







1. 认知科学和心理语言学的发展与任务
认知科学和心理语言学是两个密切相关的领域,它们研究认知过程和语言使用是如何相互作用的。
1.1 认知科学和心理语言学的历史发展
在历史上,这两个领域的发展经历了几个重要的阶段:
1.1.1 19世纪晚期(内省法)
Wundt 和其他德国心理学家使用一种叫做内省法的研究方法。内省法是一种主观的方法,研究者通过自我观察和分析个人的思维过程来研究心理现象。这种方法高度依赖于个体的自我报告,因此在客观性上存在限制。
1.1.2 20世纪20年代(行为主义)
Watson 和其他美国心理学家提出了行为主义。行为主义者拒绝发展任何关于心智操作的理论,他们只观察可见的行为,并尝试通过刺激与反应之间的关系来解释这些行为。这个阶段标志着心理学研究从内部心理过程的探究转向了对外在行为的观察和分析。
1.1.3 二战后(心理语言学)
认知心理学受到信息论(由Shannon提出)、人工智能(Minsky的研究)和生成语言学(Chomsky的工作)的影响。这一时期,心理学家开始关注心智如何处理信息,包括记忆、思维、解决问题等认知过程。心理语言学作为心理学和语言学交叉的一个分支,专注于研究语言获取、语言理解和语言产生的心理机制。
1.1.4 在最近几十年(大脑在进行认知活动时的活动模式)
新的洞察来自于神经生理技术的发展,如功能性磁共振成像(Functional Magnetic Resonance Imaging, FMRI)、正电子发射断层扫描(Positron Emission Tomography, PET)、磁脑电图(Magnetoencephalography, MEG)等。这些技术使得科学家能够直接观察大脑在进行认知活动时的活动模式,从而提供了关于认知过程和语言处理的新见解。
总的来说,认知科学和心理语言学是通过不断发展的研究方法和技术,从不同角度探索人类认知和语言能力的领域。随着时间的推移,这些领域在理论和实践上都取得了显著的进展。
1.2 心理语言学的主要任务
心理语言学涉及到语言产生、理解和加工等多个方面。这一领域旨在解析个体是如何规划、产出、理解语言的,以及这一过程中所涉及的认知机制和大脑活动。以下是主要任务:
1.2.1 规划语句(Planning Utterances)
探讨个体如何组织和规划要表达的思想和信息,包括选择合适的语言结构和词汇来传达意图。
1.2.2 寻找词汇(Finding Words)
分析语言用户如何从其词汇库中选择恰当的词汇来表达思想,包括词汇检索的过程和机制。
1.2.3 构建词汇(Building Words)
研究词汇的形成过程,包括词形变化和词汇的组合,以及这一过程对语言产出的影响。
1.2.4 监控和修正(Monitoring and Repair)
讨论个体如何在语言产出过程中监控和评估自己的语言,以及在发现错误时如何进行修正。
1.2.5 手势的使用(The Use of Gesture)
分析手势如何与言语交互作用,支持语言的表达和理解,以及手势在沟通中的作用。
1.2.6 语言的感知(Perception for Language)
探索大脑如何处理和理解语言信号,包括听觉和视觉信息的接收和加工。
1.2.7 口语词汇识别(Spoken Word Recognition)
研究个体如何识别和理解口语中的词汇,包括声音信号的处理过程。
1.2.8 视觉词汇识别(Visual Word Recognition)
探讨如何通过视觉加工识别书写文字,包括阅读过程中的字形和词汇处理。
1.2.9 句法句子处理(Syntactic Sentence Processing)
分析个体如何理解句子的结构,以及如何通过句法规则构建意义。
1.2.10 解释句子(Interpreting Sentences)
讨论在语境中理解和解释句子含义的过程,包括推断和语境效应。
1.2.11 建立连接(Making Connections)
探索个体如何将新的语言信息与已有知识联系起来,以及这一过程对理解和记忆的影响。
