








>>文章导航:
1. 数据库介绍
1.1 什么是数据库
数据库,是一类管理数据的软件,相较于文件保存数据,有更安全、更利于数据查询和管理、更利于存储海量数据、在程序中控制更方便的优点,其存储介质是磁盘。
常识补充:
- 电脑存储数据的存储器: 磁盘 和 内存 。
- 内存和硬盘的差别:
1.硬盘比较大的,内存比较小(不是物理的尺寸.是存储空间的容量)
2.硬盘读写速度比较慢的.内存的读写速度比较快. (几千倍,上万倍)
3.内存比硬盘成本更高(贵)
4.内存存储的数据,断电之后,就会丢失;硬盘存储的数据,断电之后,仍然存在;
- 关于缓存:
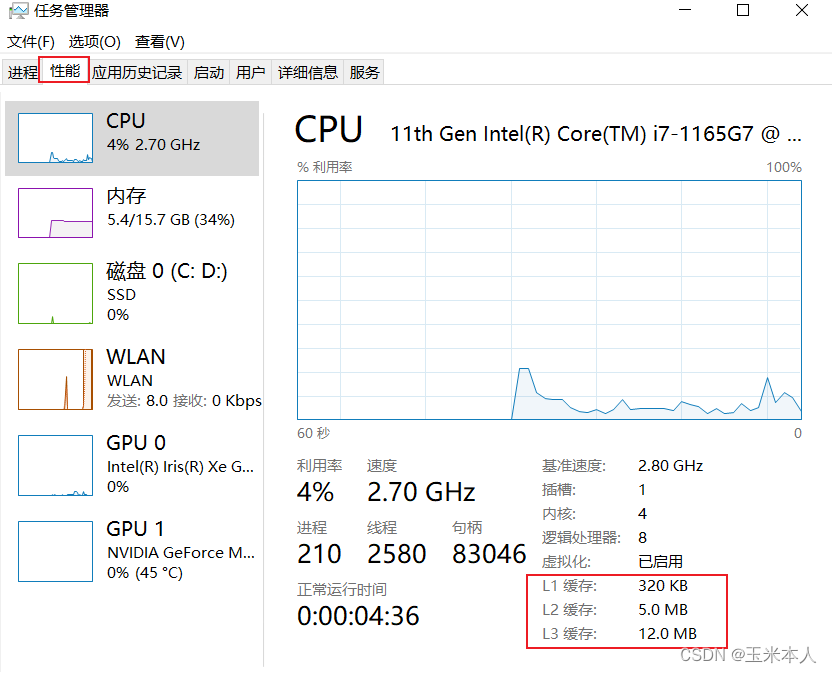
缓存是CPU内部,用来存储数据的部分;
寄存器,同样也是CPU内部用来存储数据的部分;
寄存器是用来参与进行计算的.(保存计算过程中的中间结果的);
寄存器读写数据的速度是最快的,比内存还快几千倍;
因为内存比奇存器慢太多了.所以就给cpu引入了缓存;
缓存属于存储空间介于寄存器和内存之间.速度也是介于之间的;
CPU读内存的时候,往往会把一些数据线放到缓存中保存,就可以减少读取内存的次数,提高整体程序的效率;
查看缓存: 按 win + X 键 打开任务管理器:
- 关于显卡:
显卡也是一种芯片,称为GPU.也是用来进行计算和逻辑判断的;
最开始的电脑,没有显卡,只有CPU; 但后来人们希望电脑能显示出更丰富的图像, 显示复杂图像,尤其是快速变化的图像,就需要大量的算术运算(一系列的矩阵运算,线代)用CPU能算,就会给CPU 带来一定的负担; 于是,英伟达这个公司就提出了GPU这个概念---"专用计算芯片”, CPU则是"通用计算芯片"; 图形领域,运算量虽然很大,但是基本都是1+1这种水平的;除了图形之外,人工智能,也巧了,,也是都是1+1的运算,运算量贼大;
数据库可以提供远程服务,即通过远程连接来使用数据库,因此也称为数据库服务器。
MySQL 是一个 “ 客户端(client,主动发起通信的一方)- 服务器(server,被动接受通信的一方)” 结构的程序。客户端给服务器发送的数据称为 “请求(Request)”,服务器给客户端返回的数据称为“响应(Response)”。客户端程序和服务器之间 数据交互的方式最主要就是通过“网络”。服务器是被动的一方,一个服务器一般来说要同时给多个客户端提供服务,商业级别的服务器一般会 7*24 小时运行。
电脑在安装好 MySQL 之后,就是安装了 MySQL 客户端和服务器(客户端和服务器都在你同一个电脑上),并通过网络通信。客户端和服务器可以在同一个主机上,也可以在不同主机(工作中通常是不同主机。
这就是客户端:

