






什么是性能测试?
概念
性能测试是模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行的测试。
说明:
峰值:客户指定指标数值或场景需求数值,如:CPU使用率80%以内、登录3秒、内存空间40%等等 负载:用户(一个或多个)向服务器发送请求,负载测试我们1.2节会讲解
性能测试方法是通过模拟生产运行的业务压力量和使用场景组合,测试系统的性能是否满足生产性能要求。通俗地说,这种方法就是要在特定的运行条件下验证系统的能力状态。
特点:
1、这种方法的主要目的是验证系统是否有系统宣称具有的能力。
2、这种方法要事先了解被测试系统经典场景,并具有确定的性能目标。
3、这种方法要求在已经确定的环境下运行。
也就是说,这种方法是对系统性能已经有了解的前提,并对需求有明确的目标,并在已经确定的环境下进行的。
性能测试与功能测试(焦点)
功能测试:验证软件系统操作功能是否符合产品功能需求规格,主要焦点在功能(正向、逆向); 性能测试:验证软件系统是否满足业务需求场景,主要焦点是业务场景的满足度(时间、空间);
说明:
时间:软件的响应时间...
空间:服务器的磁盘读写数率、CPU 使用率、内存空闲率...
功能测试和性能测试是相辅相成的,对于一款优秀的软件产品来讲,它们是测试工作中不可或缺的两个重要环节。
业务需求:
登录不得超过3秒钟,开发一款 Web 电商网站,使用 Java 还是 PHP 呢? OA 办公系统-我们公司20000左右员工需要使用此系统。
解决方案:
负载测试-根据客户实际应用场景模拟测试应用软件、服务器是否满足需求;如果不满足,则定位问题,进行调整直到满足需求;分别使用 Java 和 PHP 写个 Demo,搭建相同的应用场景进行性能测试,找出最优符合应用场景的开发语言;根据二八定律统计出单位时间内(秒)最高请求数。
性能测试分类及常用指标
性能测试是个综合的概述,性能测试指的是测试一种分类或多种分类,任何一具体分类,都是性能测试
一、性能测试常用分类
-
负载测试
-
压力测试
-
并发测试
-
稳定性测试
-
配置测试
-
容量测试
1.1 负载测试 【重点】
通过在被测系统上不断加压,直到性能指标达到极限,例如“响应时间”超过预定指标或某种资源已经达到饱和状态。
特点:
1、这种性能测试方法的主要目的是找到系统处理能力的极限。
2、这种性能测试方法需要在给定的测试环境下进行,通常也需要考虑被测试系统的业务压力量和典型场景、使得测试结果具有业务上的意义。
3、这种性能测试方法一般用来了解系统的性能容量,或是配合性能调优来使用。
也就是说,这种方法是对一个系统持续不段的加压,看你在什么时候已经超出“我的要求”或系统崩溃。
负载测试是通过逐步加压的方式来确定系统的处理能力、确定系统能够承受的各项阀值。 例如:逐步加压,从而得到“响应时间不超过3秒”、“服务器CPU平均利用率低于80%”等指标的阀值。
阀值:关注的某一具体数值(比如:登录小于3秒、用户数2000、业务成功率100%)
1.2 压力测试 【重点】
压力测试方法测试系统在一定饱和状态下,例如cpu、内存在饱和使用情况下,系统能够处理的会话能力,以及系统是否会出现错误
特点:
1、这种性能测试方法的主要目的是检查系统处于压力性能下时,应用的表现。
2、这种性能测试一般通过模拟负载等方法,使得系统的资源使用达到较高的水平。
3、这种性能测试方法一般用于测试系统的稳定性。
也就是说,这种测试是让系统处在很大强度的压力之下,看系统是否稳定,哪里会出问题。
-
压力测试:是逐步增加负载,使系统某些资源达到饱和甚至失效。(如:测试系统最多支持同时处理多少请求,超过此数数量系统瘫痪)
-
负载测试:是逐步增加负载,确定在满足性能指标情况下,系统能承受的最大负载测试。(如:登录3秒内,最多支持多少用户同时登录;如超出此数量,可能需要5秒钟或更多时间才能登录成功)
1.3 并发测试 【重点】
并发测试方法通过模拟用户并发访问,测试多用户并发访问同一个应用、同一个模块或者数据记录时是否存在死锁或其者他性能问题。
特点:
1、这种性能测试方法的主要目的是发现系统中可能隐藏的并发访问时的问题。
2、这种性能测试方法主要关注系统可能存在的并发问题,例如系统中的内存泄漏、线程锁和资源争用方面的问题。
3、这种性能测试方法可以在开发的各个阶段使用需要相关的测试工具的配合和支持。
也就是说,这种测试关注点是多个用户同时(并发)对一个模块或操作进行加压。
1.4 稳定性测试【理解】
给系统加载一定业务压力的情况下,使系统运行一段时间,以此检测系统是否稳定。
特点:
1、这种性能测试方法的主要目的是验证是否支持长期稳定的运行。
2、这种性能测试方法需要在压力下持续一段时间的运行。(2~3天)
3、测试过程中需要关注系统的运行状况。
也就是说,这种测试的关注点是“稳定”,不需要给系统太大的压力,只要系统能够长期处于一个稳定的状态。
通常稳定性测试,我们测试一段时间即可;(如:24小时、3×24小时或7×24小时来模拟长时间运行)
1.5 配置测试
配置测试方法通过对被测系统的软\硬件环境的调整,了解各种不同对系统的性能影响的程度,从而找到系统各项资源的最优分配原则。
特点:
1、这种性能测试方法的主要目的是了解各种不同因素对系统性能影响的程度,从而判断出最值得进行的调优操作。
2、这种性能测试方法一般在对系统性能状况有初步了解后进行。
3、这种性能测试方法一般用于性能调优和规划能力。
也就是说,这种测试关注点是“微调”,通过对软硬件的不段调整,找出这他们的最佳状态,使系统达到一个最强的状态。
二、性能测试常用指标【重要】
一些经过运算得出的结果,用来衡量某种操作性能的统称;比如:错误率0.5%
性能测试常用指标:
-
吞吐量
-
并发数
-
响应时间
-
点击数
-
资源利用率
-
错误率
2.1 吞吐量
吞吐量(Throughput):指的是单位时间内处理的客户端请求数量,直接体现软件系统的性能承载能力。 通常情况下,吞吐量用“请求数/秒”或者“页面数/分钟”来衡量。
从业务角度来看,吞吐量也可以用“业务数/小时”、“业务数/天”、“访问人数/天”、“页面访问量/天”来衡量。 从网络角度来看,还可以用“字节数/小时”、“字节数/天”等来衡量网络的流量。
2.2 并发数
并发(Concurrency):它最简单的描述就是指多个同时发生的业务操作。(例如,100个用户同时单击登录页面的“登录”按钮操作。)
并发性测试描述的是多个客户端同时向服务器发出请求,考察服务器端承受能力的一种性能测试方式。
2.3 响应时间
响应时间指用户从客户端发起一个请求开始,到客户端接收到从服务器端返回结果整个过程所耗费的时间
2.4 点击数
点击数是衡量Web服务器处理能力的一个重要指标。它的统计是客户端向Web服务器发了多少次HTTP请求计算的。
-
点击数不是通常一般人认为的访问一个页面就是1次点击数,点击数是该页面包含的元素(如:图片、链接、框架等)向Web服务器发出的请求数数量。
-
通常我们也用每秒点击次数(Hits per Second)指标来衡量Web服务器的处理能力。
2.5 资源利用率
是指系统各种资源的使用情况,一般用“资源的使用量/总的资源可用量×100%”形成资源利用率的数据。
通常,没有特殊需求的话:
-
建议CPU使用率不高于80%(±5);
-
内存使用率不高于80%;
-
磁盘读写时间比不高于90%。
2.6 错误率
错误率指系统在负载情况下,失败交易的概率。错误率=(失败交易数/交易总数)*100%。
-
不同系统对错误率要求不同,但一般不超过千分之五;
-
稳定性较好的系统,其错误率应该由超时引起,即为超时率。
三、性能常用测试工具
-
Jmeter
-
LoadRunner【本阶段学习】
性能测试的工具有很多,目前最常用就是这两款,我们作为性能测试初期入门掌握这两款工具足矣!
3.1 Jmeter
Apache 公司使用 Java 平台开发的一款测试工具
作用:性能测试、接口测试、Web测试(无GUI,GUI:graphical user interface) 优点:免费、开源、小巧
3.2 LoadRunner
HP公司使用C语言开发的一款性能负载测试工具
作用:模拟高并发负载测试、测试场景搭建、运行、监控及结果分析 优点:支持多协议、自带强大的图表功能、可根据需求合并需要的图表 缺点:收费
3.3 Jmeter 和 LoadRunner 的简单对比
Jmeter:接口测试及接口性能压测首选
LoadRunner:Web性能测试首选
性能测试流程
流程
1. 性能测试需求分析 2. 性能测试计划 3. 性能测试用例 4. 测试脚本编写 5. 测试场景设计 6. 测试场景运行 7. 场景运行监控 8. 运行结果分析 9. 系统性能调优 10. 性能测试报告总结
1 性能测试需求分析
需求分析就是把真正需求搞清楚
例如: 1). 公司需要对所有的功能都进行性能测试; 2). 用户登录响应时间小于3秒钟; 3). 系统支持20万用户并发访问;
2 性能测试计划
1). 性能测试计划是对性能测试过程描述的重要过程; 2). 在对需求文档经过认真分析后,作为性能测试管理人员,需要编写的第一份文档就是性能测试计划; 3). 性能测试计划中,需要阐述产品、项目的背景,将前期的需要测试性能需求明确,并落实到文档中。
3 性能测试用例
性能测试需求最终要体现在性能测试用例设计中,性能测试用例应结合用户应用系统的场景,设计出相应的性能测试用例,用例应能覆盖到测试需求。
提示: 1). 明确哪些功能业务量较大; 2). 明确系统预期的用户规模、并发用户数、在线用户数; 3). 明确系统业务的处理能力要求,如:TPS、响应时间、系统资源利用率等; TPS :(Transaction per second)事务数/秒 4). 详细的操作步骤及场景的搭建模式
4 测试脚本编写
性能测试用例编写完成以后,接下来就需要结合用例的需要,进行测试脚本的编写工作。
注意: 1). 协议的正确选用; 2). 脚本保证其正确性,去除冗余代码; 3). 注重编码的规范和代码的编写质量。
5 测试场景设计
测试场景设计的一个重要原则就是依据测试用例,把测试用例设计的场景展现出来。
提示: 1). 虚拟用户数量及启动虚拟用户方式 2). 场景的相关设置(如:集合点) 3). 脚本是否存在依赖关系(登录与注册)
6 测试场景运行
测试场景运行是关系到测试结果是否准确的一个重要过程。
注意: 1). 负载的测试机是否能够运行设定的虚拟用户数; 2). 有没有“预热”的过程; 3). 有没有模拟用户的真实环境; 4). 性能用例运行次数是否过少。
7 场景运行监控
场景运行监控,可以在场景运行时决定要监控那些数据,便于后期分析性能测试结果。
1). 应用性能测试工具的重要目的就是可以提取到本次测试关心的数据指标内容; 2). 性能测试工具利用应用服务器取得在负载过程中相关计数器的性能指标。 (计数器:计算、统计性能指标的工具)
注意:尽量搜集与系统测试目标相关信息,无关内容不必进行监控。
8 运行结果分析
性能测试执行过程中,性能测试工具搜集相关性能测试数据,待执行完成后,这些数据会存储到数据表或者 其他文件中,为了定位系统性能问题,我们需要系统分析这些性能测试结果。
提示: 1). 一般使用“拐点分析”方法,利用性能计数器曲线图上的拐点进行分析的方法。 (基本思想就是性能产生瓶颈的主要原因就是因为某个资源的使用达到了极限,此时表现为随着压力的增大,系统性能却出现急剧下降,就产生了“拐点”现象。)
9 系统性能调优
性能测试分析人员经过对结果的分析以后,有可能提出系统存在性能瓶颈。
提示: 1). 调优人员(开发人员、数据库管理员、系统管理员、网络管理员、性能测试分析人员)相关人员对系统进行调整; 2). 验证-性能测试人员继续进行第二轮、第三轮...的测试,与以前的测试结果进行对比,从而确定经过调整以后的系统性能是否有提升。
注意事项:
系统调优由易到难的先后顺序如下: 1. 硬件问题; 2. 网络问题; 3. 应用服务器、数据库等配置问题; 4. 源代码、数据库脚本问题; 5. 系统架构问题。
10 性能测试报告总结
性能测试总结要包含以下内容:
1). 性能测试需求覆盖情况,性能测试过程中出现的问题,如何去分析、调优、解决的;
2). 测试人员、进度控制与实际执行偏差和性能测试过程中遇到各类风险是如何控制的;
3). 经过该项目性能测试后,有那些经验和教训等内容。
LoadRunner介绍
一、LoadRunner简介
LoadRunner是一种工业级标准的性能负载测试工具;可以模拟上千万用户实施测试,并在测试时可实时检测应用服务器及服务器硬件的各种数据,来查找和确认存在的性能瓶颈;
支持多种协议,如:Web(HTTP/HTML)、Windows Sockets、FTP、ODBC、MS SQL Server等协议
二、LoadRunner组成【非常重要】
组成:
1. Virtual User Generator(VuGen)
2. Controller
3. Analysis
提示:
1. VuGen:脚本生成器-脚本录制、编辑
2. Controller:控制器-设计场景、运行、监控
3. Analysis:测试结果分析
三、 理解LoadRunner的三大工具(扩展)
为了更好的理解LoadRunner性能测试三大工具作用,我们先回顾下不使用测试工具时,如果进行性能测试...
需求:
软件系统支持100人同时登录
实施:
1. 找100个员工及100台电脑,每个员工注册账号OK,环境OK,输入账号、密码完成...鼠标放到登录按钮上;
2. 领导拿个大喇叭,高喊:1...2...3
3. 相关人员统计平均登录时间及登录前、登陆后的服务器CPU、内存等使用情况
LoadRunner的执行原理:【重点】
1. VuGen:相当于打开登录页面、输入账号、输入密码、点击登录
2. Controller:手拿大喇叭的领导...
3. Analysis:相当与各个统计数据的相关人员

VuGen操作
一、VuGen介绍
VuGen(Virtual User Generator)录制客户端和服务器之间的相关交互活动,它将自动生成相关模拟 实际情况的API(Application Programming Interface)函数。
提示: 1. LR录制脚本功能由于兼容性问题,非常不好使,所以我们平时在工作中也不建议使用录制的方式; 2. 由于兼容性问题和录制会产生多余的操作,因此一般都是手写脚本; 3. 为了更好的学习VuGen,我们基于LR11自带的订票系统为案例,练习使用VuGen。
案例1
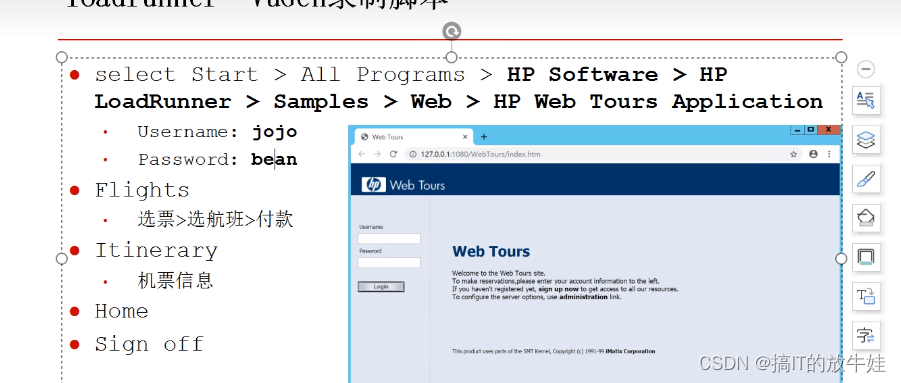
需求:1. 录制机票网站的登录、退出脚本 使用: 1. 启动网站服务程序 2. 访问地址:Dotdash Meredith - America's Largest Digital & Print Publisher 3. 登录账户:用户名:15788888888 密码:123456
【案例】-启动服务程序

启动成功界面
二、案例1-实施步骤分析
1. 启动VuGen 2. 创建脚本 3. 选择录制协议 Web(HTTP/HTML)【重要】 4. 录制设置 5. 脚本录制 6. 运行脚本

2.1 启动VuGen
双击运行VuGen图标启动

2.2 创建脚本

2.3 选择协议
1. New Single Protocol Script: 单一协议 2. Popular Protocols: 主流协议 3. Web(HTTP/HTML): HTTP协议【选择】




2.4 录制设置


 重点:区别
重点:区别
上个接口返回需要作为下个接口的入参,需要关联使用 正则函数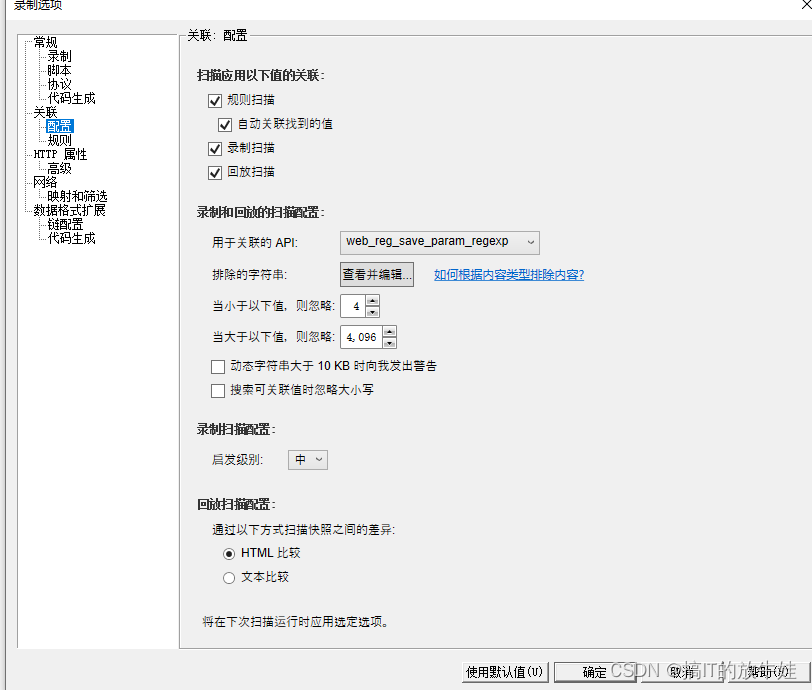
设置字符集utf-8

2.5 脚本录制
自带的项目

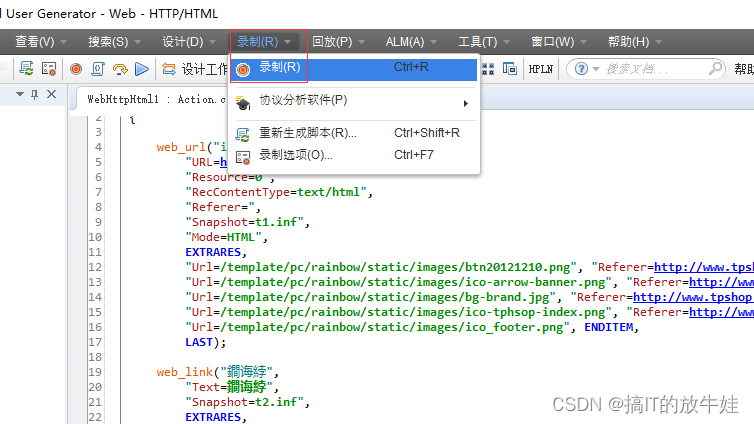

开启fiddler,开始录制


登录插入事务,退出登录开插入事务
停止录制

生成脚本



2.6 运行(回放)脚本
验证录制脚本是否能正常运行
1. 点击 Run 按钮 2. 快捷键:F5键
VuGen-扩展(录制、回放)
一、录制选项-扩展

1.1 录制设置Options选项


-
HTML-based script: 所有请求放到一个函数内(这里所有请求是指,每步操作所产生的请求)
-
URL-based script: 每个请求放到一个函数
提示:
1). 基于浏览器的应用程序推荐使用 HTML-based script
2). 不是基于浏览器的应用程序推荐使用 URL-based script
3). 基于浏览器的应用程序中使用了 HTTPS 安全协议,使用 URL-based script 方式录制
1.2 HTML Advanced选项

1. web_submit_form: 依赖上下文才能提交。 2. web_submit_data: 不依赖上下文,每个函数都指定了具体的 URL 地址,可以直接提交成功。【推荐】 提示:没有特殊的场景需求,推荐使用:web_submit_data
二、运行设置

Run-time Settings (菜单-Vuser -> Run-time Settings) 快捷键:F4
2.1 Run-time Settings

1. Run Logic 脚本运行迭代次数 2. Think Time 运行时思考时间处理方式
1. Run Logic 迭代次数
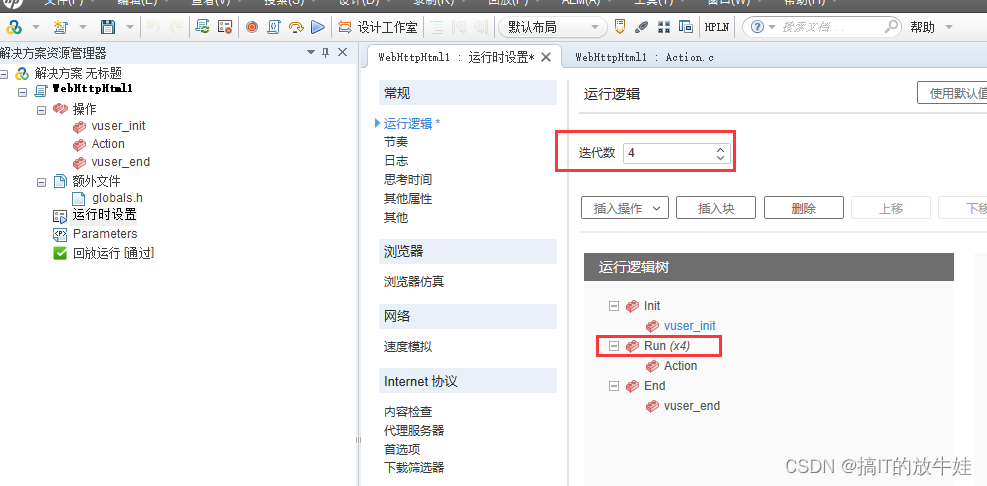
提示: 1. 迭代就是脚本要执行的次数 2. Init 与 End 由于只会运行一次,迭代次数设置不会生效
pacing 迭代的等待时间


log 日志


2. Think Time 思考时间


提示: 1. Ignore think time 默认(忽略思考时间) 2. Replay think time (回放思考时间) 1). As recorded (录制多少秒,就等待多少秒) 2). MuItiply recorded think time by (录制时间的倍数) 3). Use random percentage of recorded think time ( Min(录制时间的最小百分比) Max(录制时间的最大百分比)) 4). Limit think time to(限制最高时间)
浏览器选择
网速设置

重点 首选项
检查文字
设置HTTP连接时间
 解决中文乱码
解决中文乱码

2.1扩展 编译

C语言属于高级语言,不能直接被计算机识别,需要进行编译成计算机可执行语言,在编译的时候如果脚本语法有错,会直接提示。 使用:点击编译图标或使用快捷键:Shift + F5
提示:
编译提示:No errors detected 代表通过;
三、回放操作
双击操作

