







目录
前言
道路千万条,安全第一条
爬虫不谨慎,亲人两行泪
获取豆瓣小说分类界面的图片信息
上一篇我们说了怎么去获取该界面的文本信息,
python-爬虫实例(2):获取豆瓣小说分类界面的文本信息-CSDN博客
今天我们来获取它的图片信息。
一、话不多说,浇给
import requests
import fake_useragent
from lxml import etree
import os.path
head = {
"User-Agent": fake_useragent.UserAgent().random
}
pic_name = 0
def tu():
for j in range(0, 100, 20):
url = f"https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start={j}&type=T"
response = requests.get(url, headers=head)
douban_text = response.text
tree = etree.HTML(douban_text)
li_novel = tree.xpath("//ul[@class='subject-list']/li") # 获取所有ul标签下的li标签内容
for i in li_novel: # 遍历所获取的所有li标签
url_img = "".join(i.xpath("div[1]/a/img/@src")) # 获取图片的url,再次进行爬取操作
img_response = requests.get(url_img, headers=head)
img_content = img_response.content
global pic_name
with open(f"./public/{pic_name}.jpg", "wb") as fp:
fp.write(img_content)
pic_name += 1
if __name__ == '__main__':
if not os.path.exists("./public"):
os.mkdir("./public")
tu()
pass输出:会将获取到的图片放进文件夹中
二、爬虫四步走
1.UA伪装
还是用上次的随机生成伪装,大部分情况下都可以使用这个方法
import requests
import fake_useragent
from lxml import etree
import os.path
head = {
"User-Agent": fake_useragent.UserAgent().random
}
2.获取url
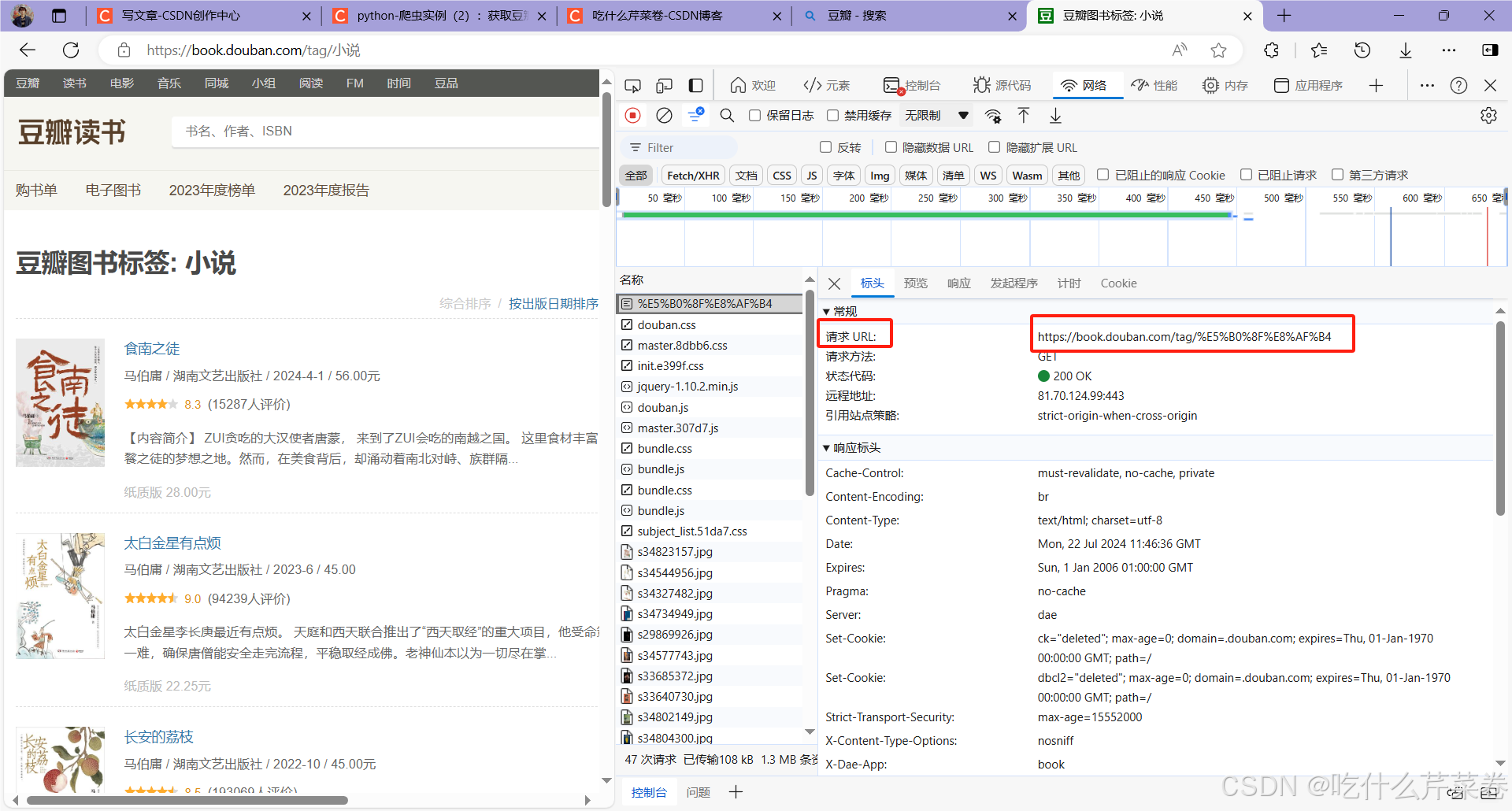
在该界面按f12进入检查界面,若是检查界面没东西的话就刷新网页,然后往上翻到第一个,复制url粘贴到pycharm即可
