






前言
这次比赛的目标是训练一个模型来给学生的论文评分。需要你的努力来减少手工评分这些论文所需的高额费用和时间。可靠的自动化技术可以让论文被引入测试,这是学生学习的一个关键指标。
我在 Kaggle竞赛 Learning Agency Lab - Automated Essay Scoring 2.0 中铜牌的解决方案。
解决方案:
1、任务描述
提供了一组训练数据,包括学生的作文和相应的人类评分员给出的分数。你需要使用这些数据来训练他们的模型。在测试阶段,你需要对他们从未见过的学生作文进行评分,并将预测的分数与人类评分员给出的分数进行比较。
2、数据集
数据集包含了约17000篇学生撰写的议论性文章,每篇文章的得分范围在1到6分之间。
-
train.csv - Essays and scores to be used as training data.
essay_id- The unique ID of the essayfull_text- The full essay responsescore- Holistic score of the essay on a 1-6 scale
-
sample_submission.csv - A submission file in the correct format.
essay_id- The unique ID of the essayscore- The predicted holistic score of the essay on a 1-6 scale
train = pd.read_csv(PATHS.train_path)
train.head()

df = pd.read_csv(PATH + "train.csv")
df["score"].value_counts().sort_index()
制作词表,将单词放入集合
columns = [
(
pl.col("full_text").str.split(by="\n\n").alias("paragraph")
),
]
PATH = "/kaggle/input/learning-agency-lab-automated-essay-scoring-2/"
# 加载训练和测试集,同时使用\n\n字符分割列出并重命名为full_text
train = pl.read_csv(PATH + "train.csv").with_columns(columns)
test = pl.read_csv(PATH + "test.csv").with_columns(columns)
nlp = spacy.load("en_core_web_sm")
with open('/kaggle/input/english-word-hx/words.txt', 'r') as file:
english_vocab = set(word.strip().lower() for word in file)
用english_vocab作对照,用于统计错误
def count_spelling_errors(text):
"""
统计论文单词错误
return:单词错误数量
"""
doc = nlp(text)
lemmatized_tokens = [token.lemma_.lower() for token in doc]
spelling_errors = sum(1 for token in lemmatized_tokens if token not in english_vocab)
return spelling_errors 我们通过将单词转换为其基本形式,可以更准确地比较单词是否在词典中。这样可以确保即使单词以不同的形式出现,也能正确地识别它们。然后将所有单词转换为小写可以消除大小写差异带来的问题。english_vocab是一个集合(set),那么检查一个词是否在其中的操作是非常快速的,因为集合的查找时间复杂度为O(1)。
3、文本预处理 && 特征工程
文本预处理
然后我们对输入文本进行预处理,包括转换为小写、移除HTML标签、删除以@开头的字符串、删除数字、删除URL、替换连续的空格为单个空格、替换连续的逗号和句点为单个逗号和句点,以及删除字符串开头和结尾的空字符。方便机器学习模型能够更好地理解和处理文本数据。
def dataPreprocessing(x):
# 将文本转换为小写
x = x.lower()
# 移除HTML标签
x = removeHTML(x)
# 删除以@开头的字符串
x = re.sub("@\w+", '', x)
# 删除数字(可能包括负号)
x = re.sub("'\d+", '', x)
x = re.sub("\d+", '', x)
# 删除URL
x = re.sub("http\w+", '', x)
# 替换连续的空格为单个空格
x = re.sub(r"\s+", " ", x)
# 替换连续的逗号和句点为单个逗号和句点
x = re.sub(r"\.+", ".", x)
x = re.sub(r"\,+", ",", x)
# 删除字符串开头和结尾的空字符
x = x.strip()
return x段落特征工程
移除所有标点符号:
def remove_punctuation(text):
"""
移除 text中的所有标点符号.
Args:
- text (str): The input text.
