






爬取豆瓣50页书籍的名字
代码如下(这是第一次写的代码,出现了一些问题)
出现爬取不到1000本就停止了
原因使用find_all 若有些书籍若副标题不存在,则会将其他书籍的副标题加在上一本的书籍
解决方法:使用find一个一个检查是否存在副标题 副标题在span标签里 用if语句判断
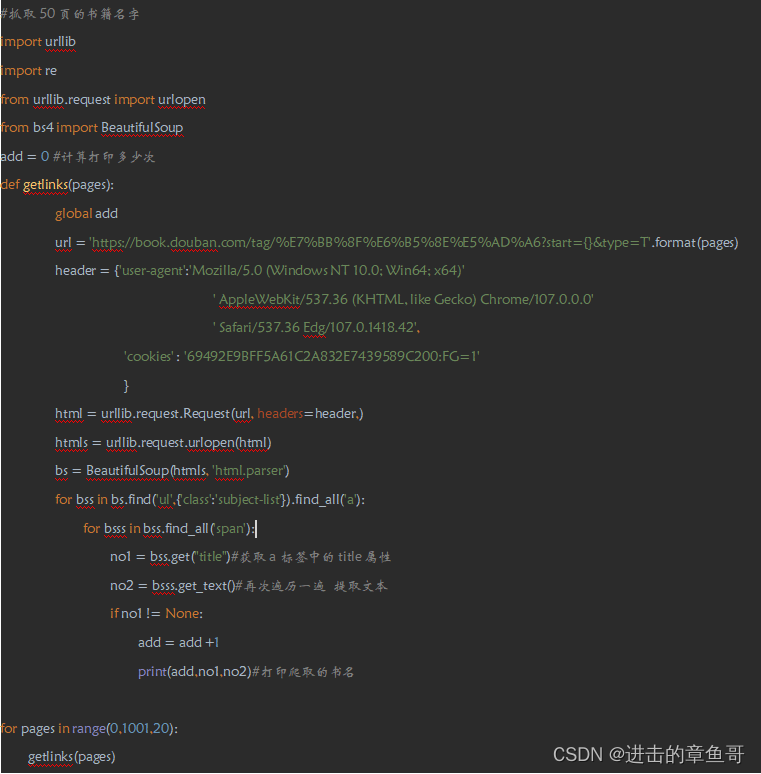
积累:
1.准确访问标签内的属性可以使用get(“属性值”)获得

如图获取a标签中指定的title属性
2.获取span标签中包含的内容 先用find_all查找上一级标签中包含的span标签,再用for循坏遍历get_text()提取文本内容
3.在终端去除None值 加入判断语句 若爬虫的值为Null则不打印
4.range()函数的使用方法 range(起始值,结束值,每次增加的值) 若结束值为11,则只到了10
改进的代码如下:
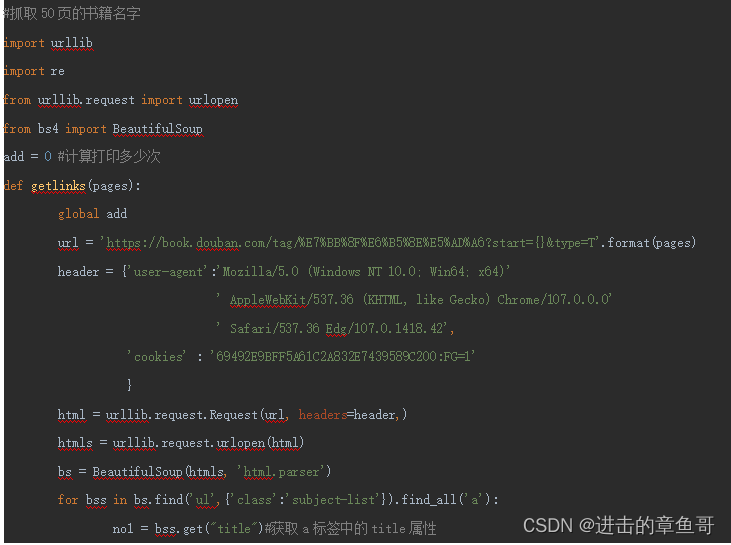
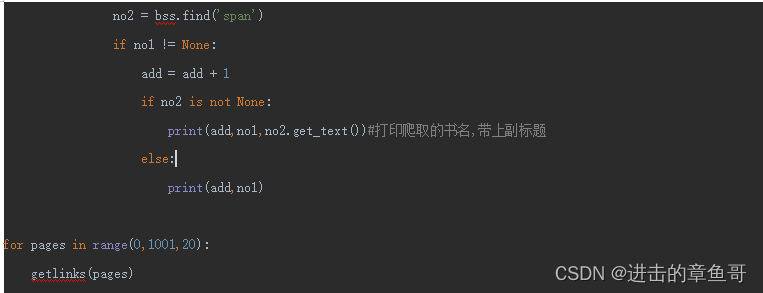
运行效果:
积累:
1.用for循环遍历 打印出来的结果是一个标签一个标签打印的
此时可以用 if语句检验是否存在某标签 如下:
If bs.find_all(‘a’).find(‘span’) is not None:
.......
Else:
.......

















 2884
2884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