右键操作

测试结果

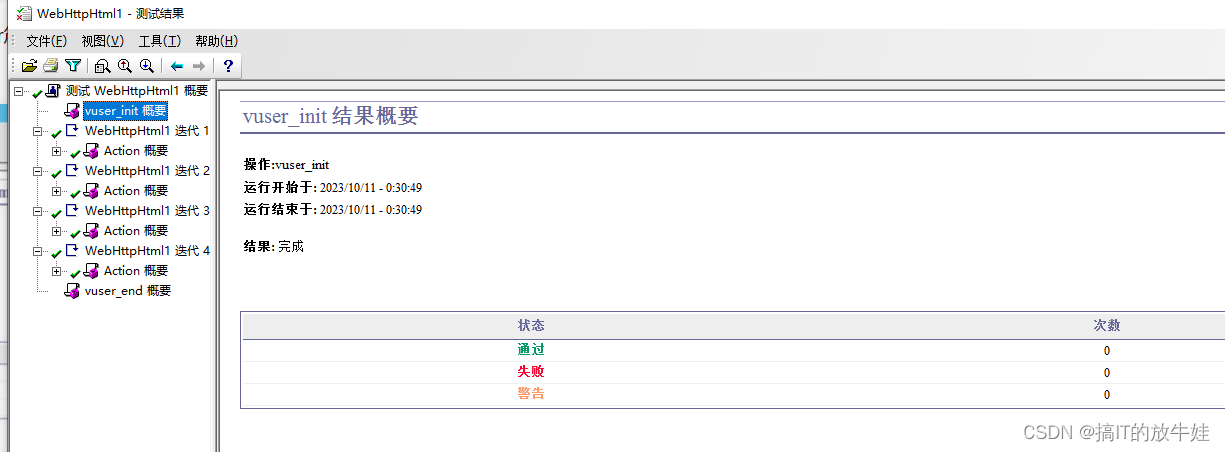


认识函数

1、web_url
web_url("login.html", "URL=http://www.tpshop.com/index.php/Home/user/login.html", "Resource=0", "RecContentType=text/html", "Referer=", "Snapshot=t15.inf", "Mode=HTML", LAST);

2、lr_start_transaction
lr_end_transaction("1_transaction——",LR_AUTO);
lr_start_transaction("1_transaction_推出登录");
3、web_submit_from()

4、web_submit_data()
web_submit_data("index.php",
"Action=http://www.tpshop.com/index.php?m=Home&c=User&a=do_login&t=0.7869850391835205",
"Method=POST",
"RecContentType=text/html",
"Referer=http://www.tpshop.com/index.php/Home/user/login.html",
"Snapshot=t16.inf",
"Mode=HTML",
ITEMDATA,
"Name=username", "Value=15708460952", ENDITEM,
"Name=password", "Value=123456", ENDITEM,
"Name=verify_code", "Value=8888", ENDITEM,
LAST);
5、web_image()

6、lr_think_time(96)

VuGen-参数化
一、什么是参数化
根据需求动态的获取数据的过程
二、为什么要参数化?
-
减少重复代码
-
数据代码进行分离,方便维护
需求1
说明:由于虚拟机运行速度原因,我们使用 lr_output_message() 函数,来学习如何使用参数化 要求:输出 我要去北京;我要去上海;我要去广州;我要去深圳;
三、参数化操作
3.1 打开参数化菜单

选中要参数化的文本 -> 鼠标右键 -> Replace with a Parameter 或者 菜单 Insert -> New Parameter...
方法一:
方法二:


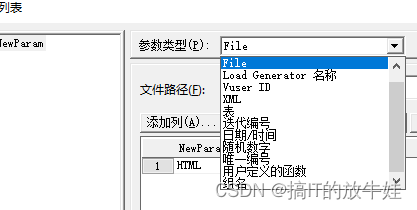



3.2 Custom 普通常规参数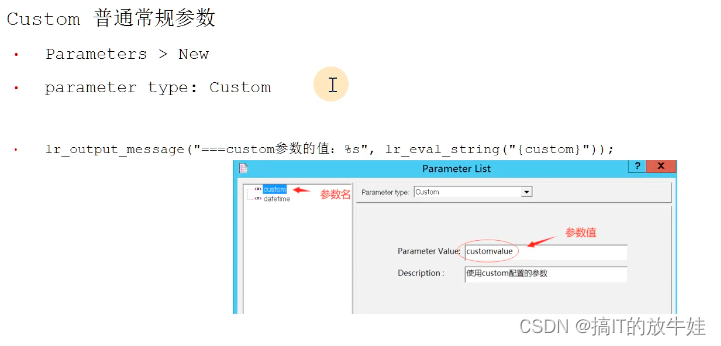

设置参数

使用
Action()
{
lr_output_message("===custom参数的值:%s",lr_eval_string("{custom}));
return 0;
}
3.3 Date/Time 日期/时间型参数

设置(可以选择时间格式)

使用
Action()
{
lr_output_message("===datetime参数的值:%s",lr_eval_string("{mydatetime}));
return 0;
}
3.4 Group Name 用户所属组

设置

使用
Action()
{
lr_output_message("===groupname参数的值:%s",lr_eval_string("{groupname}));
return 0;
}
3.5 Iteration Number 迭代编号(常用)

设置

使用
Action()
{
lr_output_message("===iternum参数的值:%s",lr_eval_string("{iternum}));
return 0;
}
设置迭代次数

3.6 Load Generator Name 控制器名称

设置

使用
Action()
{
lr_output_message("===loadgener参数的值:%s",lr_eval_string("{loadgener}));
return 0;
}
3.6 Random Number 随机数字 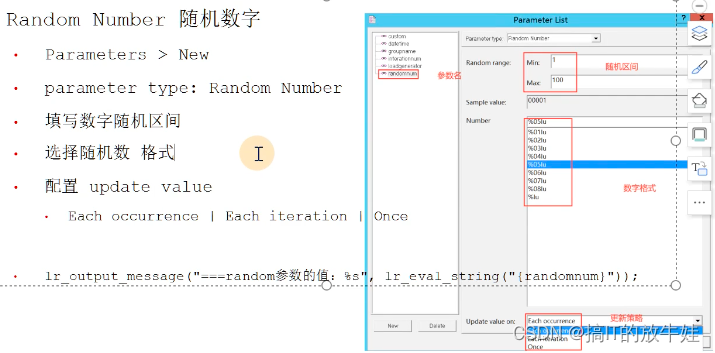
设置(手机号码)

使用
Action()
{
lr_output_message("===randimnum参数的值:%s",lr_eval_string("{randphone}));
return 0;
}


3.7 Unique Number 唯一值
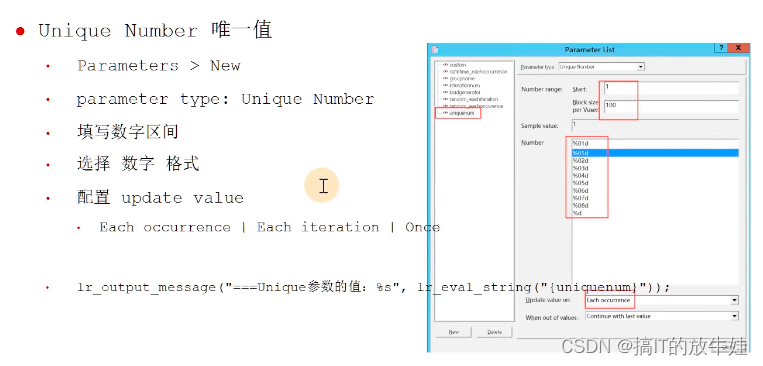
设置
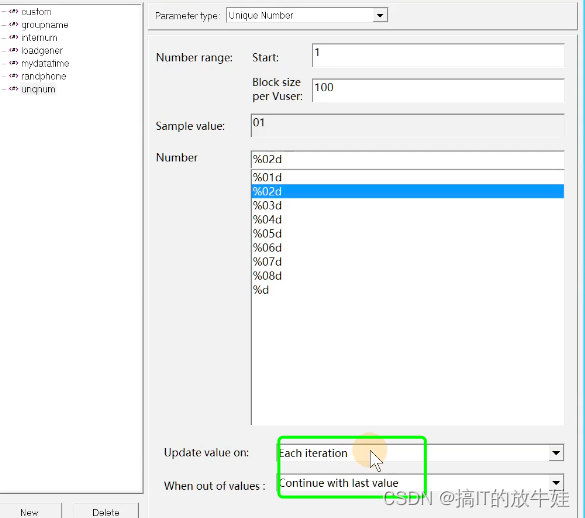
使用
Action()
{
lr_output_message("===unqnum参数的值:%s",lr_eval_string("{unqnum}));
return 0;
}
3.8 VuserID 用户ID

设置
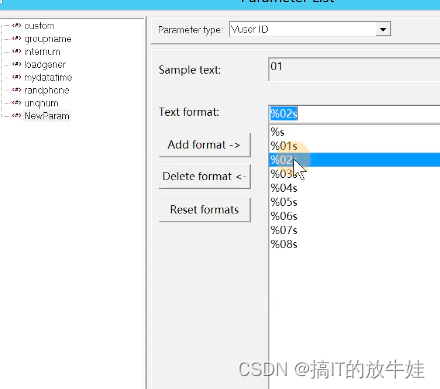
使用
VuGen-关联
一、为什么要学习关联?
1. 获取动态加载的数据,例如:Session ID(会话ID) 2. 测试的时候需要获取页面上指定的数据,注意是获取,而不是查找 说明: Session ID:客户端与服务器交互时,服务器生成的一个唯一标识码; (通过标识码服务器可以区分多次交互对象是否同一客户端,浏览器只要不关闭标识码就不变)
二、什么是关联(correlation)?

动态获取指定的数据,并把获取的数据通过参数化的方式在另一处引用
三、LoadRunner 常用的关联方式
手动关联【推荐】
自动关联【了解】


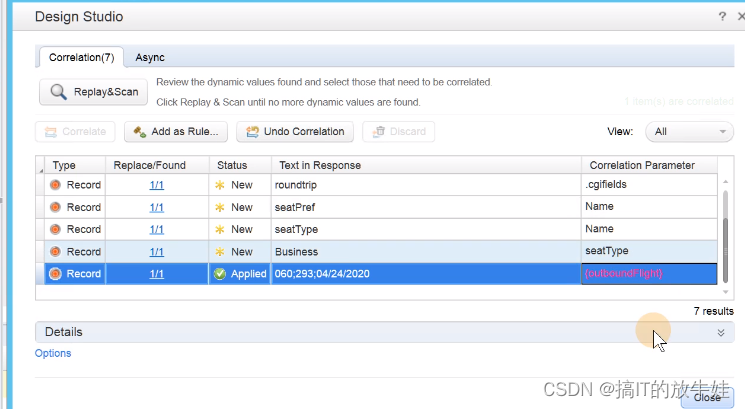
3.1 手动关联【重点】
手动关联就是直接调用关联函数;
关联函数 web_reg_save_param()

1). 执行顺序:LR中函数内含reg为注册函数,注册函数是在下一个Action Function完成时执行。
2). 函数位置:注册函数【必须】放到下一个Action Function(要进行关联数据所在的函数)函数之前;
3). 如果关联的参数值超过256个字符,需要先调用 web_set_max_html_param_len("1024") 改变参数长度;

VuGen-函数详解
一、常见函数类型

二、标准C函数

三、loadrunner标准C函数类型
字符串操作函数
缓冲区操作函数
过程控制函数
内存分配函数
数学函数
输入输出函数
文件操作函数
日期时间函数
数据类型转换函数字符分类和转换函数
3.1 loadrunner标准C函数——字符串操作函数
strcat\strncat 拼接
strcmp\strncmp 比较
strcpy\strncpy 拷贝
strlen 长度
strlwr\strupr 转换小写\大写strset 用什么填充
strstr 字符串出现的位置
3.2 loadrunner标准C函数——缓冲区操作函数
memchr
memcmp
memcpy
memmove
memset
3.3 loadrunner标准C函数——过程控制函数
getenv 获取环境变量
putenv 向环境变量中插入
system 执行系统命令
3.4 loadrunner标准C函数——内存分配函数
calloc
free
malloc
realloc
3.5 loadrunner标准C函数——数学函数
abs
cos\sin
floor 积分
rand\srand
sqrt
3.6 loadrunner标准C函数——输入输出函数
fread \ fopen \ fwrite \ fclose
fprintf \ fscanf
sprintf \ sscanf
fgets \ fgetc \ fputc
3.7 loadrunner标准C函数——文件操作函数
chdir
getcwd
mkdir \ rmdir
remove
3.8 loadrunner标准C函数——日期时间函数
time
ctime \ ftime
localtime
gmtime
strftime
3.9 loadrunner标准C函数——数据类型转换函数 (重点)
atof 字符串转换成浮点数
atoi 字符串转换成整型
atol 字符串转换成长整型
itoa 整型转换成字符串
3.10 loadrunner标准C函数——字符分类和转换函数
tolower
toupper
isdigit 是否为十进制
isalpha 是否为字母
四、loadrunner脚本lr 函数
Utility Functions and c language Reference > Utility Functions: c Language (Ir )
命令行解析函数
数据库函数
信息函数
消息函数
运行时函数
宁符串与参数 函数
事务函数
xml函数
4.1 loadrunner标准lr 函数——命令行解析函数
Ir_get_attrib_double
Ir_get_attrib_long
Ir_get_attrib_string
4.2 loadrunner标准lr函数——数据库函数
Ir db connect 建立连接
Ir db disconnect 断开连接
Ir db executesQLstatement 执行sql脚本
Ir db dataset action 处理请求数据
Ir db getvalue 获取值
4.3 loadrunner标准lr函数——信息函数
Ir_start_timer \ Ir end timer
lr_whoami
lr_get_host_name \ Ir_get_master_host_nameIr_get_vuser_ip
4.4 loadrunner标准lr 函数——消息函数
Ir_log_message \ Ir_output_message \ lr_message
Ir_debug_message
Ir_get_debug_message \ lr_set_debug_message
Ir_error_message
Ir_set_custom_error_message
Ir_remove_custom_error_message
Ir_vuser_status_message
4.5 loadrunner标准lr 函数——运行时函数
lr_abort 中止运行 \ lr_continue_on_error \ lrvexit
ir_load_dlllr_rendezvous \ lr_rendezvous_ex
lr_think_time
4.6 loadrunner标准lr 函数——字符串和参数函数
lr_evel_
lr_eval_string
lr_convent_
lr_convent_string_encoding
lr_save_
lr_save_string
lr_param
4.7 loadrunner标准lr 函数——事务函数
Ir_start_transaction
lr_set_transaction
Ir_get_transaction
lr_stop_transaction
lr_end_transaction
4.8 loadrunner标准lr函数-xml函数
Ir_xml_insert
Ir_xml_set_valuesIr_xml_get_values
lr_xml_replace
lr_xml_find
lr_xml_delete
Ir_xml_extract
lr_xml_tansform
五、loadrunner 脚本web_函数
Web Vuser Functions (WEB) > Web Vuser Functions: C Lanquage (WEB)
动作函数
认证函数
异步函数
检查函数
连接丽数
cookie相关函数
关联函数
数据格式函数
过滤函数
header函数
代理函数
重播函数
5.1 Loadrunner 标准web函数——动作函数(重点)
web_url 发起get请求
web_submit_form 提交表单
web_submit_data 无上下文数据提交web_custom_request 支持所有http方法发起请求
web_rest 模拟RESTapi请求
web_image 模拟鼠标点击图片
web_link 模拟鼠标点击超文本链接
5.2 loadrunner标准web函数——认证函数
web_set_certificate 设置使用的证书
web_set_certificate ex 指定证书和密钥的位置与格式
web_set_user 指定登录文本服务器的用户
5.3 loadrunner标准web函数——异步函数
web_sync \ web_stop async
web_reg_async_attributes
web_reg_cross_step_download
web_until_set_formatted_request body
web_until_set_request_body
web_until_set_request_url
Request_Callback \ Response_Callback
Response_Body_Buffer_Callback
Response_leader_Buffer_Callback
5.4 loadrunner标准web 函数 检查函数
web_find \ web_reg_find 在页面中搜索 \ 注册函数,在下一个操作中搜
web_image_check 检查图片是否存在
web_ global_ verification 搜索所有后续请求中的文本字符串
web_ global_ verification_ pause 挂起..
web_ global _verification_ resume 恢复...
5.5 loadrunner标准web函数——连接函数
web_ enable _keep _alive 启用保持连接
web _disable_ keep_ alive 禁用保持连接
5.6 loadrunner标准web 函数——cookie 相关函数
web_add_cookie \ web_add_cookie_ex 添加cookie
web _reg_add_ cookie 注册函数,添加cookie
web _remove_ cookie 移除指定cookic
web_ cleanup_ cookies 清除所有的cookie
5.7 loadrunner标准web 函数——关联函数
web_reg_save_param_ex 注册函数,保存指定边界的动态数据
web_reg_save_param_regexp 注册函数,保存正则式匹配的动态数据
web_reg _save _param_ xpath 注册函数,保存html 的动态数据
web_save _param _length 保存参数的长度
web_ save _timestamp _param 保存当前时间戳web_ set _max html_ param _len 设置检索的html信息最大长度
5.8 loadrunner标准web函数——数据格式函数
web_convert_param 将htm1转换为ur1或文木
web_convert _from _formatted 从什么格式转换回源格式
web_convert _to _formatted 转换为其他权
5.9 loadrunner标准web 函数 过滤函数
web_add_filter 设置下载时包括或排除的条件(仅用于下一个)
web_add_auto_filter 设置下载时包括或排除的条件(适用后续所有)
web_remove_auto_filter 删除过滤器
5.10 loadrunner标准web函数——消息头函数
web_add_header 添加自定义消息头(仅用于下一个)
web_add_auto_header 添加自定义消息头(适用于后续所有)
web_cleanup_auto_header 清除后续所有的白定义消息头
web_remove_auto_header 移除指定的消息头
web_save_header 保存消息头到变量
web_revert_auto_header 生成隐式消息头
5.11 loadrunner标准web 函数——代理函数
web_set_pac 设置代理位置
web_set_proxy 设置http请求的代理服务器web_set_proxy_bypass 指定脚本直接访问ur1列表,不使用代理
web_set_proxy_bypass_local 指定代理服务器是否绕过本地地址
web_set_secure_proxy 将安全的http请求指向安全的代理服务器
5.12 loadrunner标准web函数——重播函数
web_set_max_retries 设置最大重试次数
web_set_option 设置web选项
web_set_timeout 设置最大超时时间
loadrunner VuGen 手写脚本

一、HTTP协议方法——get
1.1 get方法—— web_url()
1、在action中,输入: web url();
2、选中函数名称(或光标定位在函数中),按F1
Loads the specified Web page (GET request)
C Language
int web_url (const char *StepName, const char *url, <list of Attributes>,[EXTRARES, list of Resource Attributes>,] LAST );

函数解读


案例
 1.2 post方法
1.2 post方法
post常用函数
web_submit_data()
web_submit_form() 上下依赖
web_custom_request () 所有的请求方式都可以使用(json)
web_submit_data()


验证登陆成功 需要打开详细日志

补充:自带函数功能




 登陆
登陆


web_custom_request(json格式)


1.3 定义变量
定义字符串
char parm [11];
指定字符长度,超过长度就会报错;
一个汉字是 2个字符长度
char *var;
不限长度
定义整型
int num;
定义浮点型
float fla;
Action()
{
char parm[12]= "loadrunner11";
char parm1[10],parm2[20];
char *var;
int num;
float fla;
var = "loadrunner12";
num = 5;
fal = 5.45;
lr_output_message("===%s", parm);
lr_output_message("===%s", var);
lr_output_message("===%d", num);
lr_output_message("===%.2f", fla);
lr_output_message("===%.1f", fla);
return 0;
}变量类型转换(函数)
atoi 字符串转换整型
var = "12abcdefggggkk";
anum = atoi(var);
lr_output_message("===%d", anum);
itoa 整形转换为字符串
itoa(34, parm1, 10)
lr_output_message("===%s",parm1);
atof 字符串转换浮点数
var = "12abcdefggggkk";
float fla2;
fla2 = atof(var);
lr_output_message("===%f", fla2);
1.4 定义参数
lr_save_string("值" , "参数名称"); 定义参数为字符串
lr_save_int("值" , "参数名称"); 定义参数为整型
lr_eval_string("{参数名称}"); 获取参数
lr_save_string("parmvalue" , "parmkey");
lr_output_message("===%s" , lr_eval_string("{parmkey}"));
lr_save_int(123456 , "intkey");
lr_output_message("===%s" , lr_eval_string("{intkey}")); 1.5 局部变量 vs 全局变量
局部变量
在action中定义的变量
只能在当前action中被引用
全局变量
在globals.h文件中定义变量
在所有action中,都可以被引用

1.6 脚本关联
注册函数
web_reg_
先注册,后使用:
写在被用于的脚本前面
常用的关联函数
veb_reg_find() 查找
web_reg_save_param_ex() 保存 关联使用
web_reg_save_param ( 11 以前的)
veb_reg_find()




