







活动地址:CSDN21天学习挑战赛
学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰!
一、浅入BeautifulSoup4
1、简单介绍
BeautifulSoup4是一个可以从HTML或者XML文件中提取数据的python库,它可以通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。大大提高工作效率。
2、模块下载
在cmd命令窗口或者python终端窗口输入以下命令完成安装:
pip install beautifulsoup43、导包(不可以直接import BeautifulSoup)
from bs4 import BeautifulSoup4、解析库
BeautifulSoup在解析时实际上依赖解析器,除了支持python标准库中的HTML解析器以外,还支持一些第三方解析器(比如lxml):
解析器 使用方法 优势 劣势 python标准库 BeautifulSoup(html,'html.parser') python内置的标准库、执行速度快、文档容错力强 在python2.7.3以及python3.2.2之前的版本文档容错力差 lxmlHTML解析库 BeautifulSoup(html,'lxml') 速度快、文档容错力强 需要安装c语言库 lxmlXML解析库 BeautifulSoup(html,'xml') 速度快、唯一支持XML的解析器 需要安装c语言库 htm5lib解析库 BeautifulSoup(html,'htm5lib') 最好的容错性、以浏览器的方式解析文档、生成HTMLS格式的文档 速度慢、不依赖外部扩展 一般常用lxmlHTML解析库,其次是htm5lib解析库
二、BeautifulSoup4的使用
1、基础操作
①读取HTML字符串:
from bs4 import BeautifulSoup html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel_body"> <ul class="list" id="list-1" name="element"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <a href="https://www.baidu.com">百度官网</a> <li class="element">Bar</li> </ul> </div> </div> ''' # 创建对象 soup = BeautifulSoup(html, 'lxml')②读取HTML文件:(没有html文件可以创建一个html文件,将上个代码的HTML字符串录入即可)
from bs4 import BeautifulSoup soup = BeautifulSoup(open('index.html'), 'lxml') # 文件路径记得修改③基本的方法:
from bs4 import BeautifulSoup html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel_body"> <ul class="list" id="list-1" name="element"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <a href="https://www.baidu.com">百度官网</a> <li class="element">Bar</li> </ul> </div> </div> ''' # 创建对象 soup = BeautifulSoup(html, 'lxml') # 缩进格式 print(soup.prettify()) # 获取title标签的所有内容 print(soup.title) # 获取title标签的名称 print(soup.title.name) # 获取title标签的文本内容 print(soup.title.string) # 获取head标签的所有内容 print(soup.head) # 获取第一个div标签中的所有内容 print(soup.div) # 获取第一个div标签的id的值 print(soup.div["id"]) # 获取第一个a标签中的所有内容 print(soup.a) # 获取所有的a标签中的所有内容 print(soup.find_all("a")) # 获取id="u1" print(soup.find(id="u1")) # 获取所有的a标签,并遍历打印a标签中的href的值 for item in soup.find_all("a"): print(item.get("href")) # 获取所有的a标签,并遍历打印a标签的文本值 for item in soup.find_all("a"): print(item.get_text())