3.发送请求
流水的url,铁打的发送请求。
response = requests.get(url, headers=head)
4.获取响应数据进行解析并保存
上一篇文章讲过了用,etree.HTML解析网页,再用xpath获取标签内容。本次使用的也是这个方法
右击书的封面图片即可找到所在标签,如图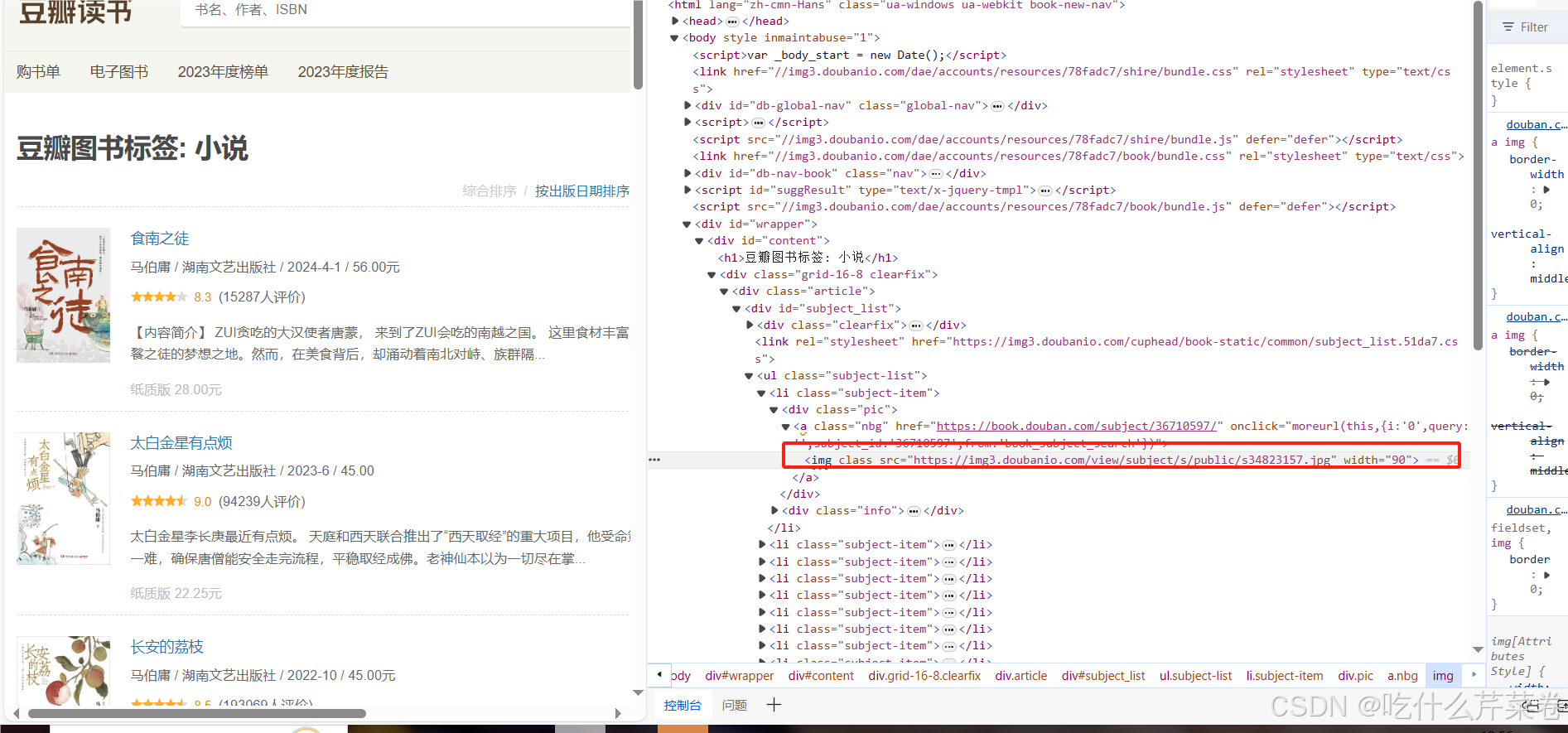
- 就可以通过循环ul标签下的li标签去获取每一本书的图片
- 而这个图片其实也是一个网页url,因为点击图片链接就会跳转到那张图片,
- 那么我们就可以对图片再次进行请求和获取操作
- 在这里略有不同的是,图片,音频之类的信息使用二进制数据保存的,所以这里使用.content的方法去解析数据。
- 因为每一个图片都是一个单独的文件,所以这里使用with open去储存图片,pic_name用来给图片命名。
pic_name = 0
def tu():
for j in range(0, 100, 20):
url = f"https://book.douban.com/tag/%E5%B0%8F%E8%AF%B4?start={j}&type=T"
response = requests.get(url, headers=head)
douban_text = response.text
tree = etree.HTML(douban_text)
li_novel = tree.xpath("//ul[@class='subject-list']/li") # 获取所有ul标签下的li标签内容
for i in li_novel: # 遍历所获取的所有li标签
url_img = "".join(i.xpath("div[1]/a/img/@src")) # 获取图片的url,再次进行爬取操作
img_response = requests.get(url_img, headers=head)
img_content = img_response.content
global pic_name
with open(f"./public/{pic_name}.jpg", "wb") as fp:
fp.write(img_content)
pic_name += 1
最后,创建个新的文件夹去保存获取到的所有图片。
if __name__ == '__main__':
#如果当前工作目录下不存在名为public的文件夹,则创建一个新的public文件夹。
if not os.path.exists("./public"):
os.mkdir("./public")
tu()
pass


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











