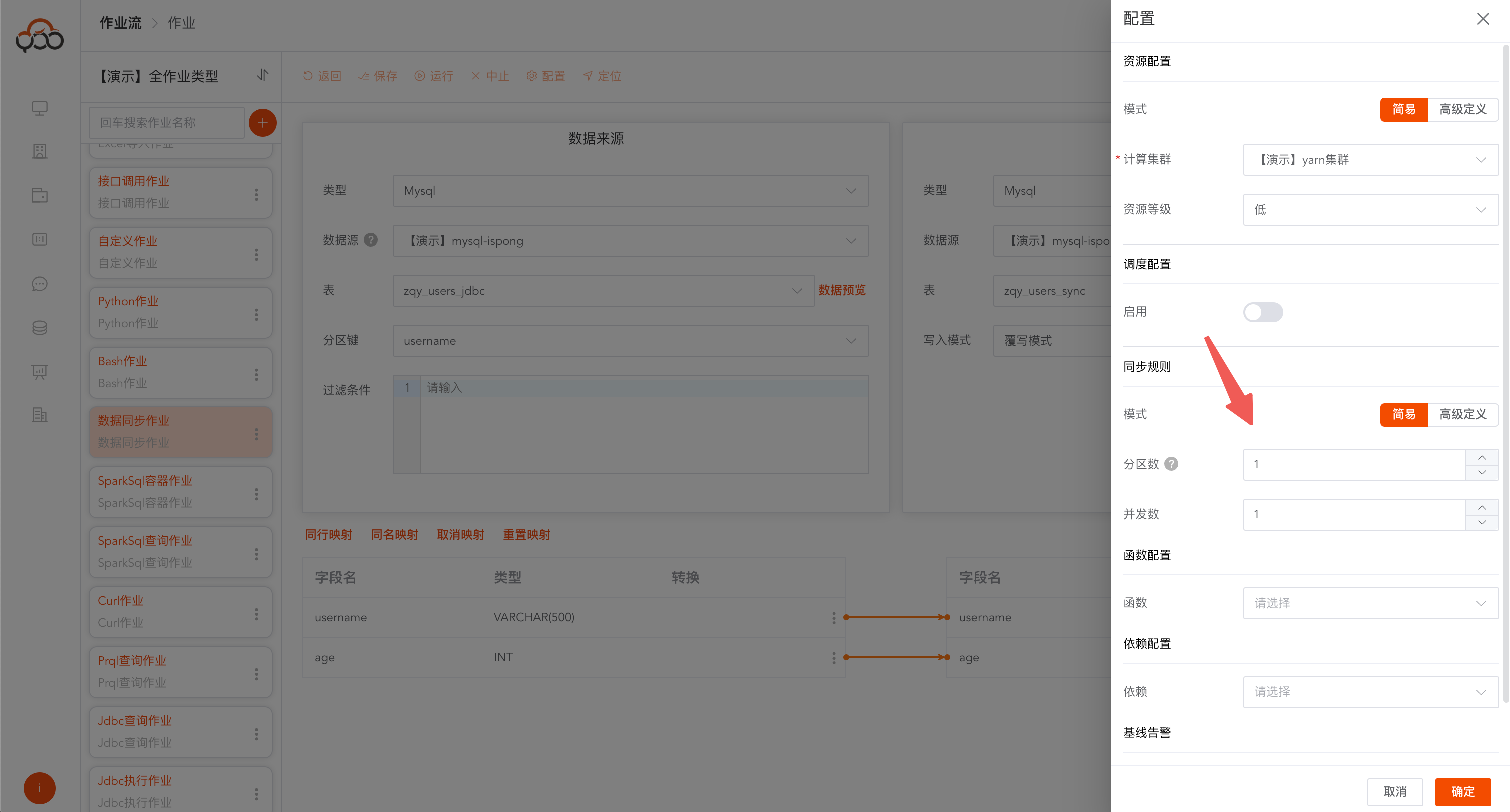
SparkSql查询作业支持计算集群切换,支持hive数据源切换,支持资源等级切换,函数配置,依赖配置
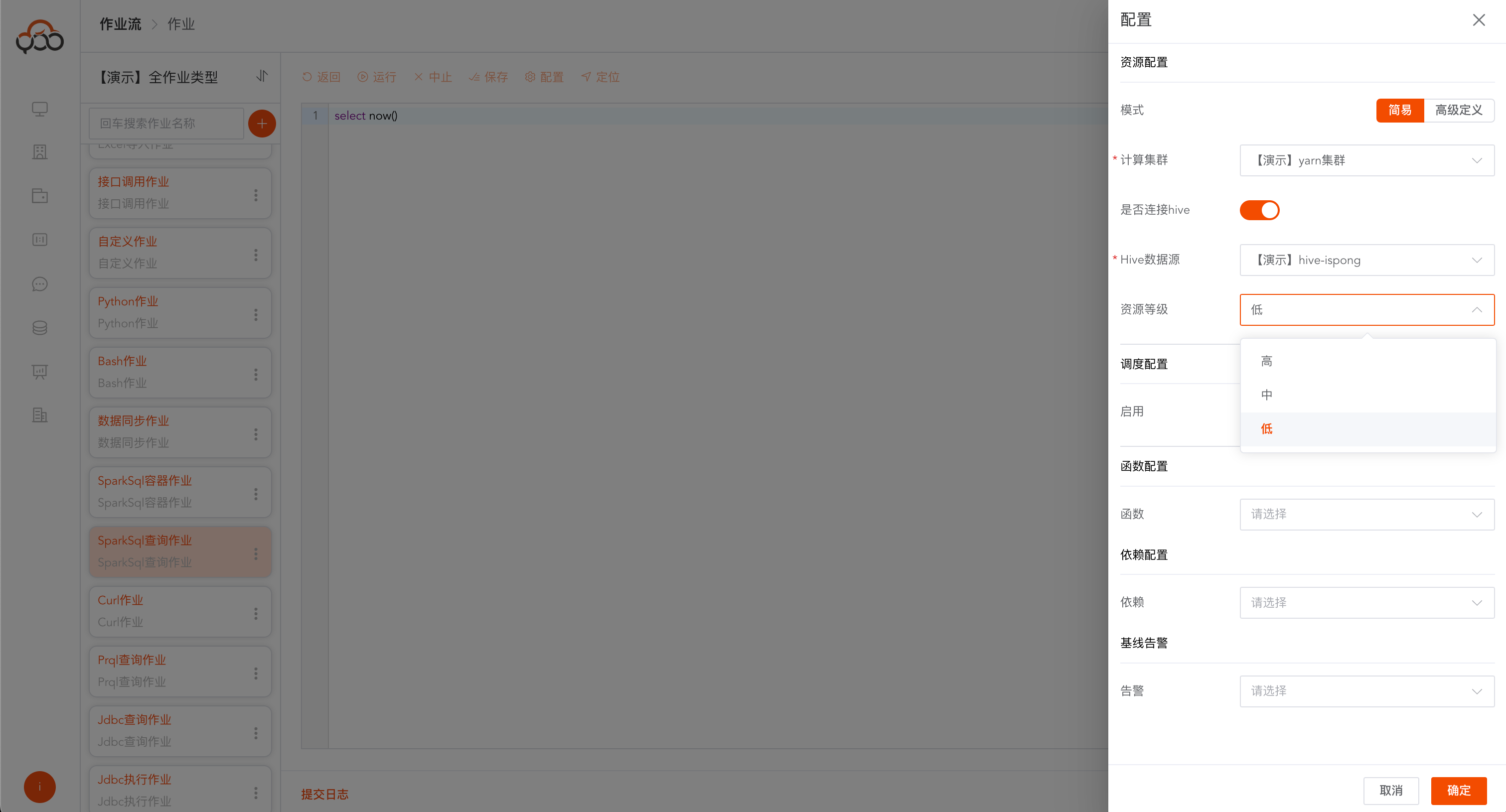
资源等级说明
- 高: 8GB
- 中: 4GB
- 低: 2GB
支持高级配置SparkConfig,配置参考链接: https://spark.apache.org/docs/3.4.1/configuration.html
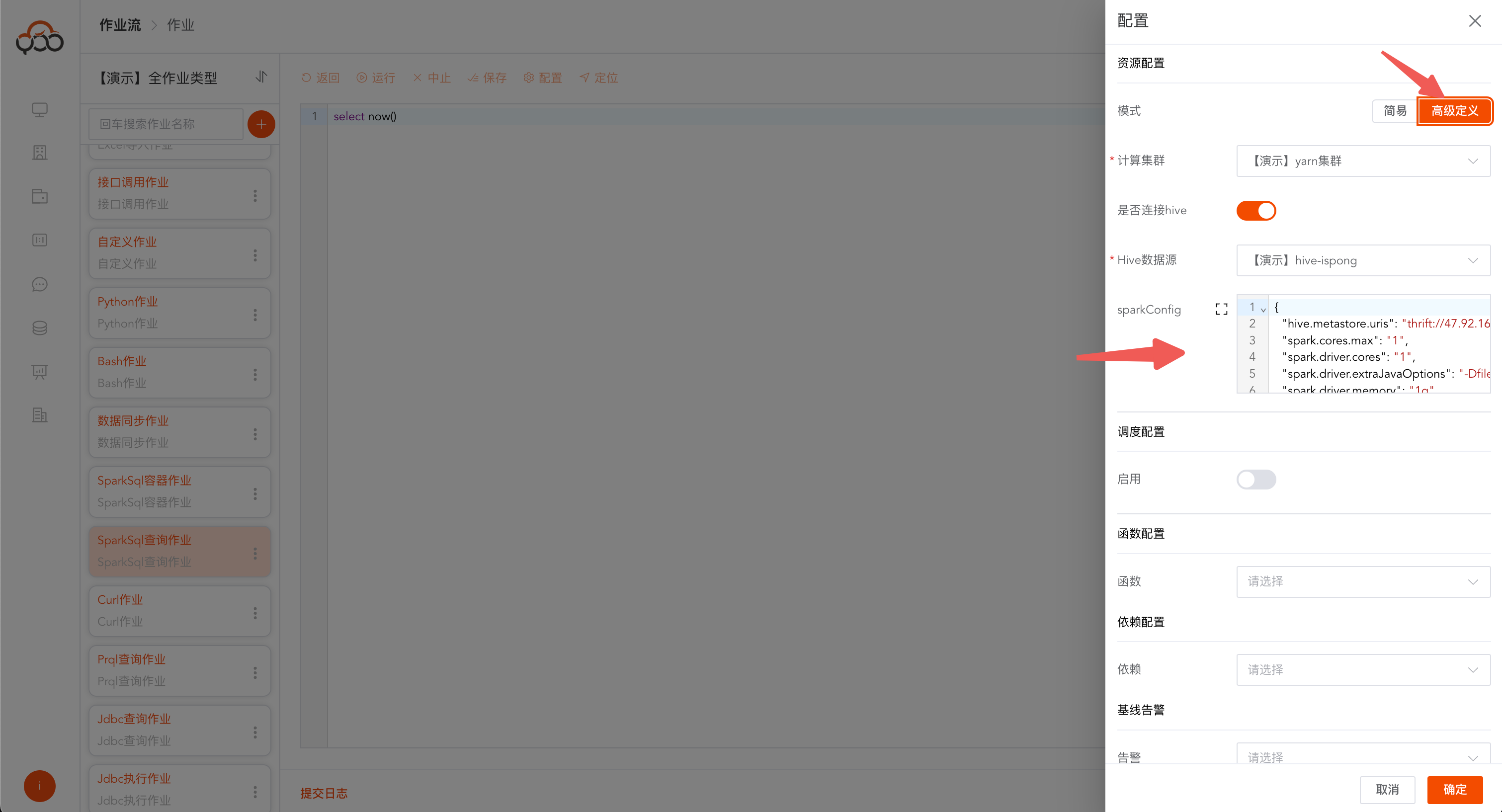
配置样例
可点击左侧的按钮,放大编辑
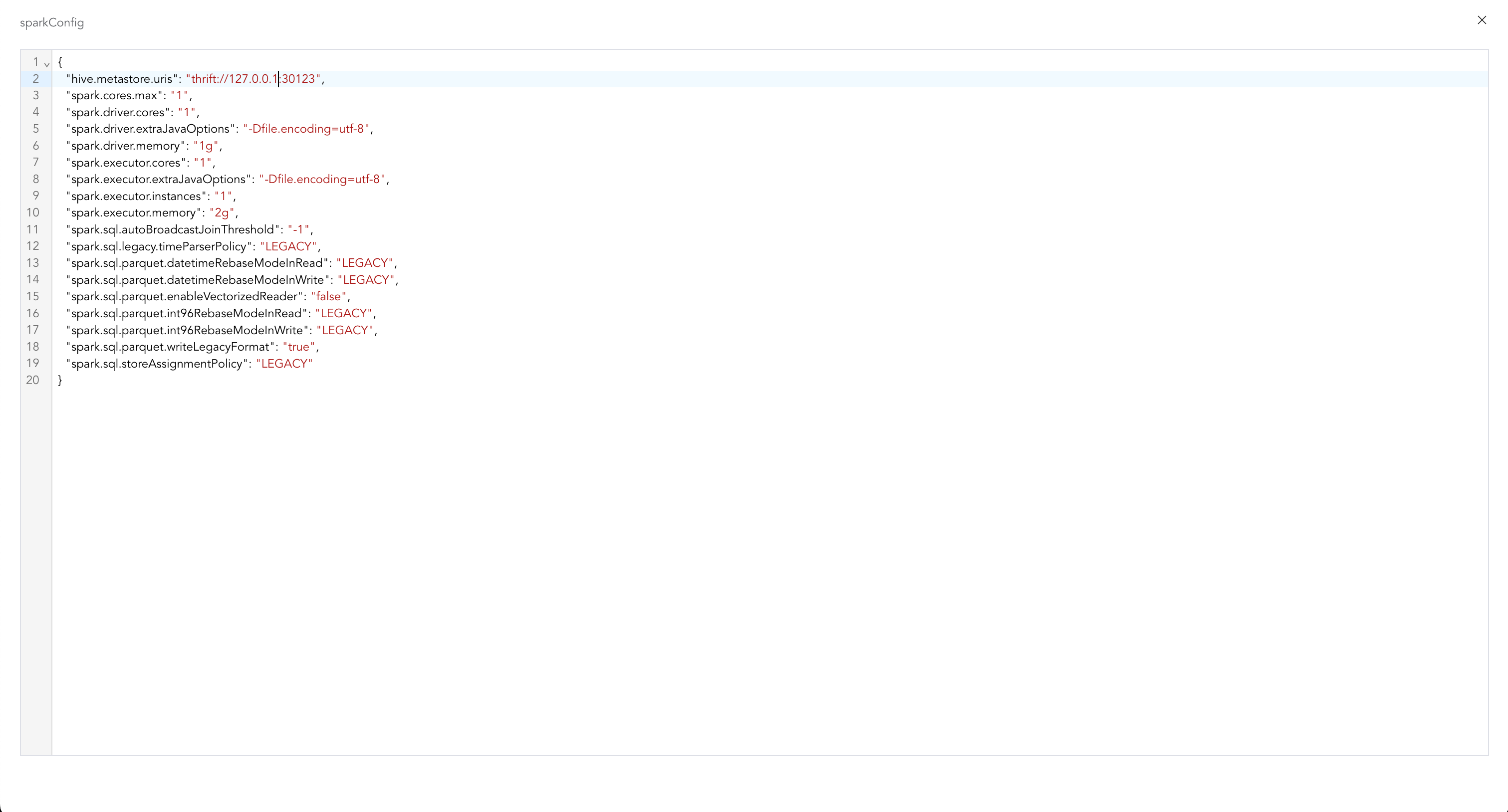
{
"hive.metastore.uris": "thrift://127.0.0.1:9083",
"spark.cores.max": "1",
"spark.driver.cores": "1",