2、对象种类3、搜索文档树
使用:.find_all(name,attrs,recursive,text,**kwargs)
参数解析:
name:可以查找所有名字为name的tag,字符串对象会被自动忽略
①匹配字符串:查找与字符串完整匹配的内容,用于查找文档中所有的<a>标签
a_list = soup.find_all("a") print(a_list)②匹配正则表达式:如果传入正则表达式,则会根据正则表达式来匹配内容
# 返回所有表示<body>和<b>标签 for tag in soup.find_all(re.compile("^b")): print(tag.name)③匹配列表:如果传入列表参数,则会与列表里面的任意元素匹配内容(相当于使用”或“)
# 返回所有所有<p>标签和<a>标签: soup.find_all(["p", "a"])kwargs:
soup.find_all(id='link2')text:通过text参数可以搜索文档中的字符串内容,和name参数的可选值一样,接受字符串,正则,列表
# 匹配字符串 soup.find_all(text="a") # 匹配正则 soup.find_all(text=re.compile("^b")) # 匹配列表 soup.find_all(text=["p", "a"])4、CSS选择器
在使用BeautifulSoup解析库时,可以使用CSS选择器来提取数据。
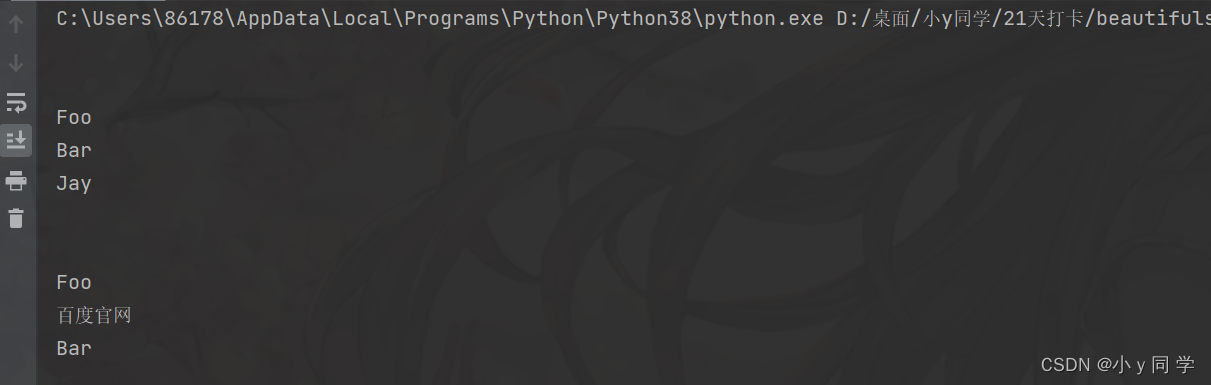
①根据标签名查找。(输入li)
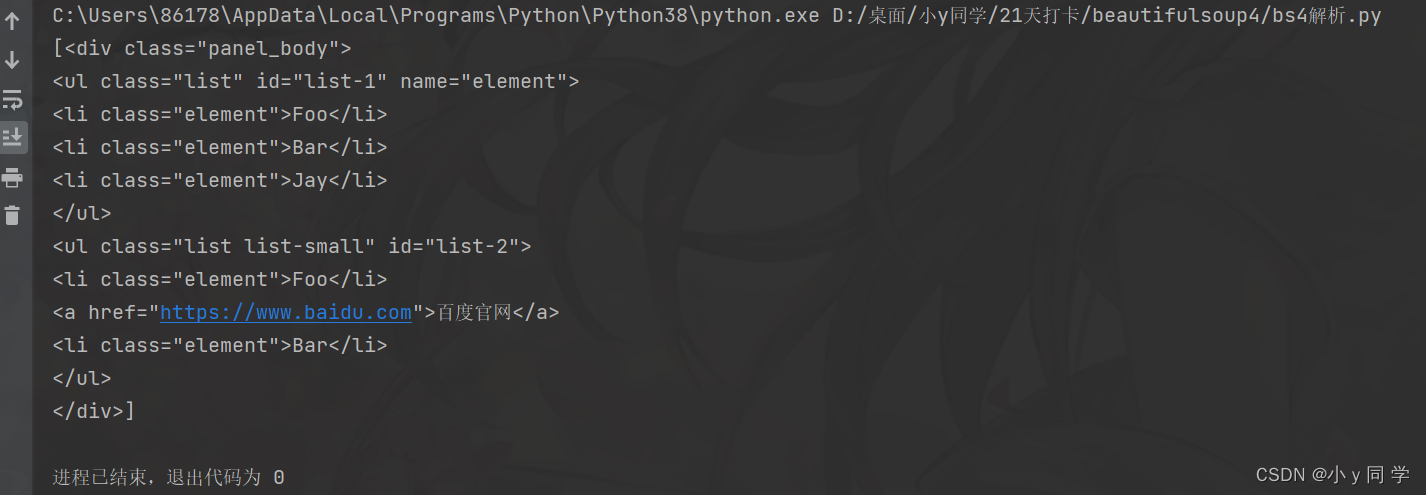
from bs4 import BeautifulSoup html = ''' <div class="panel"> <div class="panel-heading"> <h4>Hello</h4> </div> <div class="panel_body"> <ul class="list" id="list-1" name="element"> <li