 注意
注意
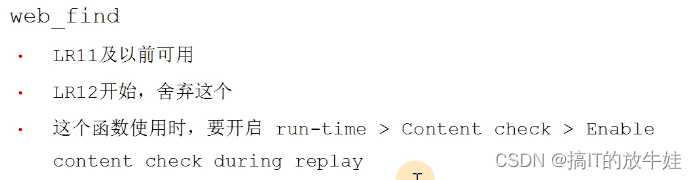

区别
 web_reg_save_param_ex() 关联使用
web_reg_save_param_ex() 关联使用




web_reg_save_param_regexp 需要用到正则去匹配
1.7 逻辑控制语句













循环操作




1.8 提取响应信息

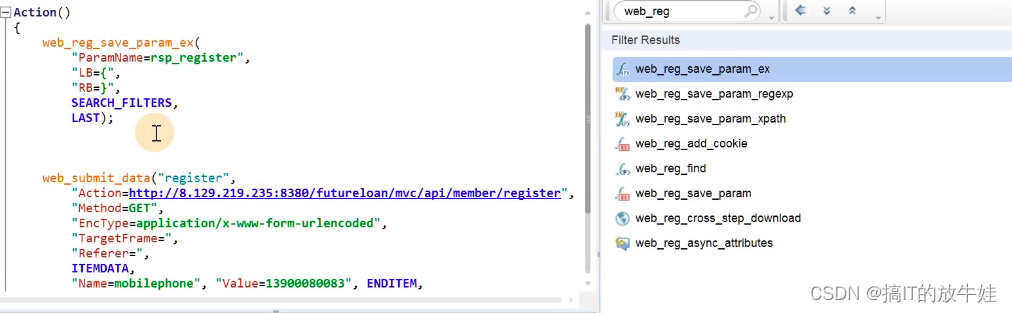





总结脚本












Action()
{
int nHttpRetCode; // code 变量
lr_start_transaction("tpshop.login"); // 事务开始
web_url("web_url",
"URL=http://www.tpshop.com/index.php?m=Home&c=User&a=verify",
"TargetFrame=",
"Resource=0",
"Referer=",
LAST);
// 默认最大长度为256,get请求需注意缓存问题,需要根据content-length进行修改
web_set_max_html_param_len("262144");
// REQUEST为内置变量,保存请求的头信息,需在发送URL请求前注册使用,将请求头信息存入字符串RequestHeader中
web_save_header(REQUEST, "RequestHeader");
// 将RESPONSE保存响应的头信息在字符串ResponseHeader中
web_save_header(RESPONSE, "ResponseHeader");
//自定义截取字符串,根据左右字符串获取数据,设置查找范围为消息体、左右查找边界为空则可以获取整个响应体的内容
web_reg_save_param_ex("ParamName=ResponseBody","LB=","RB=",SEARCH_FILTERS,LAST);
// 查找
web_reg_find("Search=Body","SaveCount=reg_count","Text=2593",LAST);
web_submit_data("web_submit_data",
"Action=http://www.tpshop.com/index.php?m=Home&c=User&a=do_login",
"Method=POST",
"TargetFrame=",
"Referer=",
ITEMDATA,
"Name=username", "Value=15708460952", ENDITEM,
"Name=password", "Value=123456", ENDITEM,
"Name=verify_code", "Value=8888", ENDITEM,
LAST);
lr_end_transaction("tpshop.login", LR_AUTO); // 事务结束
//字符转码
// lr_convert_string_encoding(lr_eval_string("{RequestHeader}"),LR_ENC_UTF8,LR_ENC_SYSTEM_LOCALE,"RequestHeaderUTF8"); // 请求头信息
// lr_convert_string_encoding(lr_eval_string("{ResponseHeader}"),LR_ENC_SYSTEM_LOCALE,LR_ENC_UTF8 ,"ResponseHeaderUTF8"); // 响应头信息
lr_convert_string_encoding(lr_eval_string("{ResponseBody}"),"utf-8",NULL,"ResponseBodyUTF8"); // 响应体内容
//
// //输出信息 lr_eval_string()将参数值转换成字符串
// lr_output_message("请求头信息:\n %s", lr_eval_string("{RequestHeaderUTF8}"));
// lr_output_message("响应头信息:\n %s", lr_eval_string("{ResponseHeaderUTF8}"));
// lr_output_message("响应内容体:\n %s", lr_eval_string("{ResponseBodyUTF8}"));
//获取服务器http响应码,HTTP_INFO_RETURN_CODE变量在请求后使用
// nHttpRetCode = web_get_int_property(HTTP_INFO_RETURN_CODE);
// if(nHttpRetCode == 200){
// lr_output_message("Success!");
// }else{
// lr_output_message("Failed! ");
// }
if(atoi(lr_eval_string("{reg_count}")) == 2593 )
{
lr_output_message("reg_count = %s", lr_eval_string("{reg_count}"));
}
lr_output_message("响应内容体:\n %s", lr_eval_string("{ResponseBodyUTF8}"));
return 0;
}
token值处理
Action()
{
lr_start_transaction("loging_add");
//自定义截取字符串,根据左右字符串获取数据,设置查找范围为消息体、左右查找边界为空则可以获取整个响应体的内容
web_reg_save_param_ex("ParamName=token","LB=token\":\"","RB=\"},\"errmsg",SEARCH_FILTERS,LAST); // 提取token值
// 查找
web_reg_find("Search=Body","SaveCount=reg_count","Text=user123",LAST);
web_reg_save_param_ex("ParamName=ResponseBody","LB=","RB=",SEARCH_FILTERS,LAST);
web_custom_request("登录",
"URL=http://www.litemall360.com:8080/wx/auth/login",
"Method=POST",
"TargetFrame=",
"Resource=0",
"Referer=",
"EncType=application/json",
"Body={\"username\":\"user123\",\"password\":\"user123\"}",
LAST);
lr_convert_string_encoding(lr_eval_string("{ResponseBody}"),"utf-8",NULL,"ResponseBodyUTF8");
if(atoi(lr_eval_string("{reg_count}")) > 0)
{
lr_output_message("token值为:\n %s",lr_eval_string("{token}"));
lr_output_message("响应内容体:\n %s", lr_eval_string("{ResponseBodyUTF8}"));
}else{
lr_output_message("登录失败");
}
web_add_auto_header("X-Litemall-Token","{token}"); // 设置token值
web_reg_save_param_ex("ParamName=Response","LB=","RB=",SEARCH_FILTERS,LAST);
// 查找
web_reg_find("Search=Body","SaveCount=reg_cou","Text=0",LAST);
web_custom_request("添加商品到购物车",
"URL=http://www.litemall360.com:8080/wx/cart/add",
"Method=POST",
"TargetFrame=",
"Resource=0",
"Referer=",
"EncType=application/json",
"Body={\"goodsId\":1181000,\"number\":1,\"productId\":2}",
LAST);
lr_convert_string_encoding(lr_eval_string("{Response}"),"utf-8",NULL,"ResponseBodyUTF");
if(atoi(lr_eval_string("{reg_cou}")) > 0)
{
lr_output_message("响应内容体:\n %s", lr_eval_string("{ResponseBodyUTF}"));
}else{
lr_output_message("加入购物车:失败");
}
lr_end_transaction("loging_add", LR_AUTO);
return 0;
}
VuGen-集合点
一、为什么要学习集合点?
需求:
1. 10个用户同时登录订票网站,统计服务器处理登录事务性能;
1.1 问题
-
10个用户同时登录,如何保证10个虚拟用户同时(忽略绝对论,最大程度去模拟)去操作?
1.2 集合点(rendezvous)
在指定的地点集合指定虚拟用户(Vuser),条件满足时集合的虚拟用户,同时去操作同一事务
1. 在VuGen脚本内可以插入集合点,要运行集合点必须配合下一章《Controller》知识点,我们在这里先学习 如何基于VuGen创建集合点; 2. 前面了解的并发测试就是基于集合点来完成【重点】
1.3 集合点 创建
方式:

1. 指定插入位置,鼠标右键 -> Insert -> Rendezvous【推荐】 2. 工具栏菜单(Insert) -> Rendezvous
参数:
Rendezvous Name:集合点名称;在Controller场景运行时使用;例如:Login
提示:
1. 创建集合点,相当于找好集合的地方,那么到底应该哪些用户及集合多少用户需要单独设置; 2. 集合点的具体设置和运行,必须在Controller工具内完成; 3. 由于Controller工具我们目前还没有学习,所以我们先在这里先学习使用它如何设置集合点。
1.4 集合点设置

1). 基于当前脚本 创建Controller场景

菜单工具(Tools) -> Create Controller Scenario (基于当前脚本直接创建场景)
2). 选择场景模式及虚拟用户数

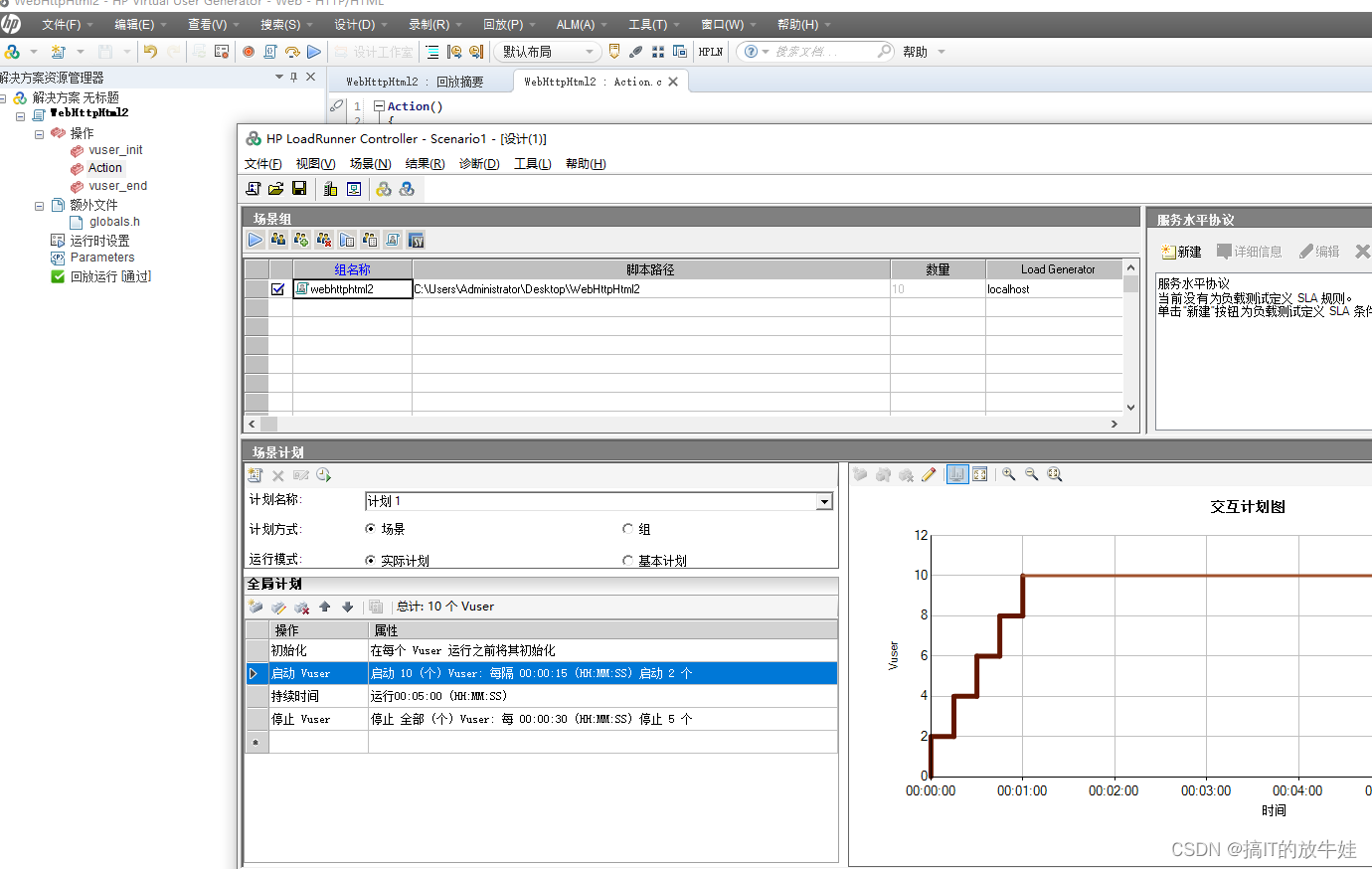
设置:
1. 场景模式:Manual Scenario(手工场景) 2. Number of Vusers:虚拟用户数
提示:
场景模式:我们还没了解,在这里暂时使用下手工场景 虚拟用户数:为并发用户数,我们这里以需求10个并发登录为例
3) Controller工具内设置集合策略 打开集合点设置

Controoler工具-菜单(Scenario) -> Rendezvous
设置集合点
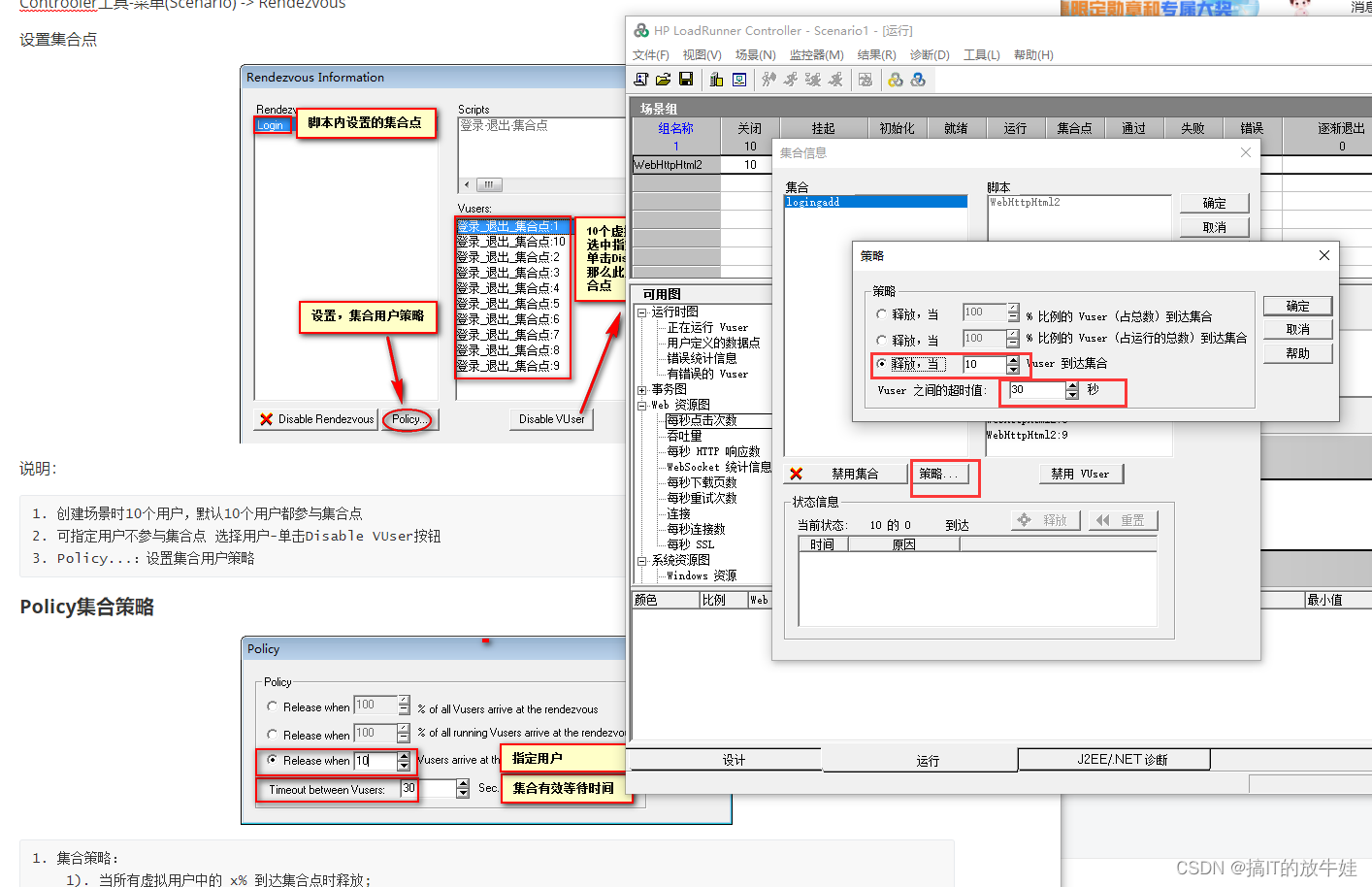
说明:
1. 创建场景时10个用户,默认10个用户都参与集合点 2. 可指定用户不参与集合点 选择用户-单击Disable VUser按钮 3. Policy...:设置集合用户策略
Policy集合策略

1. 集合策略: 1). 当所有虚拟用户中的 x% 到达集合点时释放; 2). 当所有正在运行的虚拟用户中的 x% 到达集合点时释放; 3). 当 x 个虚拟用户到达集合点时释放;【推荐】 2. 时间: 1). Timeout between Vusers:默认30秒;虚拟用户之间的超时时长; 3. 提示: 1). 集合点的插入和场景设置我们就学习完了,集合点的执行要在学习完Controller工具后,再进行具体操作;
1.5 需求1 代码
Action()
{
web_url("WebTours",
"URL=http://127.0.0.1:1080/WebTours/",
"Resource=0",
"RecContentType=text/html",
"Referer=",
"Snapshot=t1.inf",
"Mode=HTML",
LAST);
lr_think_time(8);
# 集合点
lr_rendezvous("Login");
# 登录事务开始
lr_start_transaction("登录");
web_submit_form("login.pl",
"Snapshot=t2.inf",
ITEMDATA,
"Name=username", "Value=jojo", ENDITEM,
"Name=password", "Value=bean", ENDITEM,
"Name=login.x", "Value=68", ENDITEM,
"Name=login.y", "Value=12", ENDITEM,
LAST);
# 登录事务结束
lr_end_transaction("登录", LR_AUTO);
lr_think_time(19);
web_image("SignOff Button",
"Alt=SignOff Button",
"Snapshot=t3.inf",
LAST);
return 0;
}1.6 集合点设置 注意事项
集合点只能在手工场景模式内使用
多个脚本需要同步并发时,可以在不同脚本内设置相同的集合点,再在一个场景内搭建时使用这些脚本
如果脚本内没有设置集合点,在Controller内集合点策略设置功能不生效!
集合点只能在Action部分添加,在 vuser_init 和 vuser_end 中则无法添加
Goal-Oriented Scenario(目标场景)
一、目标场景 【了解】
1.1 目标场景 目标场景设计就是定义要实现的【测试目标】,LR会根据根据这些目标自动构建场景。
LR提供了5种测试目标::
1、虚拟用户数 2、每秒点击数 3、每秒事务数 4、每分钟页面数 5、事务响应时间 (其中每秒点击数、每分钟页面数只适合Web项目)
1.2 如何选择启动目标场景

1) 创建目标场景
-
启动Controller
-
Select Scenario Type:选择Goal-Oriented Scenario
-
根据测试用例给目标场景添加相应业务(单一业务或混合业务),双击(Available)有效脚本,或选 中点击Add ==>> 按钮
(单一业务:单个业务脚本;混合业务:多个业务脚本【重点】)
2) 目标场景图
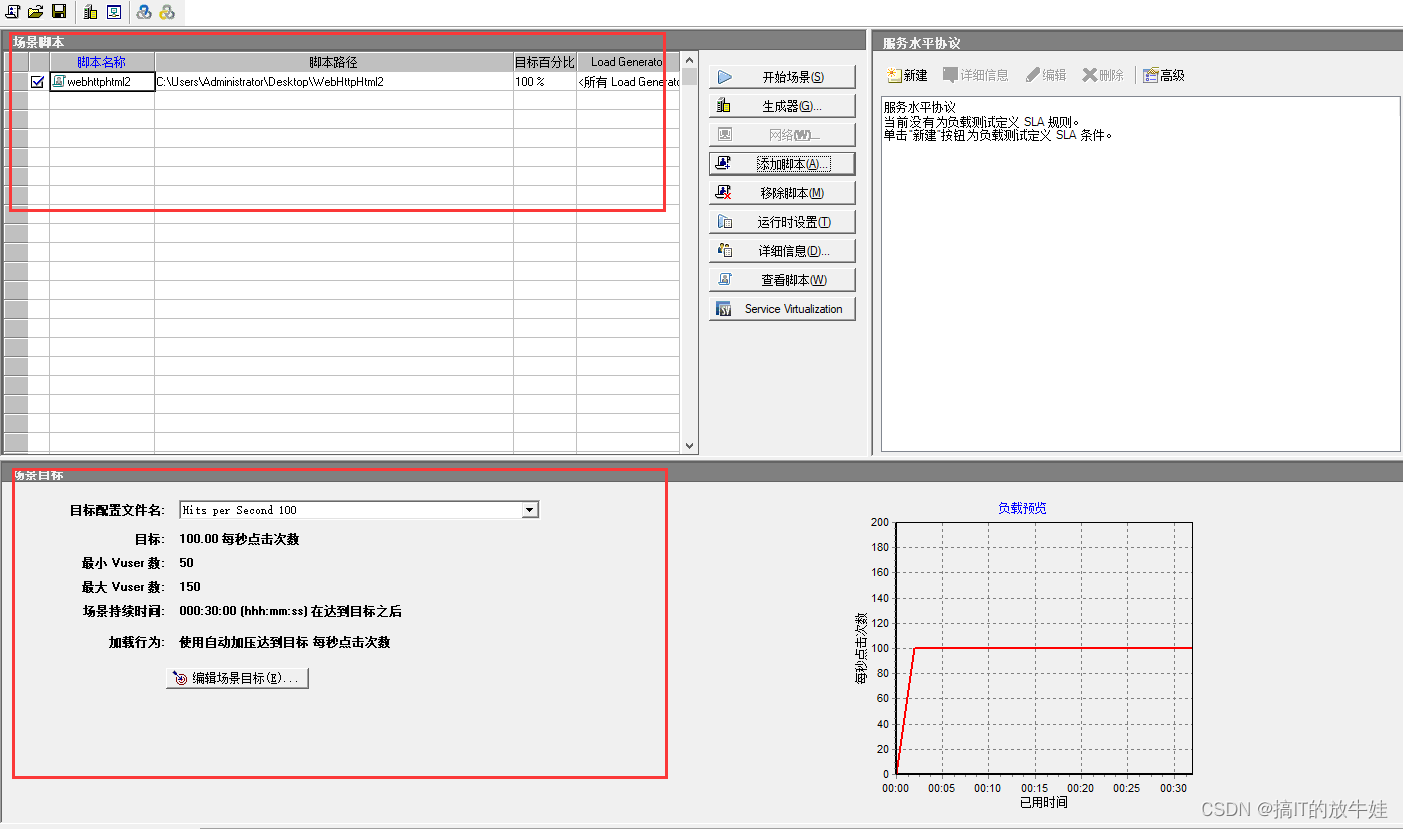
红框选中的为接下来需要关注的地方
1.3 目标场景 计划与编辑
-
启动编辑场景
-
编辑场景
1) 启动编辑场景

场景默认数据:为 Controller 默认创建目标场景时设计的数据
Edit Scenario Goal:编辑目标场景-修改目标场景数据
2)编辑场景

标注1:新建场景、修改现有场景名称、设置场景启动时间 标注2:设置目标场景的测试目标类型及目标范围【相对目标场景 重点】 标注3:场景运行时间及策略设计 标注4:负载行为(会根据场景目标变化对应内容)
标注 1 (新建场景、修改现有场景名称、设置场景启动时间)

Scenario Start Time:设计完场景后,场景启动时间;一般默认即可
1). Without delay:立即运行场景(默认) 2). With a delay of HH:MM:SS:等待指定时间运行场景 3). At HH:MM:SS on Y/M/D:指定X年X月X日X时X分X秒运行场景
New:创建一个新的计划场景
标注 2 【目标场景的核心】

1. Goal Type:本次性能测试的测试目标 2. 由于此选项比较重要,在接下来第二小节【二、目标场景5种 测试目标】中单独讲解
标注 3 (场景运行时间及策略设计)


-
标示1(Run time):场景达到目标后,继续运行多长时间;(一般10-30分钟)
-
标示2(If target cannot be reached):如果达不到设定目标时的处理方式
1). Stop scenario and save results 停止并保存运行结果
2). Continue Scenario without reaching 继续执行场景直到达到目标位置 【默认】
提示: 以上选项如没有特殊业务需求,默认即可;
标注 4 (负载行为)

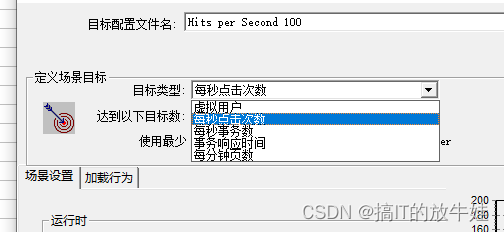
二、目标场景5种 测试目标
Virtual users (虚拟用户)
Hits per Second (每秒点击数)
Transactions per Second (每秒事务数)
Transaction Response time (事务响应时间)
Pages per Minute (每分钟页面数)
提示: Hits per Second 和 Pages per Minute 只适合用于 Web 项目
2.1 Virtual users(虚拟用户)

Virtual user 目标:测试应用程序是否可以同时运行指定数量的虚拟用户数
2.2 Hits per Second(每秒点击数)

-
Hits per Second 目标:测试服务器的每秒点击数 (指定每秒点击数目标以及达到这一目标的最小用户数和最大用户数)
-
负载行为(Load Behavior)应选择 自动加载(Automatic)
-
Hits per Second只适合Web项目【注意】
2.3 Transactions per Second(每秒事务数)

-
Transactions per Second 目标:测试服务器每秒事务数(指定事务) (指定每秒完成事务数目标以及达到这一目标的最小用户数和最大用户数)
-
在VuGen中必须插入相应的事务才能够进行设置!
2.4 Transaction Response Time(事务响应时间)

Transaction Response Time 目标:测试在不超过预期事务响应时间(目标)的情况下可以运行多少个用户,必须指定预期时间、最少用户、最大用户。 (如:需求100个人使用支付软件付款,在3秒钟内完成;预期目标时间为3秒,最少用户80,最多用户180)
2.5 Pages per Minute(每分钟页面数)

-
Pages per Minute 目标:测试服务器每分钟页面数 (指定每分钟完成页面数目标以及达到这一目标的最小用户数和最大用户数)
-
Pages per Minute只适合Web项目【注意】
提示:
1. 目标场景主要采用内在工具来最大限度完成测试目标,工具很智能,但人更智能。在实际工作场景中使用最多的还是手工场景; 2. 目标场景和手工场景都只是测试场景的搭建模式,场景的运行和监控都是一样。
Manual Scenario(手工场景)
一、Manual Scenario(手工场景)【重点】
在实际性能测试工作中,应用最多的还是基于手工设置的场景;
1.1 为什么工作中选择手工场景?
在手工场景模式内可以最大程度模拟业务场景(虚拟用户的增加、减少、虚拟用户对混合场景的应用)
1.2 手工场景的创建
1) 启动 选择手工场景

启动:
1). 启动Controller工具
2). Select Scenario Type:Manual Scenario(手工场景)
说明:
1). Use the Percentage Mode to ... 选项:为使用百分比模式
2). 场景添加脚本参考-目标场景添加脚本
2) 手工场景界面

