






基于MS-Swift框架的Qwen2.5-VL大模型推理、部署全流程文档
一、MS-Swift框架简介
ms-swift是魔搭社区提供的大模型与多模态大模型微调部署框架,现已支持450+大模型与150+多模态大模型的训练(预训练、微调、人类对齐)、推理、评测、量化与部署,其中包括:Qwen、Qwen-VL、InternLM、GLM、Llama、MiniCPM-V和DeepSeek-R1等热门开源模型。此外,ms-swift还汇集了最新的训练技术,包括LoRA、QLoRA、Llama-Pro、LongLoRA、LoRA+等轻量化训练技术,以及DPO、GRPO、RM、PPO、KTO等人类对齐训练方法,并支持CPU,NvidiaGPU、AscendNPU和MPS等硬件设备,提供了分布式训练、量化训练、RLHF训练和多模态训练等多种大模型训练方式,极大地简化了大模型的训练微调步骤,降低了大模型训练的门槛。
二、环境准备
创建conda虚拟环境(本教程为ms-swift)
conda create -n ms-swift python=3.9 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
进入conda虚拟环境
conda activate ms-swift
安装ms-swift
pip install ms-swift -U
在ms-swift虚拟环境中安装modelscope包、decord包
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install qwen-vl-utils[decord]==0.0.8
三、模型准备
在ms-swift项目根路径下,新建models文件夹
mkdir models
以Qwen2.5-VL为例,在ms-swift项目根路径下,编写模型下载脚本download_model.py
from modelscope import snapshot_download
model_id = 'Qwen/Qwen2.5-VL-3B-Instruct'
# 模型ID
local_root_dir = './models/'
model_path = snapshot_download(model_id=model_id, local_dir=local_root_dir+model_id)
print(f"模型权重下载完成,权重存放路径为{model_path}")
在当前路径下,执行以下指令,下载模型
python download_model.py
下载完成后,模型存放在./models/Qwen/Qwen2.5-VL-3B-Instruct/
四、模型推理
本节教程以WebUI界面推理为例
在项目根路径下编写infer_webui.sh
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
swift app \
--model ./models/Qwen/Qwen2.5-VL-3B-Instruct \
--infer_backend pt \
--temperature 0 \
--max_new_tokens 4096 \
--studio_title "Qwen2.5-VL-3B" \
--stream true
执行infer_webui.sh
bash infer_webio.sh
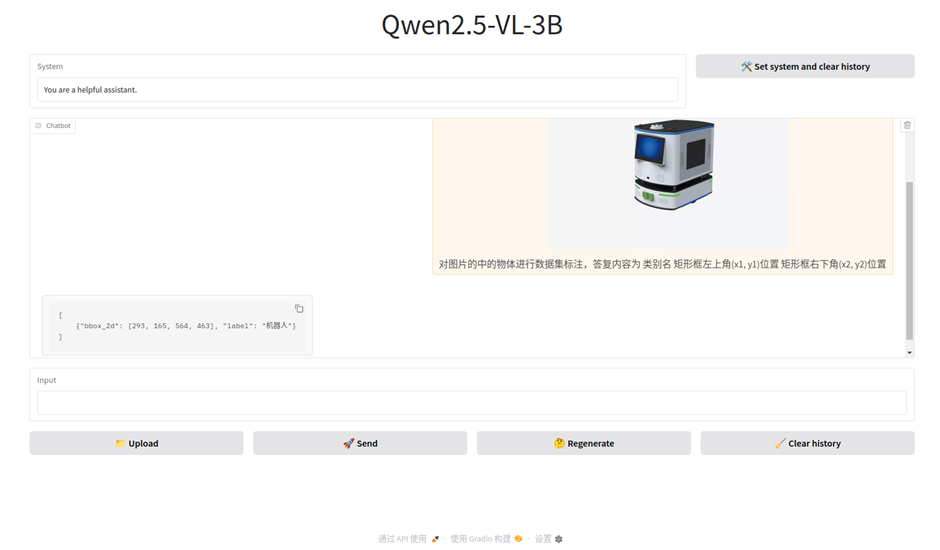
推理测试成功!