数据库服务器, 是 MySQL 的本体(持有数据管理数据负责增删改查的核心部分),而 MySQL 客户端只是一个和用户交互的界面,让用户能够通过客户端给服务器 “发送指令” 指挥服务器干活,真正干活的是数据库服务器。
1.2 数据库分类
数据库大体可以分为 关系型数据库 和 非关系型数据库 。
关系型数据库(RDBMS):
关系型数据库是按照 “表格(excel)” 的形式来组织数据的,一个表格有很多行,每一行又有很多列,每一列表示不同的含义,每一行和每一行之间的列需要对应。
基于标准的SQL,只是内部一些实现有区别。常用的关系型数据库如:
1. Oracle:甲骨文产品,适合大型项目,适用于做复杂的业务逻辑,如ERP、OA等企业信息系统。收费。
2. MySQL:属于甲骨文,不适合做复杂的业务。开源免费。最广泛使用。
3. SQL Server:微软的产品,安装部署在windows server上,适用于中大型项目。收费。
非关系型数据库(NoSQL):
往往是按照 “键值对” 或者 “文档” 的方式来组织的,文档没有上述 “表格” 这样严格的要求。如:
1. 基于键值对(Key-Value):如 memcached、redis
2. 基于文档型:如 mongodb
3. 基于列族:如 hbase
4. 基于图型:如 neo4j
关系型数据库与非关系型数据库的 区别:

2. SQL分类
MySQL的操作用到一种专门的编程语言---- SQL (和Java, C++是同类的), 其他数据库也会用到这个语言;
(1)DDL数据定义语言,用来维护存储数据的结构,代表指令: create, drop, alter;
(2)DML数据操纵语言,用来对数据进行操作,代表指令: insert,delete,update;
DML中又单独分了一个DQL,数据查询语言,代表指令: select;
(3)DCL数据控制语言,主要负责权限管理和事务,代表指令: grant,revoke,commit。
3. 数据库的操作
逻辑上的数据集合, 一个mysql服务器上可以有多个这样的数据集合;
3.1 显示当前的数据库
show databases;
注意:
(1)show 和 databases 之间有一个或多个空格;
(2)注意是databases;
(3)使用英文分号结尾;(客户端里的任何一个 sql 都需要使用分号来结尾)
(4)客户端是允许你一个 sql 分多行写的,如果不写分号,直接换行,此时客户端会认为你当前的 sql 还没写完。
执行结果:

(5)set 指 HashSet;
3.2 创建数据库
create database [数据库名];
注意:
(1)是 database 单数;
(2) 数据库命名与 Java 变量名命名规则相同;
(3)如果想用关键字作为数据库名,可以使用 反引号 ` 将数据库名引用起来;
(4)创建数据库时,命名不能重复;
(5)sql 的关键字是大小写不敏感的;
执行结果:

3.3 使用数据库
use 数据库名;
要想针对某个数据库进行后续操作(增删改查),就得先明确是针对哪个库进行的,所以使用数据库需要先选中数据库。
选中数据库选中之后,会有个提示:

3.4 删除数据库
drop database [数据库名];
ATTENTION!删除操作非常非常危险,一定要慎重再慎重!!!
一旦删除了,数据就没了,难以恢复。
BTW,删库有办法恢复吗?
理论上来说,有。但是恢复比较复杂而且不保证 100% 恢复回来。其实,计算机删除硬盘数据,是 逻辑删除 (把这个数据标记成无效而不是直接把数据抹掉)。如果真删库了,赶紧停机!把硬盘拿下来, 交给专业的团队来进行恢复,还是有很大概率恢复出来的。
However,假设你的电脑上有一些你不想让别人知道的数掘想彻底删除,咋办?
只需要物理删除 —— 把硬盘砸了lol。
4. 表的操作
一个数据库中,可以存储不同的数据; 每组数据都使用数据表来存储, 相当于"表格"类似于excel;
一个表里有很多行(row),每一行,都是一条“记录”!
“数据"每一行又包含很多列,每一格也称为一个"字段”(field);

4.1 查看有哪些表
use 数据库名; (需要先选中数据库才行!)
show tables;
执行结果:

4.2 创建表
创建表的时候,需要描述出表包含哪些列,每一列的名字,每一列的类型, 需要先认识类型有哪些:5. 常用数据类型 。
每一列的数据的类型都要一致;
后续往表里放的数据,也要遵守这个规则。
create table 表名字 (
列名1 数据类型
列名2 数据类型
);
需要注意的是:
类型放到列名后面写法,与 Go 和 Python 的规则编程语言相同;
a:int = 10; //python
var a int = 10; //go
但 C / Java 都是先写类型, 再定义变量名。
int a = 10;
sql 语法补充:
在 sql 中, 可以使用 - 或者 # 的方式作为注释;
遇到 ; 才是一个完整的 sql, 在 ; 之前换行,就是换行操作;
4.3 查看表结构
一个表里面有哪些列, 列的名字和类型 等。
desc 表名; # describe 描述
执行结果:
int (11),11称为位宽,表示 int在mysql客户端中打印的时候,会占据最多大的宽度;
20表示字符串里最多包含20个字符;
null 在 sql 中表示的含义,是这个单元格里面啥都没有,空的;