Returns:
- str: 无标点的text
"""
translator = str.maketrans('', '', string.punctuation)
return text.translate(translator)·我们对文本数据中的段落进行预处理,并提取一系列特征。将'paragraph'列展开为多行,对每个段落应用各种转换(如移除标点符号),计算每个段落的长度,段落中句子和单词的数量,以及计算每个段落中的拼写错误数量。对文本数据进行清洗、分析和特征提取,这样更容易地捕捉到数据中的关键信息,从而提高预测准确性或分类性能。
def Paragraph_Preprocess(tmp):
"""
对文本数据进行清洗、分析和特征提取
"""
tmp = tmp.explode('paragraph')
# 段落工程
tmp = tmp.with_columns(pl.col('paragraph').map_elements(dataPreprocessing))
tmp = tmp.with_columns(pl.col('paragraph').map_elements(remove_punctuation).alias('paragraph_no_pinctuation'))
tmp = tmp.with_columns(pl.col('paragraph_no_pinctuation').map_elements(count_spelling_errors).alias("paragraph_error_num"))
# 计算每个段落的长度
tmp = tmp.with_columns(pl.col('paragraph').map_elements(lambda x: len(x)).alias("paragraph_len"))
# 计算每个段落的句子和单词数
tmp = tmp.with_columns(pl.col('paragraph').map_elements(lambda x: len(x.split('.'))).alias("paragraph_sentence_cnt"),
pl.col('paragraph').map_elements(lambda x: len(x.split(' '))).alias("paragraph_word_cnt"),)
return tmp我们将每段文本数据进行分组聚合,每个特征都计算了一系列统计量(最大值、均值、最小值、总和、第一个值、最后一个值、峰度、四分位数等),以便更好地了解文本的分布情况,从而为后续的文本处理和分析提供更好信息。
def Paragraph_Eng(train_tmp):
"""
将每段文本数据通过特征进行分组聚合
"""
num_list = [0, 50,75,100,125,150,175,200,250,300,350,400,500,600]
num_list2 = [0, 50,75,100,125,150,175,200,250,300,350,400,500,600,700]
aggs = [
# 计算大于和小于i值的段落长度数
*[pl.col('paragraph').filter(pl.col('paragraph_len') >= i).count().alias(f"paragraph_{i}_cnt") for i in [0, 50,75,100,125,150,175,200,250,300,350,400,500,600,700] ],
*[pl.col('paragraph').filter(pl.col('paragraph_len') <= i).count().alias(f"paragraph_{i}_cnt") for i in [25,49]],
# other
*[pl.col(fea).max().alias(f"{fea}_max") for fea in paragraph_fea2],
*[pl.col(fea).mean().alias(f"{fea}_mean") for fea in paragraph_fea2],
*[pl.col(fea).min().alias(f"{fea}_min") for fea in paragraph_fea2],
*[pl.col(fea).sum().alias(f"{fea}_sum") for fea in paragraph_fea2],
*[pl.col(fea).first().alias(f"{fea}_first") for fea in paragraph_fea2],
*[pl.col(fea).last().alias(f"{fea}_last") for fea in paragraph_fea2],
*[pl.col(fea).kurtosis().alias(f"{fea}_kurtosis") for fea in paragraph_fea2],
*[pl.col(fea).quantile(0.25).alias(f"{fea}_q1") for fea in paragraph_fea2],
*[pl.col(fea).quantile(0.75).alias(f"{fea}_q3") for fea in paragraph_fea2],
]
df = train_tmp.group_by(['essay_id'], maintain_order=True).agg(aggs).sort("essay_id")
df = df.to_pandas()
return df
句子特征工程
我们将预处理后的文本按句号(".")分割成多个句子,并将结果存储在名为sentence的新列中。计算每个句子的长度。
过短的句子可能不包含足够的上下文或信息来进行有效的分析,较长的句子通常包含更多的词汇和语法结构,减少数据集的大小可以显著减少计算时间和资源消耗。我们可以通过滤掉长度小于15的句子,可以缩小数据集的大小。
我们计算每个句子中的单词数量,并将结果存储在名为sentence_word_cnt的新列中。
def Sentence_Preprocess(tmp):
"""
full_text 列进行预处理,以分割句子、计算句子长度、过滤掉长度大于15的句子,
并计算每个句子的单词数量.