五、模型部署与调用
本节教程以OpenAI库调用部署的模型为例
1.模型部署
在ms-swift项目根路径下,ms-swift的conda虚拟环境中,执行以下指令
CUDA_VISIBLE_DEVICES=0 \
MAX_PIXELS=1003520 \
VIDEO_MAX_PIXELS=50176 \
FPS_MAX_FRAMES=12 \
swift deploy \
--model ./models/Qwen/Qwen2.5-VL-3B-Instruct/ \
--infer_backend vllm \
--gpu_memory_utilization 0.9 \
--max_model_len 8192 \
--max_new_tokens 2048 \
--limit_mm_per_prompt '{"image": 5, "video": 2}' \
--served_model_name Qwen2.5-VL-3B-Instruct \
--port 8000
2.模型调用
在项目根目录下新建一个Python脚本,如client_openai.py,通过OpenAI库来调用部署的Qwen2.5-VL大模型API服务,脚本中写入以下示例代码:
from openai import OpenAI
client = OpenAI(
api_key='retoo',
base_url='http://127.0.0.1:8000/v1',
)
model_type = client.models.list().data[0].id
print(f'model_type: {model_type}')
# 构建包含图像和文本的消息
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "http://modelscope-open.oss-cn-hangzhou.aliyuncs.com/images/animal.png"
},
{
"type": "text",
"text": "对图片的中的物体进行数据集标注,答复内容为 类别名 矩形框左上角(x1, y1)位置 矩形框右下角(x2, y2)位置"
}
]
}
]
resp = client.chat.completions.create(
model=model_type,
messages=messages,
max_tokens=256,
temperature=0,
seed=42
)
response = resp.choices[0].message.content
print(f'query: {messages[0]["content"]}')
print(f'response: {response}')
# 流式输出(这里假设流式输出也可以使用类似的多模态消息)
# 由于流式输出时,这里简单添加一条新的文本消息
new_text_query = "再解释一下标注的含义"
messages.append({'role': 'assistant', 'content': response})
messages.append({'role': 'user', 'content': [{"type": "text", "text": new_text_query}]})
stream_resp = client.chat.completions.create(
model=model_type,
messages=messages,
stream=True,
max_tokens=256,
temperature=0,
seed=42
)
print(f'query: {new_text_query}')
print('response: ', end='')
for chunk in stream_resp:
print(chunk.choices[0].delta.content, end='', flush=True)
print()
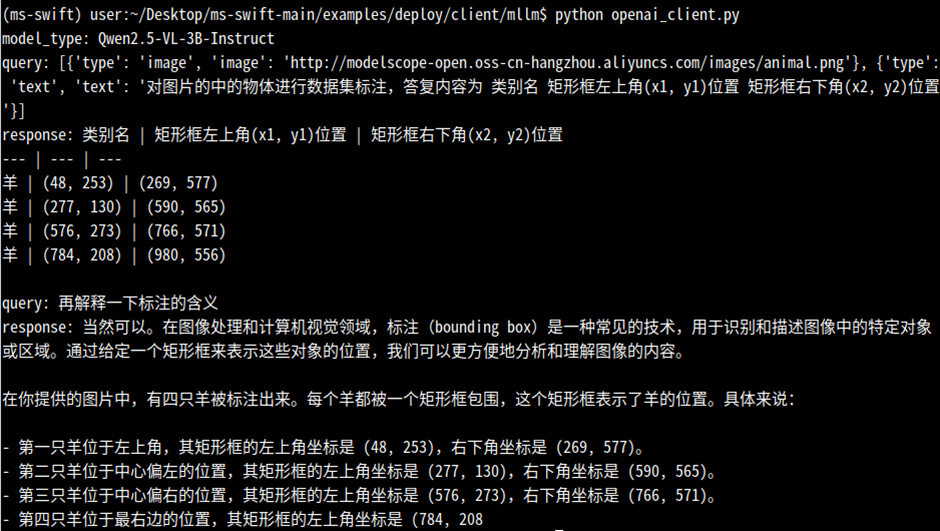
模型调用成功!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