"spark.driver.extraJavaOptions": "-Dfile.encoding=utf-8",
"spark.driver.memory": "1g",
"spark.executor.cores": "1",
"spark.executor.extraJavaOptions": "-Dfile.encoding=utf-8",
"spark.executor.instances": "1",
"spark.executor.memory": "2g",
"spark.sql.autoBroadcastJoinThreshold": "-1",
"spark.sql.legacy.timeParserPolicy": "LEGACY",
"spark.sql.parquet.datetimeRebaseModeInRead": "LEGACY",
"spark.sql.parquet.datetimeRebaseModeInWrite": "LEGACY",
"spark.sql.parquet.enableVectorizedReader": "false",
"spark.sql.parquet.int96RebaseModeInRead": "LEGACY",
"spark.sql.parquet.int96RebaseModeInWrite": "LEGACY",
"spark.sql.parquet.writeLegacyFormat": "true",
"spark.sql.storeAssignmentPolicy": "LEGACY"
}
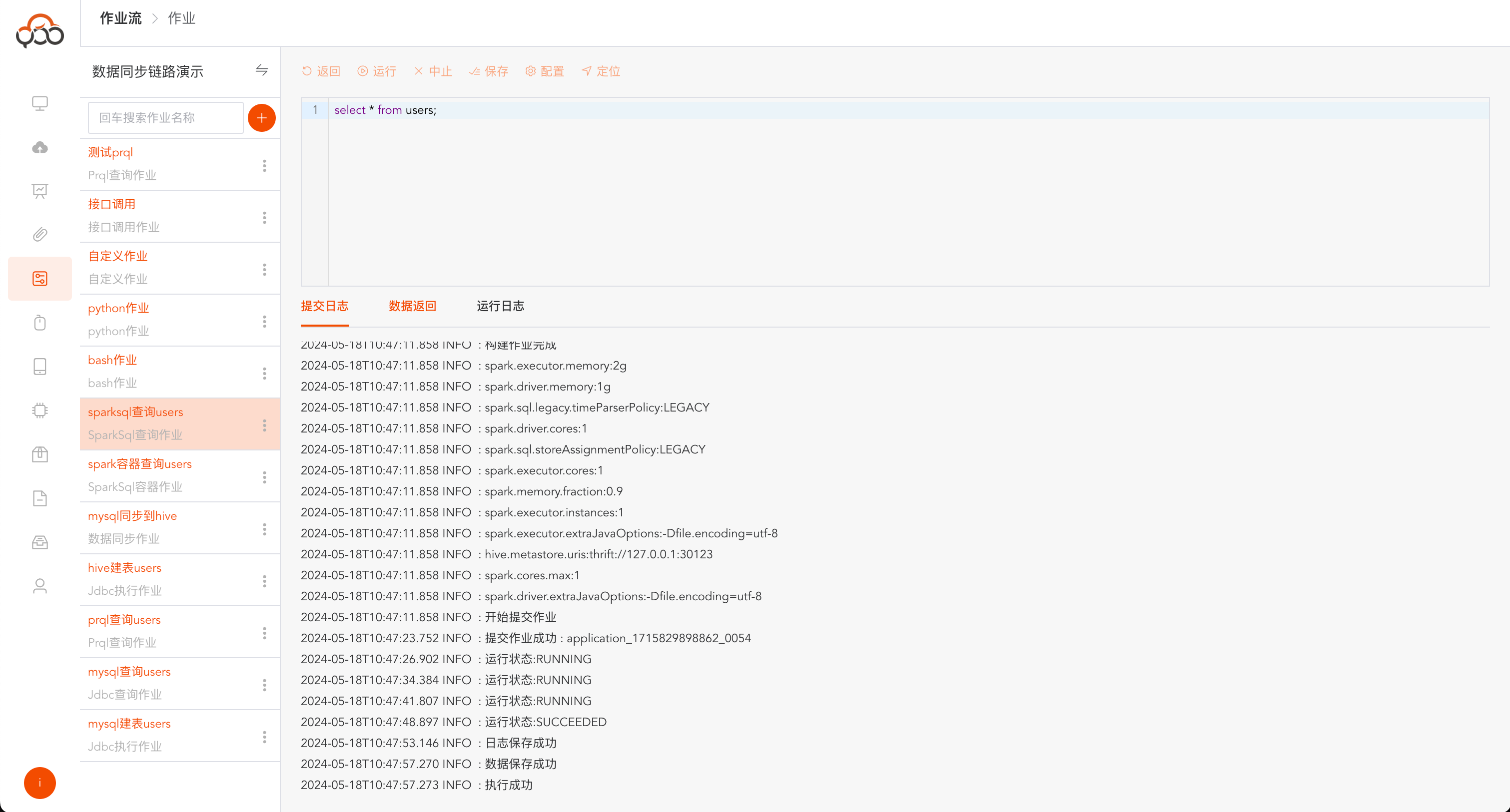
点击工具栏
运行按钮,弹出提交日志,可查看作业运行的实时情况
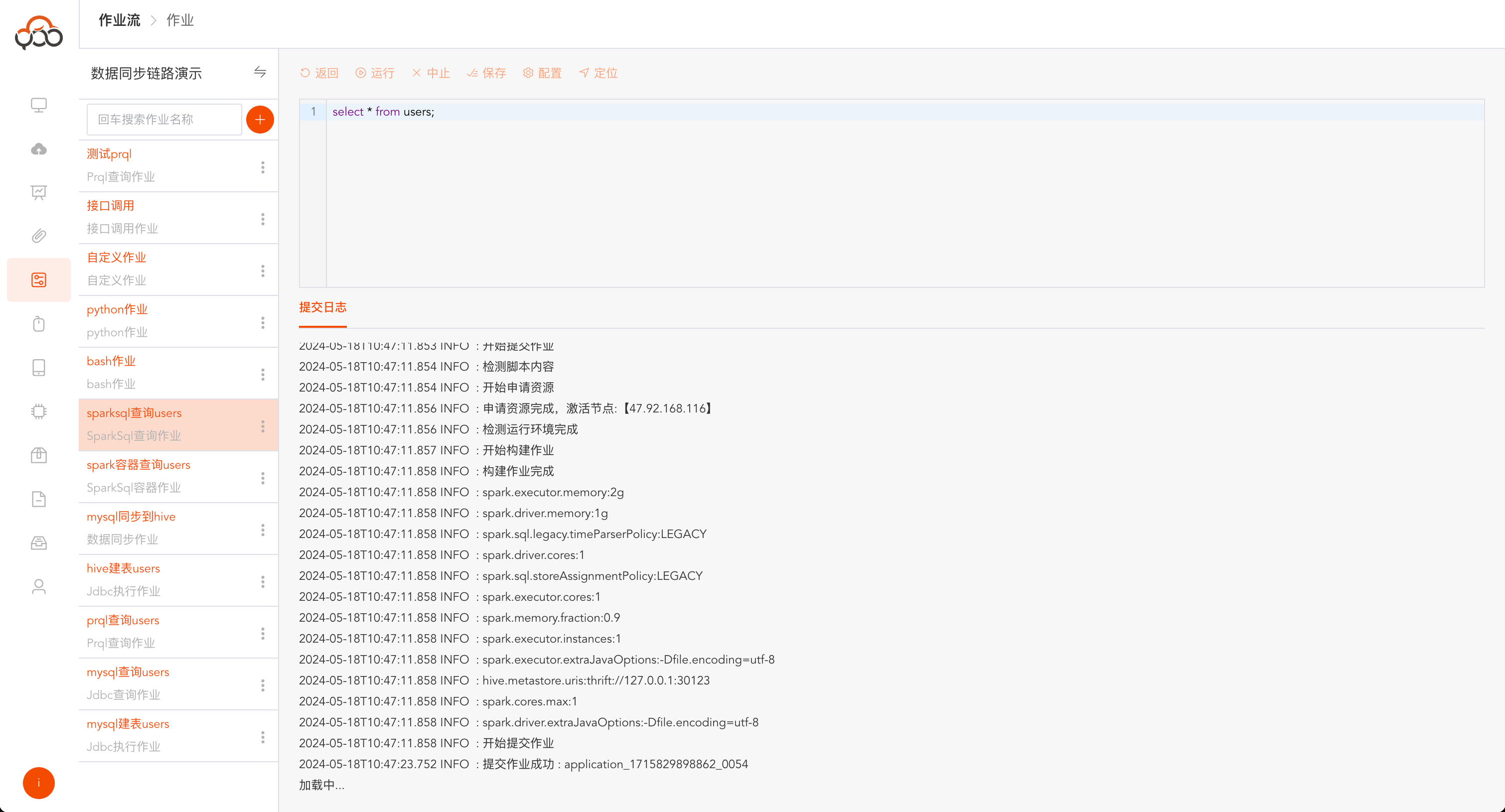
运行成功后,日志中提示
执行成功
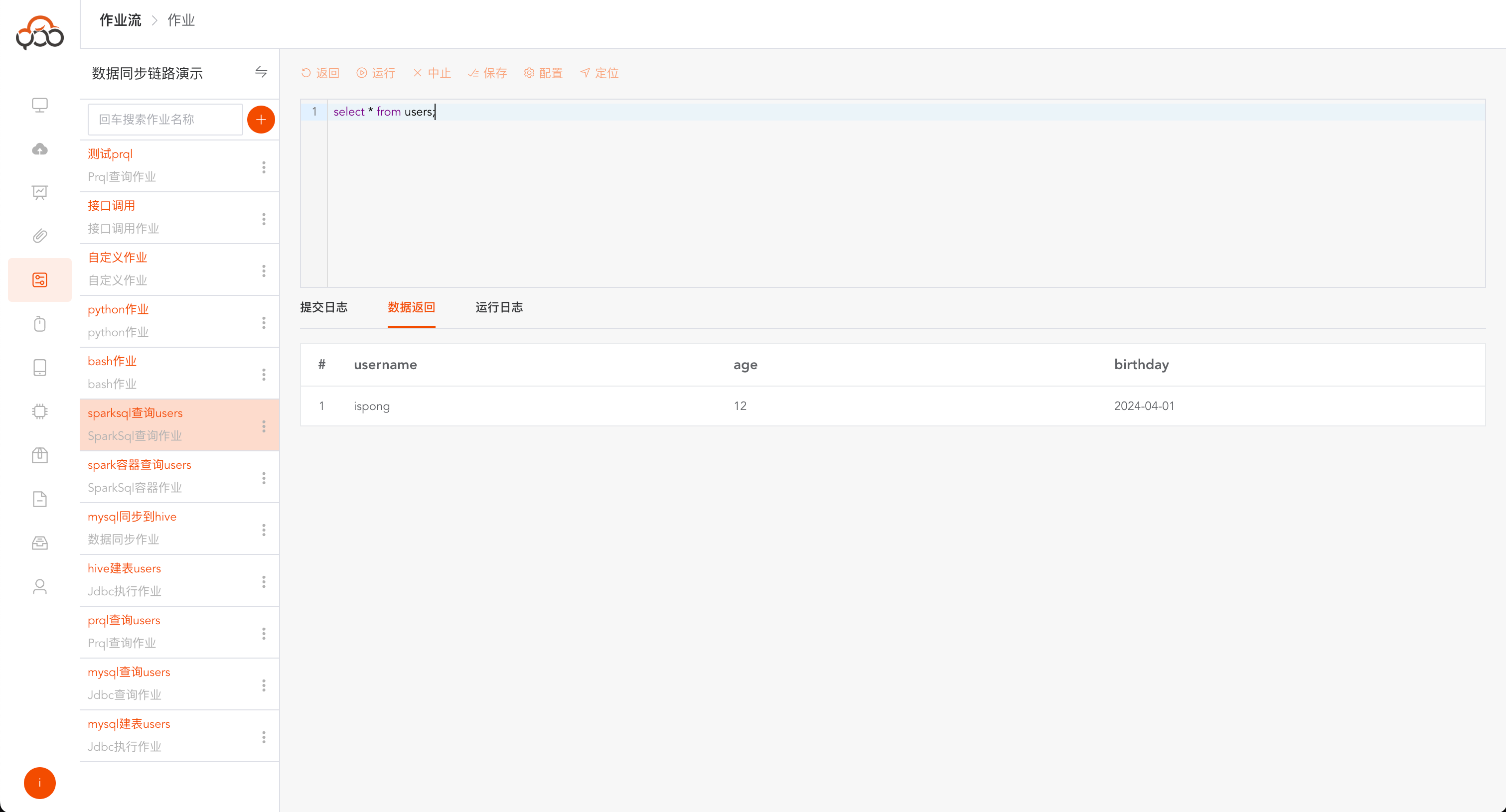
运行成功后,点击
数据返回,查看sparkSql执行的返回数据
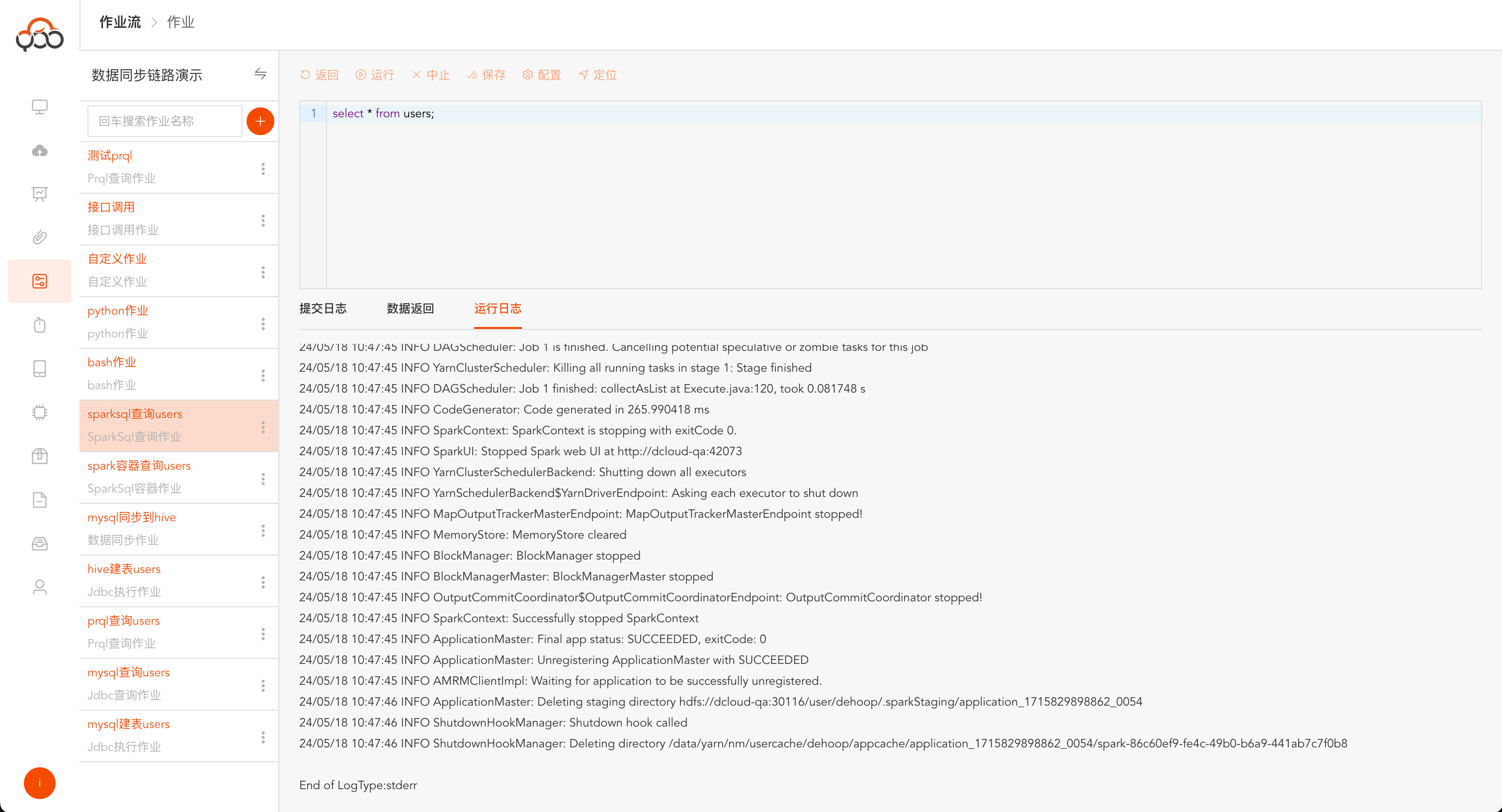