"""
#预处理full_text并使用句号来分割文本中的句子
tmp = tmp.with_columns(pl.col('full_text').map_elements(dataPreprocessing).str.split(by=".").alias("sentence"))
tmp = tmp.explode('sentence')
# 计算句子的长度
tmp = tmp.with_columns(pl.col('sentence').map_elements(lambda x: len(x)).alias("sentence_len"))
# 过滤出句子长度大于15的部分数据
tmp = tmp.filter(pl.col('sentence_len')>=15)
# 计算每个句子的字数
tmp = tmp.with_columns(pl.col('sentence').map_elements(lambda x: len(x.split(' '))).alias("sentence_word_cnt"))
return tmp然后我们可以用与上面对段落特征分组聚合的方法,同样以句子特征做分组聚合

词特征工程
我们可以用同上面类似的方法对单词进行处理,计算单词的长度通过单词的长度阈值进行分组聚合
def Word_Preprocess(tmp):
# 预处理full_text并使用空格将单词与文本分开
tmp = tmp.with_columns(pl.col('full_text').map_elements(dataPreprocessing).str.split(by=" ").alias("word"))
tmp = tmp.explode('word')
# 计算每个单词的长度
tmp = tmp.with_columns(pl.col('word').map_elements(lambda x: len(x)).alias("word_len"))
# 删除字长为0的数据
tmp = tmp.filter(pl.col('word_len')!=0)
return tmp
TF-IDF
基于TF-IDF算法将文本数据转换为特征向量,为捕获短语级别的信息,我将生成3到6个字符长度的n-gram特征,为了除去错误词,罕见词,无意义的停用词等,我把最小文档率设置为5%,最大文档率设置为95%,因为文本数据已经做过特征工程和数据预处理,参数设定如下:
# 定义parameter
vectorizer = TfidfVectorizer(
tokenizer=lambda x: x,
preprocessor=lambda x: x,
token_pattern=None,
strip_accents='unicode',
analyzer = 'word',
ngram_range=(3,6),
min_df=0.05,
max_df=0.95,
sublinear_tf=True,
)
将通过TF-IDF算法得到的特征向量与原有的特征数据合并
train_tfid = vectorizer.fit_transform([i for i in train['full_text']])
# 转换为数组
dense_matrix = train_tfid.toarray()
# 转换为数据帧
df = pd.DataFrame(dense_matrix)
# 特征重命名
tfid_columns = [ f'tfid_{i}' for i in range(len(df.columns))]
df.columns = tfid_columns
df['essay_id'] = train_feats['essay_id']
# 将新生成的特征数据与之前生成的特征数据合并
train_feats = train_feats.merge(df, on='essay_id', how='left')
将deberta模型预测出来的概率作为特征添加到特征集中(相当于该模型对每个类别的置信度。)