1.2.12 语言处理系统的架构(Architecture of the Language Processing System)
综合讨论语言加工的整体结构和组织,包括认知和神经机制,以及不同加工层面之间的交互。
这个计划提供了一个全面的框架,用于探索心理语言学中的关键议题和研究方向,旨在深入理解语言的认知基础和加工机制。
2. 规划语句(Planning Utterances)(1.2.1中提及)
2.1 规划语句
在心理语言学中,规划语句(Planning Utterances)是一个复杂的过程,涉及从最初的想法到最终的语言表达的多个阶段。这一过程通常包括以下几个步骤:
2.1.1 概念化(Conceptualization)
概念化是一个前语言阶段,在这一阶段,我们组织和安排自己的想法,构建一个前言语消息。这个过程发生在我们的内心,使用的是一种被称为心智语言(mentalese,或 mentalais)的内部过程,这种过程并不依赖于任何具体的自然语言形式。
在概念化过程中,我们决定要传达的信息内容,这包括选择相关的概念、想法和意图。
2.1.2 语法编码(Grammatical Encoding)
语法编码是将前言语消息转换为特定语言表达的过程。这个阶段可以进一步分为四个子步骤:
a.词汇选择(Lexical Selection):从我们的词汇库中选择合适的词汇来表达我们的想法。
b.功能分配(Function Assignment):确定各个词汇在句子中的语法角色,比如主语、宾语等。
c.位置处理(Positional Processing):安排词汇在句子中的顺序。
d.成分组装(Constituent Assembly):将选定的词汇和短语组装成完整的句子结构。
2.1.3 音韵编码(Phonological Encoding)
在音韵编码阶段,已经编码的语言内容被进一步处理为内部语音形式。这一步骤涉及到音节和音位的选择,为即将发出的语言制定一个内部的声音计划。
2.1.4 发音(Articulation)
最后一步是发音,即实际产生语言声音或书写文字的过程,属于外部语言/书写。在这个阶段,内部语音形式转化为实际的语音动作,通过口部和发声器官的运动来产出声音,或者通过手部动作在书写媒介上形成文字。
这一连串的过程展示了从最初的思想到实际语言表达的完整转化路径。每个阶段都是高度协调和精细调控的,体现了语言产生过程的复杂性和动态性。
2.2 心智语言(2.1.1中提及)
在规划语言表达的过程中,心智语言(Mentalese)是一个关键的概念,它代表了我们在内心用来组织和加工想法的非言语形式的思维方式。在这一框架下,想法被用来构建一个心理模型,这个模型是通过各种主题角色(如施事者、受事者、行动等)来组织的。这种组织方式有助于我们理解和规划即将进行的语言表达。以下是这一过程中的一些关键点:
2.2.1 心理模型的构建
在心智语言中,我们利用想法构建一个心理模型,该模型包含了我们想要表达的信息的所有相关方面。这个模型是高度抽象的,不依赖于任何具体的自然语言。
心理模型按照主题角色进行结构化,这些角色定义了句子中各个元素的功能和相互关系。例如,施事者(agent)是执行动作的实体,受事者(patient)是动作影响的对象,而行动(action)则描述了发生的具体事件。
2.2.2 语言规划的层次
通过研究说话时的停顿(包括发音停顿、界定性停顿、生理性停顿即呼吸),我们了解到语言规划包含宏观规划(macroplanning)和微观规划(microplanning)两个层次。
宏观规划涉及到整体目标的设定,即我们想要通过语言表达实现的全局目标。
微观规划则关注每一个言语行为,包括如何表达具体的想法、选择恰当的词汇和语法结构等。
2.2.3 说话的流畅性变化
在规划语言表达时,说话可能会更加犹豫,这是因为我们在进行心理模型的构建和细节的规划。这一阶段,说话者可能会频繁地停顿,以组织思路和选择适当的表达方式。
随着言语的继续和规划过程的推进,说话变得更加流畅。这表明说话者已经完成了大部分规划工作,可以较为顺畅地进行语言表达。
