






(原创作品,创作不易,还望点个关注)
(没看过我之前写的python爬虫笔记一的朋友建议去看看,本次笔记需要以上篇笔记为基础进行介绍 python爬虫学习笔记:一、HTTP的构成(前置知识)-CSDN博客)
如果说爬虫就是让一只工作效率极高的蜘蛛爬虫在互联网这张蜘蛛网上把网上的虫子(信息)给搬到自个家里大快朵颐,那么我们的上一篇笔记就是介绍了互联网这张网上我们的小蜘蛛需要走的蛛丝路径---HTTP协议是怎样的一条天路,之后我们就要学习如何在这条神奇的天路上卖出第一步。(当然,希望大家能遵纪守法,不要爬取触动法律的网站。 网络不是法外之地,你也不是法外狂徒 ---张三)
正如上篇笔记所说,HTTP主要流程就是一去一来,就好似叫小孩下楼去打酱油拿快递,小孩带着你的要求去楼下小卖铺(服务器),从小卖铺又带着你要的东西(网页)回来。接下来,我们便需要让我们的小蜘蛛模仿这一过程。
但是我们的小蜘蛛没有这么聪明,需要把整个HTTP请求的内容告诉它,它才能去对应的网站上爬取下来你所需要的内容,如果是这样的话,我地勒个乖乖,那要写出个什么东西才能进行爬取啊。
这时,我们就要为我们伟大的程序员前辈表示崇高的敬意了,因为他们写了一个python的第三方库 -------requests,这个库可以说是python爬虫中的一个极其强大的库了,有了它,即使你是一个不会python,只看得懂几个if,with,elif的小白,今天,你也可以进行网页爬取了!不要998,不要98,只要你在安装号python和编译器后,只要跟着下面的操作,就可以把这个第三方库带回家!
requests的安装
就我个人而言,因为使用vscode比较多,所以比较喜欢从cmd进行安装,当然也有从Pycharm进行安装的方法,大家可以依据自己的需求进行寻找方法进行安装,下面介绍从cmd进行安装的方法:
首先我们通过左下角搜索框搜索cmd,然后以管理员身份运行:

在打开cmd这个黑的和开了小说的夜间阅读模式的窗口后输入
python -m pip install requests在正常情况下就可以成功安装了(如果安装失败的朋友可以自行复制失败原因搜索解决方法),这时我们可以尝试一下这个库
新建一个python文件,输入import requests导入requests库
import requests # 导入requests库,后续需要用该库的函数接下来我们试试使用这个库对网站 https://books.toscrape.com/进行一次访问
request=requests.get("https://books.toscrape.com/")
# 用requests.get函数发送一个get请求给网址http://books.toscrape.com/
print(request.status_code)
# 输出HTTP响应回来的状态码
# 代码的详细构成之后会详细说明
运行后我们来看看结果,嗯,是很健康的200呢~