运行后,点击
运行日志,查看SparkSql作业执行的日志,可通过日志内容排查问题
SparkSql容器作业
注意!!!SparkSql容器作业比SparkSql查询作业快,支持秒级查询数据
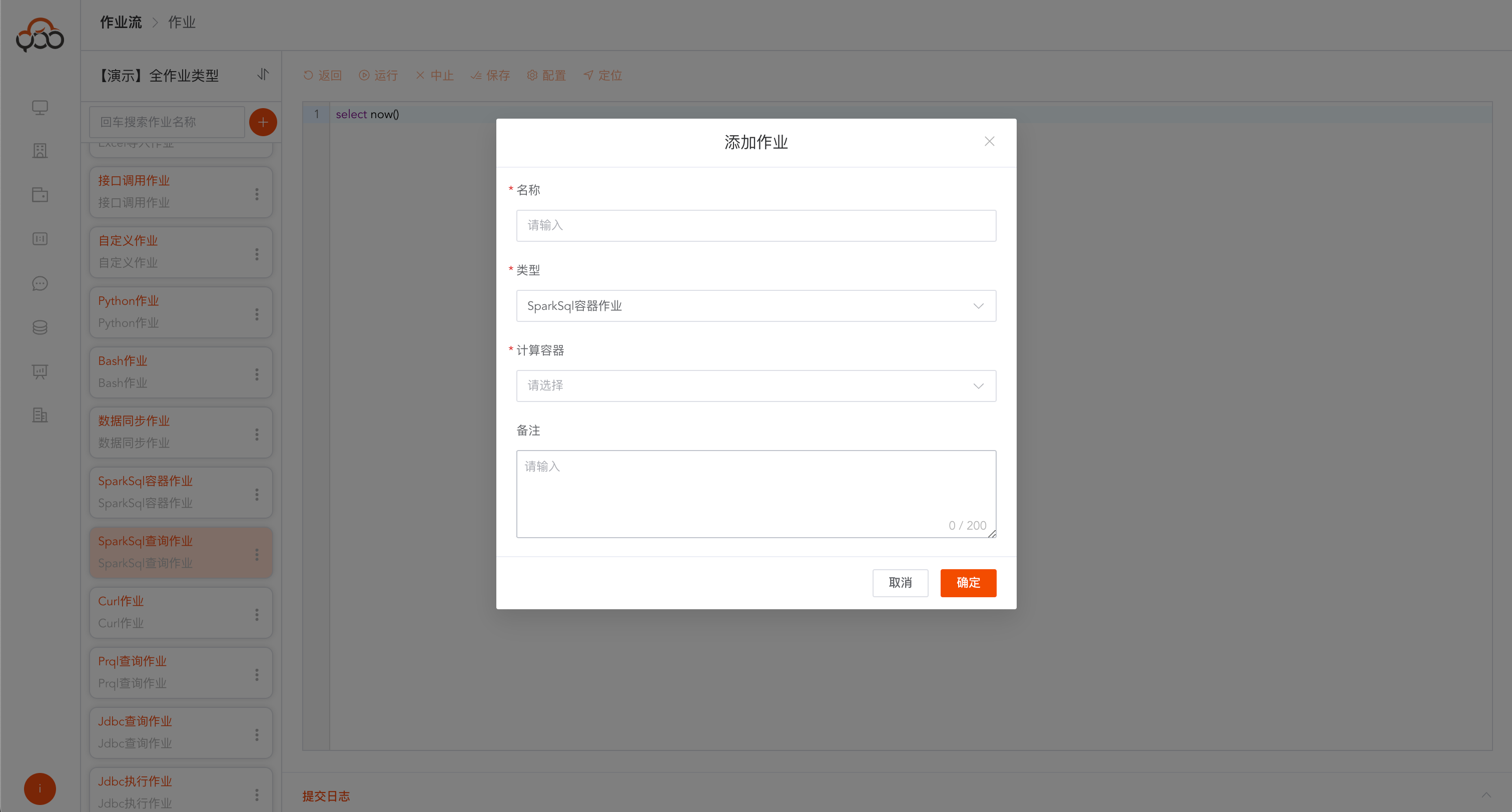
选择SparkSql容器作业类型
- 名称: 必填,作业流内名称唯一
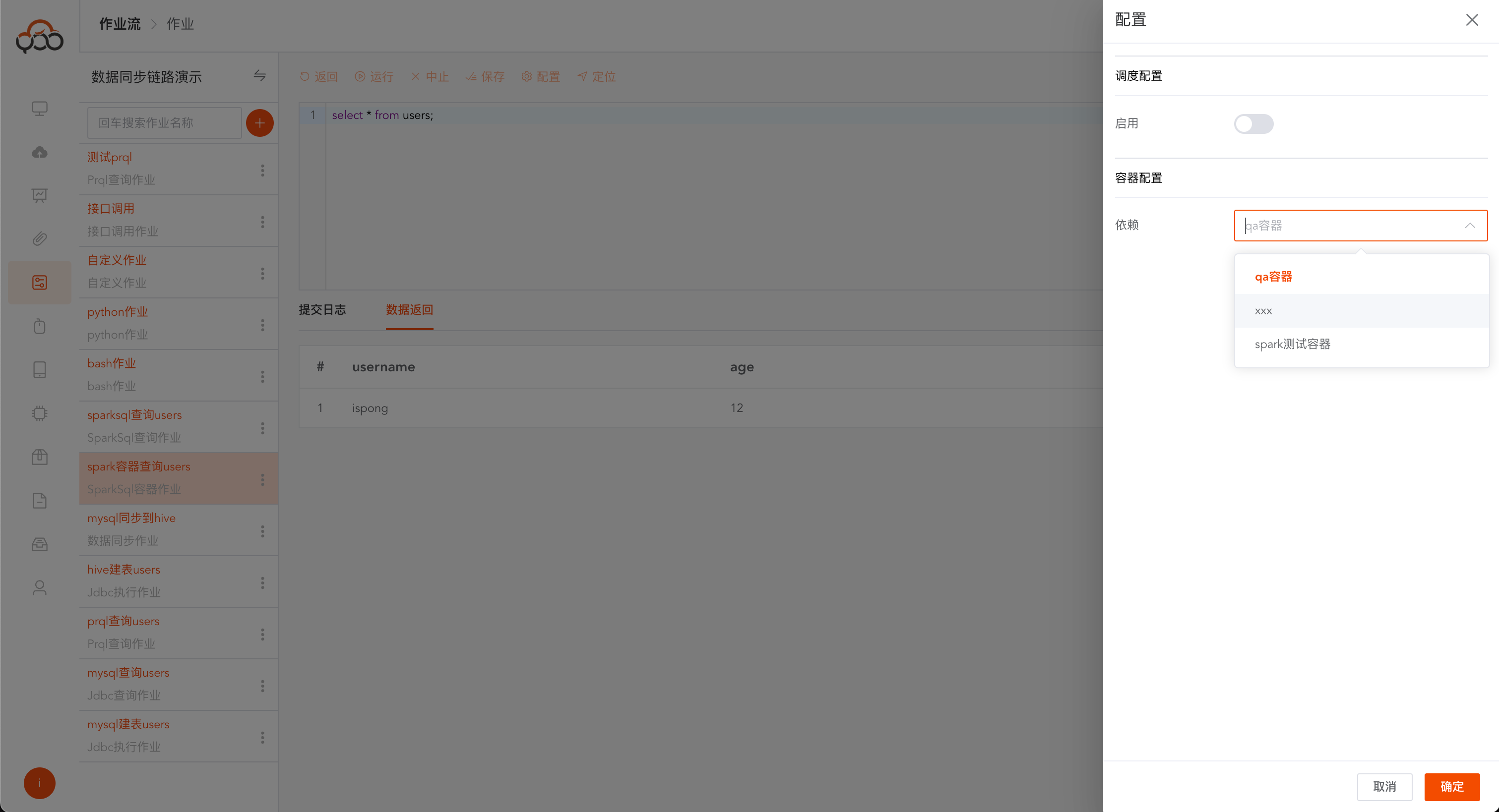
- 计算容器: 必填,作业执行所需的容器,需要在
计算容器菜单中创建,且状态处于运行中 - 备注: 非必填
点击运行,运行成功后,日志中返回
执行成功
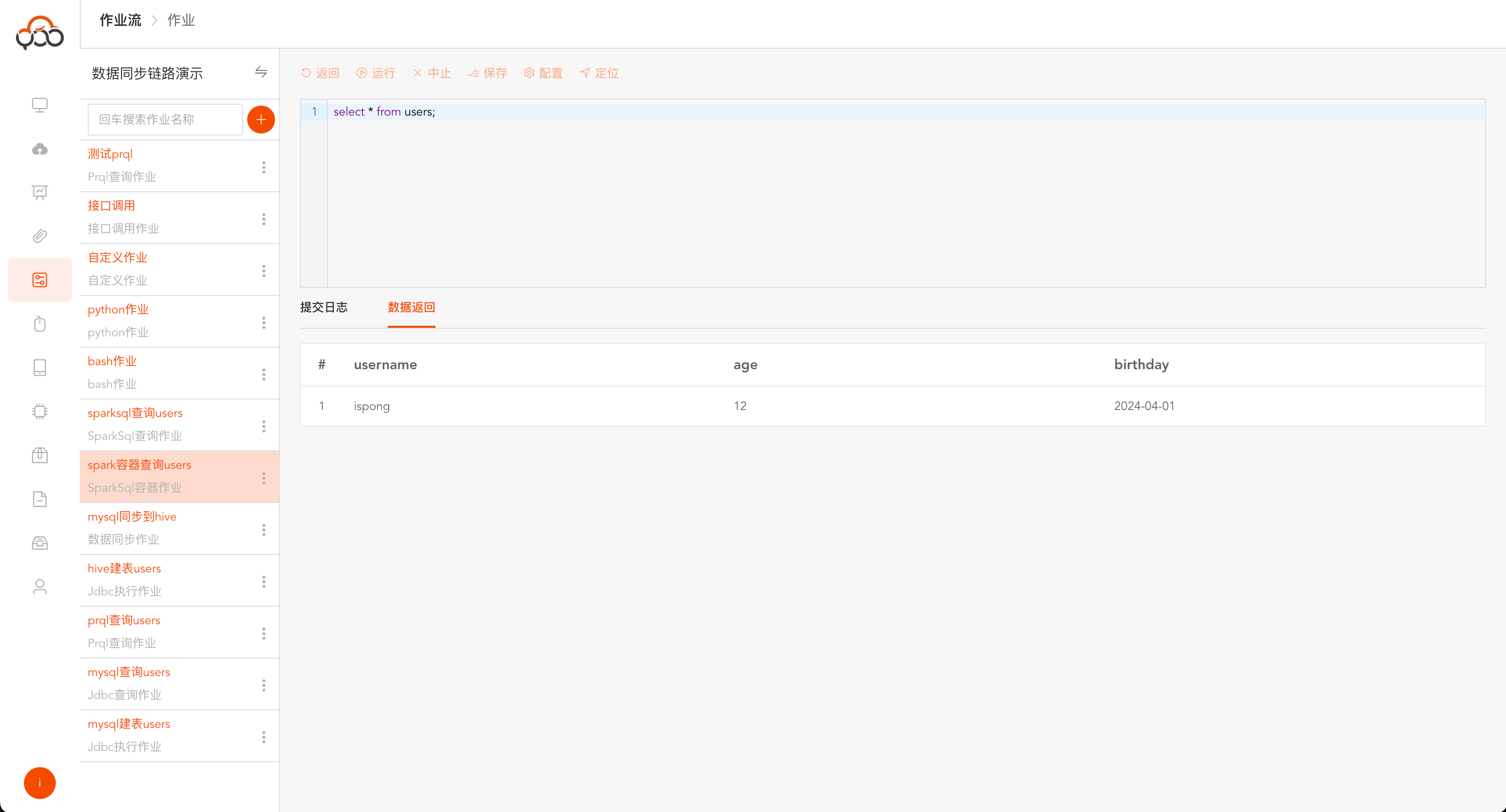
运行成功,点击
数据返回,可以查询SparkSql的返回数据
SparkSql容器作业支持计算容器切换
数据同步作业
选择数据同步作业类型
- 名称: 必填,作业流内名称唯一
- 计算集群: 必填,指定需要提交作业运行的计算集群
