







红队系列
🍭bilibili对应配套视频:
https://www.bilibili.com/video/BV1EM4y1q7TS/?share_source=copy_web&vd_source=0e30e09a4adf6f81c3038fa266588eff
🔥系列专栏:红队系列
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
📆首发时间:🌴2023年5月16日🌴
🍭作者水平很有限,如果发现错误,还望告知,感谢!
文章中所有的操作均仅限于展示,不涉及任何的真实攻击,扫描等行为,本文章所采用的方法未经有关单位授权不可擅用,违者自行承担后果。请读者严格遵守相关法律,谢谢。
我计划的整个红队体系:
外网信息收集——>打点——>权限维持——>提权——>内网信息收集——>横向移动——>痕迹清理
这是第一章节,后续也会继续发出其他章节
大佬云:信息收集决定了你的成败与否
准备阶段
1.准备一个隧道代理,我只用过快代理的,价钱还行,防止被BANip
2. 清除个人信息(自己用的武器库东西整好以后保存一下快照,每次做测试的时候恢复)
3. 浏览器随时隐私模式
4. 不要登任何的私人账号,防止被后期溯源
正式开始
1. 主域名信息搜集
(1)备案信息查询
站点最下面会有备案信息
我们可以去一些网站进行备案信息的查询,直接点一下就跳转了
这里的图片被和谐了,视频里可以看
于是我们知道了,这是北京的单位
同时还有SEO综合查询,还可以,比较全
https://seo.chinaz.com/fofa.info
(2)whois查询(没啥用了现在)
现在whois基本上查不到啥东西,但是还是看几个,有些也许有缓存,主要站长之家一定要看
站长之家(推荐)
http://whois.chinaz.com
Bugscanner
http://whois.bugscaner.com
国外BGP
https://bgp.he.net
who.is
https://who.is/
IP138网站
https://site.ip138.com/
域名信息查询-腾讯云
https://whois.cloud.tencent.com/
ICANN LOOKUP
https://lookup.icann.org/
狗狗查询
https://www.ggcx.com/main/integrated
(3)IP反查
因为可能有多个域名在一台服务器上,所以IP反差可能可以找到其他资产
站长之家工具
https://stool.chinaz.com/same
在线平台:
https://www.webscan.cc/
https://viewdns.info/reverseip/
https://reverseip.domaintools.com/