这时我们就可以很完美的确定requests这个库装好了,可以进行我们的第一次了~
爬虫初使用
通过之前对HTTP协议流程的了解,是我们对目标网站url发送了一个方法类型,例如get方法,然后服务器给了我们一个网页,接下来我们也模仿这个过程,在导入requests这个库后,我们可以使用.get()这个函数去进行模仿get方法然目标网站(我这里用的是https://books.toscrape.com/,一个用来进行爬取练习的网站)给我们一个想要的网页,于是就有了下面的这段代码:
request=requests.get("https://books.toscrape.com/")
# 用requests库中的.get函数发送一个get请求给网址http://books.toscrape.com/,并赋给request此时使用.get函数爬取下来的内容都保存在了request中,但里面东西那叫一个杂,什么HTTP响应出来的状态码,html等一大堆东西都在里面,如果你直接print输出出来将会是状态码,而不是你想要的html中保存的数据,于是我们需要将request中的数据再进行一次转换。
iNeed=request.text
print(iNeed)
# 使用.text将存储在request中的页面数据代码储存在iNeed中,并输出出来我们使用.text将原本在request中没有表示出来的页面数据存到iNeed中这样就可以输出结果了
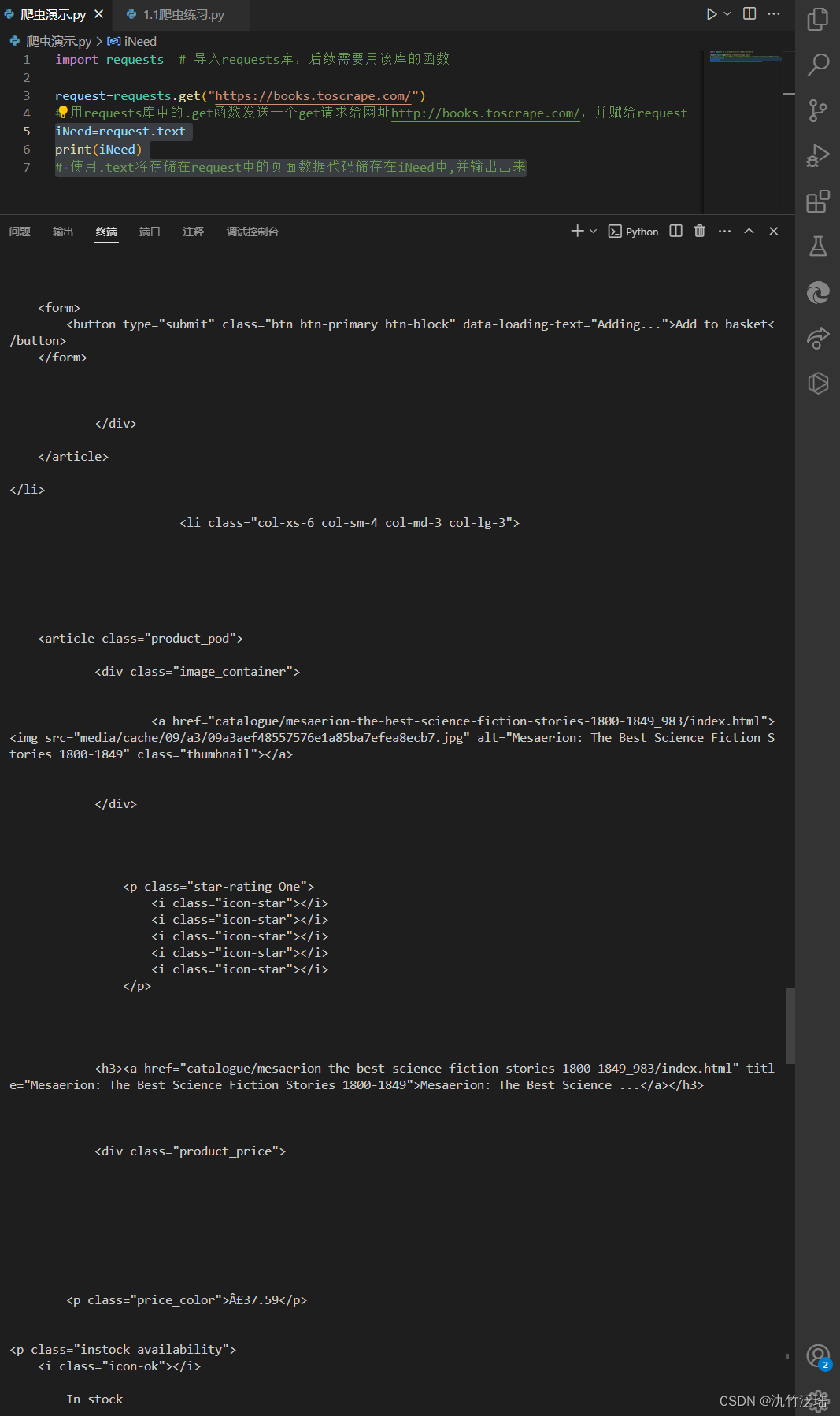
而显示出来的就是html代码,在一般情况下,我们所需要的信息就藏在这些代码里,因此我们还需要学习认识html,css,JavaScript这前端三剑客才能更好的对网页进行爬取。
接下来做一个投票,看看大家是想先系统的了解html语言再继续学习python爬虫,还是在之后的python爬虫中需要时再进行大体粗略的介绍。
(如有错误之处还望评论区指正)
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