- 备注: 非必填
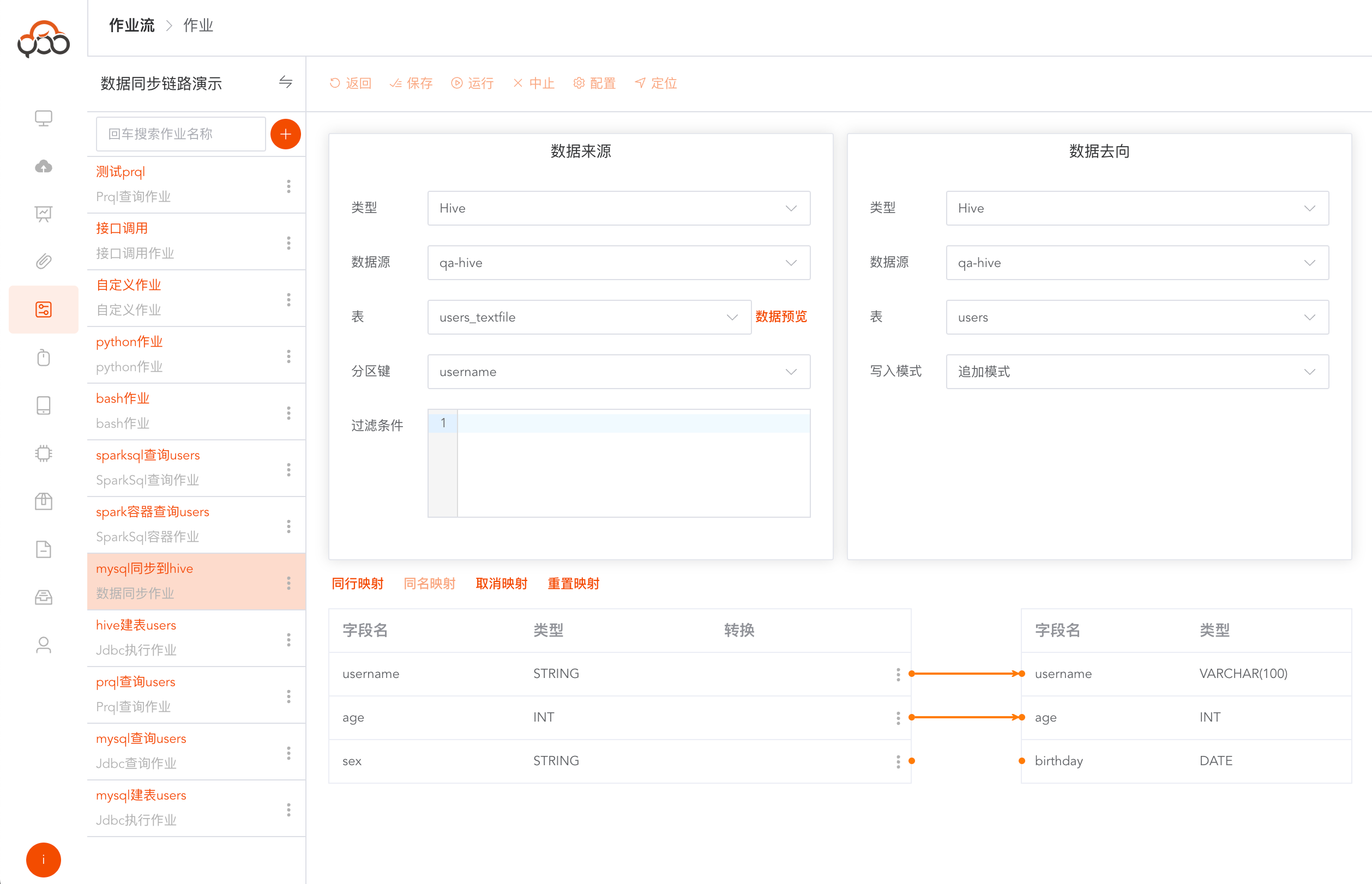
写入模式说明
- 追加模式: 目标表数据不变,插入来源数据
- 覆写模式: 先清空目标表,再进行数据同步
分区说明
- 分区键: 指定来源表中的一个字段进行分区,数据同步过程中会对该字段切分
- 分区数: 默认1,以
分区键为准,将来源表切分成多少分,进行同步 - 并发数: 默认1,对切分好的分区数据,指定并发处理的执行器,推荐:分区数大于等于并发数,且成倍数关系
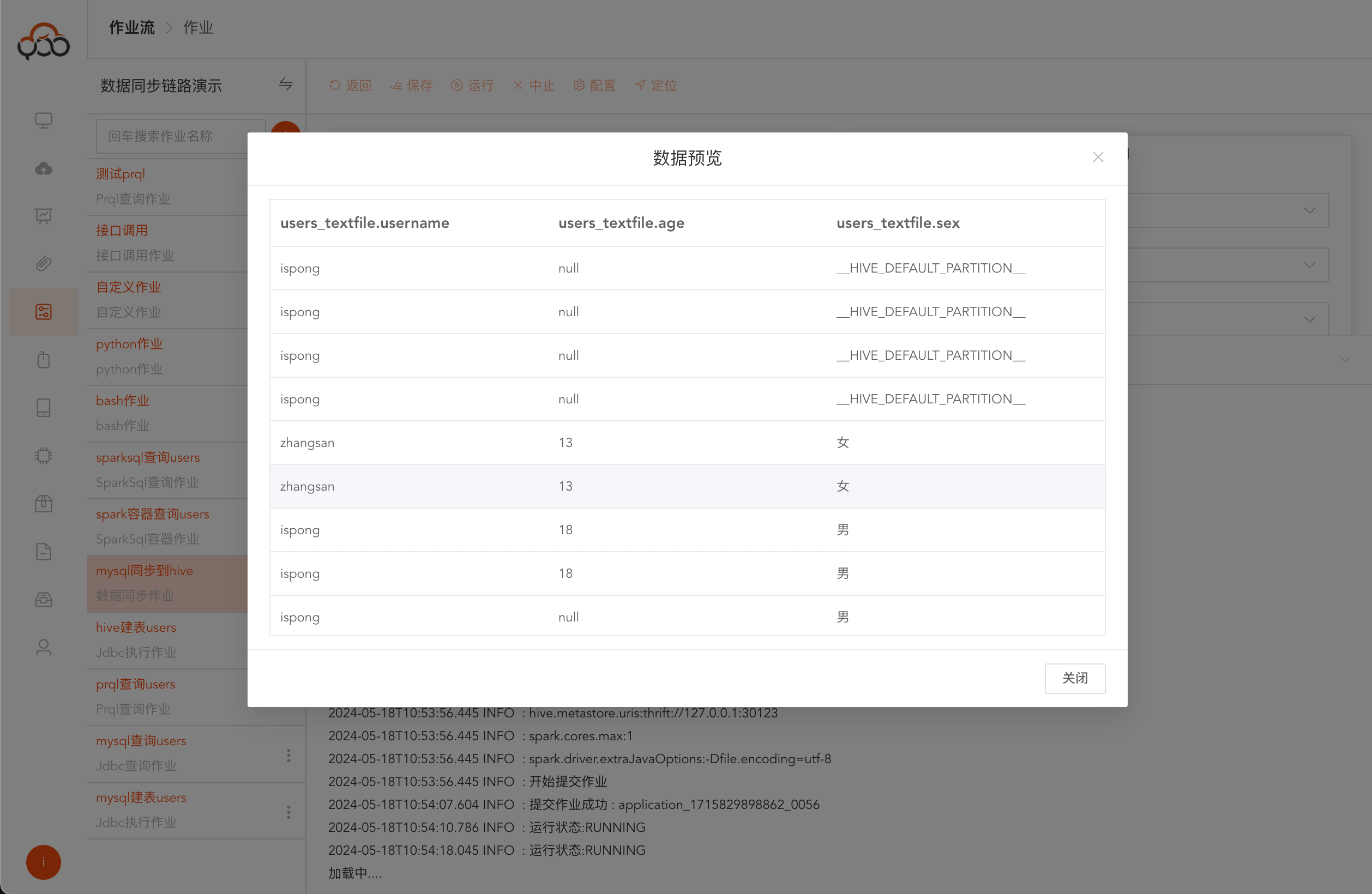
点击
数据预览按钮,
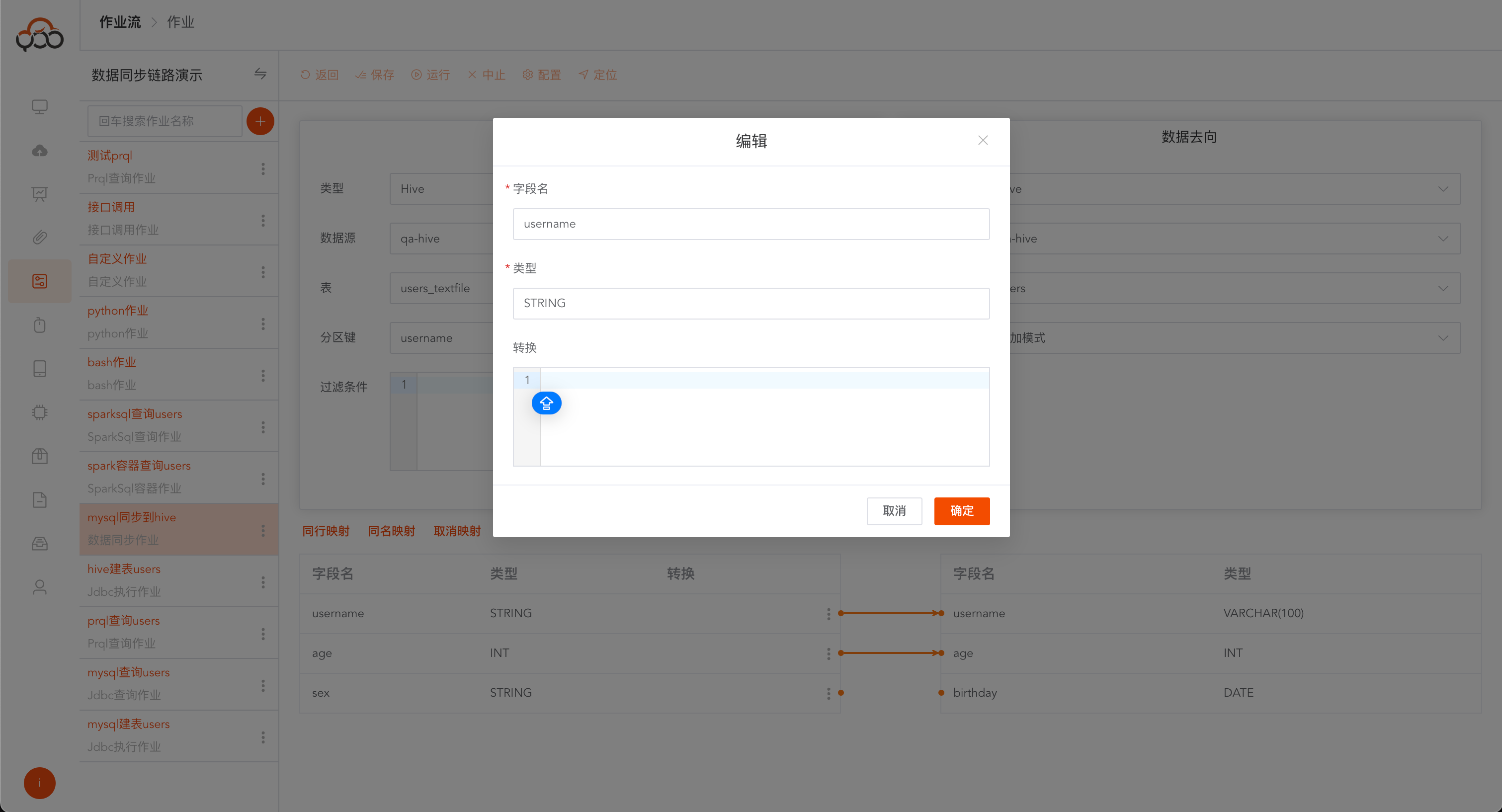
字段支持转换功能,支持spark官方的函数,参考链接: https://spark.apache.org/docs/latest/sql-ref-functions.html
点击运行,运行成功日志中返回
执行成功
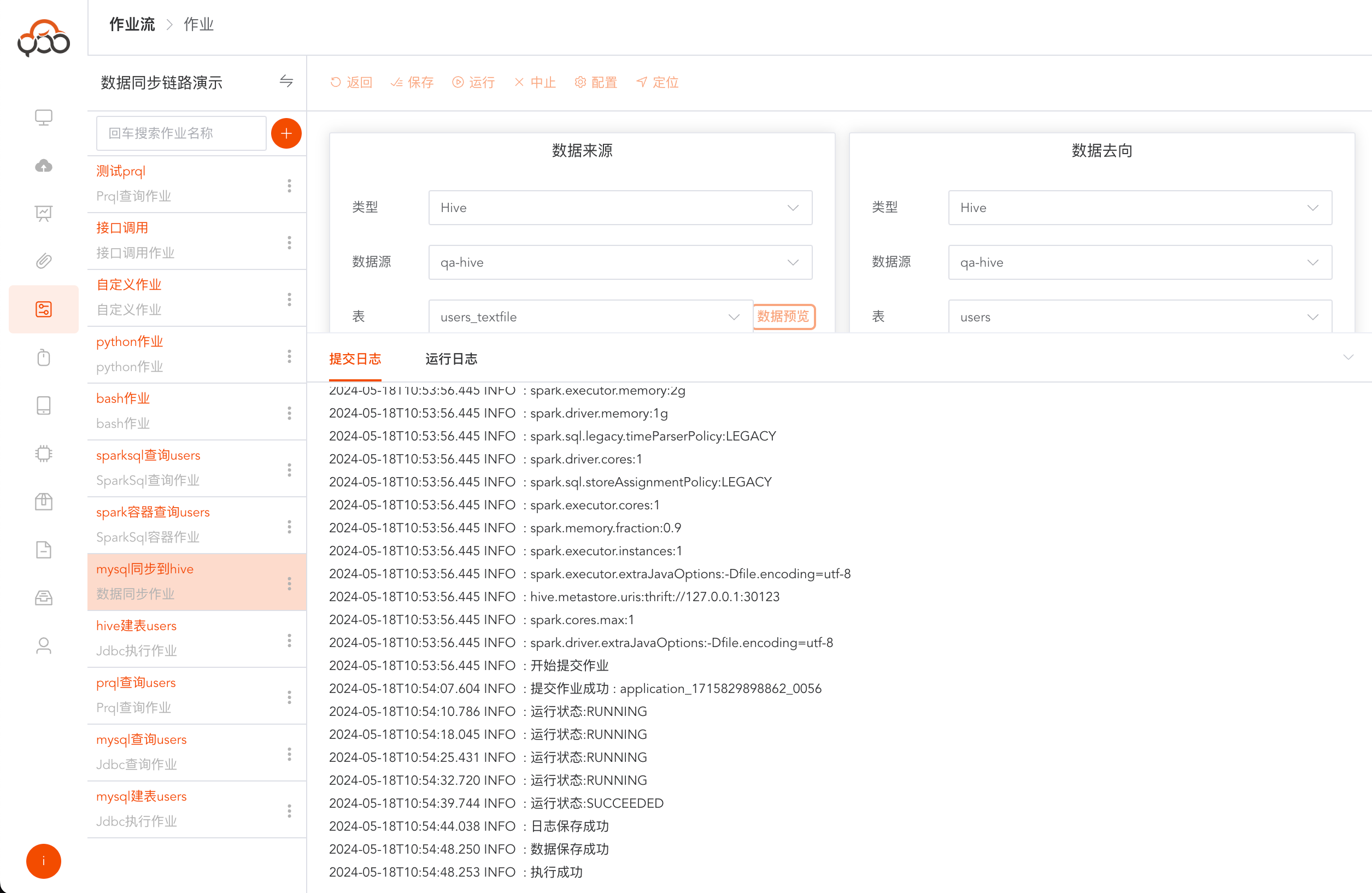