标1:手工场景的基础计划(脚本名称为组名称、虚拟用户数量默认为10); 标2:标1基础计划的默认计划选项(计划方式:场景模式、运行模式:实际计划) 标3:标1计划运行模式 (虚拟用户初始化方式、虚拟用户启动加载方式、计划持续运行时间方式、计划完成用户退出方式) 标4:标3计划运行策略直观图
以上4点为手工场景的核心,是手工场景的重要组成
二、手工场景-各区域
2.1 默认基础计划

标1: 1). 1:运行场景 2). 2:编辑虚拟用户 3). 3:添加组(脚本) 4). 4:删除组(脚本) 5). 5:运行设置-场景内设置 快捷键:F4 6). 6:查看当前选中组的详情信息(刷新功能) 7). 7:查看当前选中组脚本-切换回VuGen中 标2: 1). Group Name: 组名称(脚本名称) 2). Script Path:组路径(脚本路径) 3). Quantity:虚拟用户数量 4). Load Generators:当前组使用的负载机
2.2 编辑/创建计划

Schedule by - 计划方式
Run Mode - 运行模式
1) Schedule by(计划方式)
1. Scenario(场景):以场景计划为单位,Controller同时运行所有参与场景的Vuser组; (定义的场景运行计划同时会应用于所有Vuser组) 2. Group(组):以Vuser组为单位,参与场景计划的Vuser组,每个组都按其自己的单独计划运行; (每个Vuer组(脚本)都要设置单独的运行计划策略)
提示:
1. 计划方式一般情况下选择Scenario(场景),这样面对混合场景时,计划运行策略只需要设置一次;
2. Group(组):场景中如果存在业务依赖关系时,必须使用Group组,详情请看Group(组)应用图
Group(组)应用图

依赖关系:两个业务脚本有先后执行顺序
(假设模拟订票业务20个并发,前提必须先注册20个用户(注册业务)执行20次,再使用这些新注册用户去订票)
2) Run Mode(运行模式)
1. Real-world schedule(实际计划):场景根据模拟用户实际计划操作来运行【推荐】 (可以通过添加用户组的Action来改变组的虚拟用户策略) 2. Basic schedule(基本计划):和实际计划相同,不同之处,基本计划只能设置虚拟用户在场景一次的启动和停止策略
2.3 全局计划运行策略
计划运行策略是根据Schedule by(计划方式)与Run Mode-模式的组合而产生不同的策略
全局计划策略、计划改变模式改变、都会影响计划图的改变
1) 全局计划 场景+真实计划(Scenario + Real-world schedule)

1. Initialize(虚拟用户初始化策略)

1:Controller运行Vuser之前对所有Vuser同时进行初始化
2:Controller在运行指定数目的Vuser之前,根据指定时间间隔对Vuser逐渐进行初始化
3:Controller在每个Vuser开始运行之前对其进行初始化【推荐默认】
提示:
1). Controller运行虚拟用户(线程)之前必须初始化 2). 一般采取默认,运行每个Vuser之前对其初始化
2. Start Vusers(虚拟用户启动策略) 【重点】

1:要启动的虚拟用户数;默认为场景内个Vuser组的Vuser用户总和;
2:同步启动1设定的虚拟用户数;
3:逐渐运行1设定的虚拟用户数;默认15秒启动指定虚拟用户。
3. Duration(持续运行) 【重点】

1:脚本执行一次,如果有迭代,那么执行到迭代次数完成
2:当前场景运行指定时长 (如果选择此项,那么脚本内如果设置有迭代次数,迭代次数设置将失去作用)
提示:
1). 持续运行策略需要根据场景需求来选择,如:持续压测5分钟,就选第二条 2). 如果脚本有迭代次数,需要迭代完毕就停止场景的话,就选择第一条
4. Stop Vuser(虚拟用户停止策略)
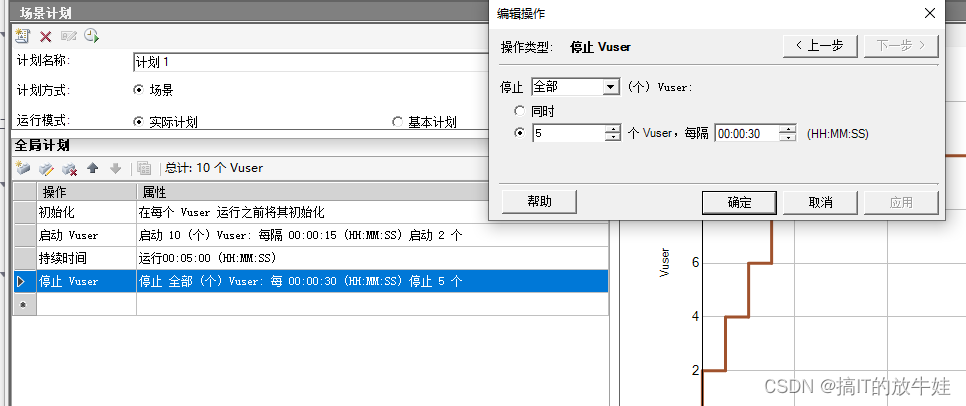
1:停止的虚拟用户数,默认All(所有用户),或指定用户数
2:同步停止1设定的用户数
3:逐渐停止1设定的用户数,默认:30秒停止5个虚拟用户
2) 全局计划 用户组+真实计划(Group + Real-world schedule)

1). Start when group ...... finishes:指定某一用户组(脚本)执行完毕后,执行当前组(脚本); (脚本有依赖关系时使用,比如:必须先注册再登录)
2). 其他选项参考(Scenario + Real-world schedule)说明
三、案例1
-
场景搭建是模拟真实应用场景,而真实场景一般都为混合模式(多个业务)
-
结合LR自带机票网站,模拟真实场景来学习混合场景的搭建
场景:
1. 根据需求分析WebTours订票网站高峰期时25人访问,其中80%用户在使用订票业务,20%用户在使用注册业务; 2. 混合场景 = 注册业务(5) + 订票业务(20)
需求:
1. 登录业务时间小于5秒; 2. 订票业务小于10秒;
提示:
1. 注册业务:录制/手工编写注册脚本 2. 订票业务:录制/手工编写订票脚本,脚本内需要插入登录事务和订票事务 3. WebTours 项目中用户注册后生成文件的存放路径为: 例如:C:\LoadRunner安装根目录\WebTours\MercuryWebTours\users
3.1 案例1 难点分析
-
先注册20个账户,再使用这20个新注册账户订票;
-
订票脚本依赖注册脚本(Schedule by: Group)
-
注册脚本参数化:行的选择和更新值方式(Unique + Each iteration + Abort Vuser) (Abort Vuser:当没有唯一行时处理方式,终止用户)
-
购票脚本参数化:行的选择和更新值方式(Sequential + Once)
3.2 案例1 场景设置 预览图

负载生成器与场景运行
一、负载生成器(Load Generator)
负载生成器又俗称负载机
性能测试就要面临模拟大量的虚拟用户并发请求,单台负载机就面临自身硬件性能瓶颈问题,需要扩展多台负载机上运行达到减压不减虚拟用户的目的;
在 LR 中运行场景内脚本的机器被称为负载机
使用负载机 流程
启动Load Generator
添加负载机
场景-用户组(脚本)选择相应的负载机
1.启动 Load Generator

1. 通过工具栏启动,点击标1 2. 通过菜单栏(Scenario) -> Load Generator
2. 添加负载机

标1:点击添加负载机 标2:输入负载机IP、机器名;如果添加本机可以输入本机 IP 或 localhost 标3:选择负载机平台(操作系统),支持 UNIX、Windows
3. 扩展 测试连接负载机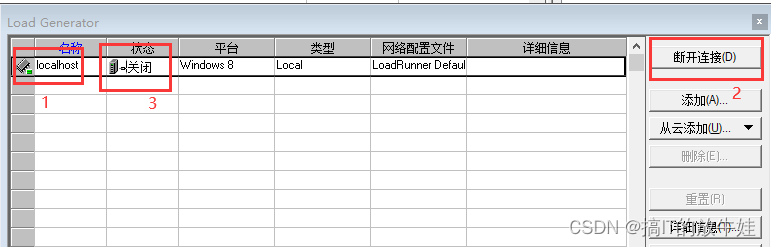
标1:选中负载机
标2:测试连接负载机
标3:查看测试结果(Ready:通过;Down:未连接;Failed:失败)
提示:
负载机需要安装LR或者Load Generator
4. 扩展 Load Generator安装说明
Windows直接通过LR安装包安装
Linux需要从官网或其他网站下载loadrunner-11-load-generator.iso
5. 扩展 负载机配置及注意事项


注意事项:
1. 网络:负载机与控制机网路通畅;使用 ping 192.168.x.x
2. 代理服务程序:
说明:负载机必须启动 LoadRunner Agent Process 代理服务程序;
(位置:开始程序 -> HP LoadRunenr -> Advanced Settings -> LoadRunner Agent Process)
3. 防火墙:负载机上的防火墙为关闭状态;
4. 权限配置:
说明:负载机运行设置工具内输入负载机本机登录用户名和密码,目的解决是控制机远程连接负载机的权限问题
(位置:开始程序 -> HP LoadRunner -> Tools ->
LoadRunner Agent Runtime Settings Configuration)
6. 扩展 负载机授权配置图
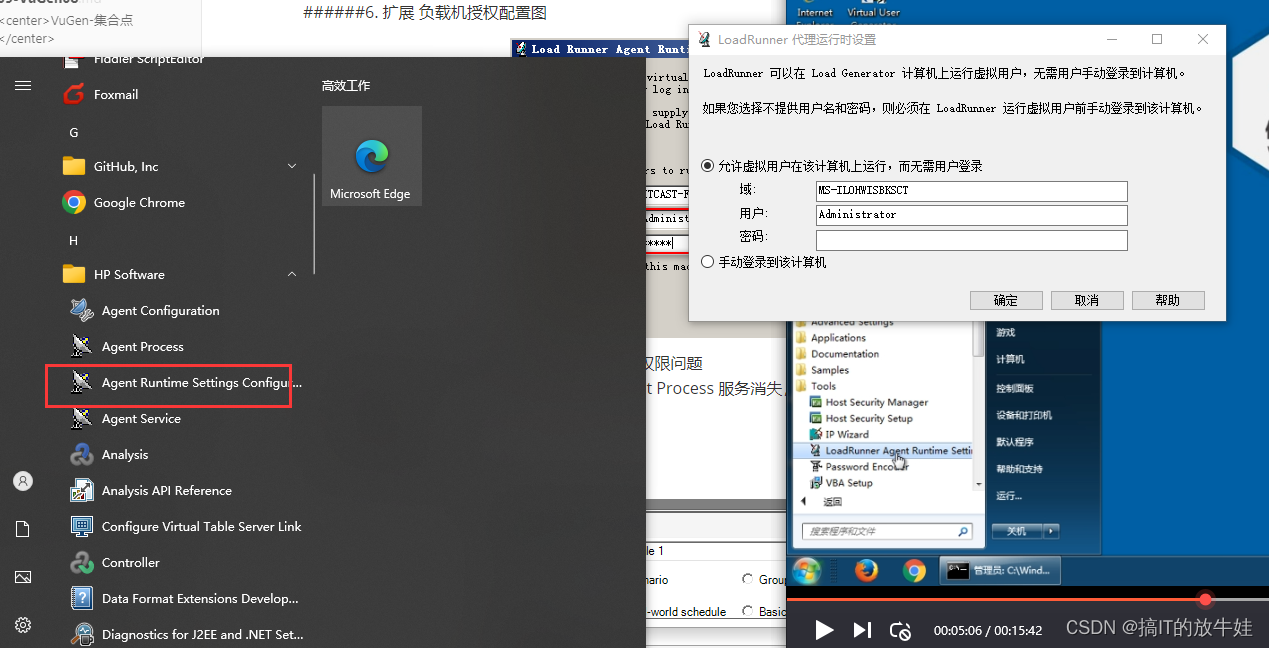
1.如上图设置,能够解决LR控制机连接负载机的权限问题
2.如果选择 Allow virtual ...后 LoadRunner Agent Process 服务消失,也可以选择使用 Manual log ...手动登录的方式实现授权!
二、场景运行
2.1 切换运行界面

在场景设计页面下,点击 标1 切换到场景运行界面
2.2 场景运行界面

标1:场景用户组虚拟用户运行状态图 标2:场景运行状态概览图 标3:可用性能计数器及性能计数器指标走向图
提示:
1). 启动场景及场景运行完成,关注点在标2区域 2). 场景启动,虚拟用户未加载完之前,关注点在标1区域 3). 场景启动,虚拟用户加载完成,持续运行阶段,关注点在标3区域
2.2.1 标1-虚拟用户运行状态图

1). Down(关闭):Vuser处于关闭状态 2). Pending(挂起):Vuser已创建,可以初始化,正将脚本传输到负载机 3). Init(初始化):Vuser正在负载机上执行初始化 4). Ready(就绪):Vuser已执行脚本初始化部分(init函数),可以运行Action函数 5). Run(正在运行):Vuser脚本正在运行 6). Rendezvous(集合点):Vuser到达集合点,等待条件满足释放 7). Passed(完成并通过):Vuser已运行结束,状态为通过 8). Failed(完成并失败):Vuser已运行结束,状态为失败 9). Error(错误):Vuser运行中发生了错误 10). Gradual Exiting(逐步退出):Vuser正在运行退出前的最后一次迭代 11). Exiting(退出):Vuser已经完成操作,正在退出 12). Stopped(停止):Vuser被停止,不在运行 需要重点关注5、6、7、8
2.2.2 标2-场景运行状态概览图

标1. 操作区:
1). Start Scenario:运行当前场景 2). Stop:停止正在场景 3). Reset:清除上次场景运行记录 4). Vuers...:对场景当前选中脚本的虚拟用户进行修改(运行、添加、删除、指定负载机) 5). Run/Stop Vusers...:对当前场景内虚拟用户进行操作(运行、停止)
标2. 结果区:
1). Running Vusers:运行用户数 2). Elapsed Time:运行时间 3). Hits/Second:每秒点击数 4). Passed Transactions:通过事务数 5). Failed Transactions:失败事务数 6). Errors:错误数
2.2.3 标3-可用性能计数器及性能计数器图表

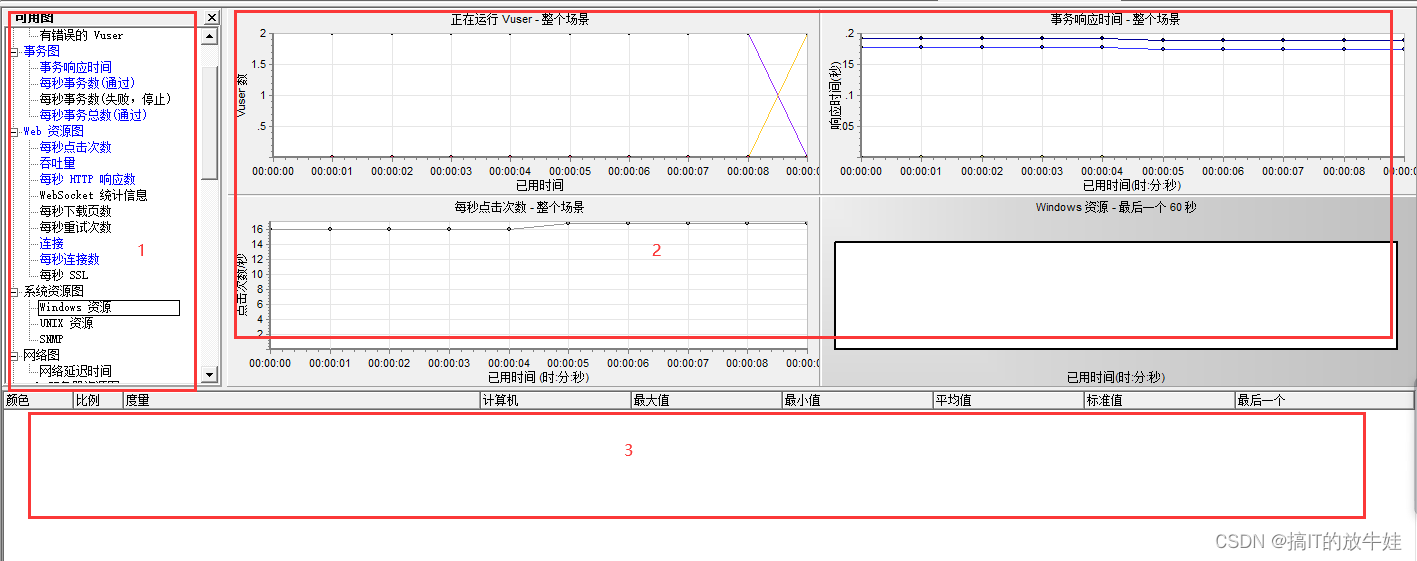
标1:可在标2检测的指标; 标2:显示标1指定指标走组图;在标1选中指标双击或拖拽到标2 标3:对应用服务器硬件资源(CPU、内存、网络、磁盘)等性能指标进行度量统计;
提示:
1). 标3度量区,度量项跟聚不同的性能指标有所不同,但是我们大多数只关注及项 (Max:最大值;Min:最小值;Avg:平均值;Std:标准偏差)
2.4 运行

1). 以上运行数据,虚拟用户共10,场景内含两个脚本,虚拟用户数比例(8:2) 2). 场景运行时长:1分09秒 (Elapsed Time) 3). 每秒点击率:50.75 4). 通过事务数:274
提示:
1. 以上数据,只是运行主要概况; 2. 详细报告数据可以通过Analyze Result得到
2.5 打开 Analyze Result(分析报告)
启动Analyze Result
预览报告
2.5.1 启动Analyze Result

通过工具栏 标1 打开Analyze Result
通过菜单栏(Results->Analyze Result)
2.5.2 预览报告

服务器 性能资源指标监控与服务水平协议(SLA)
一、服务器 性能资源指标监控
1.1 资源性能指标
资源性能指标就是预期结果,性能测试的目的和功能测试一样,观察实际结果是否与预期结果相符
业务需求:
1). 系统在1000人并发访问的时候,要求CPU利用率不超过75%; 2). 系统在500人进行订单查询的时候,系统可用内存要在20%以上。
提示:
1). “CPU利用率不超过75%”、“可用内存20%以上”就是资源性能指标 2). 资源性能指标依靠操作系统提供的【性能计数器】来记录
1.2 性能计数器?

性能计数器也叫性能监视器,是操作系统提供的一种系统功能,它能实时对操作系统内应用程序的性能数据进行采集和分析
Windows操作系统使用系统自带的 perfmon 工具
Linux操作系统使用相应的命令或第三方工具,工具如:nmon
1.3 服务器资源 常用指标
| 指标名称 | 含义 | 关注点 | 建议值 |
|---|---|---|---|
| % Processor Time | CPU利用率 | 1. CPU使用率峰值:最大值即为CPU的使用率峰值 2. CPU平均使用率:平均值为CPU的平均使用率 | 75%-85%之间 过低则CPU利用率不高,过高则CPU成为系统瓶颈 |
| Available MBytes(Memory) | 可用内存(MB) | 1. 内存占用率峰值(%) = (最大物理内存 - 最大空闲内存) / 最大物理内存 * 100% 2.内存平均使用率(%) = (最大物理内存 - 平均空闲内存数) / 最大物理内存 * 100% | 可用内存保留20%左右 |
| % Disk Time | 硬盘读写时间比 | 正常值小于10 | 此值过大表示耗费太多时间来访问磁盘,可以考虑增加内存,或更换更快的硬盘来进行优化 |
提示:
1). % Processor Time 指标在 Perfmon 工具 Processor 系列内 2). Available MBytes 指标在 Perfmon 工具 Memory 系列内 3). % Disk Time 指标在 Perfmon 工具 PhysicalDisk 系列内
二、添加资源性能计数器指标
在LoadRunner中添加资源性能计数器
需求:
在LR数据监控中监控应用服务器可用内存、CPU使用率、硬盘读写时间(参考1.4服务器资源指标)
2.1 操作步骤
在 Available Graphs 激活 System Resource Graphs(系统图表)
在系统资源图表上鼠标右键 -> Add Measurements(添加度量值)
2.1.1 激活System Resource Graphs(系统图表)

1. 这里我们以 Windows 系统为例 2. 双击 Windows Resources 激活(或拖拽),激活; 3. 激活后在右侧图表区出现 - Windows Resources 图表 4. 在 Winddows Resources 图表添加服务器-资源指标
2.1.2 Windows Resources图表 添加指标
1). Windows Resources图标上右击 -> Add Measurements(添加度量值) 2). 标1:弹出添加服务器窗口 3). 标2:Name:为服务器IP地址 4). 标3:操作系统可以默认(添加成功后会自动获取系统版本,比如Win7)
2.1.3 添加指标(CPU、内存、硬盘)
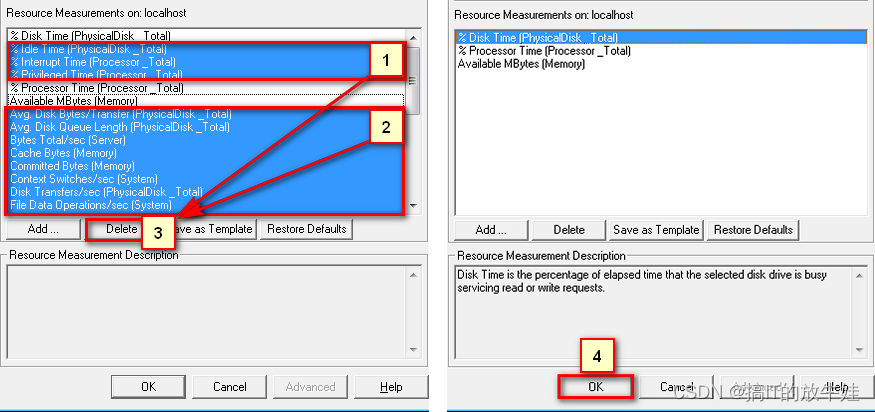
1). 选中标1、标2(本次不关注的指标) 2). 标3:删除多余指标(标1、标2) 3). 标4:点击OK 添加列表内指标
提示:
1). 默认把操作系统常用指标全部列出,需要删除多余指标 2). 全部选中的快捷键为:Ctrl + / (右shift键旁边的问号键)
2.1.4 添加指标(CPU、内存、硬盘) 效果图




2.2 扩展 修改图表监控区显示图表数量

图标区域鼠标右键 -> View Graphs
菜单(View)-View Graphs
提示:
1. 双击指定图表,可放大图表; 2. 选中指定图表右击 -> configure可对相应图表属性、样式进行配置
2.3 监控Windows资源 注意事项
确保LR控制机与需要监控的PC机网络通畅(ping 192.168.X.X )
Remote Procedure Call (RPC)、Remote Procedure Call (RPC) Locator、Remote Registry、 Workstation 这些服务都需要确认为已启动状态。
本地账户共享和安全模型-经典-对本地用户进行身份验证不改变其本来身份【win7旗舰版默认】 (gpedit.msc 计算机配置->Windowns设置->安全设置->本地策略->安全选项->网络访问:本地账户共享和安全模型)
三、服务水平协议(SLA)
Service Level Agreement(SLA) 是在场景执行之前定义相应的负载测试目标,在场景运行之后 Analysis 将运行时收集的指标值和SLA设定的进行对比,然后确定本次测试是成功还是失败。

在场景设计区域,右上侧有个SLA专栏,我们需要对它的作用及使用做个了解;
测试需要有预期结果,SLA就是给场景运行之前给相应指标设定个预期结果。
需求1
订票网站,20用户同时订票,登录在3s内完成,订票在15秒内完成;
四、SLA使用
4.1 新建SLA
点击 标1 新建SLA服务
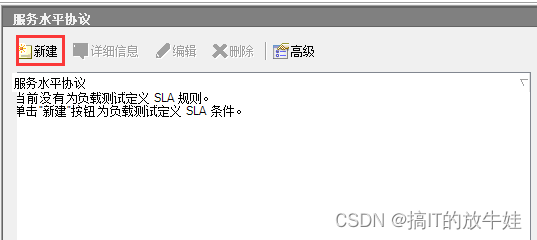
4.1.1 新建SLA
点击 Next 进行下一步