# 将Deberta预测添加到LGBM作为特征
deberta_oof = joblib.load('/kaggle/input/aes2-400-20240419134941/oof.pkl')
print(deberta_oof.shape, train_feats.shape)
for i in range(6):
train_feats[f'deberta_oof_{i}'] = deberta_oof[:, i]train_feats.shape
对quadratic_weighted_kappa 函数进行重写,论文分为1-6类。在这种情况下,Cohen's Kappa可能更适合用于评估分类器的一致性。
def quadratic_weighted_kappa(y_true, y_pred):
y_true = y_true + a
y_pred = (y_pred + a).clip(1, 6).round()
qwk = cohen_kappa_score(y_true, y_pred, weights="quadratic")
return 'QWK', qwk, True自定义LGBMRegressor的目标函数qwk_obj作为损失函数。函数中a,b参数由以下推导
def qwk_obj(y_true, y_pred):
labels = y_true + a
preds = y_pred + a
preds = preds.clip(1, 6)
f = 1/2*np.sum((preds-labels)**2)
g = 1/2*np.sum((preds-a)**2+b)
df = preds - labels
dg = preds - a
grad = (df/g - f*dg/g**2)*len(labels)
hess = np.ones(len(labels))
return grad, hess方法参考自:https://www.kaggle.com/code/rsakata/optimize-qwk-by-lgb/notebook#QWK-objective
计算每个类别标签与实际得分之间的均方误差
X = df.drop(["essay_id", "score"], axis=1)
y = df["score"]
g = np.zeros(6)
for i in range(6):
g[i] = ((y - (i+1))**2).mean()
plt.plot([1,2,3,4,5,6], g, marker=".", label="actual")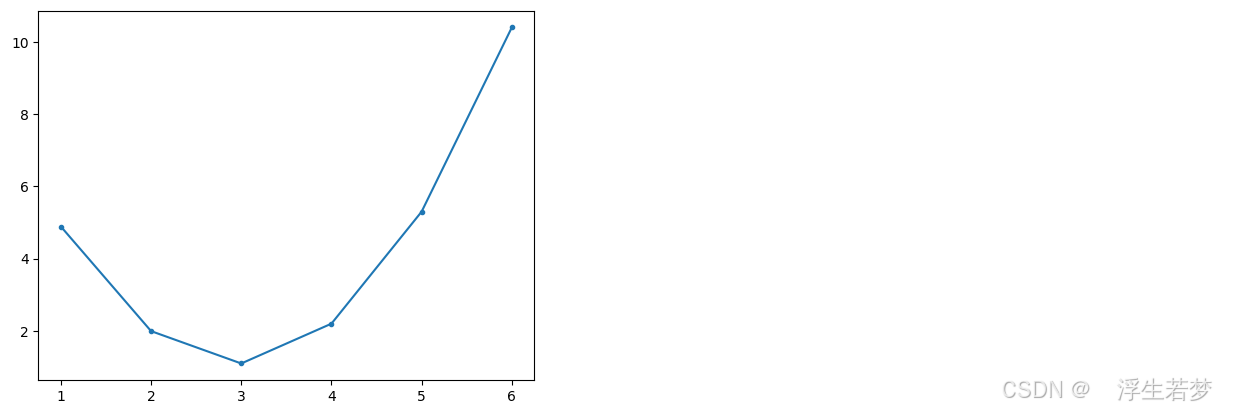
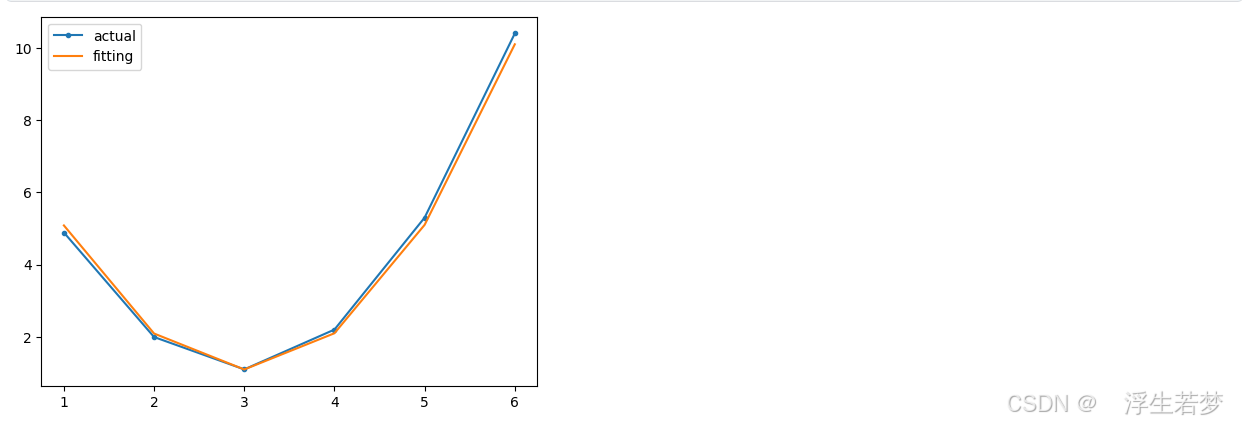
用拟合曲线拟合
a = 2.998
b = 1.092
plt.plot([1,2,3,4,5,6], g, marker=".", label="actual")
plt.plot([1,2,3,4,5,6], [(x-a)**2 + b for x in [1,2,3,4,5,6]], label="fitting")
plt.legend()
plt.show()定义a = 2.998,b = 1.092以达到拟合效果
特征筛选
特征提取完成过后达21905个特征,可以使用LightGBM模型进行特征重要性评估,筛选出重要的特征用做模型训练。用分层5折交叉验证来将数据集划分为训练集和测试集。
对于每个折,创建一个LightGBM回归模型,并使用训练集对其进行拟合。接着,使用拟合好的模型对测试集进行预测,然后计算F1分数和Cohen's Kappa分数。
将当前折的特征重要性得分累加到fse这个Pandas Series对象中。这样,在完成所有折的训练和测试后,fse将包含所有折的特征重要性总和,可以用来评估特征的重要性。最后筛选出前13000个特征。
def feature_select_wrapper():
"""
lgm
:param train
:param test
:return
"""