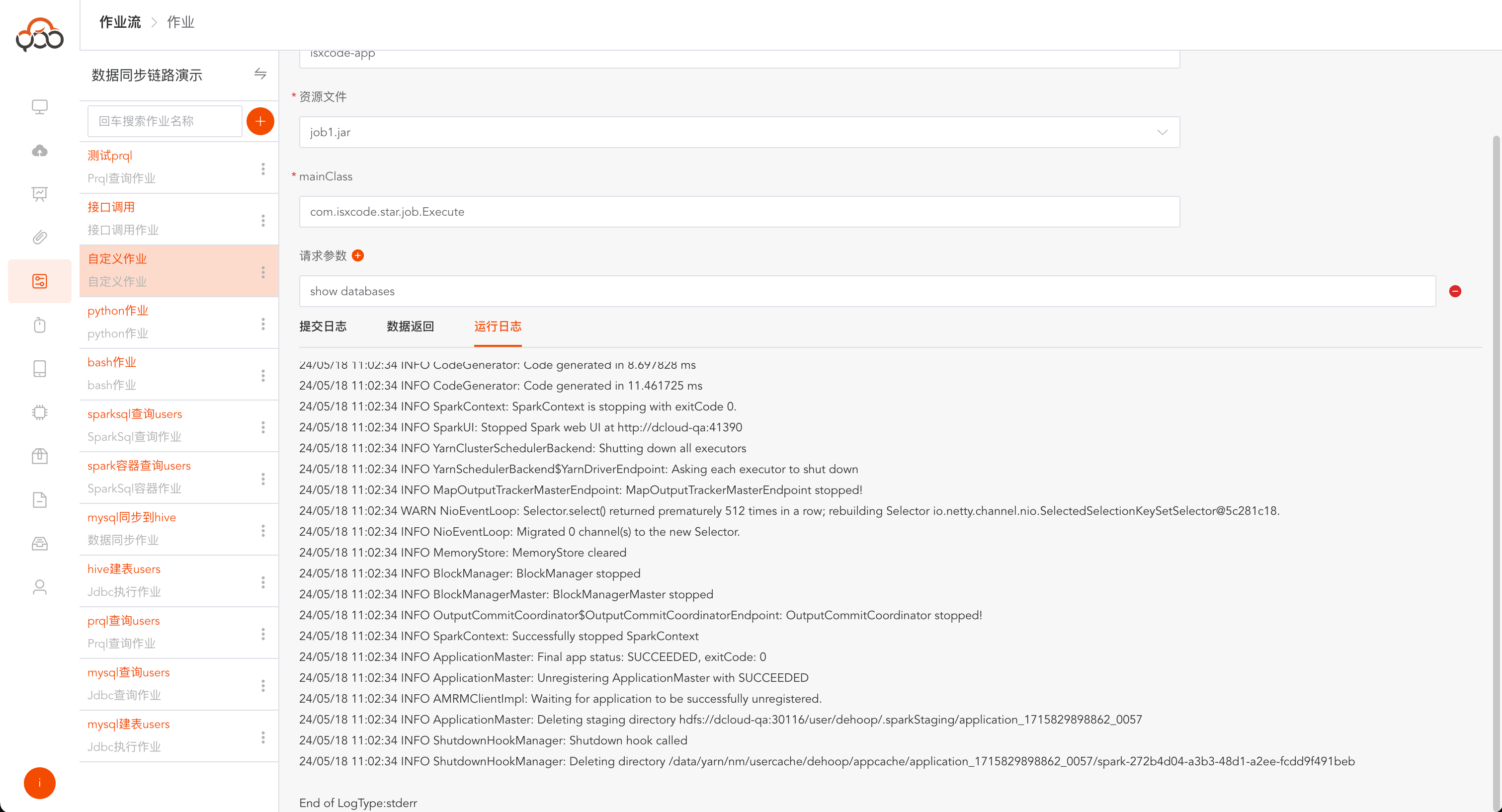
运行成功,点击运行日志,可查看作业运行的具体日志
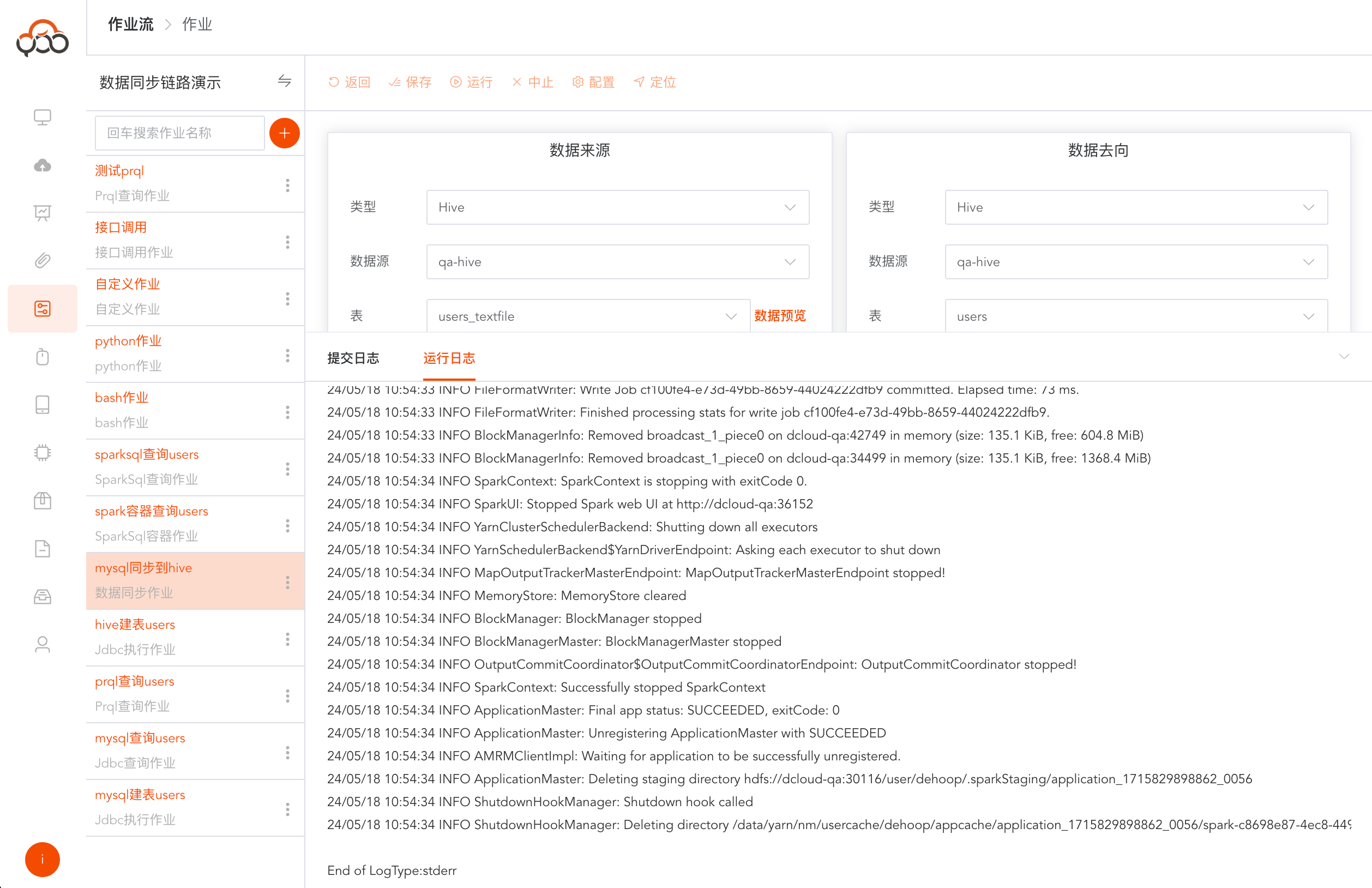
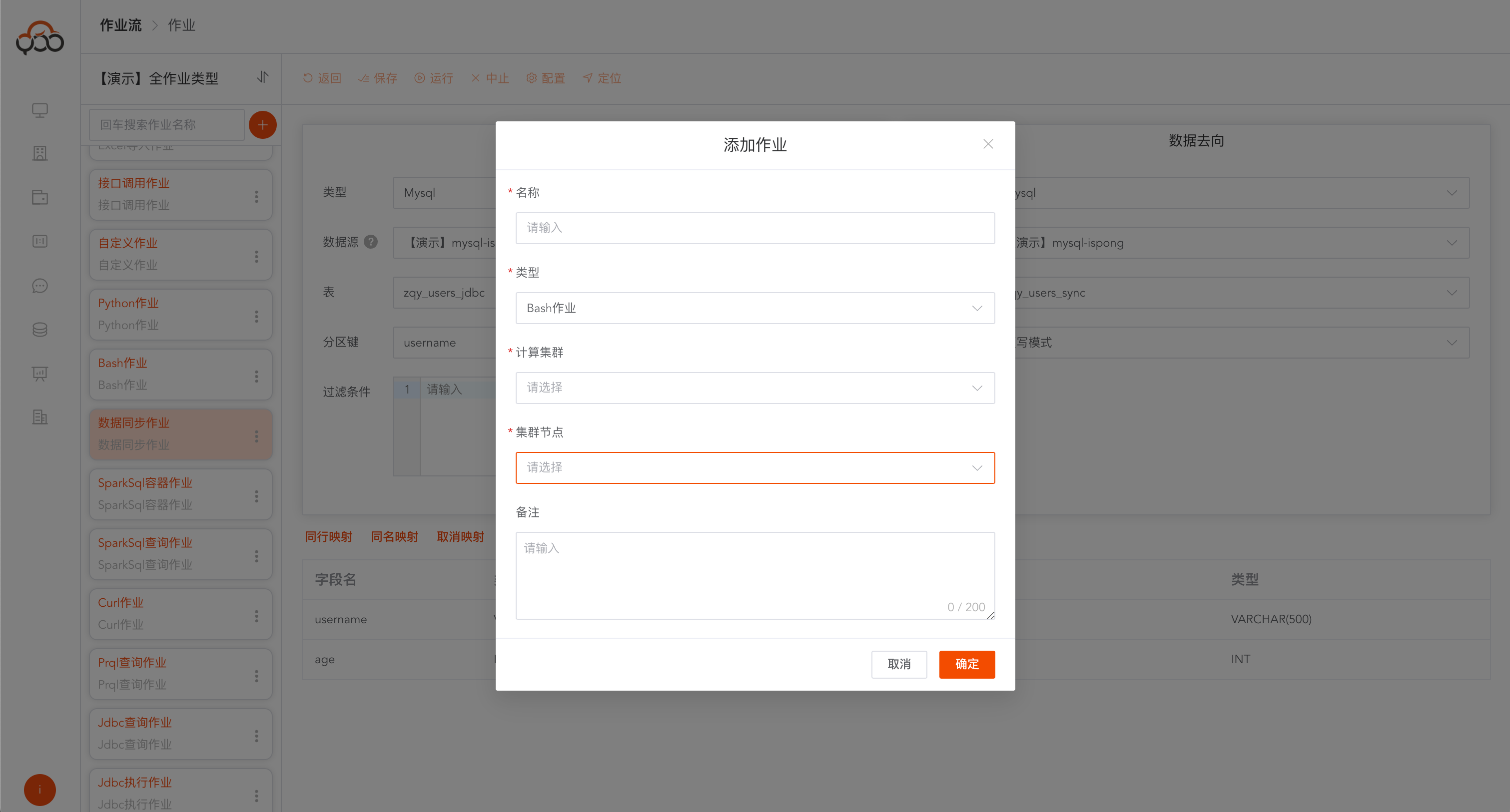
Bash作业
选择bash作业类型
- 名称: 必填,作业流内名称唯一
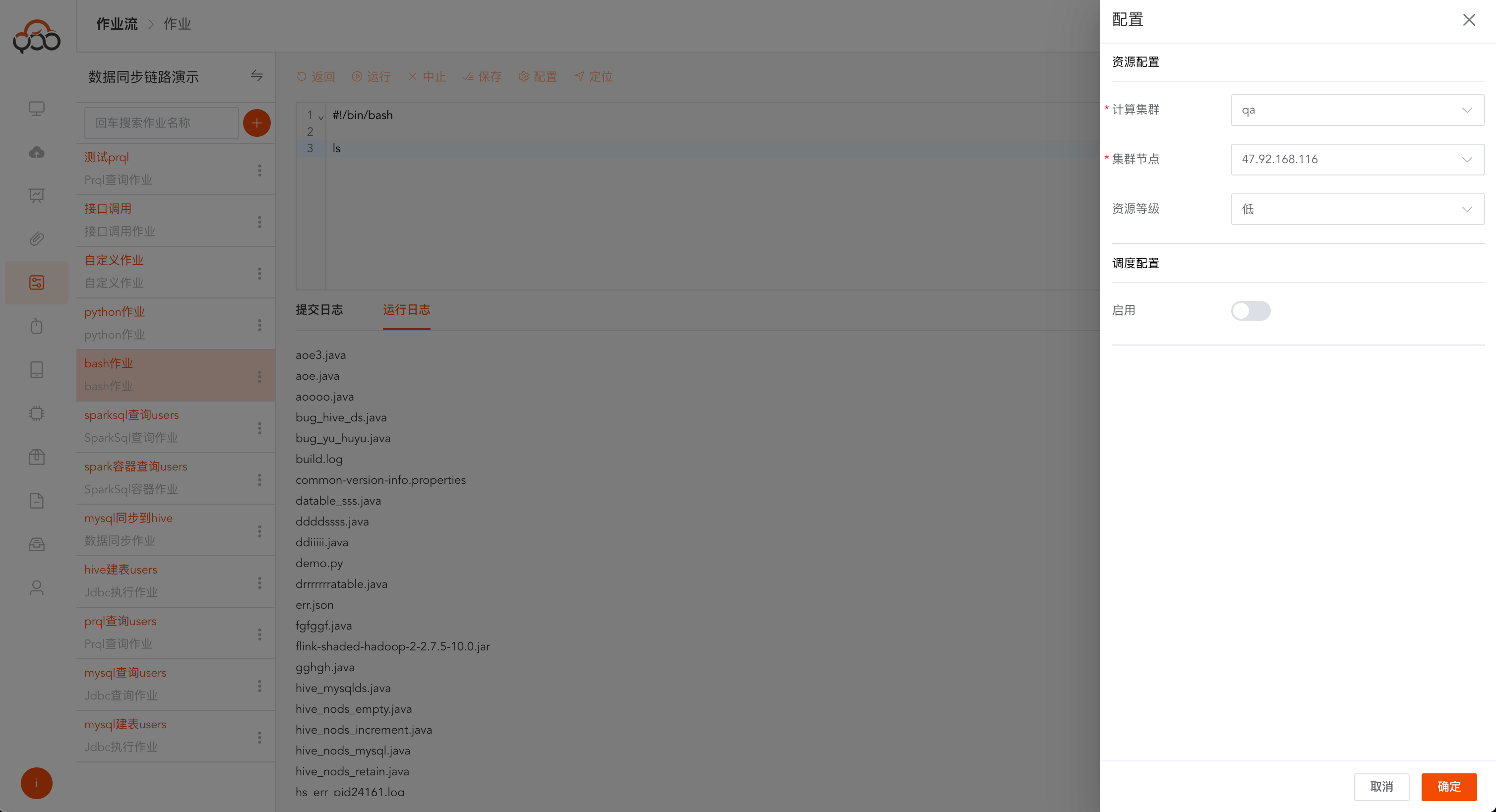
- 计算集群: 必填,选择计算集群中的执行集群
- 集群节点: 必填,选择集群中的某一个节点
- 备注: 非必填
点击运行,运行成功后,日志中返回
执行成功
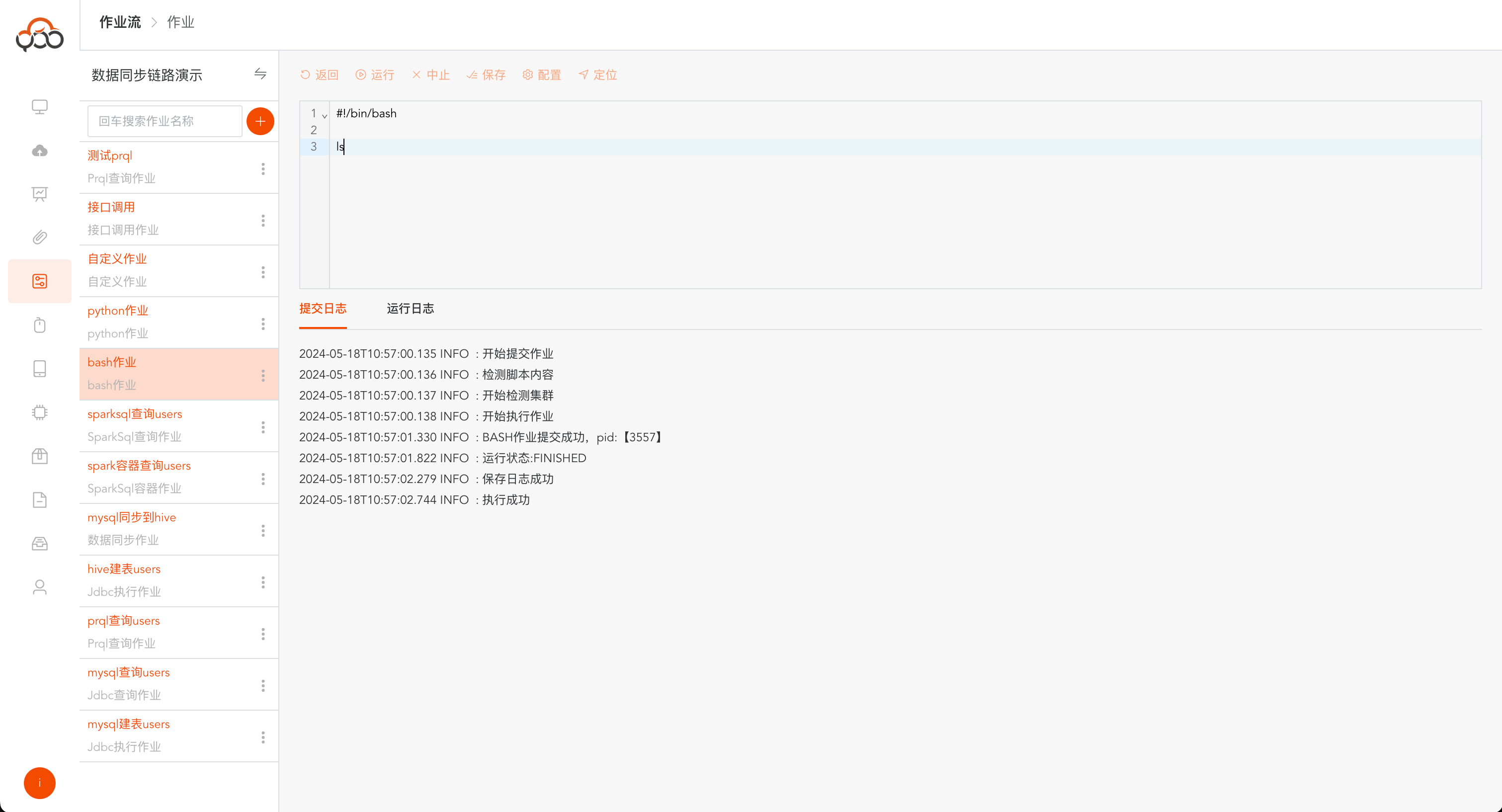
运行成功,点击运行日志,可以查看bash作业打印的内容和运行结果
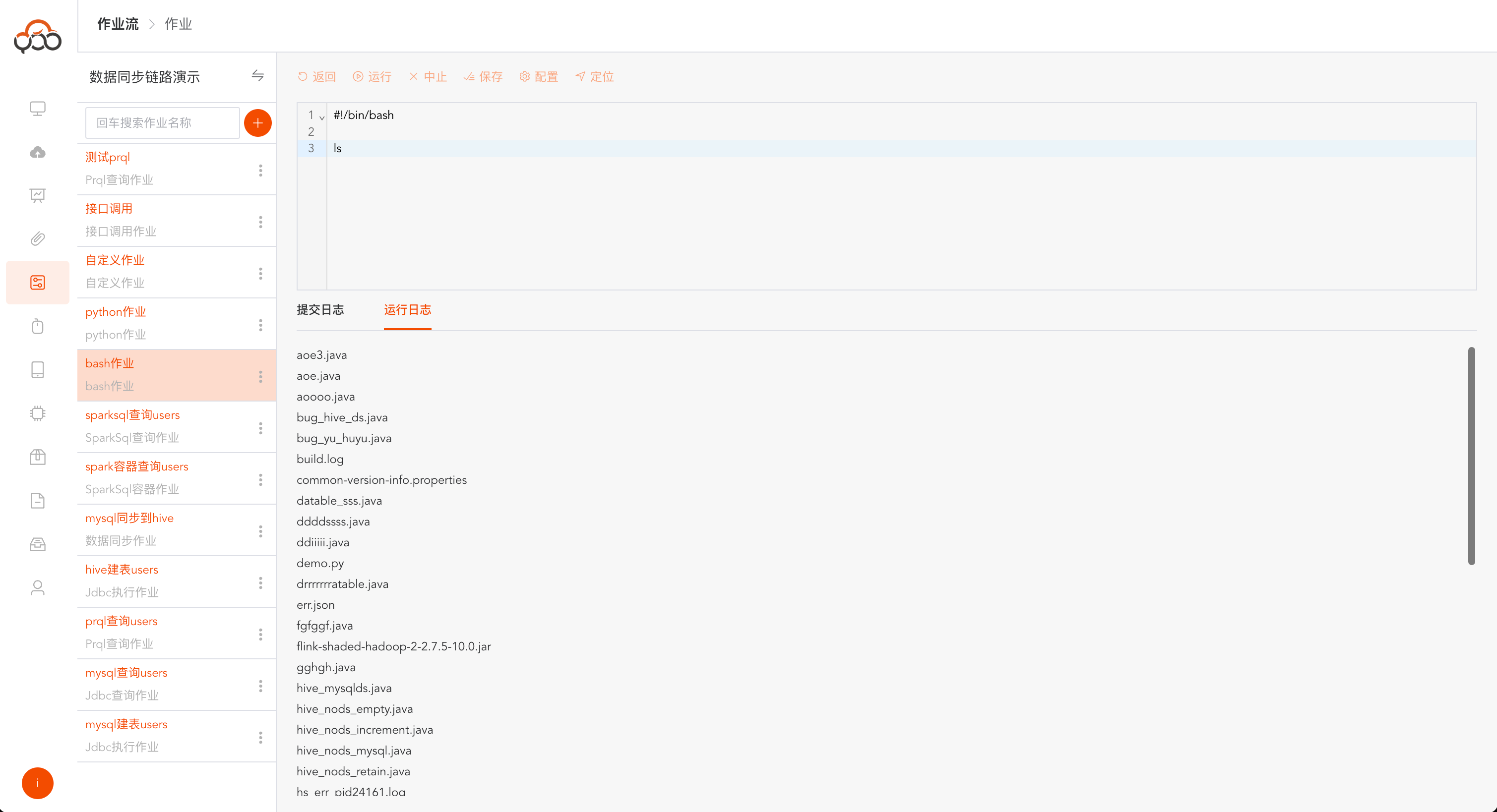
Bash作业支持切换计算集群和集群节点