class="element">Foo</li> <li class="element">Bar</li> <li class="element">Jay</li> </ul> <ul class="list list-small" id="list-2"> <li class="element">Foo</li> <a href="https://www.baidu.com">百度官网</a> <li class="element">Bar</li> </ul> </div> </div> ''' # 创建对象 soup = BeautifulSoup(html, 'lxml') # 1. 根据标签名查找:查找li标签 print(soup.select("li"))运行结果:
②根据类名class查找。(.line,一个点加line,此表达式会选择class="line"的所有标签,“.”代表class)
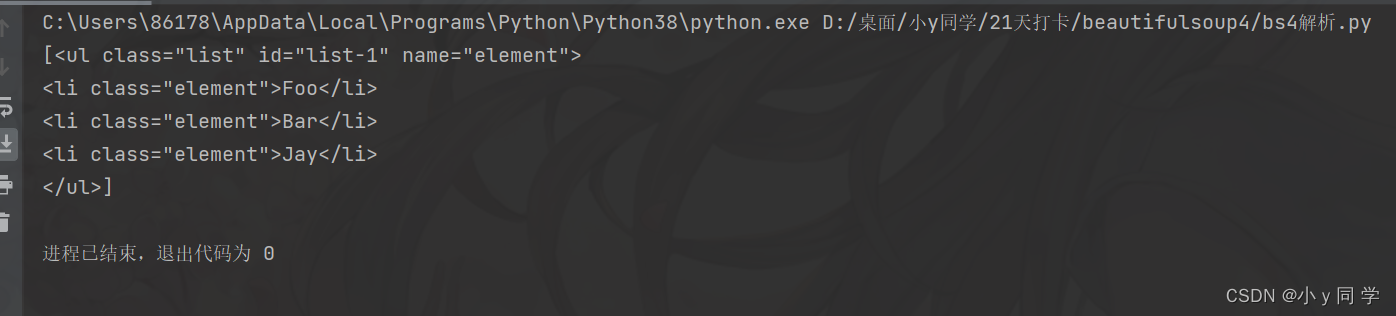
# 2.根据类名class查找 print(soup.select('.panel_body'))运行结果:
③根据id查找。(和class查找很像,#box,一个#加box,此表达式会选择id="box"的所有标签,“#”代表id)
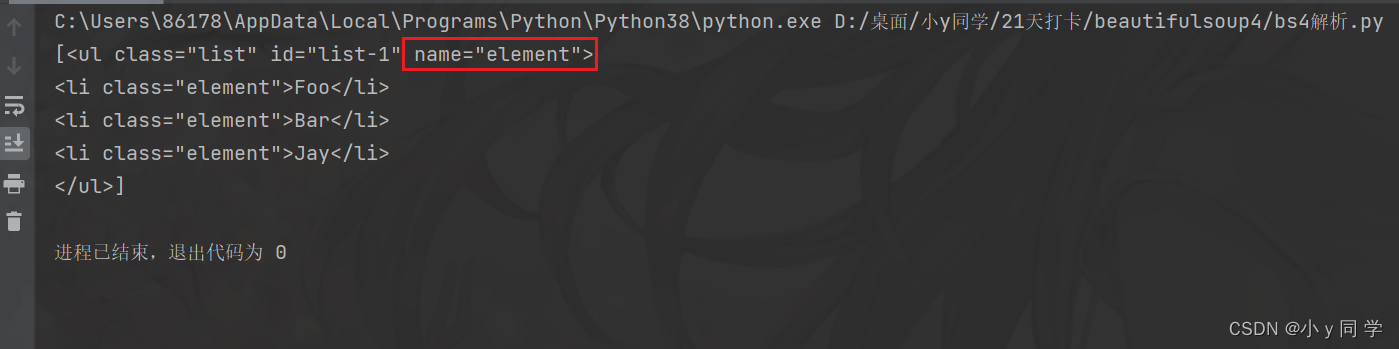
# 3.根据id查找 print(soup.select('#list-1'))运行结果:
④根据属性的名字查找。
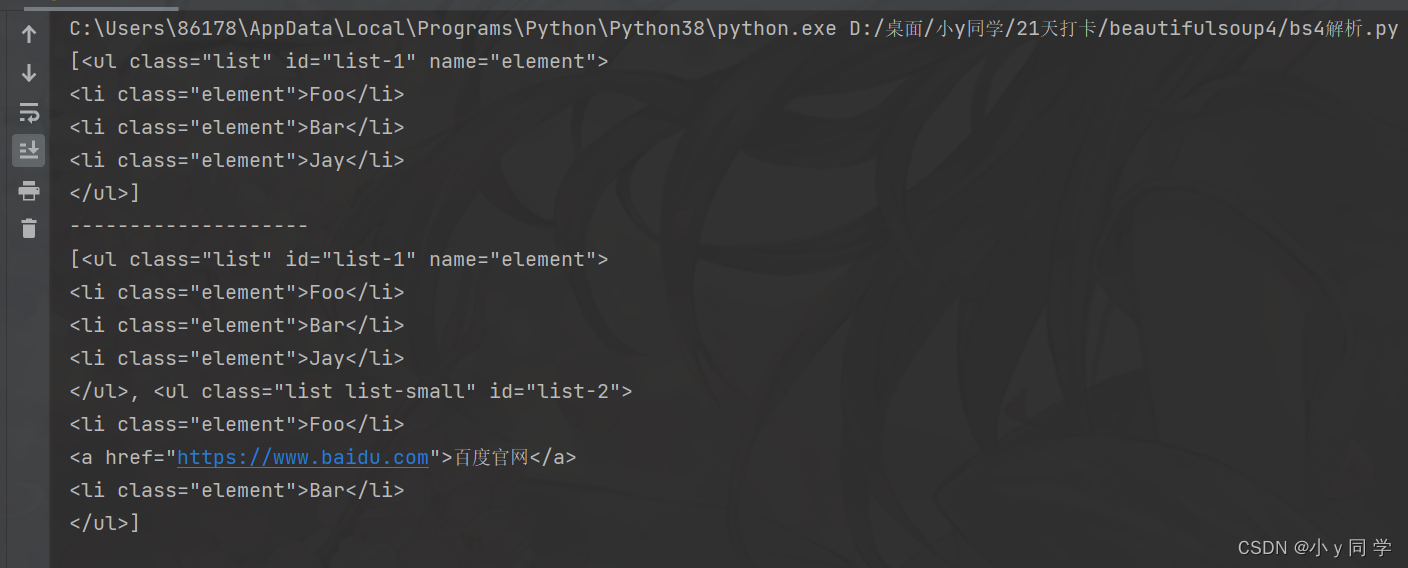
# 4、根据属性的名字查找 print(soup.select('ul[name="element"]'))运行结果:
⑤标签+类名或id的形式查找
# 查找id为list-1的ul标签 print(soup.select('ul#list-1')) print("-"*20) # 查找class为list的ul标签 print(soup.select('ul.list'))运行结果:
⑥查找直接子元素
# 查找id="list-1"的标签下的直接子标签li print(soup.select('#list-1>li'))运行结果:
⑦查找子孙标签