4.1.2 选择指标
需求为登录、订票事务时间,所以我们选择 标1
标1 有两个选项Percentile(百分比)、Averge平均值 【选择:Percentile】

提示:
1. Percentile(百分比)默认为90%
4.1.3 选择事务
添加事务

提示:
1. 录制或编写脚本的时候,必须添加相应的事务
4.1.4 设置事务预期值

设置90%登录用户时间小于等于3秒
设置90%订票业务小于等于15秒
4.1.5 完成SLA服务创建

勾选点击 完成当前SLA添加后继续添加SLA服务
点击完成当前SLA服务【使用】
4.1.6 查看SLA服务
标1:刚创建的SLA服务
标2:查看服务细节

4.1.7 Analyze Results SLA报告


4.1.8 Analyze Results SLA明细

Goal:预期目标值
Actual:实际值
IP Wizard的应用
一、IP Wizard(IP 欺骗)
场景:
1. 对于某些应用服务器,是根据IP来分配资源,当某个IP地址访问频繁或者访问量过大时,服务器会拒绝访问,或者要求输入验证码; 2. 一些应用服务器,只允许一个IP地址,操作一次应用程序;例如:投票系统。
LoadRunner 的 IP Wizard 工具可以模拟出多个不同的 IP 地址,每个虚拟用户都可以使用不同的IP地址完成类似投票系统的真实场景的业务操作。
IP Wizard应用 步骤
配置:使用 IP Wizard 工具配置 IP
应用:运行场景时启用 Enabled IP Spoofer
配置-启动IP Wizard工具
开始菜单 -> HP LoadRunner -> Tools -> IP Wizard

注意:
启动IP Wizard工具时,电脑 IP 地址必须为【静态IP地址】,不可用 DHCP 动态获取


配置-选择类型 创建IP

配置-搜索服务器IP段地址
输入 IP 地址段,或为空

配置-IP列表
1:点击Add,添加IP对话框
2:选择IP类型,默认C类
3:添加IP起始段和Submask地址
4:批量添加IP的数量

配置-确定创建IP
1: 点击完成(确定以上列表内IP地址去创建)
2: 点击完成(创建)

查看创建成功
开始菜单 -> 运行 -> cmd -> ipconfig /all 查看添加IP

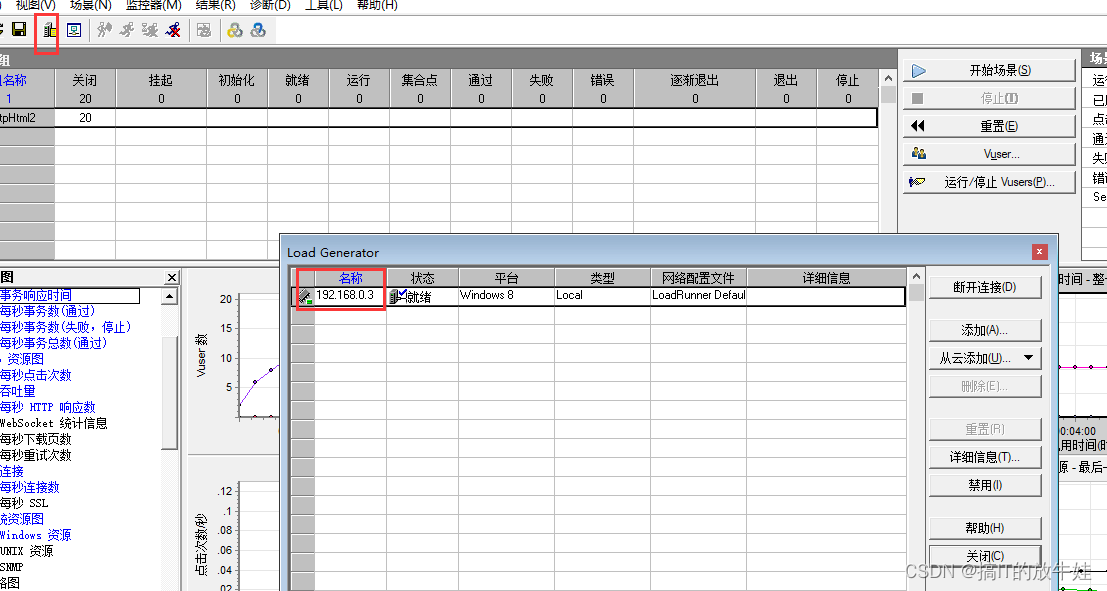

IP Wizard 应用
1). 勾选 Enabled IP Spoofer(启用IP欺骗)【必须】
2). 位置:菜单(Scenario) -> Enable IP Spoofer

删除IP
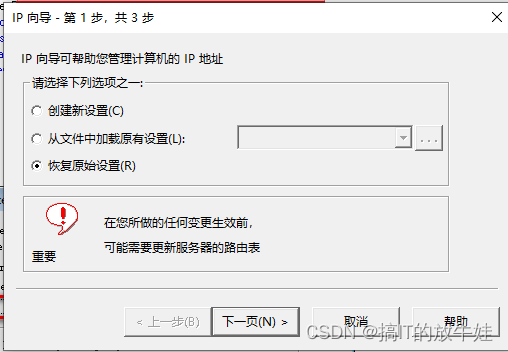
选择 Restore original set(恢复原始设置)
输入服务器IP地址
点击完成即可
使用IP Wizard 注意事项
使用 IP Wizard 必须确保 IP 地址为静态 IP,不能为动态(DHCP)IP
负载机必须启用 LoadRunner Agent Process 程序
运行场景时,启用 Enabled IP Spoofer 选项
虚拟用户模式选择进程模式(默认为线程) (Run-time Settings for script -> Miscellaneous(其他) -> Multithreading -> Run Vuser as a process)
启用专家模式 -> 菜单Tools -> Expert mode
设置多个 IP 模式为进程 菜单Tools -> options -> General -> Multiple Ip address mode(IP address allocation per process)
LoadRunner 安装目录下 dat 文件夹下 mdrv.dat 文件内 lr_socks 选项添加ExtCmdLineConc=-UsingWinInet Yes
忽略Web页面诊断 (菜单Diagnostics -> Diagnostrics Distribution -> Web Page Diagnostics...)
负载机需要设置 IP Wizard







二、练习
需求:
1. 业务:订票
2. 场景:20个用户使用订票业务
3. 要求:每个虚拟用户使用不同的 IP 进行订票;
2.1 操作步骤
录制订票业务脚本
搭建订票场景 用户数20
使用IP Wizard工具生成20个IP地址
启用IP欺骗(Enable IP Spoofer)
运行场景-查看虚拟用户日志
查看Analysis Result报告
2.2 场景搭建 示意图
1. 虚拟用户:20 2. 场景模式:场景 + 基础计划
2.2 用户日志


每个用户有自己的IP
lr_get_vuser_ip() 函数可以获取虚拟用户IP地址
用法:
char *ip;
ip = lr_get_vuser_ip();
if (ip)
lr_output_message("The IP address is %s", ip);
else
lr_output_message("IP spoofing disabled");
2.3 Analysis Result报告

Analysis Summary(结果摘要)
一、Analysis Summary 示意图
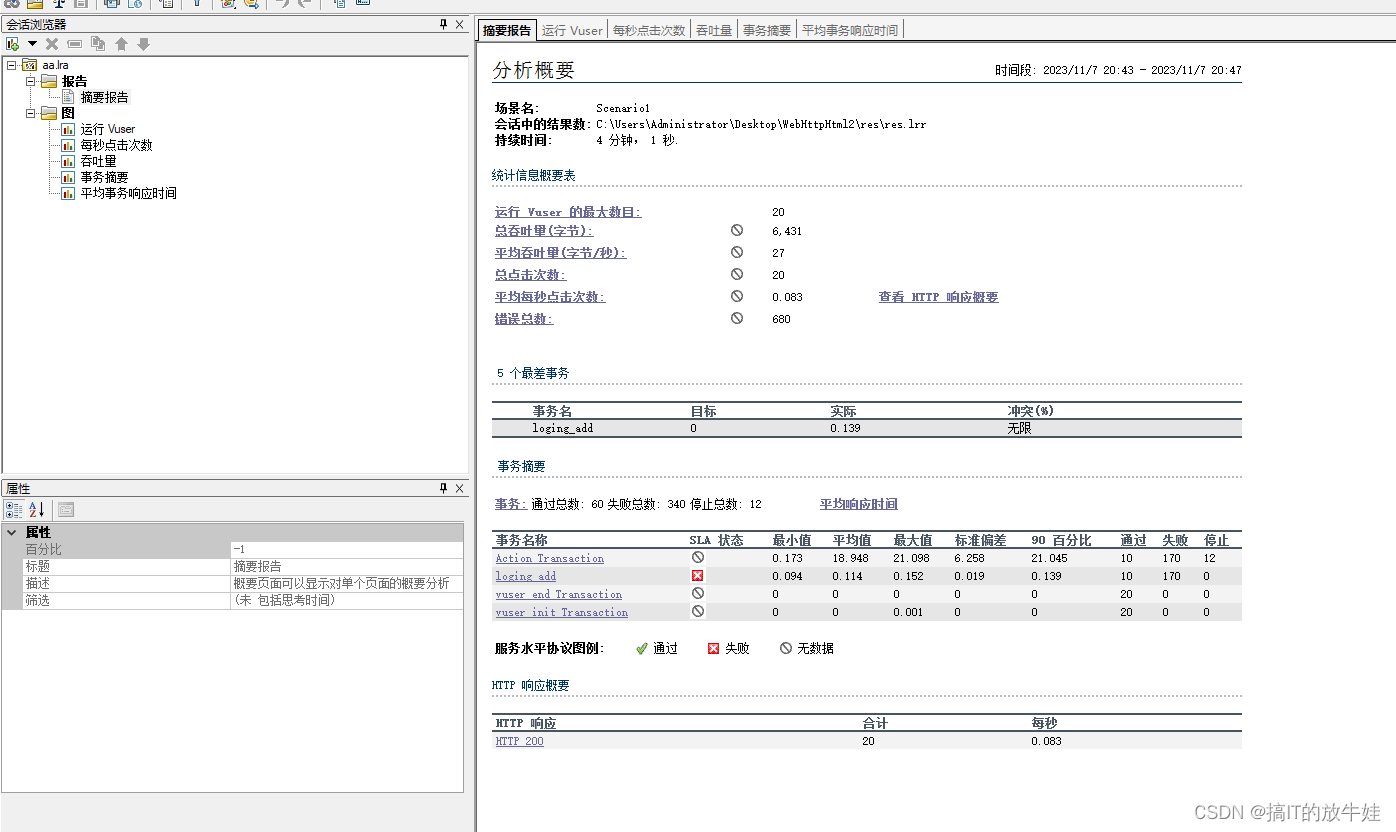
-
上图为 LR 进行场景测试结果收集后,首先显示的该结果的一个摘要信息,以简要信息列出本次测试的结果;
-
概要中包含以下几种摘要:
1). 场景及执行情况
2). Statistics Summary(统计摘要)
3). Transaction Summary(事务摘要)
4). HTTP Responses Summary(HTTP响应摘要)

1.1 场景及执行情况
Scenario Name:本次执行的结果来源那个场景;
Result in Session:结果保存目录;
Duration:本次场景运行持续时间。
1.2 Statistics Summary(统计摘要)

Maximum Running Vusers:最大运行用户数
Total Throughput(bytes):总吞吐量(字节)
Average Throughput(bytes/second):平均每秒吞吐量(字节)
Total Hits:总点击数
Average Hits per Second:平均每秒点击数
Total Errors:总错误数
1. 1MB = 1024KB 1KB = 1024Bytes 1MB = 1024KB * 1024Byte = 1048576 Byte; 2. 吞吐量越大,说明服务器处成理性能越好; 3. 请求数和吞吐量正比。
1.3 Transaction Summary(事务摘要)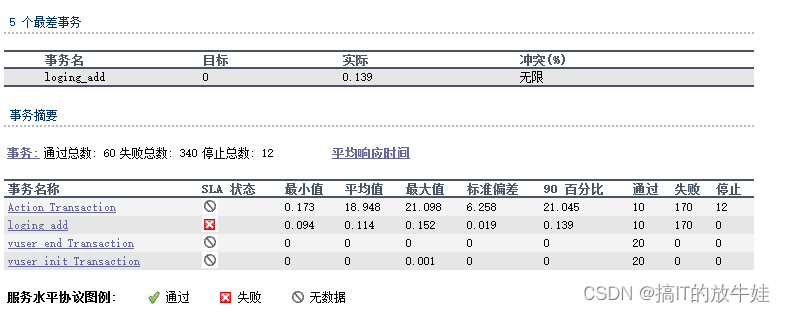
1). SLA Status:服务水平协议状态
2). Minimum:最小事务的时间
3). Average:平均事务时间
4). Maximum:最大事务时间
5). Std.Deviation:标准偏差
6). 90 Percent:90%事务小于等于这个时间
7). Pass:通过事务数
8). Fail:失败事务数
9). Stop:停止事务数
提示:
1). 以上时间单位为秒; 2). 标准偏差:越小越好,代表事务数据之间的差异大小程度,可以使用 Excel 中 STDEVP 函数计算出来
1.4 HTTP Responses Summary(HTTP响应摘要)

HTTP Responses:HTTP响应状态码
Total:总数量
Per second:每秒响应数
提示:HTTP响应代码200为服务器响应查询成功状态码,其他有关状态码请查询有关资料;
二、查看与添加图表
2.1 查看图表
在左侧图表列表处,点击要查看的图表,右侧区域显示图表结果

2.2 添加图表 添加默认未在右侧列表中显示的图表

1:点击弹出添加图表对话框
2:选中要添加的图表
3:点击添加选中的图表
提示:快捷键: Ctrl + A 可弹出添加图表对话框
2.3 可添加系列图表
Vusers:有关虚拟用户图表
Errors:有关错误图表,如:每秒错误率
Transactions:有关事务图表,如:平均事务响应时间
Web Resources:有关Web页面图表,如:每秒点击率
Web Page Diagnostics:有关Web页面组件图表,如:页面诊断
System Resources:有关服务器资源图表,如:CPU、内存、磁盘、网路
提示:
1. 以上系列图表,使用时候有时候需要进行合并,来更好的为系统调优做服务; (比如:Hits per Second与Average Throughput (bytes/second)合并,测试两款服务器性能) 2. 以上明细图表,关注【重要图表分析】章节
拐点分析法
一、什么是拐点分析法?

拐点分析是一种利用性能计数器曲线图上的拐点进行性能分析的方法。
1.1 拐点分析 基本思想
性能瓶颈主要产生原因就是某个资源的使用达到了极限,此时表现为随着压力的增大,系统性能却出现极具下降,这时产生了拐点现象;
思路:只要得到拐点附近的资源使用情况,就能定位出系统性能瓶颈所在;
1.2 订票系统
示例:
1.需求:
1. 注册和登录业务40虚拟用户混合场景(先执行40用户注册业务,然后使用40新注册用户去登录) 2. 场景策略-15秒启动2个用户,达到40用户时,持续5分钟,虚拟用户退出以每10秒退出5个策略 3. 登录业务40用户登录时<=3秒,CPU占有率不得超过80%
2. 运行用户与平均事务响应时间:

应用系统随着虚拟用户的增加,事务响应时间缓缓增加,当虚拟用户数达到17个时,事务响应时间超过预期3s持续增加,此时就说明了系统承载不了如此多用户访问这个事务,也就是存在瓶颈。
注意:上图为虚拟运行用户图和平均事务响应时间合并图
3. 运行用户与资源占用率 CPU:
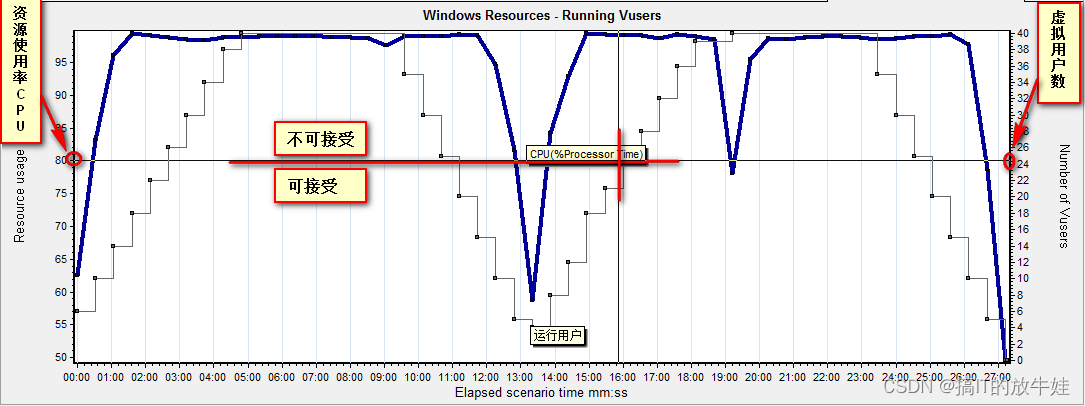
从上图得知,CPU不超过80%,目前配置最多支持25个用户。
合并图的应用
一、合并图表

合并图表是为了更好的定位系统瓶颈,比如把虚拟用户运行图和平均响应事务时间合并,能直观体现虚拟用户数量对服务器处理事务产生的影响
案例
使用订票脚本,设计个场景,场景需求设置: 设置: 1). 虚拟用户数20; 2). 场景模式 + 基本计划 3). 虚拟用户启动15秒启动2个,结束与启动相同; 4). 持续时间为2分钟。
二、Analysis合并图
Running Vusers(虚拟运行用户)
Average Transaction Response Time(平均事务响应时间)
在合并之前,我们先拿两张图来演示
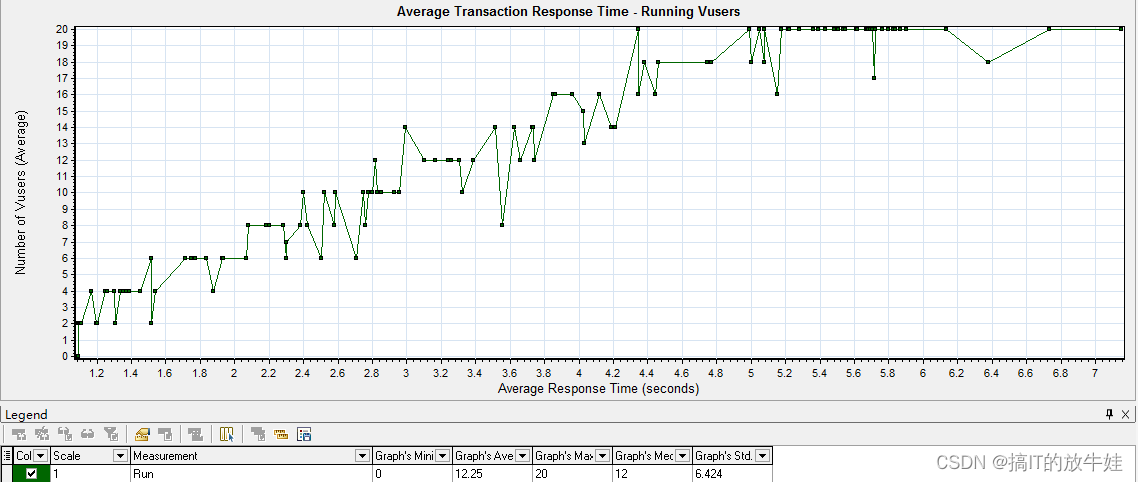
1). Running Vusers(虚拟运行用户)
2). Average Transaction Response Time(平均事务响应时间)


2.1 合并图操作说明

操作说明:
1). 打开合并选项菜单 (Ctrl + M 或者 在要合并的图表上点击鼠标右键 -> Merge Graphs) 2). 标1:选择要合并的图(并入) 如:Running Vusers 3). 标2:选择合并的方式: (1). Overlay(叠加) (2). Tile(平铺) (3). Correlate(关联)
2.2 合并方式-Overlay(叠加)


两个图使用相同的X轴,并入的图Y轴合并后在最右侧
2.3 合并方式-Tile(平铺)

两个图公用一个X轴,Y轴各自保持不变,并入图在上方
2.4 合并方式-Correlate(关联)
主图的Y轴变成合并后的X轴,合并图的Y轴,为合并后的Y轴;
合并的时候,需要把多余的线条给过滤掉,如:只留订票业务;
以上图为例,合并后X轴为平均响应时间,Y轴为虚拟用户数。
提示:在实际工作中,除了以上三种合并方式外,瓶颈分析还有一种方法-自动关联
三、自动关联应用
3.1 什么是自动关联?