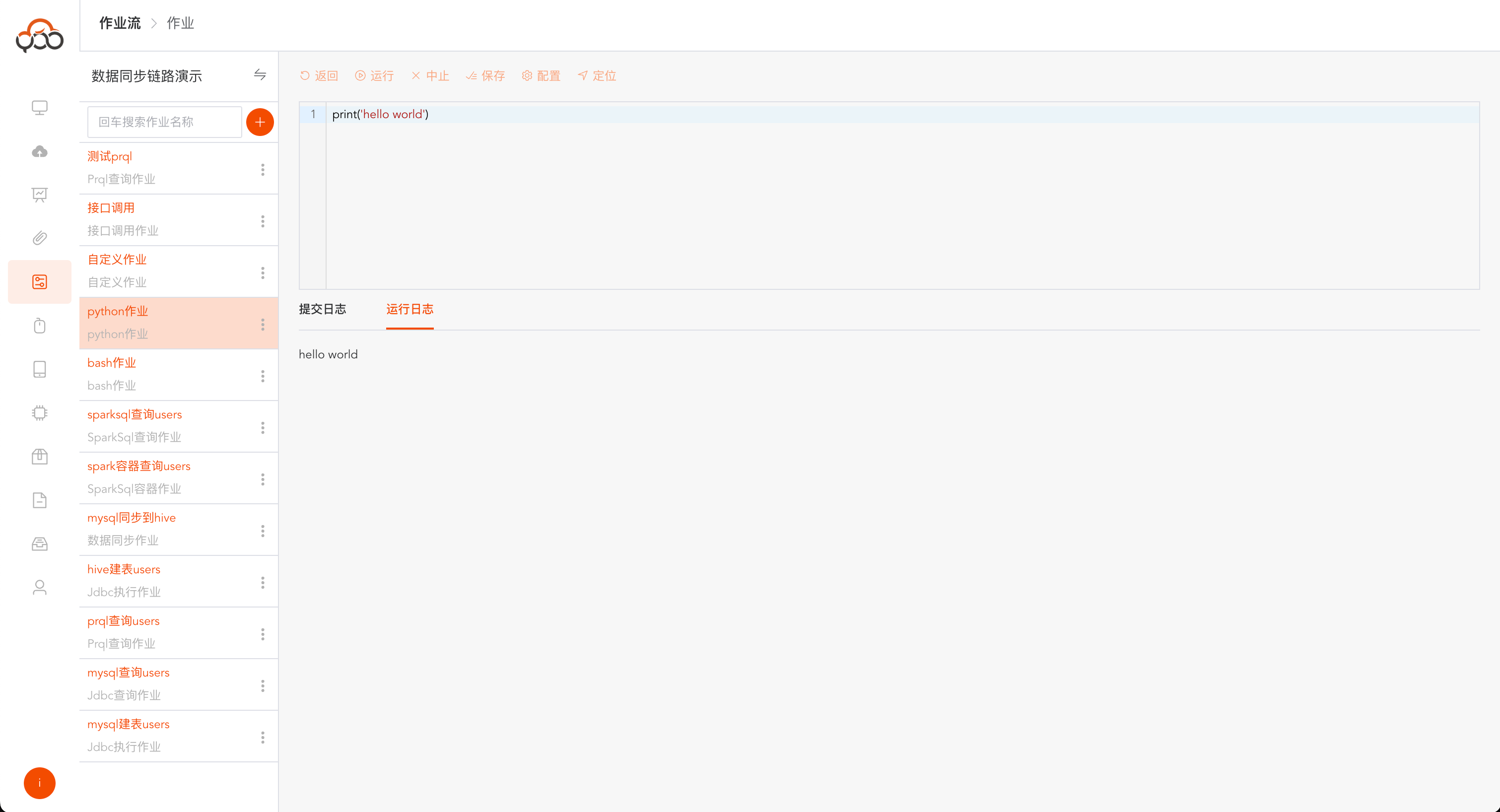
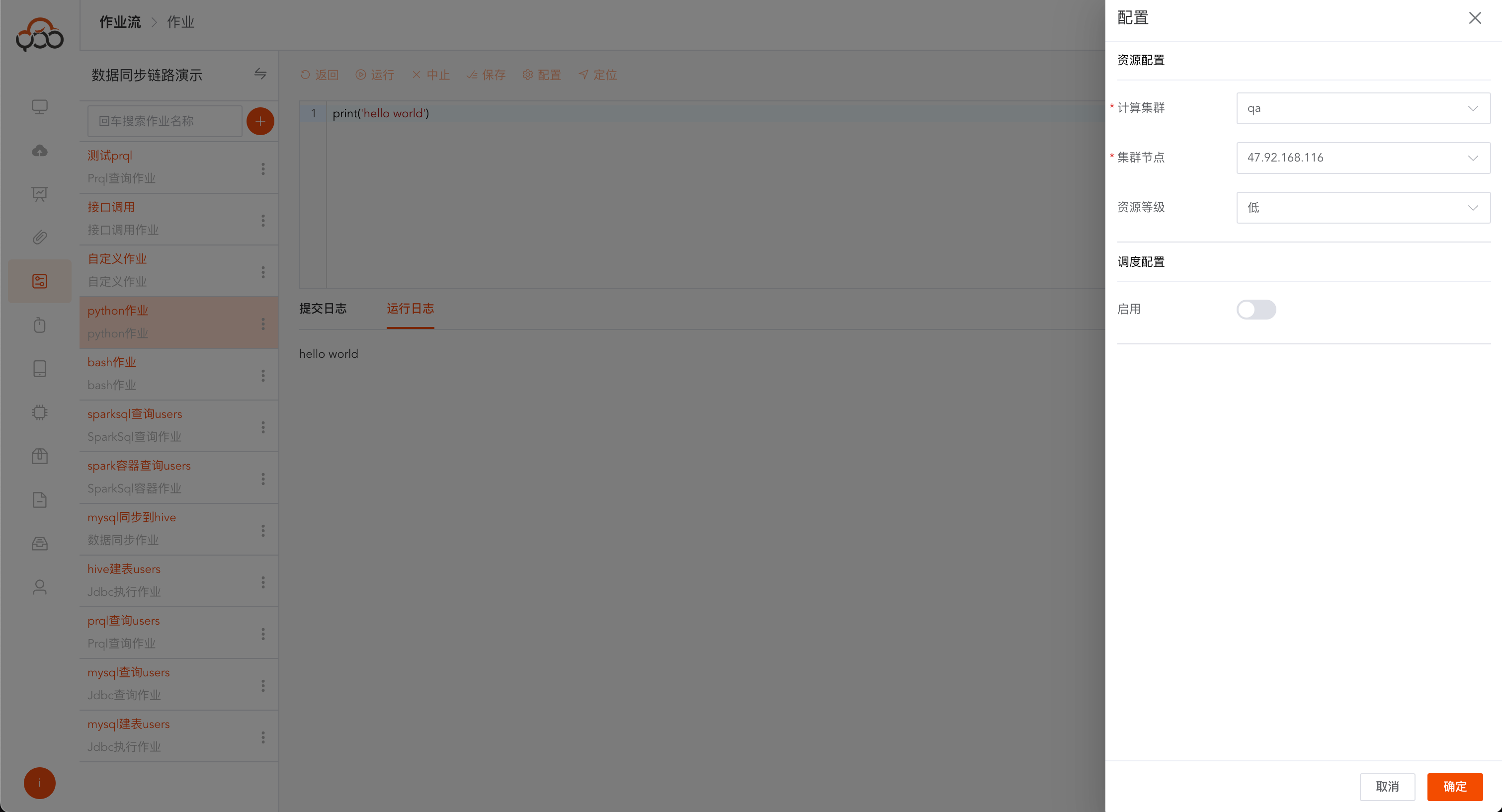
python作业
选择python作业类型
- 名称: 必填,作业流内名称唯一
- 计算集群: 必填,选择计算集群中的执行集群
- 集群节点: 必填,选择集群中的某一个节点
- 备注: 非必填
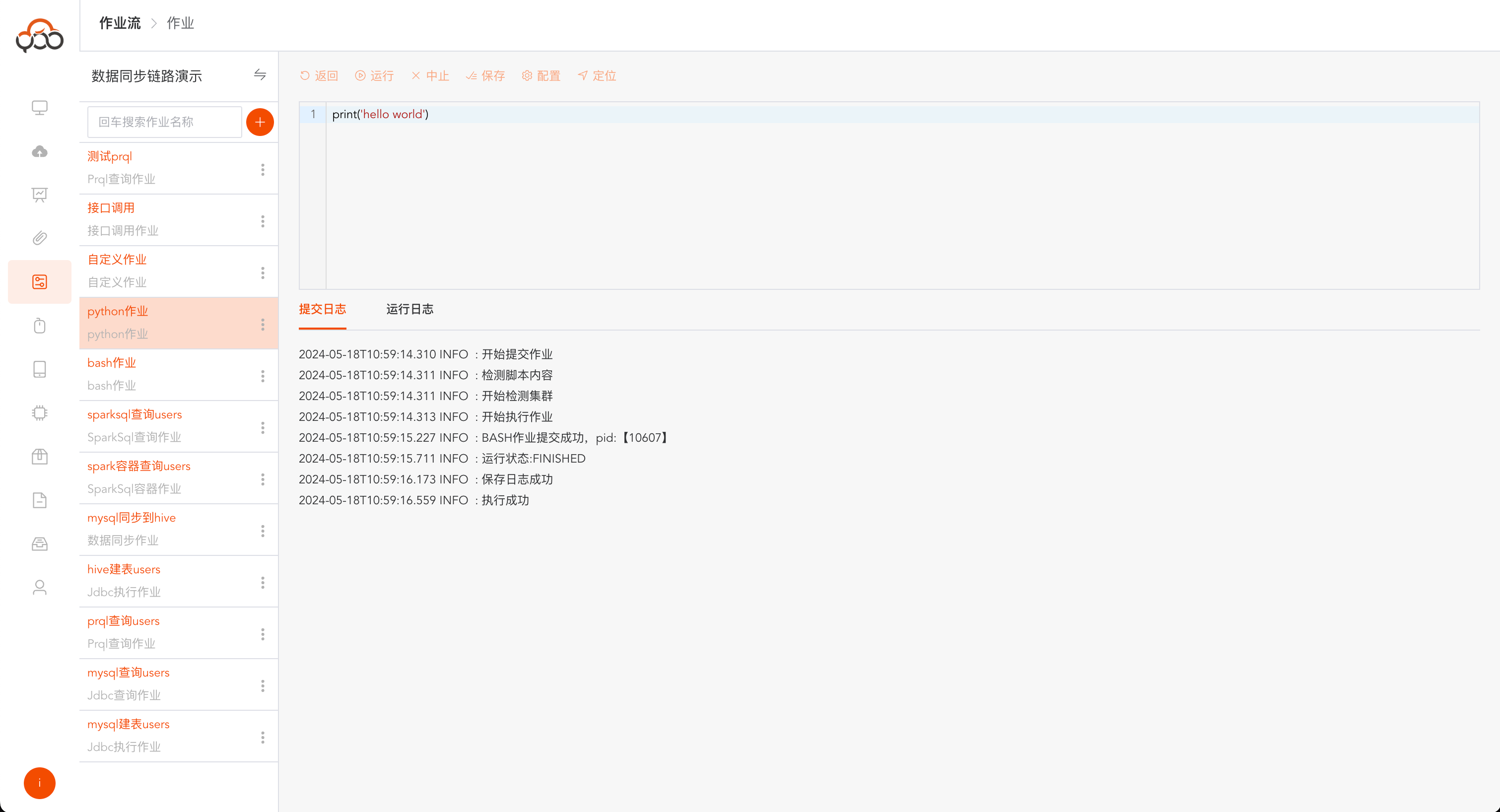
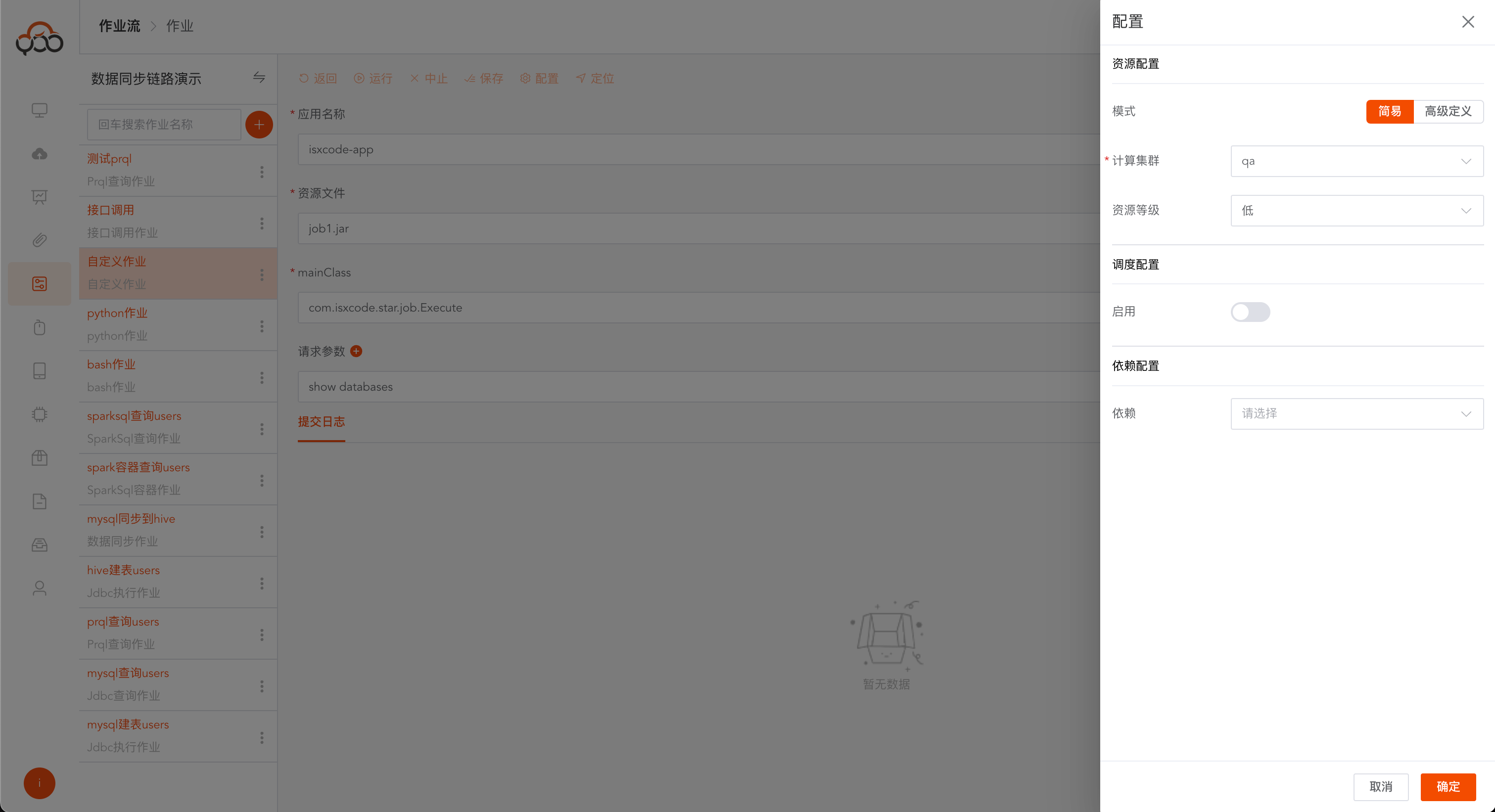
自定义作业
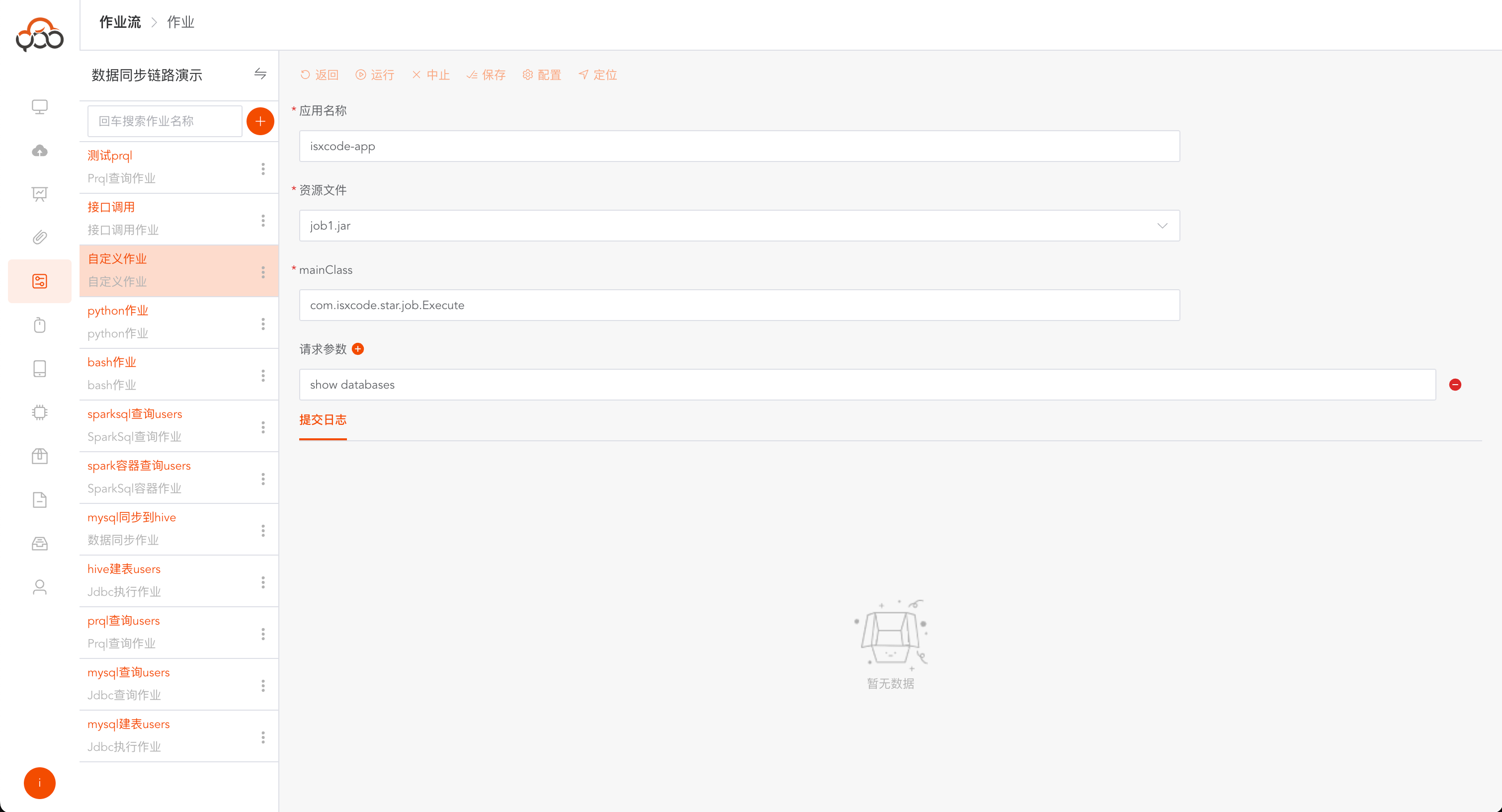
选择自定义作业
- 名称: 必填,作业流内名称唯一
- 计算集群: 必填,指定需要提交作业运行的计算集群
- 备注: 非必填
- 应用名称 : 必填,应用的名称
- 资源文件 : 必填,资源中心上传的自定义Spark作业jar文件
- mainClass : 必填,jar包中启动的入口程序
- 请求参数 : 非必填,jar作业运行所有需要的请求参数