# .panel_body和li之间是一个空格,这个表达式查找id=”.panel_body”的标签下的子或孙标签li print(soup.select('.panel_body li'))运行结果:
⑧取某个标签的属性
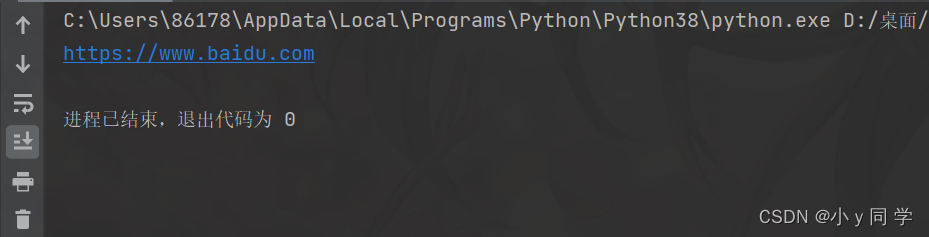
# 1. 先取到<div class="panel_body"> div = soup.select(".panel_body")[0] # 2. 再去下面的a标签下的href属性 print(div.select('a')[0]["href"])运行结果:
⑨、获取文本内容的四种方式:
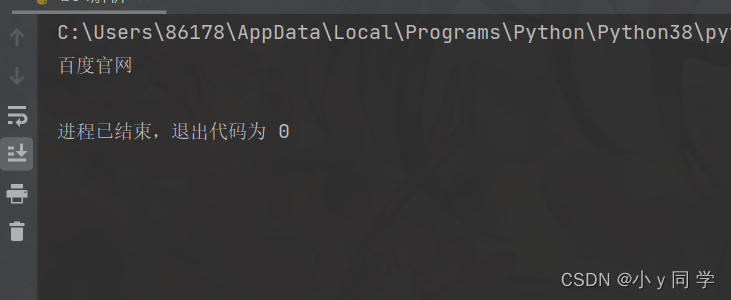
a、string:获取某个标签下的文本内容,强调一个标签,不含嵌套,返回的是一个字符串类型数据。
# 1. 先取到<div class="panel_body"> div = soup.select(".panel_body")[0] # 2. 再去下面的a标签下 print(div.select('a')[0].string)运行结果:
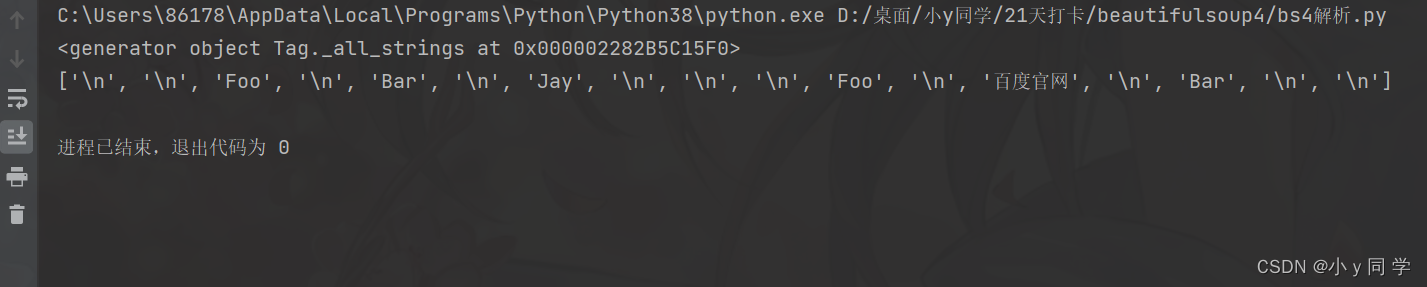
b、strings:获取某个标签下的所有文本内容,可以嵌套,返回一个生成器(可以用list(生成器)转换为列表)
div = soup.select(".panel_body")[0] print(div.strings) print(list(div.strings))运行结果:
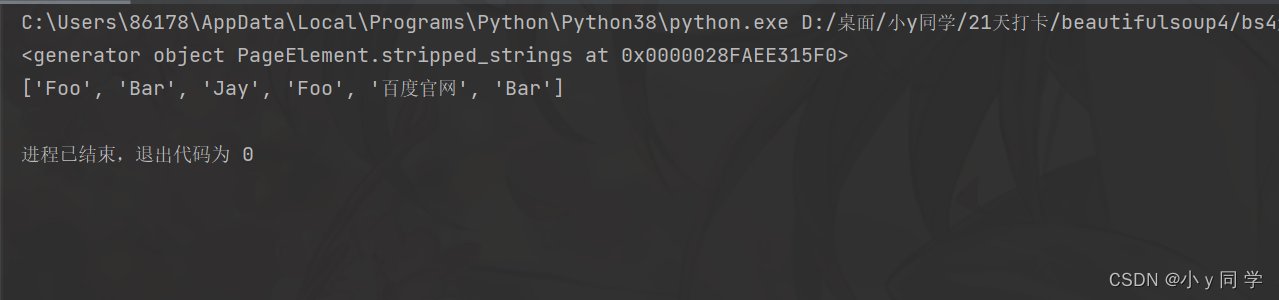
c、stripped.strings:和strings差不多,但是它会去掉每个字符串头部和尾部的空格和换行符
print(div.stripped_strings) print(list(div.stripped_strings))运行结果:
d、get.text():获取所有字符串,含有嵌套,但是会把所有字符串拼接成一个字符串返回
print(div.get_text())运行结果:



以上便是小y的学习笔记,小y希望和大家共同进步!
欢迎点赞+收藏+关注!
















 9777
9777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