这些过程揭示了人类在进行语言表达前的复杂心理活动,包括如何从一系列抽象的想法中构建出有意义的、组织良好的语言输出。通过理解这些过程,我们能够更好地认识到语言产生的复杂性以及人类如何有效地进行沟通。
2.3 语法编码(Grammatical Encoding)(2.1.2中提到)
在语言学中, 功能分配(选择词语的功能)和位置处理(即排序)是两个专门的术语,它们描述了我们在生成语言时大脑内部的两个分离的过程。
2.3.1 位置处理(排序)
这是指在我们说话或写作时,如何决定单词的顺序。在英语中,通常的顺序是主语-动词-宾语,但其他语言可能有不同的顺序。位置处理确保我们把词放在正确的位置,使句子有意义。
2.3.2 功能分配(选择词语的功能)
这是指如何决定每个词在句子中的语法角色。比如在“猫坐在垫子上”这句话中,“猫”是主语,“坐”是动词,“垫子”是宾语。
2.3.3 言语错误
言语错误(如将单词放在错误的位置或使用错误的单词形式)可以帮助我们了解这些过程。例如,如果某人想说“a floor full of holes”(一个满是洞的地板),但不小心说成了“a hole full of floors”(一个满是地板的洞),这个错误可能表明,在他们的大脑中,单词的排序(位置处理)和它们的功能(功能分配)是分开考虑的。这是因为“floor”和“hole”可以在句子中扮演同样的语法角色(都可以做主语),所以它们更容易被交换。
2.3.4 语法启动
语法启动是另一个例证。它是指人们在说过一句话之后,如果要描述一个场景,他们倾向于使用刚才说过的那种句子结构,即使新的场景和之前说的句子内容不相关。这表明,之前的语言结构影响了后来的语言产出,说明位置处理和功能分配是分开进行的,因为人们在没有意识到的情况下就重复了之前的句子结构。
通过这些现象,我们可以了解到,当我们构建句子时,单词的顺序(位置处理)和单词的语法角色(功能分配)是通过不同的心理语言机制来实现的。
3. 寻找单词(1.2.2中提到)
在语言产生过程中寻找单词的两个阶段,即词汇化(lexicalization)的过程:
3.1 找到单词(finding words)
概念(concept)是语言产生的起点,即你想要表达的基本概念或思想。
接下来,你从心智词汇表中检索与该概念相关的抽象形式:词元(lemma)。词元是单词的基本形式,通常是字典中的查找形式,例如动词的原形。
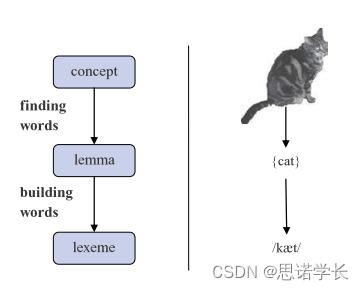
3.2 构建单词(building words)
你构建具体的单词形式变为词位(lexeme),这是词元的具体语音实现,也就是我们说或写的实际单词形式。
在单词选择和语音编码过程中考虑的其他因素:
寻找合适的单词时,会考虑词频(frequency)和可预测性(predictability)。例如,在短语“too many cooks spoil the broth”中,由于短语的固定性和预期性,下一个单词很容易预测。
功能词(function words,如冠词、介词、连词等)在心智词汇表的不同部分,并在构建语法句子框架时变得可用。
整个过程强调了从有一个想法到说出或写出具体单词之间的转换,以及在这个过程中涉及的不同认知步骤。
3.3 心理语言学领域中的词元(lemma)、词位(lexeme)和词素(morpheme)
在心理语言学领域(例如Warren的研究),词元(lemma)、词位(lexeme)和词素(morpheme)是三个重要概念,它们用来描述语言中不同层次的语言单位。
3.3.1 词元(Lemma)
词元(Lemma)通常指的是一组词的词典形式或基本形式,用于代表该单词的所有变化形式。在多数情况下,词元是指动词的不定式形式、名词的单数形式等。例如:英语的 transform 和法语的 superviser 都是词元。这就像是你在字典里查找的单词的“原型”。比如说,动词“run”在字典里只有一个形式,不论它是用在过去时(ran)、现在分词(running)还是其他时态中。中文里的例子就像是“跑”,不管它是“跑步”还是“跑了”。