https://tools.ipip.net/ipdomain.php
https://dnslytics.com/
或者直接fofa,hunter那些就OK
(4)host碰撞
有一些页面显示nginx、4xx、500、503、各种意义不明的Route json提示,包括只有一些默认页面。这种一般需要绑定host去访问
就是意思是只能host去访问
所以这种情况就需要host碰撞去尝试
ARL,水泽,hostscan可以完成目标
https://github.com/TophantTechnology/ARL
https://github.com/0x727/ShuiZe_0x727
https://github.com/cckuailong/hostscan
(5)DNS记录
DNS记录的利用点在于如果一些公司自己搭建了外部DNS服务器,可以通过查询他的一些记录,找到一些该公司的域名
查询方式
nslookup -query=ns baidu.com 8.8.8.8
这个图片也被和谐了
有5个DNS服务器,一看就是百度自己搭建的
所以我们查询一下
https://hackertarget.com/find-shared-dns-servers/
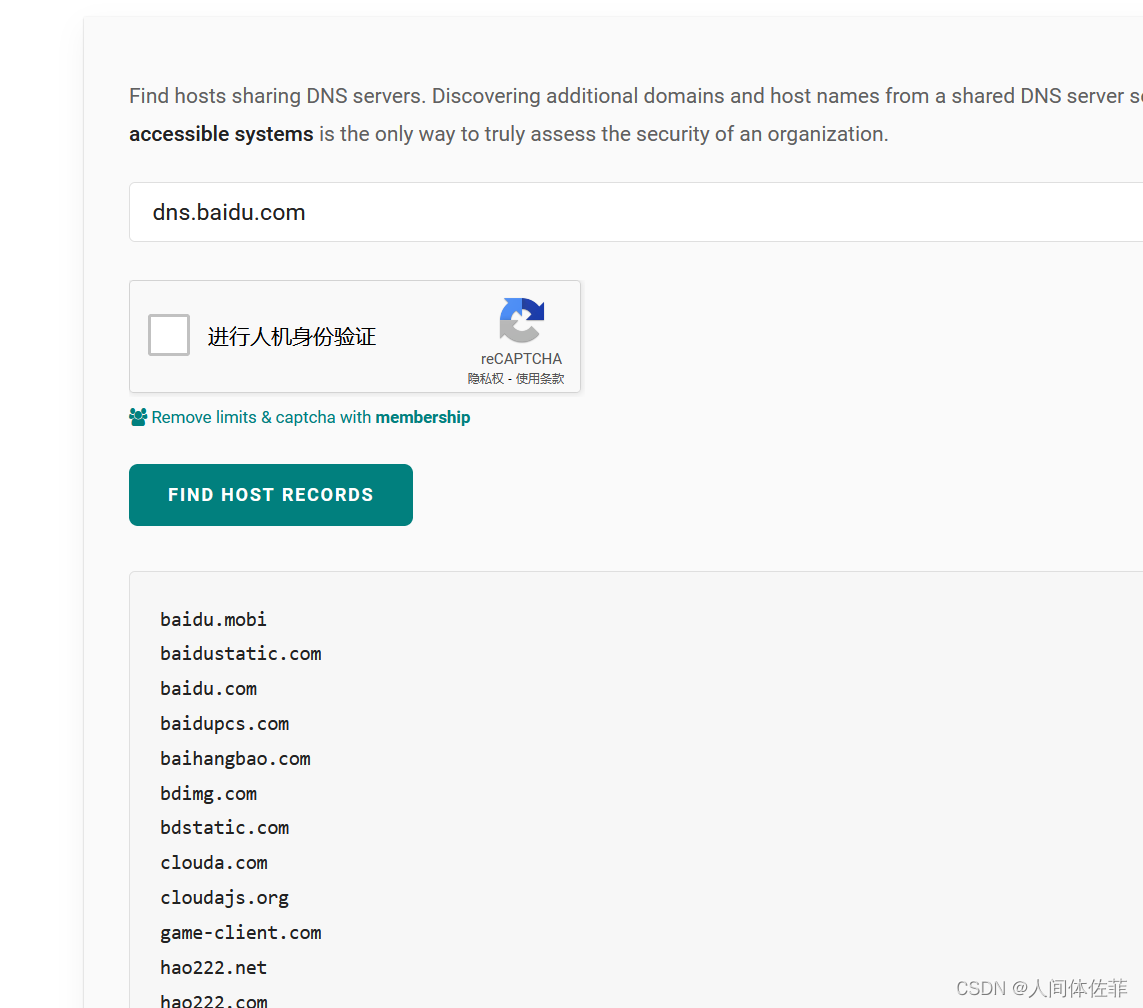
(6)配置信息泄露
常见的有crossdomain.xml文件
直接域名拼就行了
sitemap.xml、sitemap.txt、sitemap.html、sitemapindex.xml、sitemapindex.xml
也是直接域名拼就行了
一般很多字典里面都有
不多说了
(7)各种漏洞平台
有些公司会在众测项目里给出自己的域名让你测试
(8)企业信息
企业信息就在什么爱企查什么的去查
有可能有东西,重点关注邮箱,开发的应用之类的
包括一些姓名
常用的
天眼查
企查查
爱企查
七麦数据
https://www.qimai.cn/
小蓝本(个人推荐)
https://www.xiaolanben.com/pc
豌豆荚(历史版本app)
https://www.wandoujia.com/
2. 子域名信息搜集
子域名的收集非常简单粗暴
他有很多种方式,有兴趣的可以了解一下
但是也有很多种工具集成的非常好
我个人认为
最好的方式是
fofa,hunter等引擎+oneforall+Layer子域名挖掘机
我认为这就完全足够了
OneForAll
https://github.com/shmilylty/OneForAll
解决大多传统子域名收集工具不够强大、不够友好、缺少维护和效率问题的痛点,是一款集百家之长,功能强大的全面快速子域收集终极神器。
Layer子域名挖掘机
https://github.com/euphrat1ca/LayerDomainFinder