LoadRunner使用统计信息算法去关联相似事务波段的指标,从而来定位某一瓶颈是由那些指标引起的
3.2 自动关联 关联对象-登录事务


可以选择指定关注的时间段;
选项设置一般为默认;[Trend(趋势-默认);Feature(相似)]
3.3 自动关联 指定-匹配的度量指标

四、常用合并图表组合 说明
平均事务响应时间与虚拟运行用户
平均事务响应时间与吞吐量
每秒点击数与吞吐量
每秒点击数与平均事务响应时间
4.1 平均事务响应时间与虚拟运行用户 合并图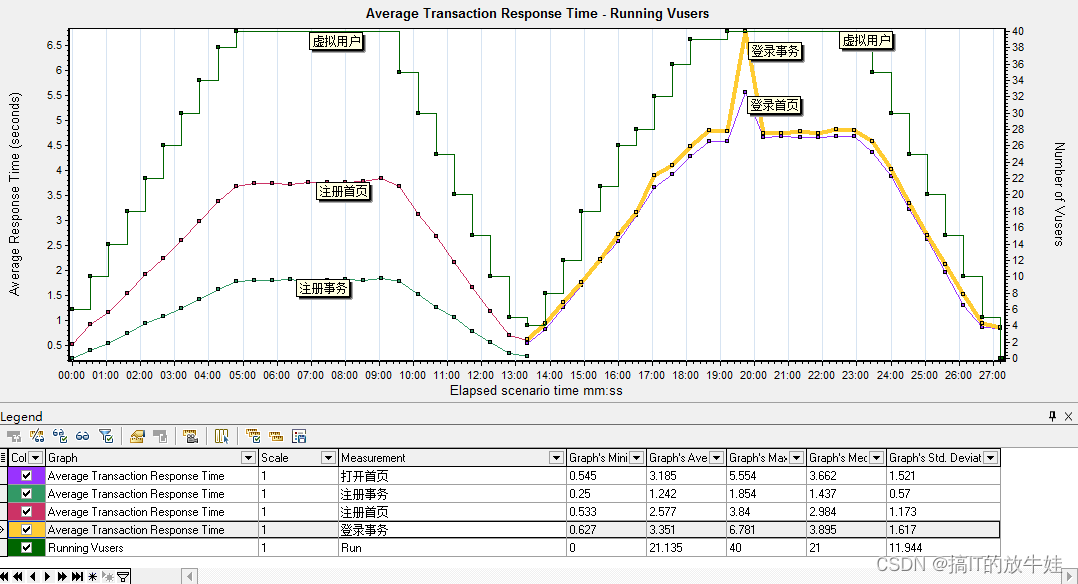
平均事务时间和运行用户图合并能直观体现 虚拟用户数对不同事务的影响
分析:
1. 从上图看出,虚拟用户数对登录事务的影响明显高于注册事务;首先确定一点,应用服务器对40用户并发请求处理是没有问题的。 2. 如果需求登录40并发<=3秒的话,需要进一步结合页面组件细分图及每秒点击率来分析
4.2 平均事务响应时间与吞吐量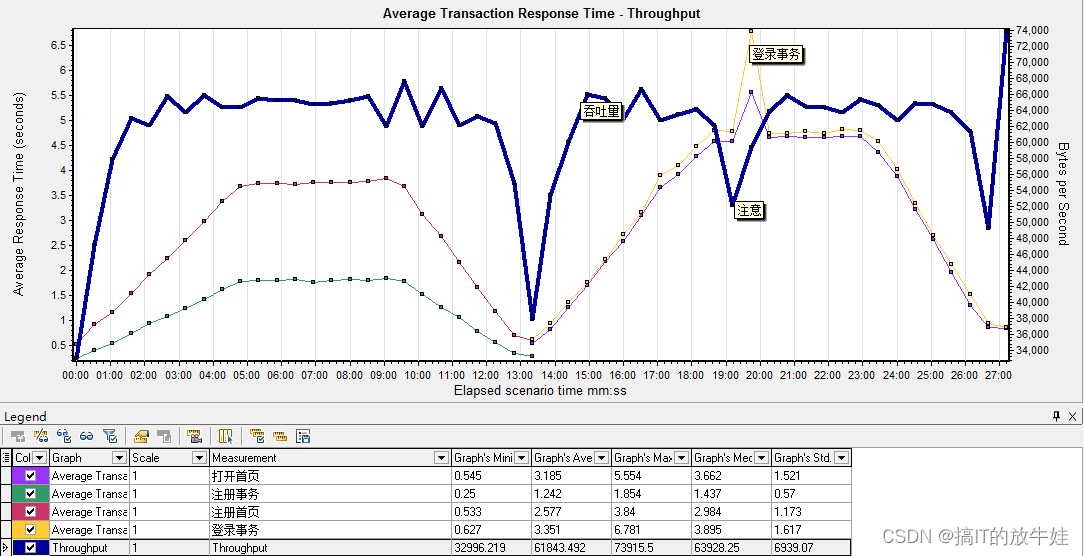
平均事务响应时间与吞吐量结合,可以看出单个事务对吞吐量的影响
分析:
1. 从上图中看出,登录事务响应时间忽然拉长,系统吞吐量直线下降,说明,系统并不是因为总吞吐量的问题导致登录响应延长,基本确定是登录资源或登录业务代码问题; 2. 具体是登录资源还是登录业务,需要结合页面组件细分图和每秒点击数来确定是哪个问题;
4.3 每秒点击数与吞吐量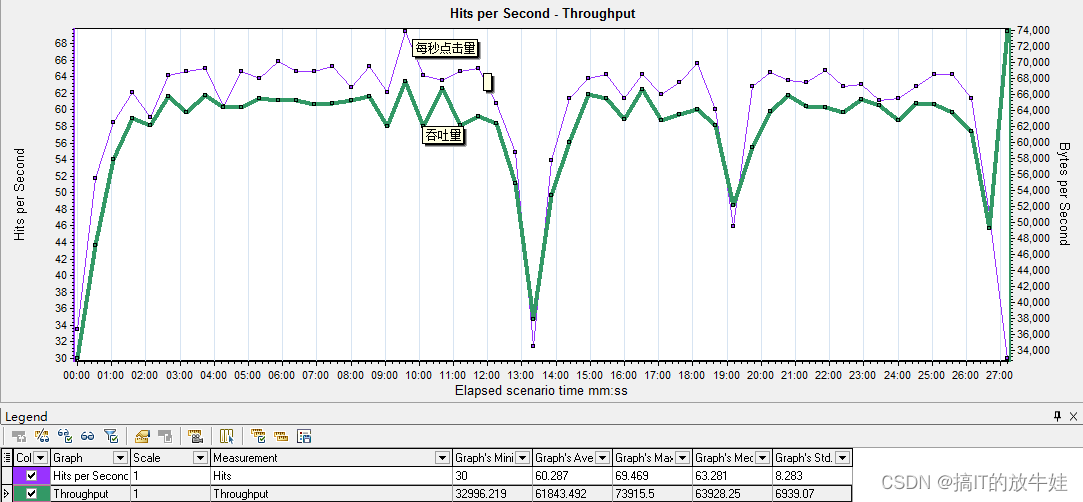
分析:
1. 吞吐量不正常那么说明,应用程序响应时间慢 2. 点击量不正常那么说明,网络存在问题,需要检查网络相关报表
提示:一般测试不同配置服务器性能时,这两张图合并最好用
4.4 每秒点击数与平均事务响应时间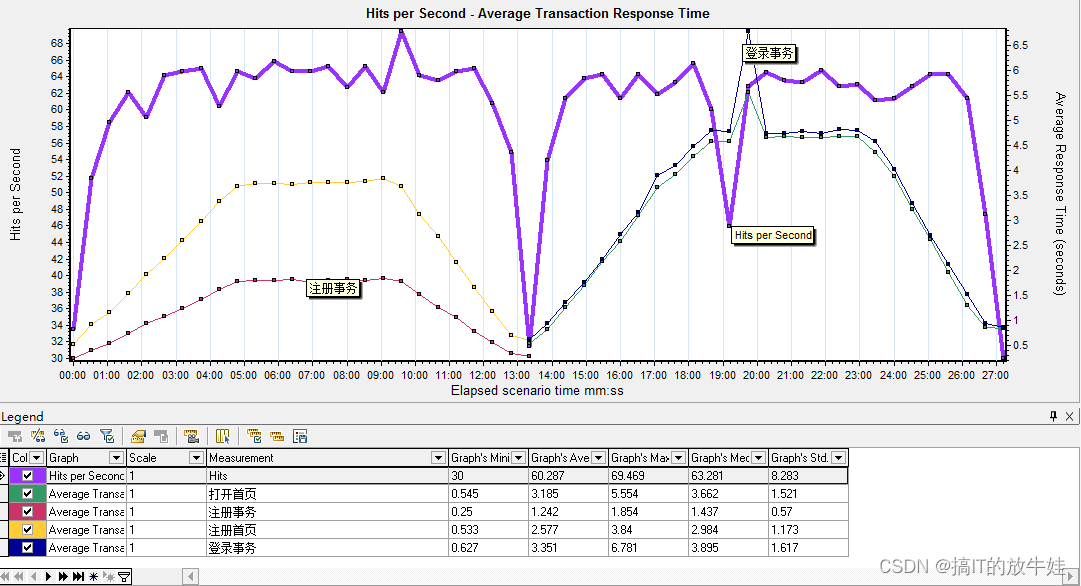
查看每秒点击数对事务的影响
分析:
1. 每秒点击数对注册业务影响很小,注册业务最高每秒点击了69次 2. 每秒点次数对登录业务影响很大,登录业务有请求异常缓慢,需要结合页面组件细分表来确认是那个组件请求
交叉结果与性能报告生成
一、交叉结果的应用
本轮的测试结果诞生是根据上一轮测试结果进行分析、由相关人员进行调优后进行的重新测试,需要确定调优是否有所改善
交叉结果是指相同场景下两次测试结果进行交叉对比,在 LR 中把这种对比两次结果指标叫做交叉结果
交叉结果应用
在Analysis工具点击File菜单 -> Cross with Result...
点击Add添加上次结果目录文件 (.lrr)

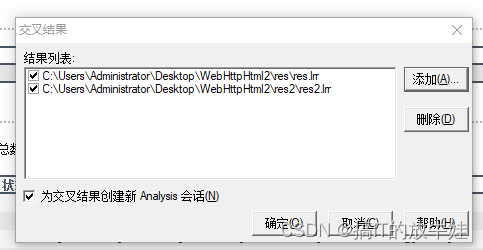
提示:
1. .lrr文件为场景运行后的收集的结果,默认保存在当前用户下的临时文件夹 (如:C:\Users\Administrator\AppData\Local\Temp) 2. .lrr保存目录,可在菜单【Result】-> Set Result Directory进行修改
效果图

之前两张报表有的数据都会产生对比,以上摘要报告只是举例说明
二、性能报告生成
LoadRunner 支持导出非常丰富的报告类型(如:HTML、Word、PDF)等,我们常用的是Word(可编写)
2.1 生成报告 步骤
生成模板
在模板上导出指定报告类型
1. 生成模板

在Analysis菜单(Reports) -> New Report
直接点击 Generate(生成)模板

提示:
General、Format、Content为选填信息,可以不填,我们需要修改自己公司关注的东西; 1. General(普通选项):标题、作者等信息 2. Format(报告格式):报告格式设置 3. Content(报告内容):报告内容修改等
2. 导出报告

1:在报告模板内选择Save菜单 -> Microsoft Word 2007 File...
2:导出设置,默认ALL(全部)导出 直接点击OK
3:保存报告路径和名称
提示:
1. 以上为Word版格式,导起来稍微繁琐,因为我们常用的Word格式,可以对报告内图表文字进行修改; 2. 如果需要导出HTML格式报告,菜单(Reports) -> HTML Report
主要图表分析说明

重要图表系列
虚拟用户相关图表
错误相关图表
事务相关图表
Web资源相关图表
网页诊断相关图表【Web项目关注 重点】
系统资源相关图表
提示:
1). 选中“Display only graphs containing data”:只显示有数据的图表; 2). 取消选中:蓝色字体代表有数据,黑色代表无数据; 3). 以上系列内,我们说几个比较常用的图表
一、 虚拟用户相关图表
1.1 Running Vusers(运行虚拟用户)【重要】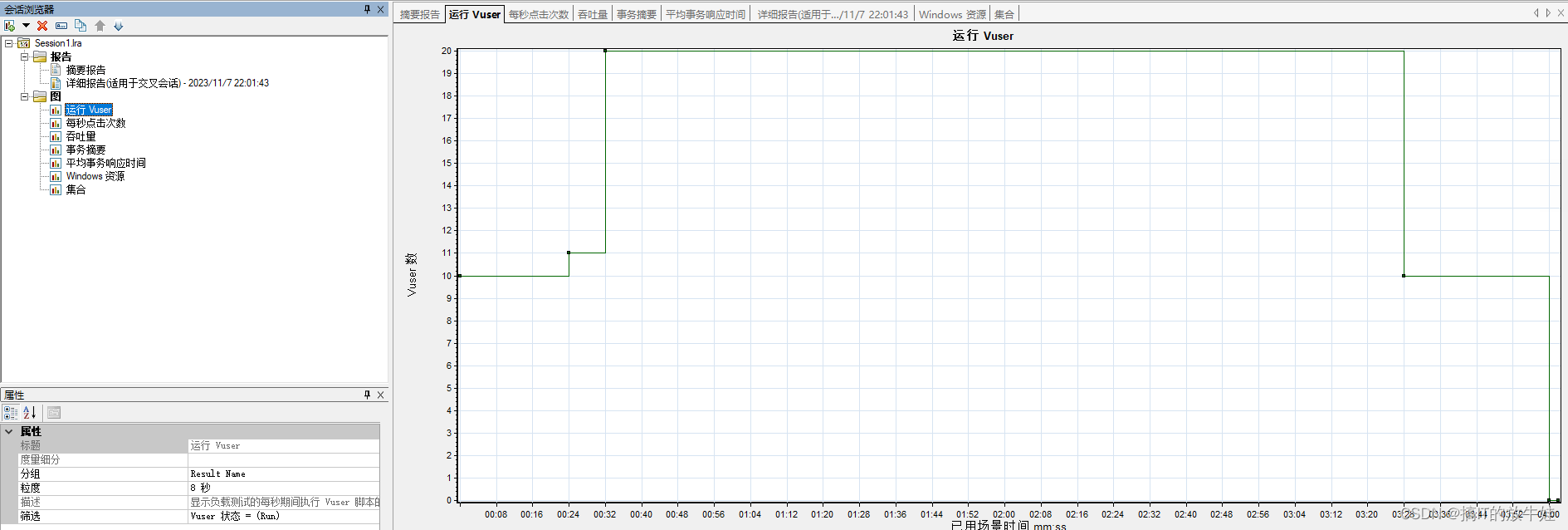
在运行期间虚拟的整体用户运行情况:
1. 横轴:为运行时间 2. 纵轴:显示处于运行状态的虚拟用户数
提示:Running Vusers与平均事务响应时间合并,直观体现用户数量对服务器处理事务产生的影响
二、 事务相关图表 【重要】
2.1 平均事务响应时间(Average Transaction Response Time) 【重要】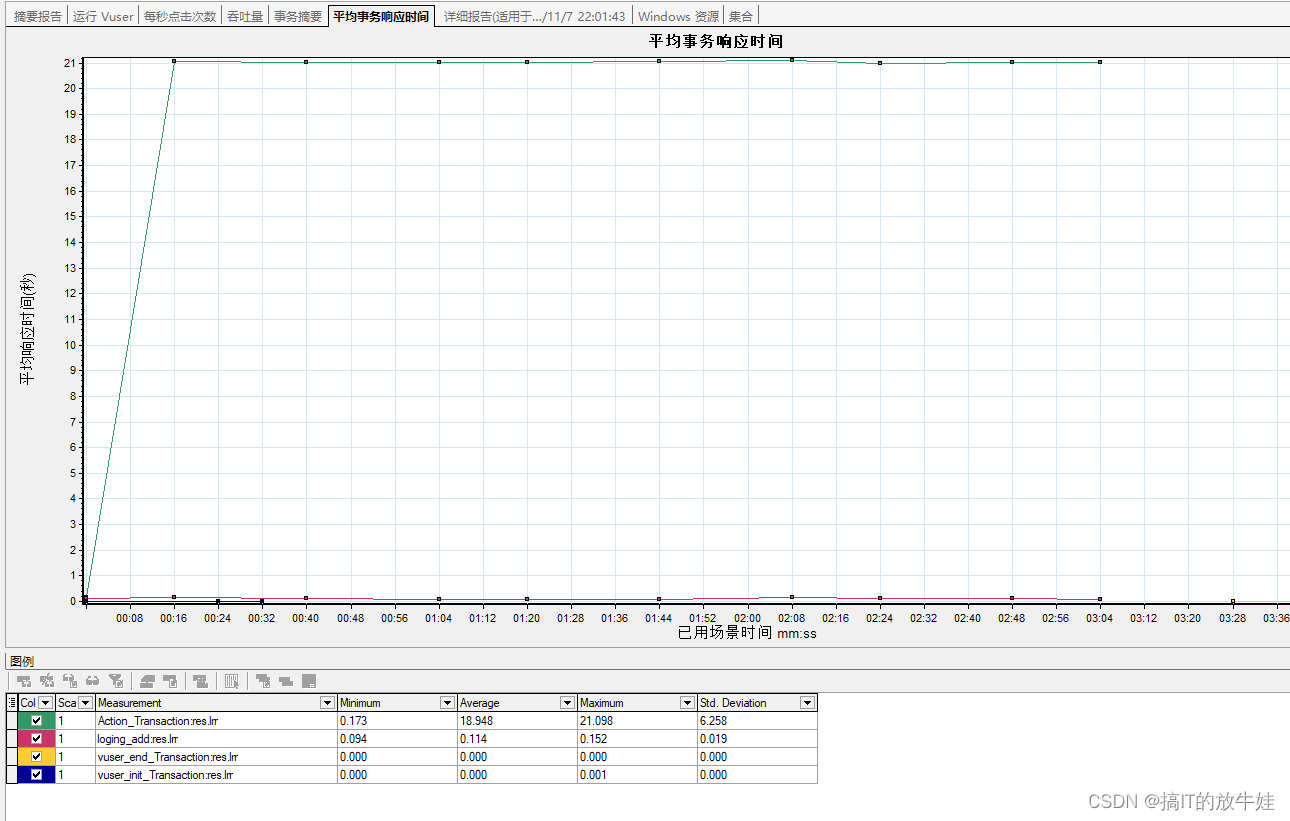
通过平均事务响应时间图表查看性能测试过程中每一秒用于执行事务的平均时间
2.2 每秒事务数(Transaction per Second) 图表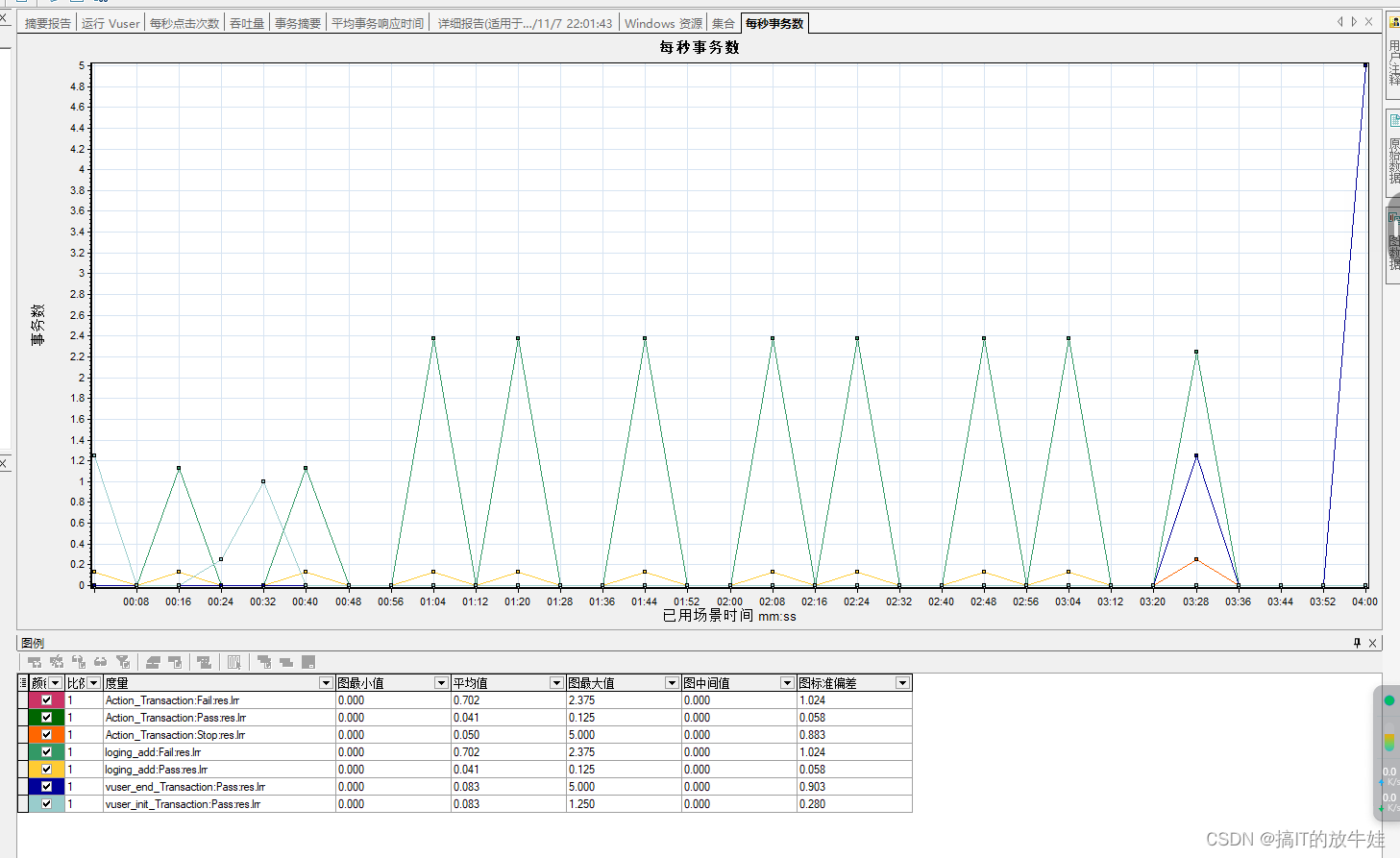
通过该图性能测试过程中每一秒内系统上的实际事务负载
2.3 每秒事务总数(Total Transactions per Second) 图表

通过该图查看性能测试过程中每一秒内,成功通过事务总数、执行失败的事务总数和停止的事务总数
2.4 事务摘要(Transaction Summary)

通过该图查看性能测试过程中执行失败、执行通过、停止和因错误而结束的事务概要信息 (业务成功率一般就是在事务摘要体现,摘要内如果事务都是通过,那么业务成功率就是100%)
2.5 事务性能摘要(Transaction Performance Summary) 图表

通过该图查看性能测试过程中所有事务的最小、最大和平均响应时间,以不同的颜色代替
2.6 负载下的事务响应时间表(Transaction Response Time Under Load) 【重点】
该图其实是事务响应时间图与虚拟运行用户图的组合,很直观体现随着虚拟用户的增加,对事务响应时间的影响
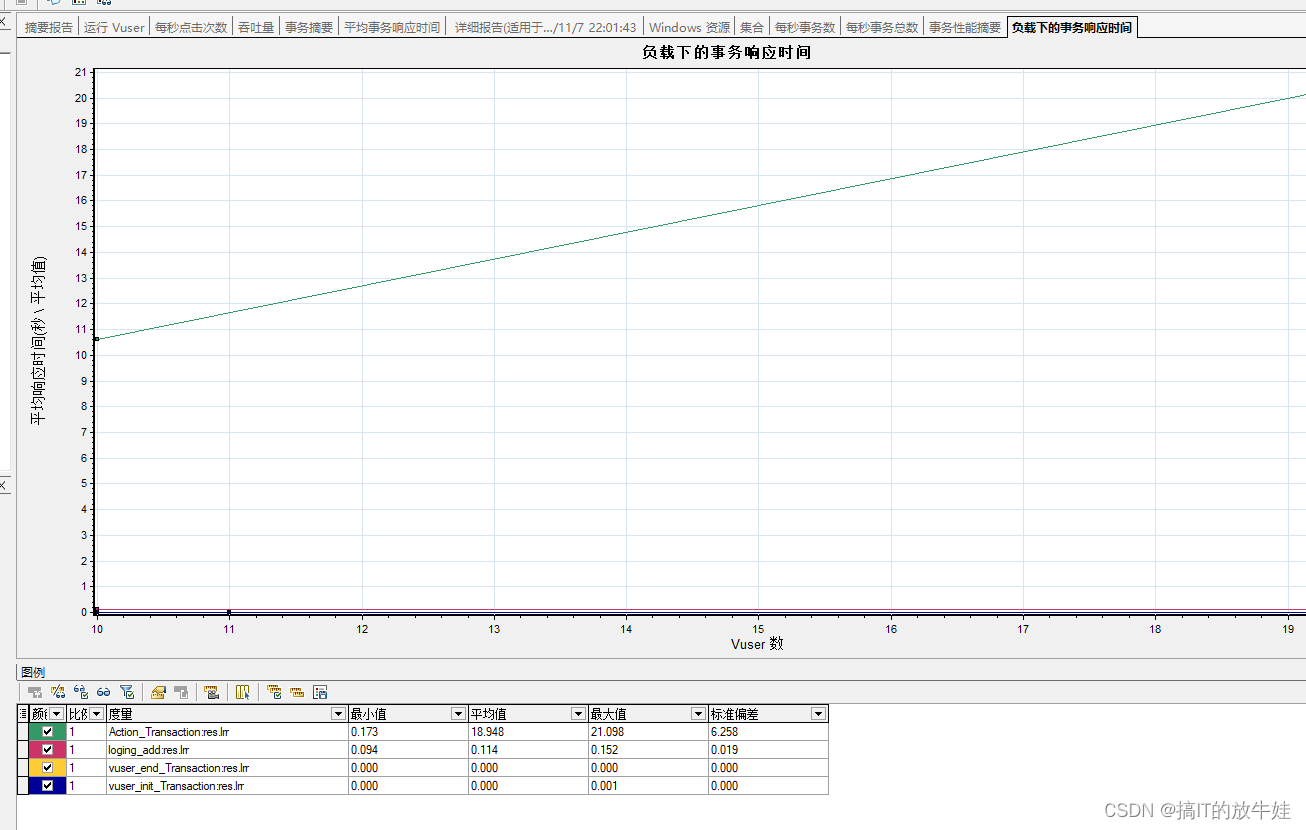
在做持续压力测试的时候,这张图最好使
2.7 事务响应时间(百分比)(Transaction Response Time (Percentile))