3.3.2 词位(Lexeme)
词位(Lexeme)是指一个单词的具体形式,是抽象的语言单位,指的是一组具有相同核心意义和用法的词的集合,不考虑时态、数、性等语法变化。例如:
英语的“transformed”和法语的“supervisâmes”都是词位。 它是指单词的具体形式,包括它所有的变化。比如说,“run”这个词位就包括了“run”, “runs”, “ran”, “running”等所有形式。中文里的例子就像是“跑”,“跑了”,“跑步”都属于“跑”这个词位的不同形式。在YH24的定义中,词位与词元(lemma)等同,都指的是词的基本形式。
3.3.3 词素(Morpheme)
词素(Morpheme)是语言中意义的最小单位,不能再分割成更小的有意义部分。语素包括词根、前缀、后缀等形式。例如:英语中的“trans”,“form”,和“-ed”,以及法语中的“super”,“vis”,和“-âmes”都是词素,它们分别代表前缀、词根和表示过去时的后缀。这是语言中最小的意义单位,不能再分割。比如英文中的“un-”(不),“-ed”(过去式标记),中文中的“子”,“们”等等。它们自己不能单独成词,但可以加到其他词素上,给词带来新的意义。
总结来说,词元(lemma)是指词的基本或字典形式,词位(lexeme)是表示一个概念的抽象单位,而语素(morpheme)是构成词的最小有意义单位。这些概念帮助我们从不同角度分析和理解词汇及其结构。
3.3.4 词汇学中的词
词位(Lexeme)被视为词汇学中的基本单位,这与心理语言学中的词元概念相似。
例如:
英语的 transformed 和法语的 supervisâmes 被视为 词 ,它们是具体使用的单词形式。
英语的 transform 和法语的 superviser 在这里被视为词位,相当于心理语言学中的词元(lemma)。
这表明在不同的语言学子领域或不同的理论框架下,相同的术语可能会有不同的定义。在心理语言学中,区分这些概念有助于研究者理解语言处理的不同阶段,这些术语有助于我们理解人们是如何在大脑中处理和产生语言的。比如说,当我们要说一个词的时候,我们的大脑首先会想到这个词的基本意思(词元),然后再找到这个词的具体形式(词位),最后可能会根据需要添加不同的词素来表达不同的时态或者数等语法信息。
而在词汇学中,这些术语的定义和用法可能更加侧重于单词的形态和用法。
3.4 言语错误
在语言学中,研究言语错误可以帮助我们理解寻找单词的机制。言语错误可以被看作是一种学科或爱好,但是它们并不总是可靠的,因为它们可能是口误或者听觉上的错误。言语错误的类型包括:
3.4.1 错误选择(Mis-selection)
替换(Substitution):用一个错误的词替换了原本的词。比如,“Must you leave? It’s still so *late”中的“late”可能本意想说“early”。
混合(Blend):两个词混合成了一个新词。例如,“*buggage”可能是“bag”和“luggage”的混合。
3.4.2 错误排序(Mis-ordering)
预期(Anticipation):一个词出现得太早了。例如,“I’m not a candidate for the cabinet”说成了“I’m not a *cabinet…”。
持续(Perseveration):一个词稍后又重复出现了。比如,“How many pints in a *pint… liter”。
交换(Exchange):两个词的位置被交换了。例如,“Just *piece a *put of cardboard in it”应该是“Just put a piece of cardboard in it”。
3.4.3 遗漏(Omission)
某个词
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3665
3665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











