







前言
在项目中我们经常需要得到一个连续不中断的序列数用做单号的组装。而这个序列数最终要的几个特点:
1. 唯一性:不同单使用唯一的一个号,如果重复的话就会导致单号重复,业务数据受影响。
2. 连续性:希望这个数据是连续的,这样就可以从单号就看出数量。
3. 可回滚:很多时候我们的操作都是在一个事务上,事务可能回滚,因此单号也需要进行回滚。
做法一 数据库表id
大部分人都会使用这种做法,直接使用数据库表id,id设置为自增长,这样就确保了唯一性、连续性和可回滚。
这种做法的缺点:
1. 增加数据库操作,你必须要先insert拿到id后再update,那如果是批量插入,那么操作数据库的次数就会增加,性能就会受影响。
2. 如果数据在同一个表中,不同维度的数据有自己独立的序列号,这种情况就没办法实现。
做法二 文件存储
使用单独文件记录每次取完之后就自增+1,独立维护序列号的加和减。
这种做法的缺点:
1. 无法支持高并发的操作,高并发时很容易出现数字维护的混乱。
2. 文件读取效率较低。
做法三 数据库函数+表
实现过程
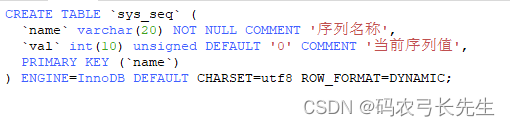
1、MySQL 创建一个存储序列化的表 sys_seq
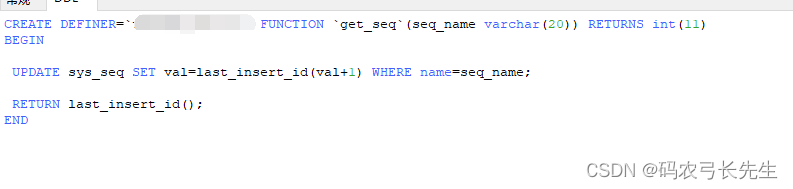
2、创建一个函数 get_seq
3、php 或者mysql 使用时,直接调用MySQL的函数

实现原理
1. last_insert_id函数
使用的last_insert_id()的特性:若调用last_insert_id()时传入了参数,则它会将参数值返回给调用者,并记住这个值,下次调用不带参数的last_insert_id()时,仍会返回这个值。
函数中我们每次调用时都将val值自增+1传入到last_insert_id函数中,返回时则不带参数,这样就可以直接返回上次插入的值。
2. 数据库锁机制
使用数据库操作时的行锁,这样可以防止并发调用的问题。同时由于都是数据库的操作因此在事务中也能支持回滚,当业务回滚时这个表数据的操作也会相应的回滚。
总结
以上三种方式中,第三种是弥补了上述所有的不足,我认为相对来说是比较合理的,使用起来也方便。但是对于一些对数据库有洁癖的人可能会不赞同,他们认为数据库就是用来存储更重要更有用的数据,不应该用于做一种技术方案的选择。每个人都是自己的看法,技术不应有束缚,合适的才是最重要的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