# Part 1.
print('feature_select_wrapper...')
features = feature_names
callbacks = [log_evaluation(period=25), early_stopping(stopping_rounds=75,first_metric_only=True)]
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=0)
fse = pd.Series(0, index=features)
for train_index, test_index in skf.split(X, y_split):
X_train_fold, X_test_fold = X[train_index], X[test_index]
y_train_fold, y_test_fold, y_test_fold_int = y[train_index], y[test_index], y_split[test_index]
model = lgb.LGBMRegressor(
objective = qwk_obj, #损失函数
metrics = 'None', #评价指标
learning_rate = 0.05, #学习率
max_depth = 5, #最大深度
num_leaves = 10, #叶子数
colsample_bytree=0.3, #采样比例
reg_alpha = 0.7, #L1正则化系数
reg_lambda = 0.1, #L2正则化系数
n_estimators=700, #构建的树的数量
random_state=412, #随机数生成器的种子
extra_trees=True, #是否用额外的树
class_weight='balanced', #根据类别的频率自动调整权重。
verbosity = - 1 #不输出任何信息)
predictor = model.fit(X_train_fold,
y_train_fold,
eval_names=['train', 'valid'],
eval_set=[(X_train_fold, y_train_fold), (X_test_fold, y_test_fold)],
eval_metric=quadratic_weighted_kappa, #评估模型性能的指标
callbacks=callbacks #回调函数列表)
models.append(predictor)
predictions_fold = predictor.predict(X_test_fold)
predictions_fold = predictions_fold + a
predictions_fold = predictions_fold.clip(1, 6).round()
predictions.append(predictions_fold)
f1_fold = f1_score(y_test_fold_int, predictions_fold, average='weighted')
f1_scores.append(f1_fold)
kappa_fold = cohen_kappa_score(y_test_fold_int, predictions_fold, weights='quadratic')
kappa_scores.append(kappa_fold)
fse += pd.Series(predictor.feature_importances_, features)