Layer子域名挖掘机是一款子域名收集工具,拥有简洁的界面和简单的操作模式,支持服务接口查询和暴力枚举获取子域名信息,同时可以通过已获取的域名进行递归爆破。
3. IP信息收集
(1)绕过CDN
绕过CDN方式需要多种方式结合
检测
https://www.cdnplanet.com/tools/cdnfinder/
https://tools.ipip.net/cdn.php
https://whatsmycdn.com/
并且在反查IP时发现有很多不相关域名,这就是有CDN
nslookup查询域名,发现有多个响应IP
1. 多点ping
http://ping.chinaz.com/
https://ping.aizhan.com/
http://www.webkaka.com/Ping.aspx
https://www.host-tracker.com/v3/check/
一般来说,大多地方一样的是CDN,就那么一两个不一样的是真实IP,并且不同地区IP不一样基本可以判断存在CDN
但在国内不是特别适用,因为买了CDN的基本上买了全国CDN
2. DNS历史记录
可能有以前没买CDN的时候的DNS记录
https://dnsdb.io/zh-cn/
https://securitytrails.com/ //很好用,建议用这个
https://x.threatbook.cn/
http://toolbar.netcraft.com/site_report?url=
https://viewdns.info/iphistory/?domain=
https://site.ip138.com/www.xxx.com/
3. 利用引擎
各种测绘引擎里面可能有
几个重点的要素
ip
域名
title
l图标
备案号
body
js/css/html一些比较独特的信息,一般来说结合上面的要素一起搜索
4. 利用子域名
有可能子域名没买CDN
5. 国外ping
有可能国外没买,为了省钱
http://ping.chinaz.com/
https://asm.ca.com/zh_cn/ping.php
http://host-tracker.com/
http://www.webpagetest.org/
https://dnscheck.pingdom.com/
https://www.host-tracker.com/v3/check/
6. ssl证书
直接搜,可以看到有很多证书
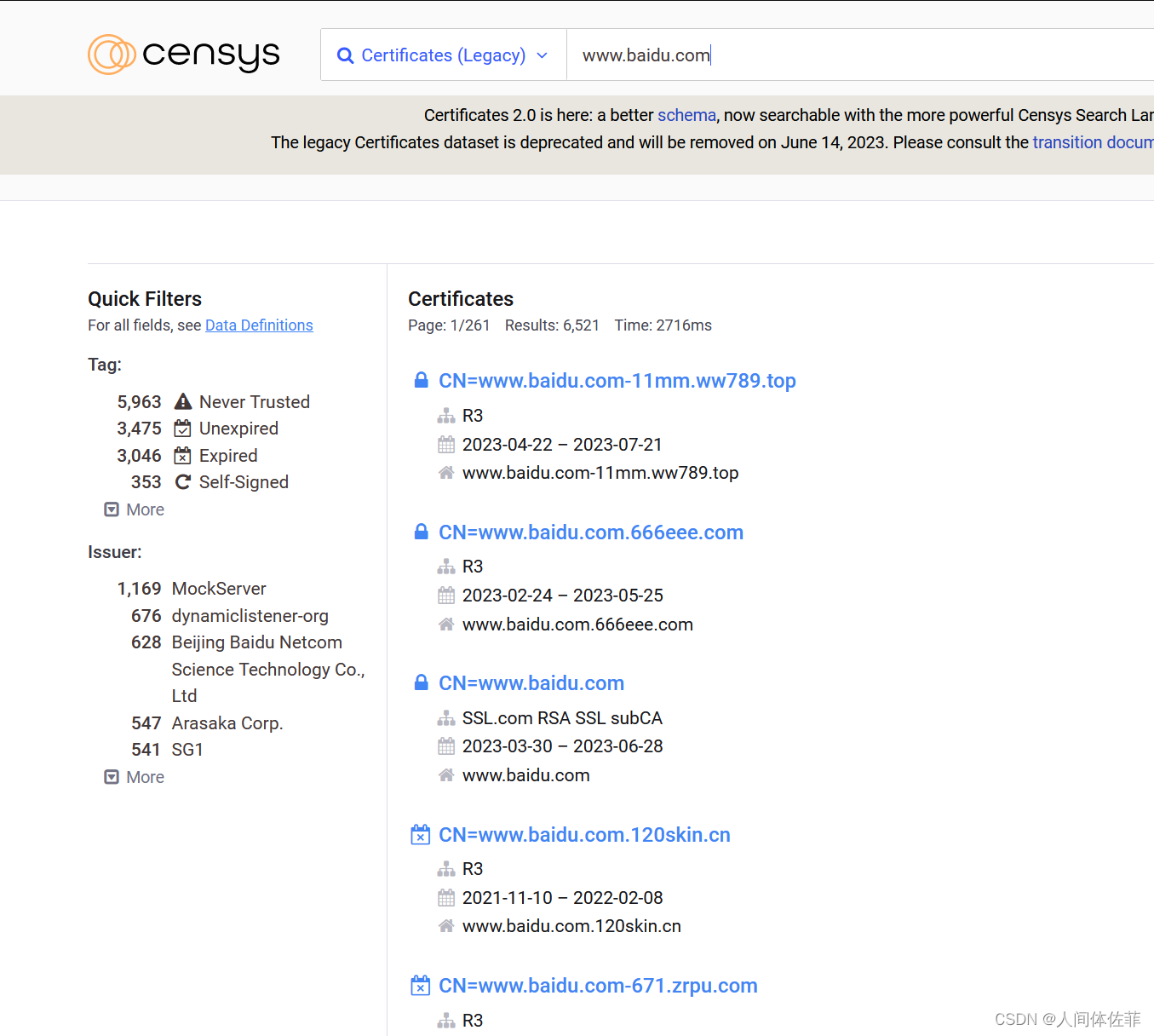 不过挺麻烦的
不过挺麻烦的
直接使用工具,这也是拿censys的API实现的,效果一样,省去了人工的繁琐
CloudFlair
项目地址:https://github.com/christophetd/CloudFlair