该图有助于确定事务响应时间是否符合需求所定义的性能指标百分比 (如:80人并发登录时候,90%用户登录业务时间小于3秒)
三、错误相关图表
在性能测试场景执行过程中,虚拟用户可能无法成功完成所有事务,可以通过错误相关图表查看相关错误信息
3.1 错误信息统计(按描述)(Error Statistics (by Description))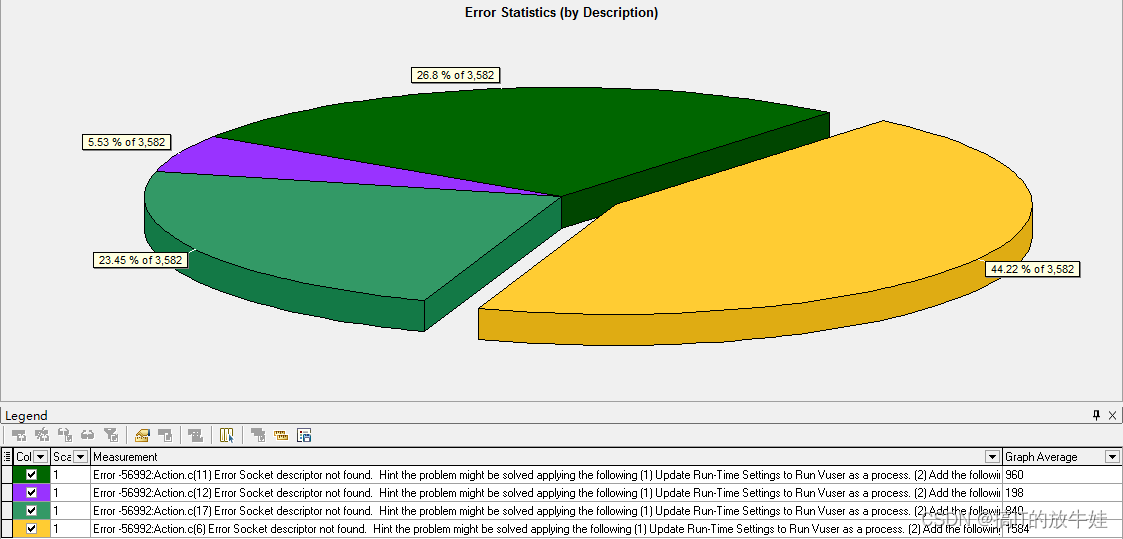
通过该图查看性能测试过程中发生的错误数(分组:按描述),以上图相同错误代码,不同描述共5次错误总次数:3582次,不同的错误描述,占比不同
3.2 每秒错误数(Errors per Second)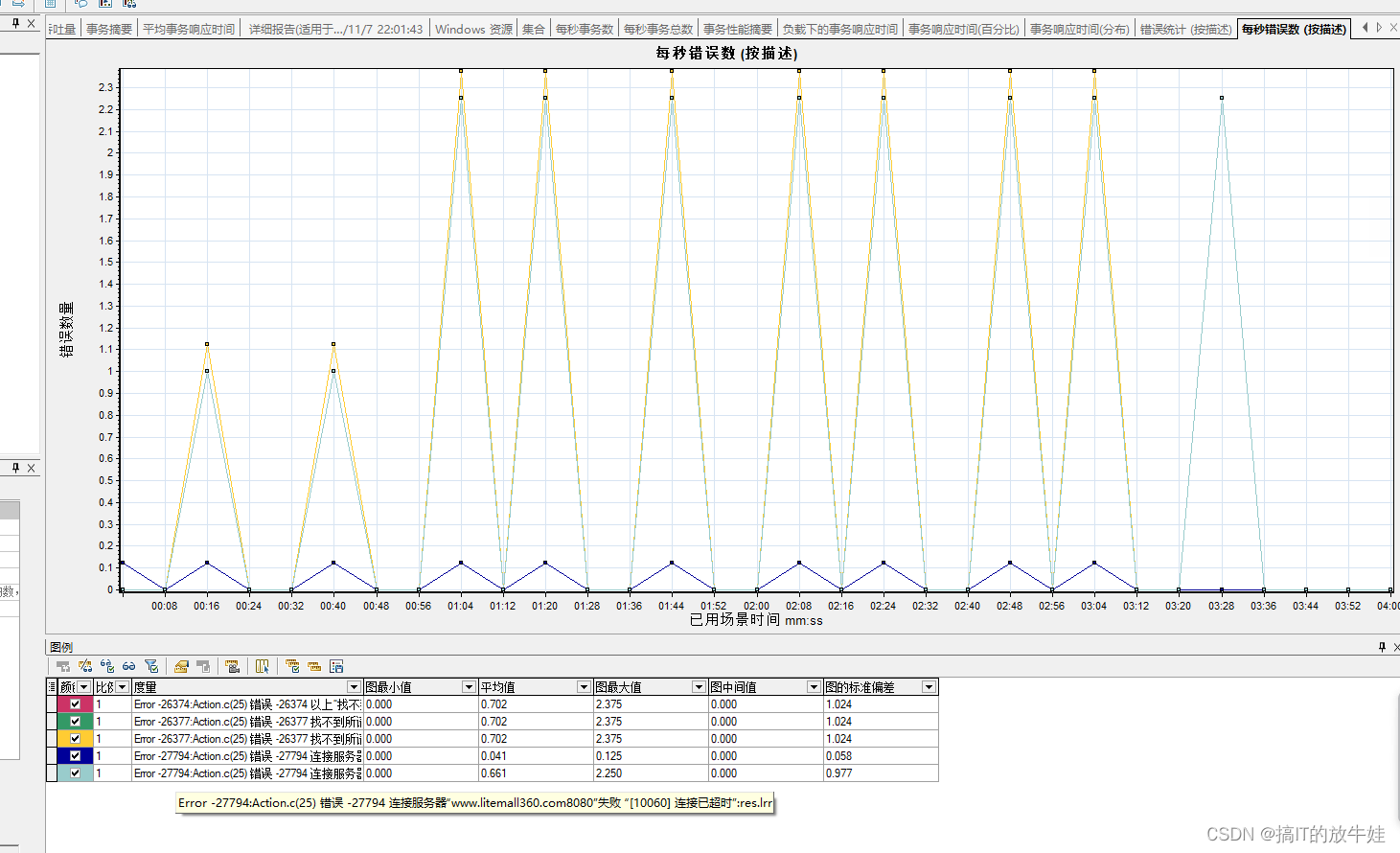
此图按代码分组,此图非常直观显示在场景运行时间中,不同错误类型,产生的错误数
四、Web资源相关图表
Web资源相关图表提供Web服务器性能相关信息
4.1 每秒点击数(Hits per Second) 图表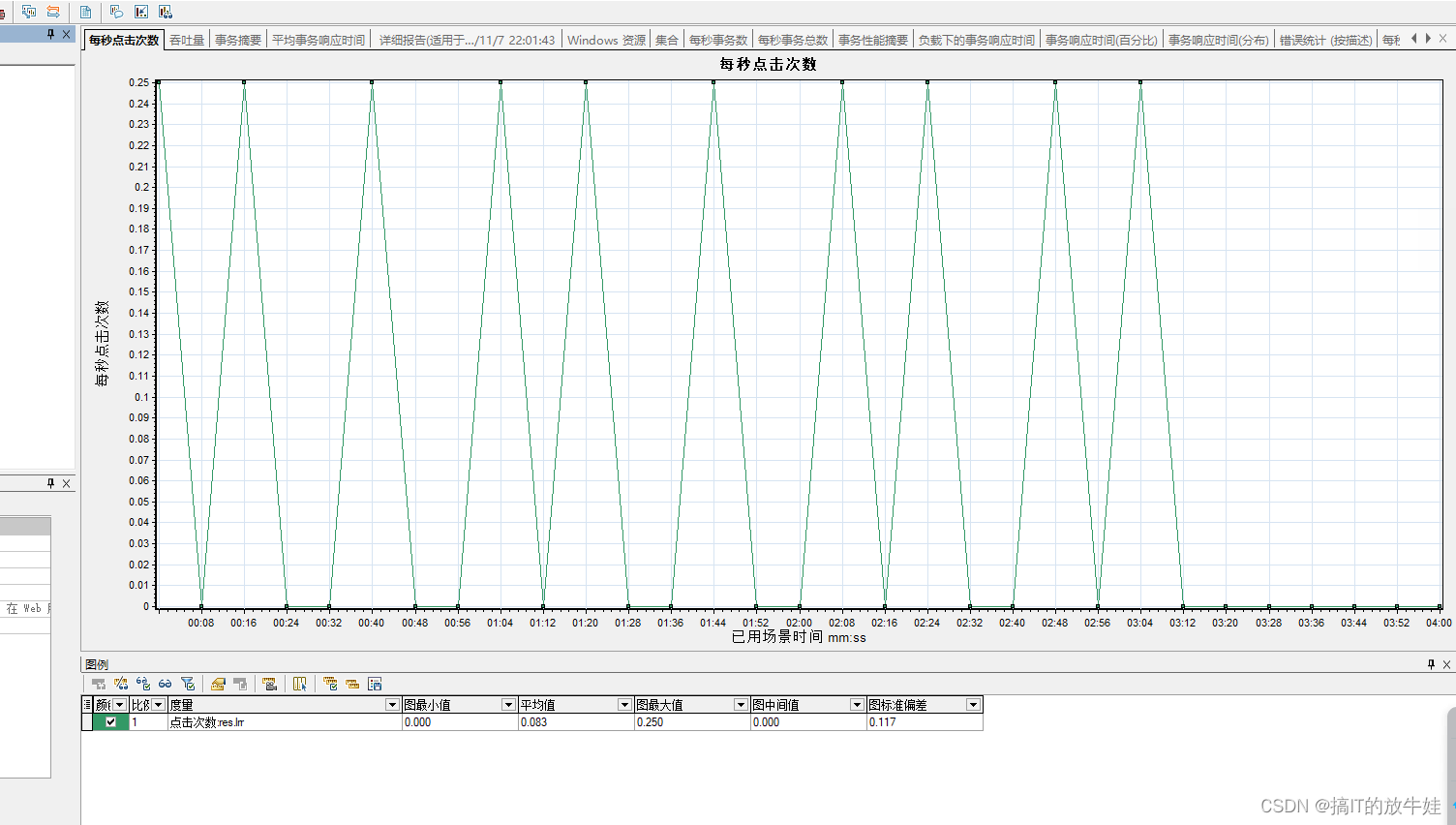
通过该图表查看性能测试中每秒内虚拟用户向Web服务器发送的HTTP请求数
提示:
1). 每秒点击数图表基本和HTTP Responses per Second(每秒响应数)一样; (因为点击数数据其实就是通过服务器返回的响应数做统计的) 2). 该图表和平均事务响应时间合并,查看单击数据对事务性能的影响。
4.2 吞吐量(MB)(Throughput(MB)) 图表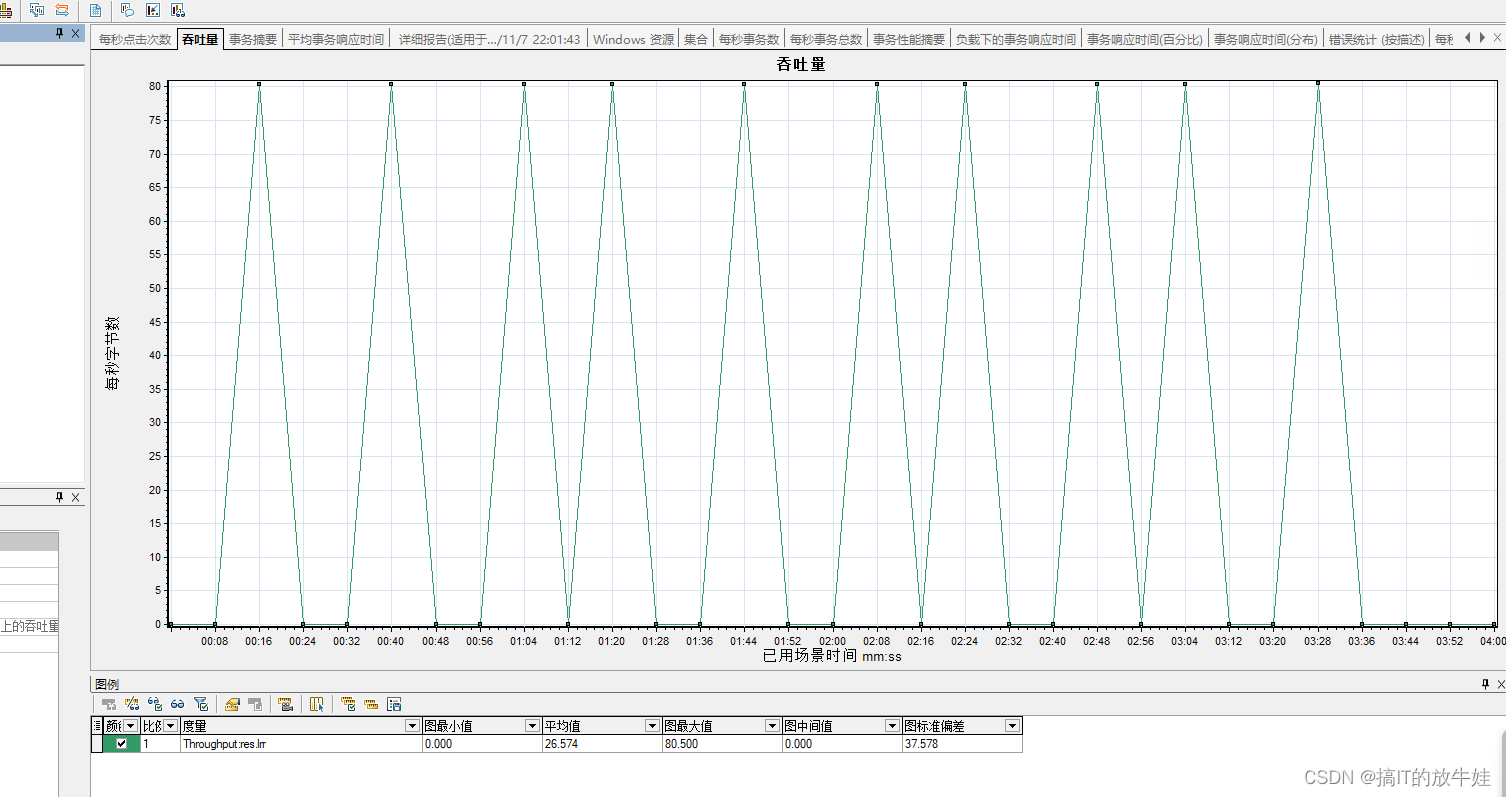
提示:该图与平均事务响应时间合并,查看吞吐量对事务性能的影响
五、Web网页诊断 相关图表
网页诊断图表提供每个页面的下载时间、下载过程出现的问题、页面内下载组件的大小等
5.1 网页分析诊断(Web Page Diagnostics)图表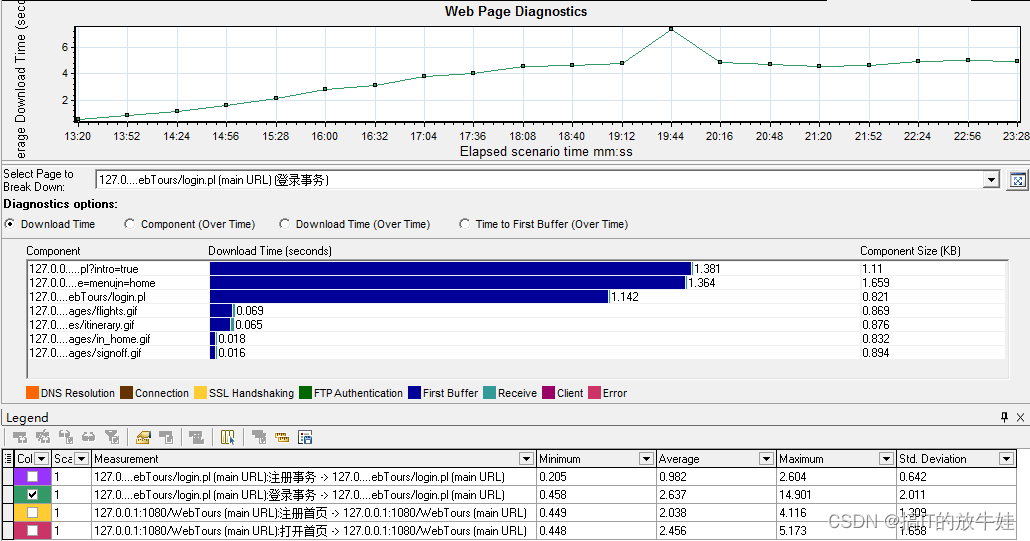
选择指定事务进行细分,如:登录事务,显示页面下载时间,页面内具体组件下载时间、大小
提示:
First Buffer(第一次缓冲时间):从HTTP请求到收到Web服务器返回的第一次缓冲所经过的时间; 度量可以准确指示Web服务器延迟和网络延迟。
5.2 页面组件细分(Page Component Breakdown)图表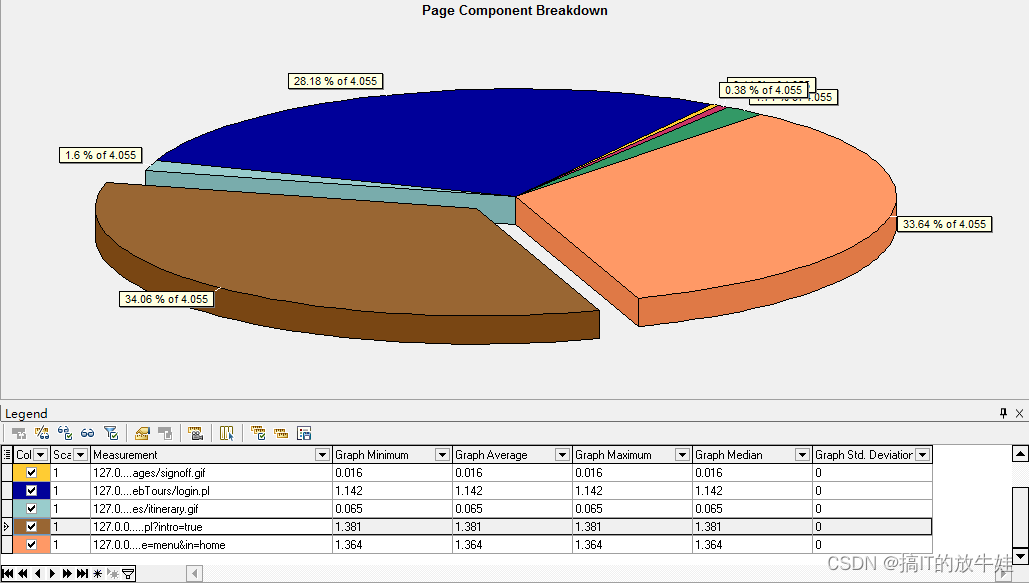
该图显示每个网页及组件的下载时间以及每个组件占用当前页面的下载时间的百分比 (通过此图很直观看出当前事务内下载资源占比情况)
5.3 页面下载时间细分(Page Download Time Breakdown)图表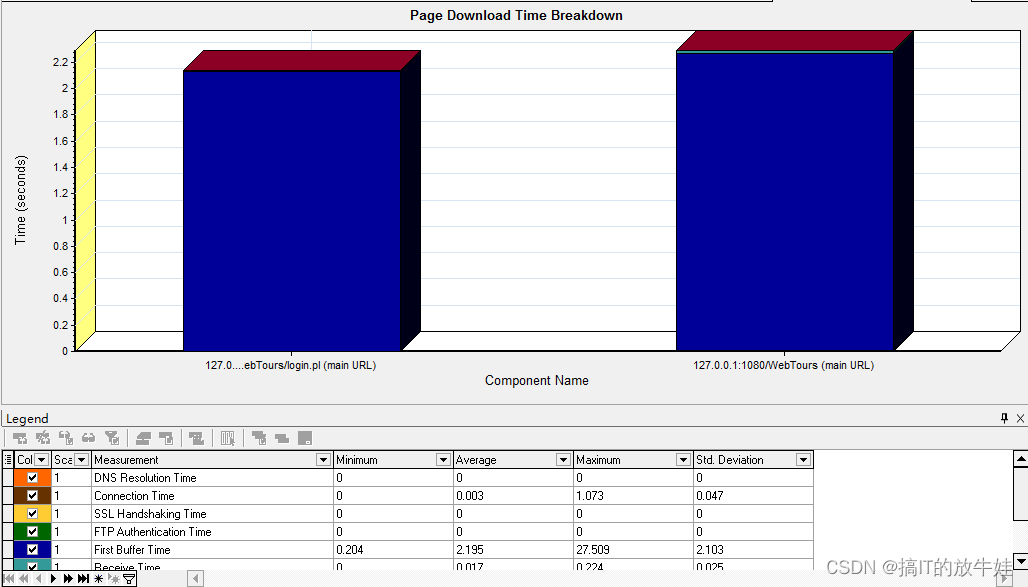
通过该图查看页面下载期间是网路原因还是服务器处理能力较差导致响应过慢:
1). DNS Resolution Time :DNS域名服务器解析域名所需时间 2). Connection Time:连接时间-客户端与应用服务器初次建立连接时间(度量网路及服务器是否响应请求) 3). SSL Handshaking Time:建立SSL(证书、秘钥)连接需要时间(度量HTTPS协议通信时使用) 4). FTP Authentication Time: FTP身份验证时间 5). First Buffer Time:第一次缓冲时间-第一次请求服务器到服务器返回第一次缓冲所需要时间(度量网络或服务器延迟) 6). Receive Time:接收时间-从开始接收到服务器传过来最后一个字符所需要时间 7). Client Time:客户端时间-客户端浏览器的延迟 导致请求在客户端延迟的平均时间 8). Error Time:错误时间-发送HTTP请求到返回错误信息所用的平均时间
5.4 第一次缓冲时间细分(Time to First Buffer Breakdown)图表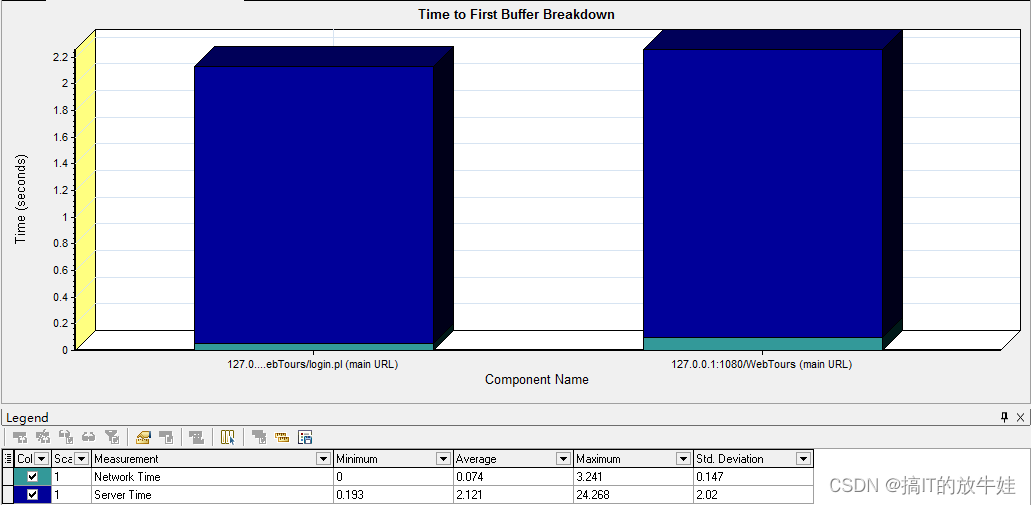
通过该图查看成功收到Web服务器返回的第一次缓冲之前的时间段内,每个网页组件的相对服务器时间、网络时间
提示:
1. 网路时间:客户端发出HTTP请求到服务器收到HTTP请求消息的平均时间;(网络传输请求的时间) 2. 服务器时间:服务器接收到请求开始到返回浏览器第一次缓冲所有的平均时间
注意:
第一次缓冲时间是在客户端进行计算的,所以是估计值(不太精准)
5.4 下载组件大小(KB)(Downloaded Component Size(KB))图表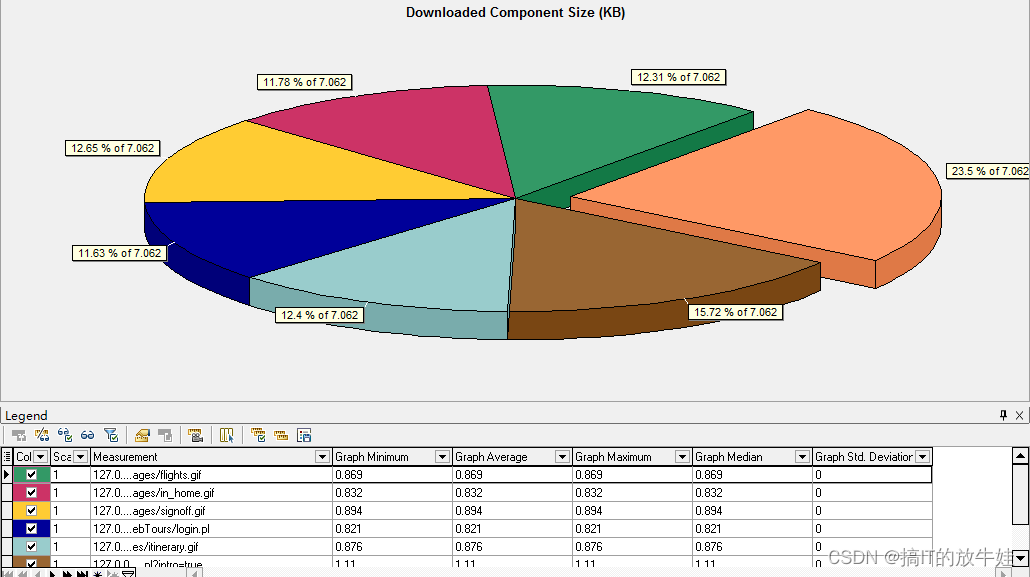
通过该图查看每个网页及其组件大小(KB)
六、系统资源相关图表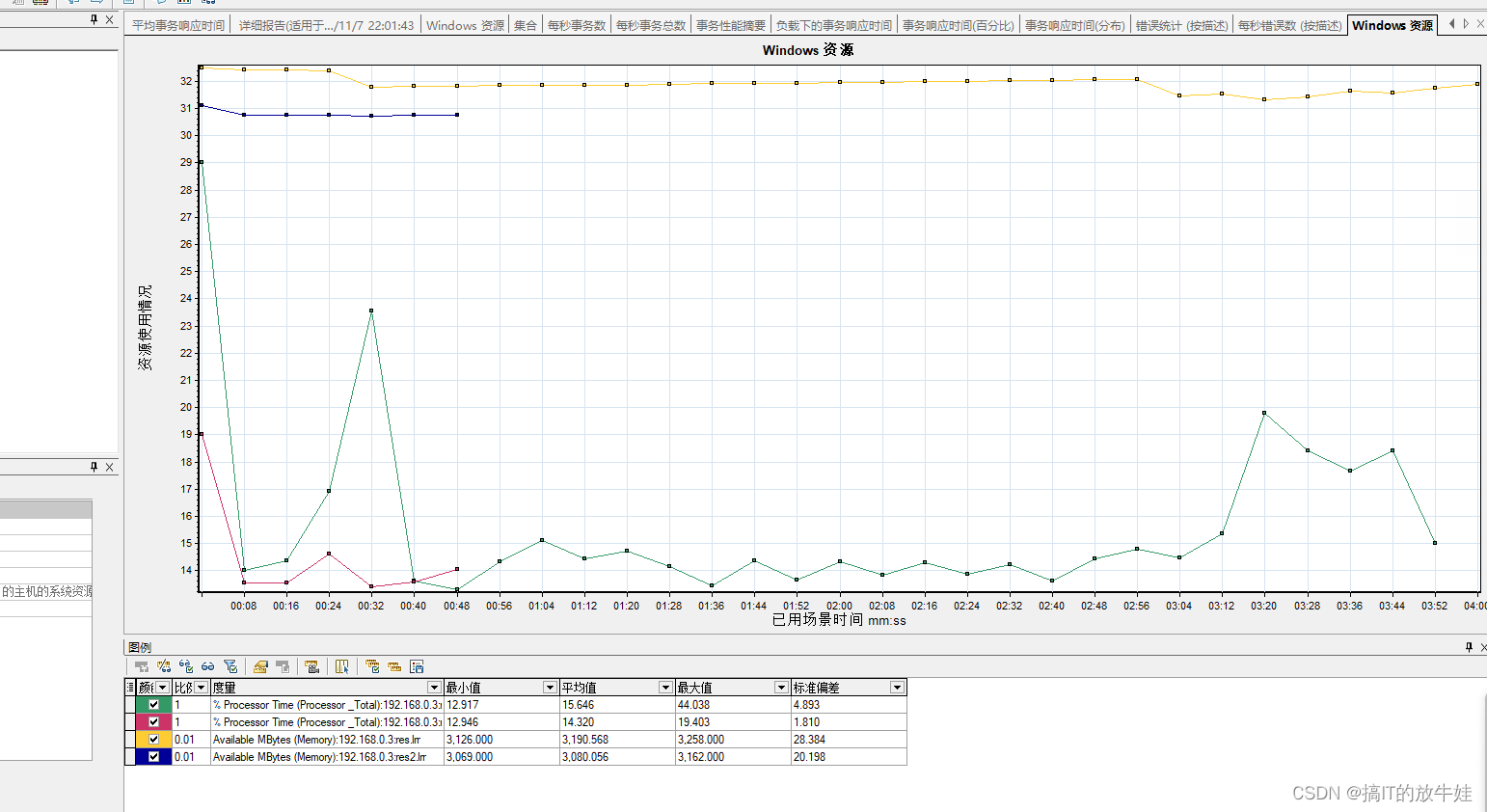
系统资源图表是在负载测试场景运行期间联机监控所监测的系统资源,通常需要对CPU利用率、内存和磁盘等进行监控
提示:
1. 系统资源标一般需要与虚拟运行用户、事务相关表进行合并,查看运行相应业务时资源利用率是否达标; 2. 在这里我们以windows Resources为例
6.1 CPU、内存、磁盘常用关注指标(CPU、内存、磁盘)
| 指标名称 | 含义 | 关注点 | 建议值 |
|---|---|---|---|
| % Processor Time | CPU利用率 | 1. CPU使用率峰值:最大值即为CPU的使用率峰值 2. CPU平均使用率:平均值为CPU的平均使用率 | 75%-85%之间;过低则CPU利用率不高,过高则CPU成为系统瓶颈 |
| Available MBytes(Memory) | 可用内存(MB) | 1. 内存占用率峰值(%) = (最大物理内存 - 最大空闲内存) / 最大物理内存 * 100% 2.内存平均使用率(%) = 最大物理内存 - 平均空闲内存数 / 最大物理内存 * 100% | 可用内存保留20%左右 |
| % Disk Time | 硬盘读写时间比 | 正常值小于10 | 此值过大表示耗费太多时间来访问磁盘,可以考虑增加内存,或更换更快的硬盘来进行优化 |
6.2 Windows Resources - Running Vusers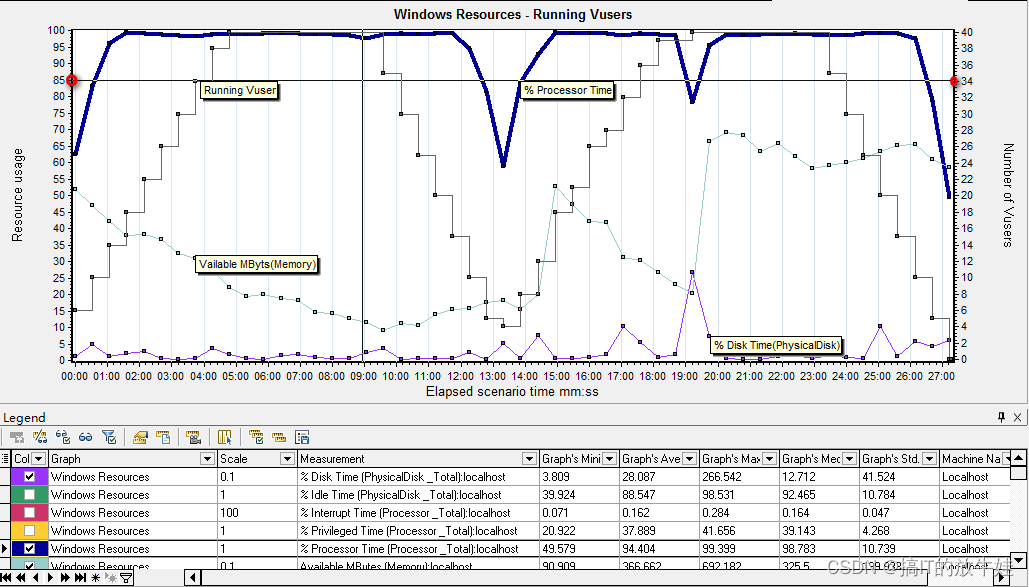
虚拟运行用户与Windows Resources表合并,查看运行用户数的增加对CPU、内存、磁盘等资源影响信息
分析:
虚拟用户达到34时CPU使用率以达到85%,CPU以出现瓶颈必须地进行CPU相关升级;
6.3 Windows Resources - Average Transaction Response Time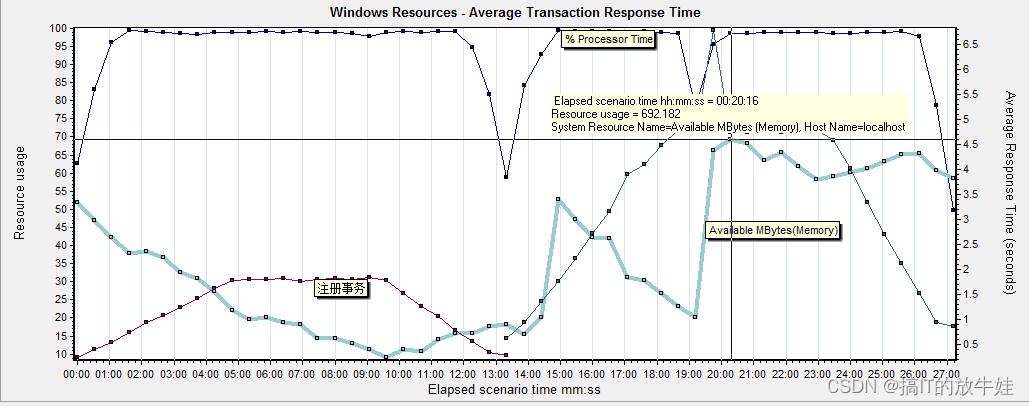
平均事务响应时间和CPU、内存合并图
分析:
从上图看出,40并发 登录事务最高使用内存70%,说明内存可用内存还有20%满足系统使用指标
Linux相关监控
Linux资源监控方式
命令
第三方工具(nmon)
LR(需要安装RPC相应服务包和开启服务)
一、命令 方式
top (系统资源管理器)
vmstat (查看虚拟内存状态)
free(查看未使用的和已使用的内存数目)
iostat (查看io磁盘信息)
sar 网络
1.1 命令 top(系统资源管理器)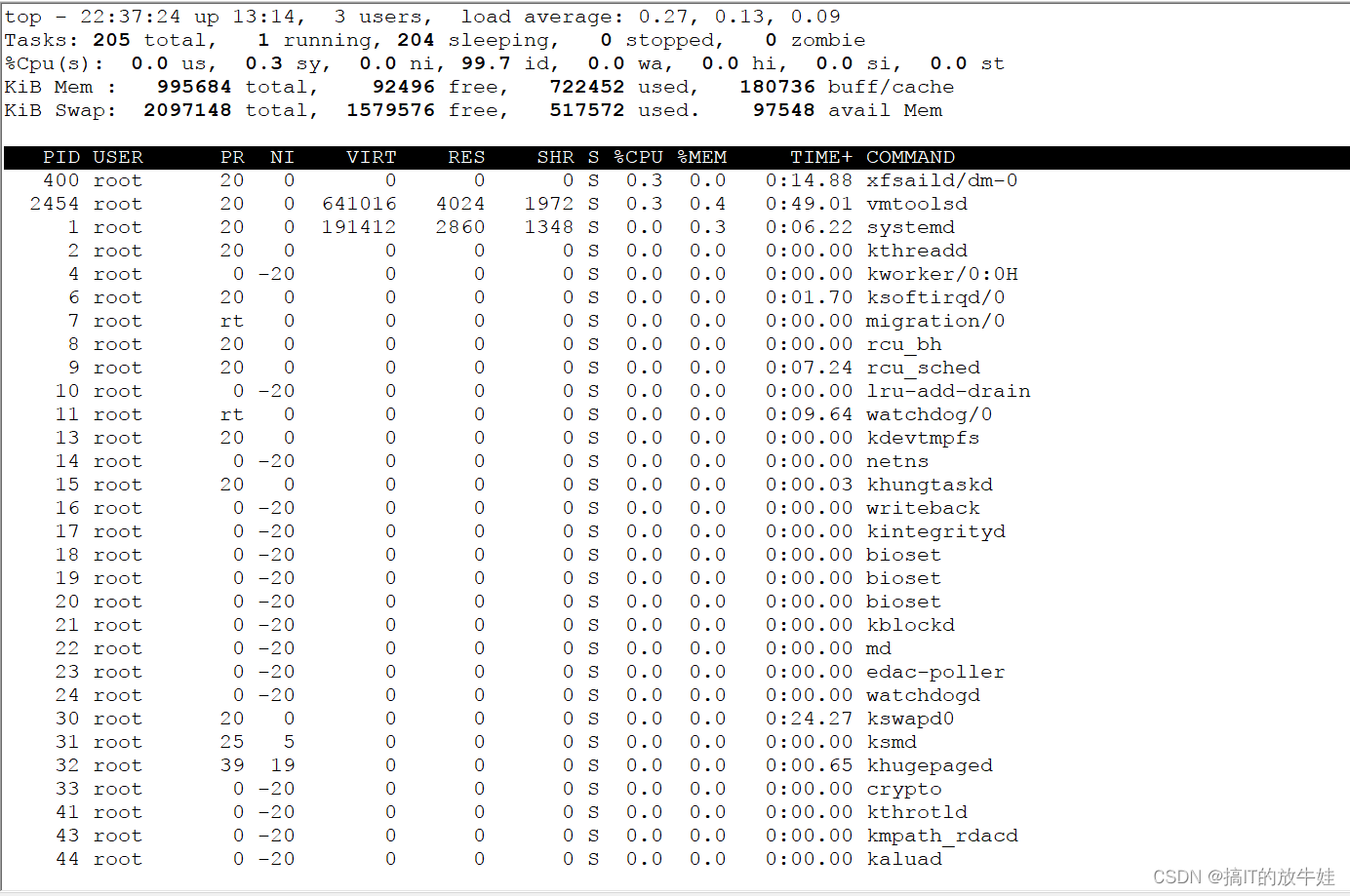
top命令类似与windows的任务管理器,查看内存、CPU、进程等操作信息
在Linux系统中常用top命令做资源性能分析工具
核心:
1). 前五行显示系统整体的统计信息; 2). load average 代表负载队列到现在平均长度(三个时间段),1分钟、5分钟、15分钟 【重点关注】
参数:
1). 第一行 任务列队基本信息 【关注系统负载】 - 06:49:14 :系统当前时间 - up 2:32 :系统运行时间 2小时32分钟 - 3 users:当前登录用户数 - load average:系统负载,即任务队列的平均长度-(1分钟、5分钟、15分钟)到现在的平均长度 2). 第二行 进程列队信息 【了解】 - Tasks : 201 total 进程总数 - 2 running 正在运行进程数 - 199 sleeping 睡眠进程数 3). 第三行 CPU信息 - 0.3 %us:用户空间占用CPU百分比 - 0.3 %sy: 内核空间占用CPU百分比 - 99.2%id: 空闲CPU百分比 【关注】 4). 第四行 内存信息 - Mem : 3908524k ktotal 物理内存总量 - 1294032k k used 使用的物理内存总量 - 2614492k k free 空闲内存总量 【关注】 - 74352k k buffers 用作内核缓存的内存量 5). 第五行 交换区内存 【了解】 - Swap : 4046844 k total 交换分区总量 - 0 k used 使用的交换区总量 - 4046844 k free 空闲交换区总量 - 297720 k cached 缓冲的交换区总量
1.2 命令 vmstat(查看内存明细)