# Part 4.
feature_select = fse.sort_values(ascending=False).index.tolist()[:13000]
print('done')
return feature_select4、模型训练
用了StratifiedKFold对象(skf)来将数据集划分为训练集和测试集的多个折(folds,并且用LightGBM模型做模型训练,通过多次迭代训练和测试模型,从而获得模型在不同数据子集上的性能评估。最后,计算所有折的平均F1分数和Cohen's Kappa分数,以得到模型的整体性能指标。最后将模型保存。
n_splits = 15
models = []
#用指定的拆分次数初始化StratifiedKFold
skf = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=0)
# 存储分数的列表
f1_scores = []
kappa_scores = []
models = []
predictions = []
callbacks = [log_evaluation(period=25), early_stopping(stopping_rounds=75,first_metric_only=True)]
# 循环遍历交叉验证的每个折叠
i=1
for train_index, test_index in skf.split(X, y_split):
# 将数据拆分为此折叠的训练和测试集
print('fold',i)
X_train_fold, X_test_fold = X[train_index], X[test_index]
y_train_fold, y_test_fold, y_test_fold_int = y[train_index], y[test_index], y_split[test_index]
model = lgb.LGBMRegressor(
objective = qwk_obj, #损失函数
metrics = 'None', #评价指标
learning_rate = 0.05, #学习率
max_depth = 5, #最大深度
num_leaves = 10, #叶子数
colsample_bytree=0.3, #采样比例
reg_alpha = 0.7, #L1正则化系数
reg_lambda = 0.1, #L2正则化系数
n_estimators=700, #构建的树的数量
random_state=42, #随机数生成器的种子
extra_trees=True, #是否用额外的树
class_weight='balanced', #根据类别的频率自动调整权重。
device='gpu',
verbosity = - 1)
# 在这个的训练数据上拟合模型
predictor = model.fit(X_train_fold,
y_train_fold,
eval_names=['train', 'valid'],
eval_set=[(X_train_fold, y_train_fold), (X_test_fold, y_test_fold)],
eval_metric=quadratic_weighted_kappa,
callbacks=callbacks
)
models.append(predictor)
# 对该测试数据进行预测
predictions_fold = predictor.predict(X_test_fold)
predictions_fold = predictions_fold + a
predictions_fold = predictions_fold.clip(1, 6).round()
predictions.append(predictions_fold)
# 计算并存储此F1分数
f1_fold = f1_score(y_test_fold_int, predictions_fold, average='weighted')
f1_scores.append(f1_fold)
# 计算并存储Cohen的kappa分数
kappa_fold = cohen_kappa_score(y_test_fold_int, predictions_fold, weights='quadratic')
kappa_scores.append(kappa_fold)
predictor.booster_.save_model(f'fold_{i}.txt')
i+=1
测试集->预处理 && 特征工程
对测试集的文本数据做与训练集做同样的文本预处理和特征工程,提取特征,将文本数据转换为特征向量
# 段落
tmp = Paragraph_Preprocess(test)
test_feats = Paragraph_Eng(tmp)
# 句子
tmp = Sentence_Preprocess(test)
test_feats = test_feats.merge(Sentence_Eng(tmp), on='essay_id', how='left')
# 单词
tmp = Word_Preprocess(test)
test_feats = test_feats.merge(Word_Eng(tmp), on='essay_id', how='left')
# TF-IDF
test_tfid = vectorizer.transform([i for i in test['full_text']])
dense_matrix = test_tfid.toarray()
df = pd.DataFrame(dense_matrix)
tfid_columns = [ f'tfid_{i}' for i in range(len(df.columns))]
df.columns = tfid_columns
df['essay_id'] = test_feats['essay_id']
test_feats = test_feats.merge(df, on='essay_id', how='left')
# CountVectorizer
test_tfid = vectorizer_cnt.transform([i for i in test['full_text']])
dense_matrix = test_tfid.toarray()
df = pd.DataFrame(dense_matrix)
tfid_columns = [ f'tfid_cnt_{i}' for i in range(len(df.columns))]
df.columns = tfid_columns
df['essay_id'] = test_feats['essay_id']
test_feats = test_feats.merge(df, on='essay_id', how='left')
# deberta模型训练
for i in range(6):
test_feats[f'deberta_oof_{i}'] = predicted_score[:, i]
预测
用训练好的模型预测测试集。
probabilities = []
for model in models:
proba = model.predict(test_feats[feature_select]) + a
probabilities.append(proba)
# 计算所有模型的平均概率
predictions = np.mean(probabilities, axis=0)
predictions = np.round(predictions.clip(1, 6))完成结果
提交 && 结果
submission = pd.read_csv("/kaggle/input/learning-agency-lab-automated-essay-scoring-2/sample_submission.csv")
submission['score'] = predictions
submission['score'] = submission['score'].astype(int)
submission.to_csv("submission.csv", index=None)在公榜上得分0.81762,在私榜上得分0.83487




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