使用来自 Censys 的全网扫描数据查找 CloudFlare 背后网站的源服务器。
7. 敏感文件泄露
phpinfo之类的很多敏感文件或许可能会有真实IP的暴露
如下也是一些
服务器日志文件
探针文件,例如 phpinfo
网站备份压缩文件
.DS_Store
.hg
.git
SVN
Web.xml
8. CDN的错误配置
尝试检查baidu.com和www.baidu.com
http和https
因为有可能因为错误配置导致CDN服务的不全面
9. 漏洞
1. 网站本身存在一些漏洞时,如XSS/SSRF/XXE/命令执行/log4j等,通过带外服务器地址注入,使服务器主动连接,被动获取连接记录。
2. 部分本身功能,如url采集、远程url图片、编辑器问题等。
3. 异常信息、调式信息等都有可能泄露真实IP或内网ip的。
10.邮件服务器
现在基本上邮件服务器都是云服务商提供的,但不排除还有用自己的云服务器做的
大佬分享的奇淫技巧:通过发送邮件给一个不存在的邮箱地址,比如 000xxx@domain.com ,因为该用户不存在,所以发送将失败,并且还会收到一个包含发送该电子邮件给你的服务器的真实 IP 通知。
11.C段排除法
当你获得一个比如说自建的邮件服务器之后,你对他的整个C段进行判断,因为有可能你需要的真实IP就在C段的某一个IP
因为一个单位的机房啥的基本上都是同一个C段
12. vhost碰撞
不建议使用,太耗时了
在线工具:
https://pentest-tools.com/information-gathering/find-virtual-hosts#
13.APP
一些app、小程序会直接采用ip进行通信交互,也可以通过一些历史版本探测真实ip。
14.DOS
有些小公司买的额度CDN,或者一些那种站点用的免费的CDN
直接把流量打光
就是真实IP了
15.F5 LTM
LTM 是将所有的应用请求分配到多个节点服务器上。提高业务的处理能力,也就是负载均衡。F5 LTM也就是5公司旗下的一种负载均衡方案。
当服务器使用 F5 LTM 做负载均衡时,通过对 set-cookie 关键字的解码,可以获取服务器真实 ip 地址。
例如:基于cookie会话保持情况:
F5在获取到客户端第一次请求时,会使用set cookie头,给客户端标记一个特定的cookie。
Set-Cookie: BIGipServerPool-i-am-na_tcp443=2388933130.64288.0000; path=/;
后续客户端请求时,F5都会去校验cookie中得字段,判断交给那个服务器处理。那么就可以利用此机制,获取处理服务器的ip地址,大概率也是网站服务器真实ip。具体解法如下:
先把第一小节的十进制数,即 2388933130 取出来