自定义作业支持依赖配置,如果jar中需要包含其他依赖,可通过资源中心上传
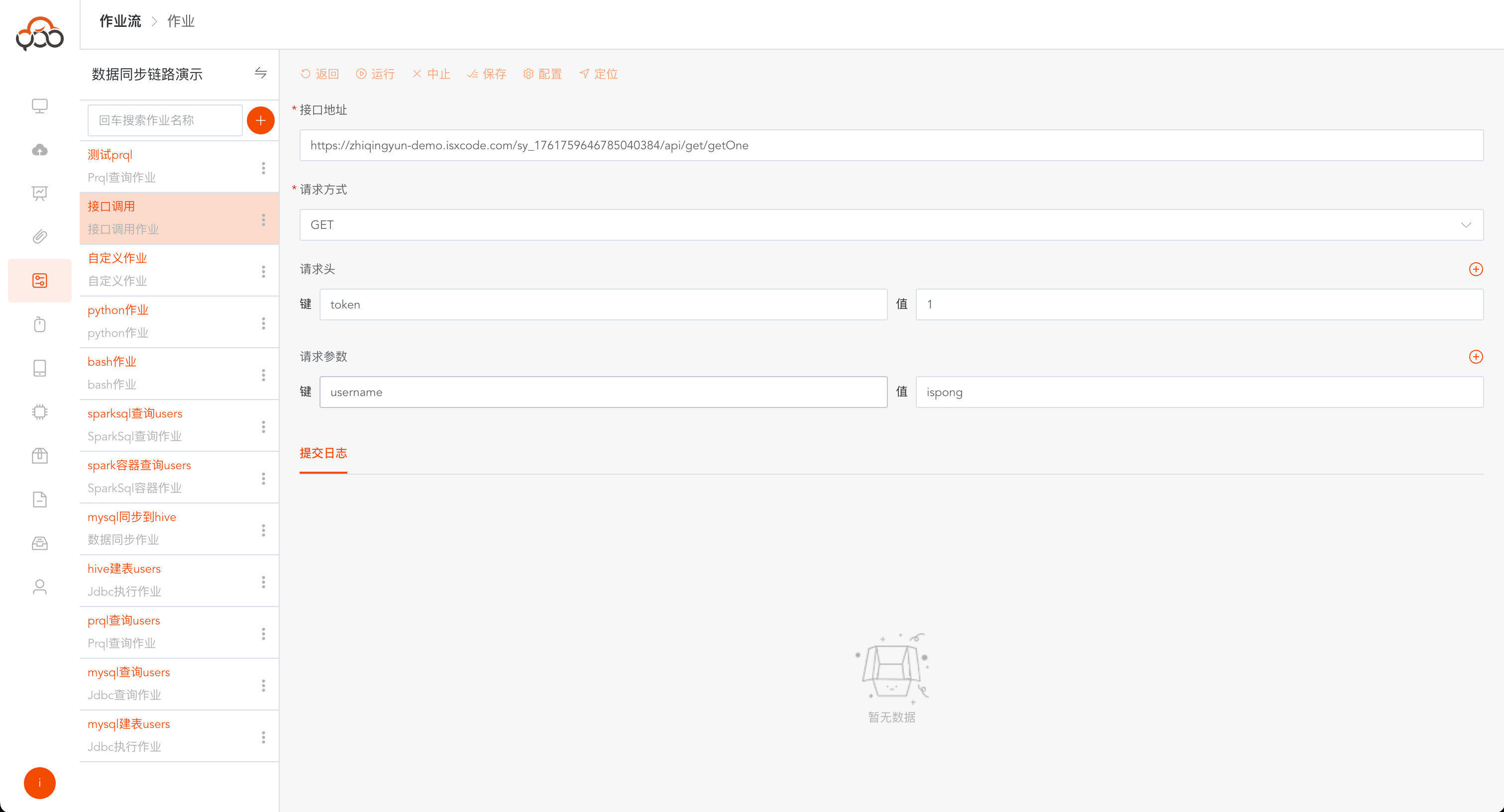
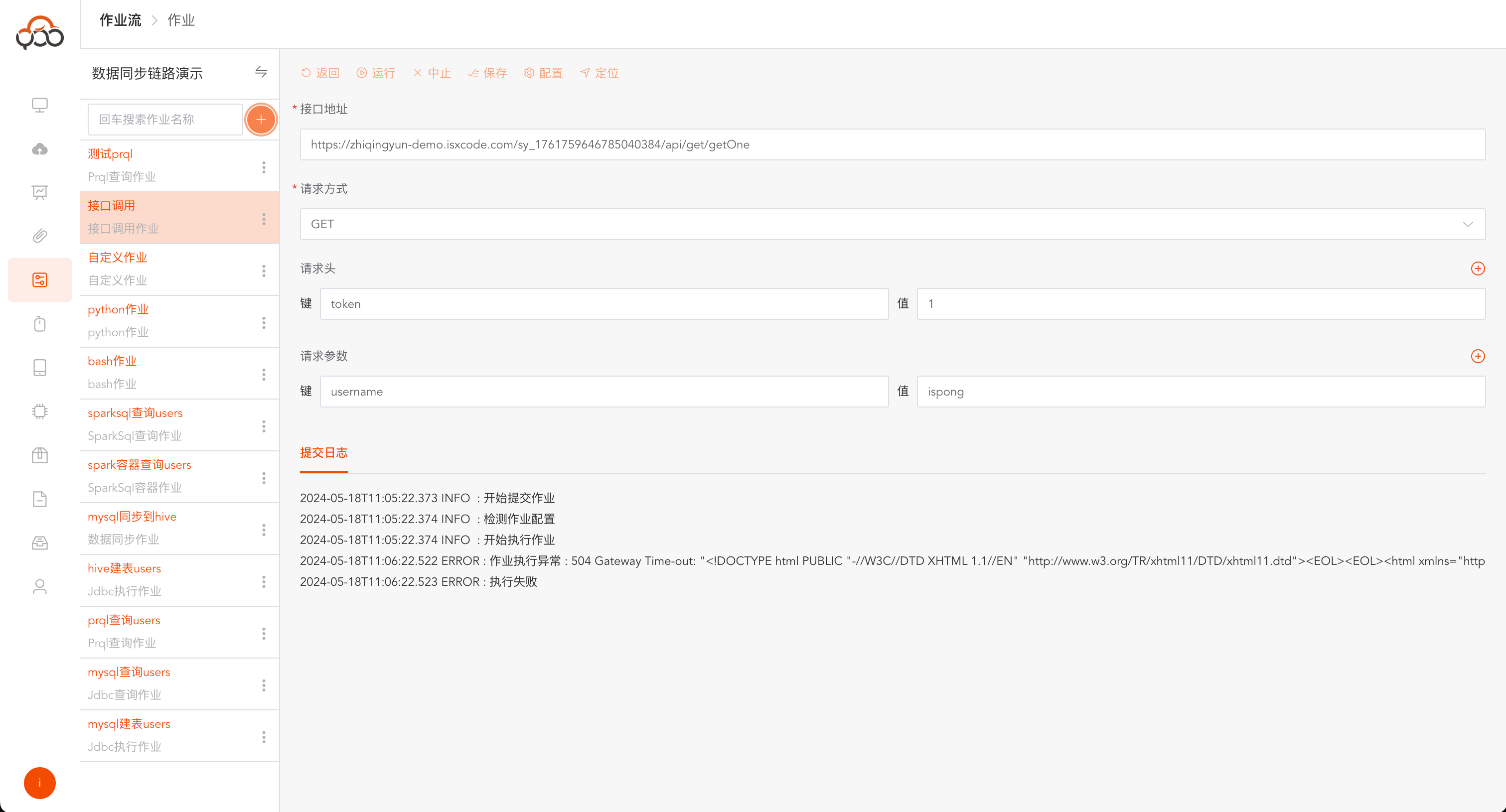
接口调用
可视化接口调用作业
Excel导入作业
选择Excel导入作业
- 名称: 必填,作业流内名称唯一
- 计算集群: 必填,指定需要提交作业运行的计算集群
- 备注: 非必填
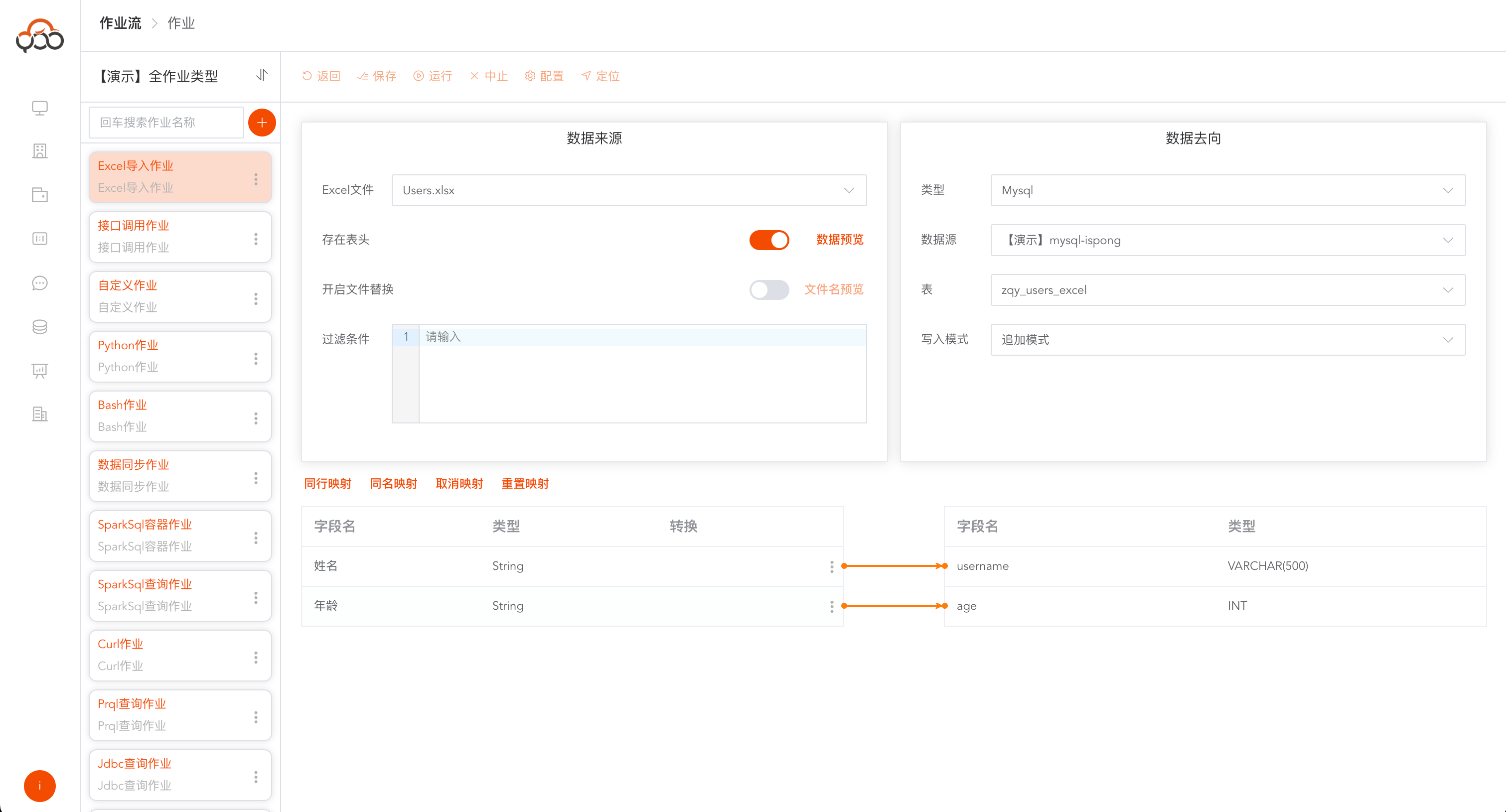
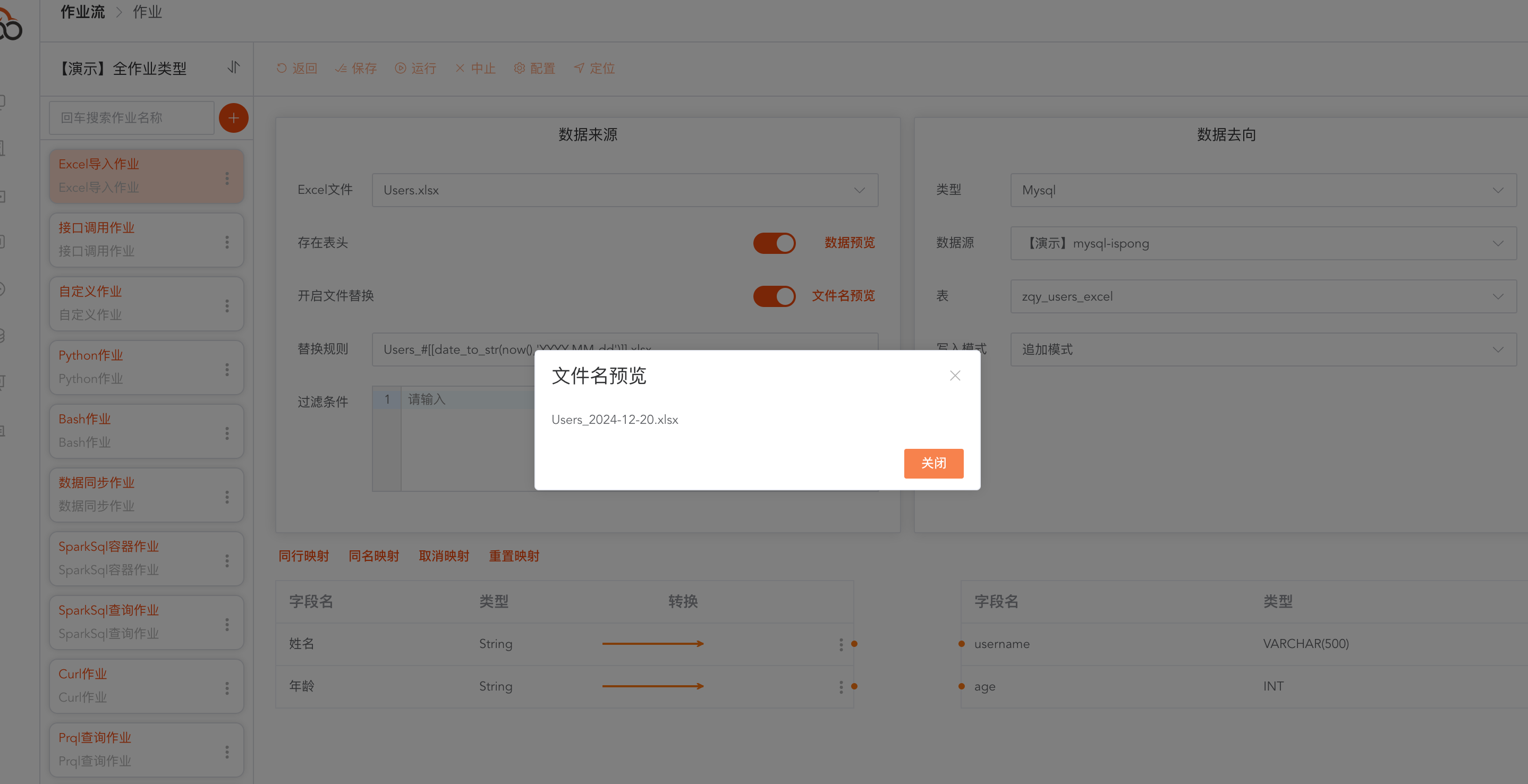
支持文件名替换功能
作业调度的时候会更具文件名称规则,导入资源中心中指定的Excel文件
Users_#[[date_to_str(now(),'YYYY-MM-dd')]].xlsx


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