4.4 删除表
drop table 表名;
drop table if exists 表名;
注意安全问题!!!
错误删除表,引起的后果,还可能比删除整个数据库来的更大;
但是实际上,相比于将库里的表全删了,只删除其中的一个表,危害反而更大;
如果删了整个库,后续程序进行任何数据库操作,都会出问题,程序员就能够更早的发现问题;
如果只删了一个表,程序运行过程中,大概率都是对的,少数操作是错的,就难以发现问题;
问题可能就会持续存在很久,这个错误越积越多,造成的影响就越来越严重!!
5. 常用数据类型
5.1 数值类型:
float 和 double 通过设置 D 来设定数字要保留几位小数;
float 和 double 有一个很严重的问题,在表示一些数据时,不能精确表示,存在误差。
因此比较两个浮点数,不能使用 == ,而需要通过作差,小于一个误差值的方式;
为什么float 和 double 表示的精度不够呢? -------- 主要原因是和内存存储结构相关。
这种表示方式的好处是,存储空间小计算速度快但是可能存在误差。
(使用 decimal ,是使用了类似于 字符串 的方式来保存的,更精确存储但是存储空间更大计算速度更慢了)

5.2 字符串类型:
设定一个“变长字符串varchar”,SIZE 指定的是最大长度,单位是 字符 (注意单位)。
假设指定 name 列类型是 varchar(10),姓名最多几个字 —— 10 个字。
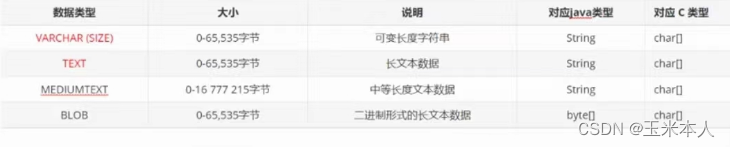
but写了个 varchar(1024)不是真的占据了 1024 个字符这么大存储空间,实际上是根据你存的数据长度动态调整的。blob 存储的是 2进制串, 和 最多只能存 64 bit的bit[ ] 不一样,blob 可以存更长,比如要存一个小的图片,存一个小的音频文件。blob 设置长度上限,是为了兜底,数据库存储数据的时,需要关注当前占用多少空间;
varchar, text, mediumtext三个类型都是存储的字符串(文本数据),blob存储的是二进制数据;
5.3 日期类型:
datetime 和 timestamp 都能表示年月日时分秒,但是 timestamp 只有4分字节的时间戳,不太够用。

6. 小练习
一个商店的数据,记录客户及购物情况,有以下三个表组成:
- 商品goods(商品编号goods_id,商品名goods_name, 单价unitprice, 商品类别category, 供应商provider)
- 客户customer(客户号customer_id,姓名name,住址address,邮箱email,性别sex,身份证card_id)
- 购买purchase(购买订单号order_id,客户号customer_id,商品号goods_id,购买数量nums)
create database practice;
use practice;
create table goods(goods_id int,goods_name varchar(50),unitprice int,category varchar(20),provider varchar(20));
create table customer(customer_id int,name varchar(30),address varchar(100),email varchar(50),gender varchar(1),card_id varchar(30));
create table `order`(order_id int,customer_id int,good_id int,nums int);正确步骤是:
1. 创建库;
2. 选中库;
3. 创建表;
- 未选中库将会报错:
- 创建表时漏掉 ) 会报错:
- 可以使用 ` 引用关键字作为表名;
- 钱用什么单位表示? ----用 int 来表示钱, 可以算的又快,又精确; 钱可以是整数,只要你用"分”作为单位就行了;
- 写 sql 时,字符串的最大长度参考两个指标: 业务确定 和 技术确定;
- 业务确定, 就是从当前这个代码场景需要解决什么问题来看, 核心就是解决问题,满足需求;
- 技术确定, 就是从性能/存储空间的角度来看, 明确总的存储空间有多少,估算总的数据量有多少,进一步计算出每个数据能占多少空间再进一步的把空间分配给每个列;



如果觉得作者写得还不错的话, 点赞 / 收藏 / 评论 / 转发 四连支持一下吧~😘
最重要的是点一个大大的关注, 你的支持就是作者创作的最大动力!!!❤















 503
503











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