将其转为十六进制数 8e643a0a
接着从后至前,取四个字节出来:0a.3a.64.8e
最后依次转为十进制数 10.58.100.142,即是服务器的真实ip地址。
一般来说基本都是内网ip,但也有例外,得看部署情况
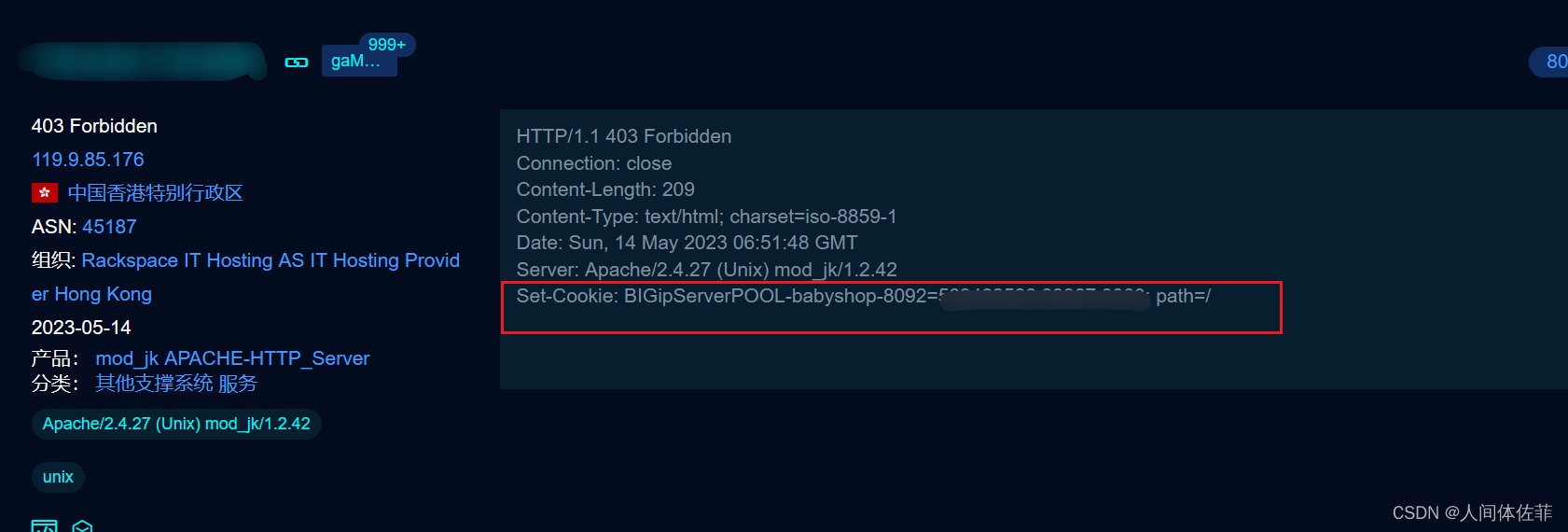
关键字是BIGipServerPOOL
自动化解码工具:
https://github.com/ezelf/f5_cookieLeaks
15.其他的小概率可能
网站响应包可能有
403绕过
当目标地址放在标头(如Location头)中时,可通过抓包将http协议改为1.0并将请求中除第一行外的所有数据删掉,再发送请求有机会再相应包中Location头获取到真实ip地址。
如何判断我们获得的是真实IP
浏览器搜索框直接view-source:[ip]
如果显示页面源码,就是真的,如果是CDN的页面,就是假的
4. 资产探活
当我们拿到一个真实IP以后,往往要对C段IP进行一下探测
探测尽可能多的资产,才有利于后期的渗透
扫C段有几个步骤,先探测IP存活,再探测服务
(1)探测IP存活
个人推荐用masscan去探测存活,发包少,其他的集成工具或多或少的太容易被监测
除非你是甲方,无脑上shuize ,arl,goby干就完了
网络空间搜索引擎(fofa、quake…)
在这一个环节引擎不太建议使用,因为时效性太差
msscan
https://github.com/robertdavidgraham/masscan
https://github.com/7dog7/masscan_to_nmap
nmap+msscan缝合怪
Goby
https://cn.gobies.org/
资产扫描利器,支持图像化、方便快捷、可自定义poc漏扫。
shuize
https://github.com/0x727/ShuiZe_0x727
信息收集一键化+漏洞检验
fscan
https://github.com/shadow1ng/fscan
ALLin
https://github.com/P1-Team/AlliN
(2)探测端口存活
这一块可以用nmap,masscan,arl之类的,因为都要发65535个包,一个屌样
单独扫,千万不要一开始就一把梭,把漏洞检测什么都带上
那绝壁GG
而且端口探测一定要挂代理池
除非你是甲方······
(3)探测服务
服务的探测一般要结合之前的ip对应端口,然后使用一些工具进行批量的探测,或者也可以使用集成的工具快捷的探测
比如ARL灯塔,我们可以装一些指纹增强包
这样我们在进行资产收集的时候就可以很好的知道他们运行了什么服务,利用了什么中间件等等,对一些OA,等易于攻击的系统就可以有个很好的了解
这一块没啥区别,主要在于指纹库
指纹库牛逼了啥都牛逼
工具的话
棱洞
