







简述:
当我们需要对数据表索引进行设定时,常用到set_index()和reset_index()函数进行索引设置,下面通过简单的例子分析进一步了解其用法。
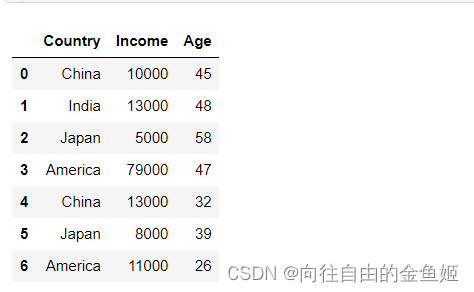
创建一个数据表:
import pandas as pd
import numpy as np
df = pd.DataFrame({
'Country':['China','India','Japan','America','China','Japan','America'],
'Income':[10000,13000,5000,79000,13000,8000,11000],
'Age':[45,48,58,47,32,39,26]
})
df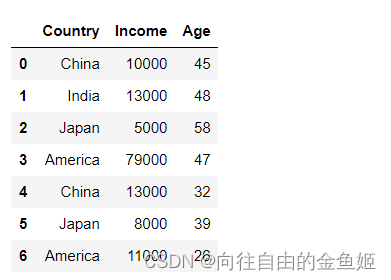
set_index()
函数体与默认参数
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)参数:
keys:列标签或数组列表,需要设置为索引的列
drop:默认为True,删除用作新索引的列
append:是否将列附加到现有索引,默认为False。
inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
verify_integrity:检查新索引的副本。否则,请将检查推迟到必要时进行。将其设置为false将提高该方法的性能,默认为false。
设置索引
将Country 作为索引值
# df_Contry = df.set_index('Country',drop=True,append=False,inplace=False,verify_integrity=False)
df_new1 = df.set_index('Country')
df_new1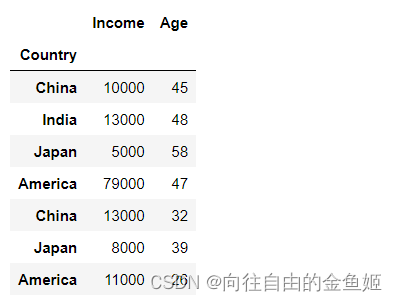
与原表相比,Country代替了索引,而且删除了作为索引的列。
drop=False
df_new2 = df.set_index('Country',drop=False)
df_new2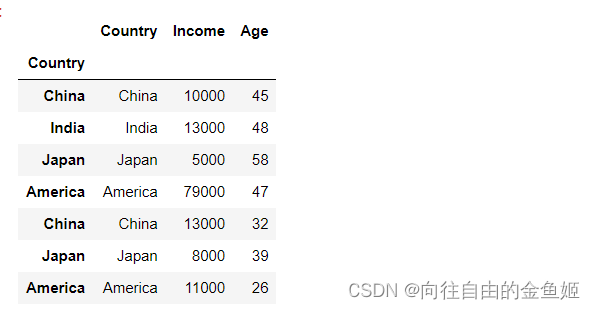
可以看出,作为索引的列Country被保留下来了。
append=False
# append=False
df_new3 = df.set_index('Country',append=False)
df_new3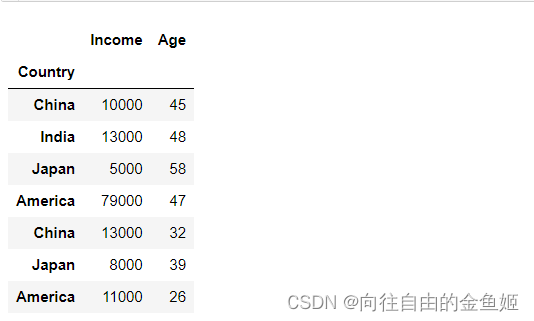
因为默认参数为append=False,与df_new1是一样的。
append=True
# append=True
df_new4 = df.set_index('Country',append=True)
df_new4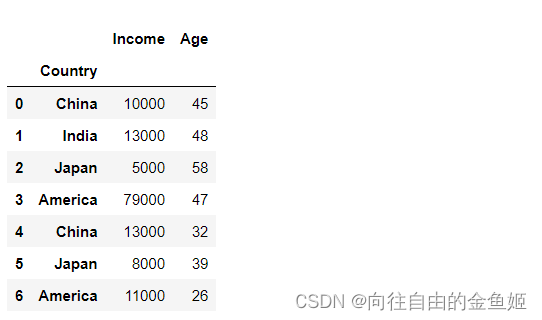
可以看到:因为指定了append=True,所以将列附加到了现有索引
reset_index()
主题函数与默认参数
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')参数:
level:数值类型可以为:int、str、tuple或list,默认无,仅从索引中删除给定级别。默认情况下移除所有级别。控制了具体要还原的那个等级的索引 。
drop:当指定drop=False时,则索引列会被还原为普通列;否则,经设置后的新索引值被会丢弃。默认为False。
inplace:输入布尔值,表示当前操作是否对原数据生效,默认为False。
col_level:数值类型为int或str,默认值为0,如果列有多个级别,则确定将标签插入到哪个级别。默认情况下,它将插入到第一级。
col_fill:对象,默认‘’,如果列有多个级别,则确定其他级别的命名方式。如果没有,则重复索引名。
reset_index()的还原
经过set_index()处理过的数据表
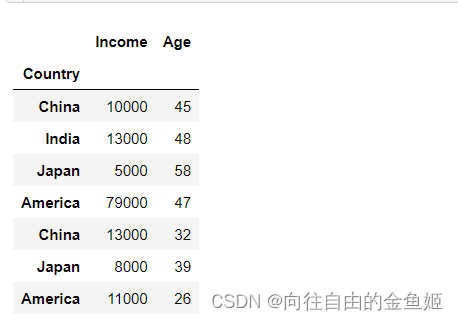
还原
注意观察:是不是和原表df一样?还原时的参数drop=False。
drop=False
df_new03 = df.reset_index(drop=False)
df_new03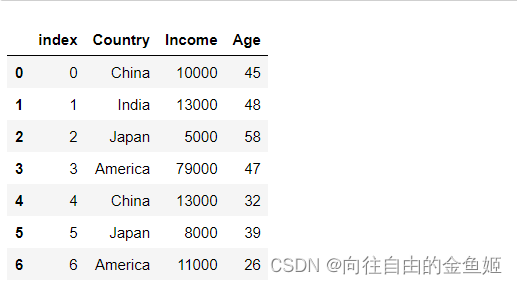
可以观察到:index也会作为新列保留下来,同时在新列上进行了重置索引。
drop=True
# drop=True
df_new04 = df.reset_index(drop=True)
df_new04
与原表是没有区别的,因为默认的参数drop=True















 7079
7079











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









