







 文章讲述了如何使用Python的pandas库对DataFrame进行操作,包括选择特定列、行,修改特定行的值,以及填充缺失值。具体展示了如何选取指定列,按索引选择行,筛选成绩低于60的记录,以及用平均值填充NaN值。
文章讲述了如何使用Python的pandas库对DataFrame进行操作,包括选择特定列、行,修改特定行的值,以及填充缺失值。具体展示了如何选取指定列,按索引选择行,筛选成绩低于60的记录,以及用平均值填充NaN值。
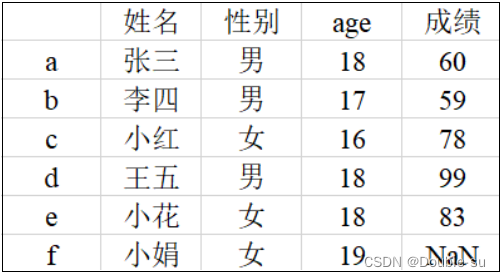
已知以下信息存在 excel 表格中,如下图所示,现利用 python 对这些数据做初步处理,
请编写代码解决以下问题。
创建一个 DataFrame 对象 df 用来存这些数据的语句为:
import numpy as np
import pandas as pd
data = {'姓名': ['张三', '李四', '小红', '王五', '小花', '小娟'],
'性别': ['男', '男', '女', '男', '女', '女'],
'age': [18, 17, 16, 18, 18, 19],
'成绩': [60, 59, 78, 99, 83, np.nan]
}
labels = ['a', 'b', 'c', 'd', 'e', 'f']
df = pd.DataFrame(data, labels)
(1) 选择 df 中列标签为性别和 age 的数据。
df[['性别','age']](2). 选择行为[1, 3, 4],且列为[性别', 'age']中的数据。
df.iloc[[1,3,4],:][['性别','age']](3). 选择成绩小于 60 的行。
df[df['成绩']<60](4). 将 c 行的 age 修改为 20。
df.loc['c','age']=20(5). 将成绩为 NaN 的值填充为该列的平均值。
df['成绩']=df['成绩'].fillna(df['成绩'].mean())















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