https://github.com/EdgeSecurityTeam/EHole
但是最牛逼的还得是在线的
https://fp.shuziguanxing.com/#/
数字观星
但是不能批量
5. WAF探测
https://cloud.tencent.com/developer/article/1872310
这是waf图,可以根据图像知道是什么waf,也包括平时的积累
工具
https://github.com/EnableSecurity/wafw00f
https://github.com/Ekultek/WhatWaf
nmap的http-waf-fingerprint.nse脚本
但是工具对国内的效果不咋地
6.以上资产梳理
对前期收集到的大量资产域名、ip信息批量进行存活性、title、架构、服务等信息进行验证提取时,可以用一些自动化工具筛选出有价值的数据,从而提高漏洞发现效率。
Ehole
https://github.com/EdgeSecurityTeam/EHole
EHole是一款对资产中重点系统指纹识别的工具,在红队作战中,信息收集是必不可少的环节,如何才能从大量的资产中提取有用的系统(如OA、VPN、Weblogic...)。EHole旨在帮助红队人员在信息收集期间能够快速从C段、大量杂乱的资产中精准定位到易被攻击的系统,从而实施进一步攻击。
AlliN
https://github.com/P1-Team/AlliN
一个辅助平常渗透测试项目或者攻防项目快速打点的综合工具,由之前写的工具AG3改名而来。是一款轻便、小巧、快速、全面的扫描工具。多用于渗透前资产收集和渗透后内网横向渗透。工具从项目上迭代了一些懒人功能(比如提供扫描资产文件中,可以写绝大部分的各种形式的链接/CIDR,并在此基础上可以添加任意端口和路径)
Bufferfly
https://github.com/dr0op/bufferfly
攻防资产处理小工具,对攻防前的信息搜集到的大批量资产/域名进行存活检测、获取标题头、语料提取、常见web端口检测、简单中间识别,去重等,便于筛选有价值资产。
HKTools
https://github.com/Security-Magic-Weapon/HKTools
一款辅助安全研发在日常工作中渗透测试、安全研究、安全开发等工作的工具
EyeWitness
https://github.com/FortyNorthSecurity/EyeWitness
Eyewitness可自动查询URL对应网站的截图、RDP服务、Open VNC服务器以及一些服务器title、甚至是可识别的默认凭据等,最终会生成一个详细的html报告。
7. 敏感信息收集
敏感信息包括一些接口,页面源码中包含的js文件,url,包括一些没有正确配置所以在网站目录泄露出来的类似于robots.txt之类的文件