1. Procs(进程) r: 运行队列中进程数量,这个值也可以判断是否需要增加CPU。 2. Memory(内存) swpd: 使用虚拟内存大小,如果swpd的值不为0,但是SI,SO的值长期为0,这种情况不会影响系统性能。 free: 空闲物理内存大小。 3. Swap si: 每秒从交换区写到内存的大小,由磁盘调入内存。 so: 每秒写入交换区的内存大小,由内存调入磁盘。 4. IO(现在的Linux版本块的大小为1kb) bi: 每秒读取的块数 bo: 每秒写入的块数 5. system(系统) in: 每秒中断数,包括时钟中断。 cs: 每秒上下文切换数。 注意:上面2个值越大,会看到由内核消耗的CPU时间会越大。 6. CPU(以百分比表示) us:用户进程执行时间百分比(user time) sy:内核系统进程执行时间百分比(system time) id: 空闲时间百分比 wa: IO等待时间百分比
1.3 命令 free(查看内存) 【推荐】

显示当前系统未使用的和已使用的内存数目,还可以显示被内核使用的内存缓冲区。
语法:
free [options]
常用:
free -m (-m:以MB为单位显示内存使用情况)
Mem行解释:
total:内存总数; used:已经使用的内存数; free:空闲的内存数; shared:当前已经废弃不用; buffers Buffer:缓冲内存数; cached Page:缓存内存数。
(-/+ buffers/cache)解释:
(-buffers/cache) used内存数:第一部分Mem行中的 used – buffers – cached=程序占用内存数 (+buffers/cache) free内存数: 第一部分Mem行中的 free + buffers + cached=可挪用内存数
1.4 命令 iostat(查看io磁盘)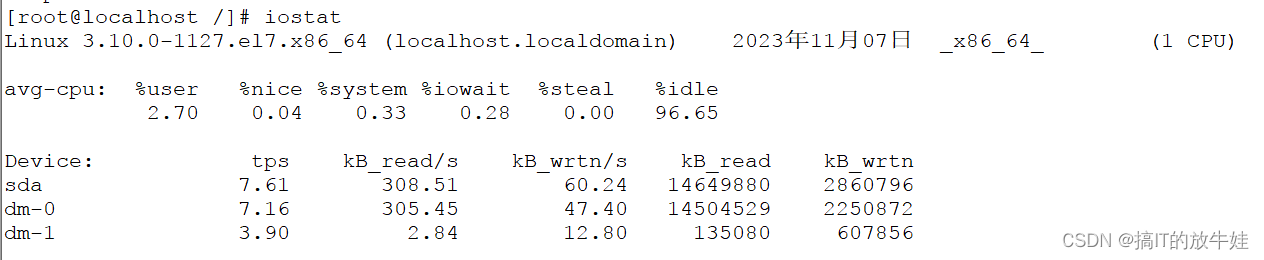
iostat是查看Linux系统io是否存在瓶颈很好用的一个命令
语法:
Usage: iostat [ options ] [ <interval> [ <count> ] ] options:选项 interval:间隔 count:计数
常用:
iostat -x 1 1 (x:输出列,1:间隔1秒,1:采集1次)
CPU:
1.%user: 在用户级别运行所使用的CPU的百分比 2.%sys: 在系统级别(kernel)运行所使用CPU的百分比 3.%iowait: CPU等待硬件I/O时,所占用CPU百分比 4.%idle: CPU空闲时间的百分比
Device:【重点】
1.tps: 每秒钟发送到的I/O请求数 2.avgqu-sz: 是平均请求队列的长度,毫无疑问,队列长度越短越好 3.await:每一个IO请求的处理的平均时间(单位是毫秒) 4.rkB/s: 每秒读取数据量(单位kb) 5.wkB/s: 每秒写入数据量(单位kb) 6.%util: 磁盘的繁忙程度,如接近100%那说明磁盘已经到瓶颈
1.5 命令 sar (查看网络)

sar命令可以通过参数单独查看系统某个局部的使用情况
语法:
sar [options] [-A] [-o file] t [n]
命令:
sar -n DEV 1 2 (-n:网络设备;DEV:磁盘设备) 1:表示一秒采集一次信息,可自行设定 2: 表示采集的次数,可自行设定
关注指标:
1. rxkB/s: 每秒接收的数据大小,单位kb 2. txkB/s: 每秒发送的数据大小,单位kb
使用场景:
查看当前网络数据包大小,是否存在网络瓶颈
二、工具 nmon
nmon 是分析 AIX 和 Linux 性能的免费工具。(其主要是IBM为自己的AIX操作系统开发的,但是也可以应用在其他Linux操作系统上)
2.1 nmon使用步骤
解压文件
复制移动对应系统的nmon工具
执行工具
使用Excel分析工具分析
1. 解压文件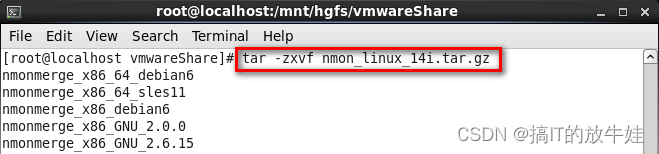
解压:
tar -zxvf nmon_linux_14i.tar.gz
注意:
1.nmon_linux_14i.tar.gz对应的gz包名 2.z:gzip压缩包;x:解压、v:详细信息、f:文件(必须放参数最后,文件前面)
2. 移动/复制文件
1). rm:移动命令
2). /tmp:移动到/tmp临时目录 (建议:直接放到 /usr/local/bin目录下)
3). nmon:移动过去后重名命名为nmon
3. 运行 nmon
./nmon -s3 -c10 -f -m /mnt/hgfs/vmwareShare/result
(3秒钟采集一次,共采集10次,保存到/mnt/hgfs/vmwareShare/result)
1)./nmon:当前目录下执行nmon文件 2). -s:时长-采集数据频率 3). -c:采集次数 4). -f:生成文件名包含文件创建时间 5). -m:指定生成文件保存目录
nmon工具只是采集结果,结果文件为.nmon,不能直接打开使用,需要使用Excel分析工具提取数据
4. Excel分析工具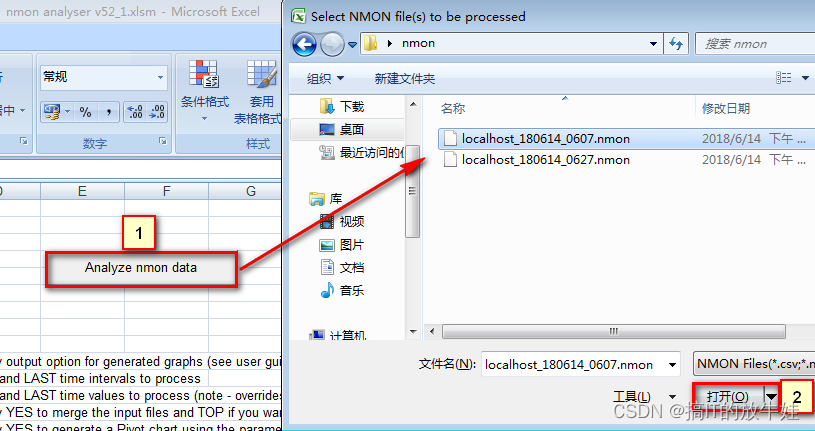
1). 点击 标1 浏览nmon文件
2). 点击 标2 打开nmon文件(分析完成后会提示保存为excel文件,选取保存路径进行保存)
提示:
1). Excel需要开启宏设置; 2). 如果提示加载文件类型错误,把电脑右下角的星期部分去掉(删除dddd)














 515
515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