常见敏感目录及文件
备份文件:www.zip、www.rar、blog.gm7.org.zip等
代码仓库:.git、.svn等
敏感、隐藏api接口:/swagger-ui.html、/env等
站点配置文件:crossdomain.xml、sitemap.xml、security.txt等
robots文件
网站后台管理页面
文件上传/下载界面
现在越来越多的是api接口方面的攻击,非常多
这里推荐一个靶场
https://xz.aliyun.com/t/11734
工具
- dirsearch
dirsearch 是一款使用 python3 编写的,用于暴力破解目录的工具,速度不错,支持随机代理、内容过滤。 - feroxbuster
用Rust编写的快速,简单,递归的内容发现工具
这两个工具直接在kali安装就好
apt install xxx即可
- 御剑目录扫描专业版图形化,我喜欢用
https://github.com/foryujian/yjdirscan
字典
- fuzzDicts
https://github.com/TheKingOfDuck/fuzzDicts
庞大的Web Pentesting Fuzz 字典,部分精准度不错,可惜更新是2021的时候了。
Web-Fuzzing-Box
- Web Fuzzing Box
https://github.com/gh0stkey/Web-Fuzzing-Box
Web 模糊测试字典与一些Payloads,主要包含:弱口令暴力破解、目录以及文件枚举、Web漏洞…
- 以及一些你自己平时收集的字典
一篇好的文章
https://gh0st.cn/archives/2019-11-11/1
JS信息收集
js文件一般用于帮助网站执行某些功能,存储着客户端代码,可能会存在大量的敏感信息,通过阅读分析可能会找到宝藏。
JS信息查找方法
手工
通过查看页面源代码信息,找到.js后筛选特定信息,但这种方法费时费力,一般网站都会存在大量的js文件,还多数为混淆后的信息。
关键信息查找可以使用浏览器自带的全局搜索:
ctrl+f
半自动
通过抓包拦截获取url后使用脚本筛选,比如Burp Suite专业版,可以在Target > sitemap下,选中目标网站选中Engagement tools -> Find scripts,找到网站所有脚本内容。
也可以使用Copy links in selected items复制出选中脚本项目中所包含的URL链接。
粘贴下,然后就可以手工验证url信息价值,有时候可以发现一些未授权、敏感的api接口或者一些GitHub仓库、key值等。
这种方法因为结合手工,在一些深层目录架构中,通过Burp Suite script可以获取到一些工具跑不到的js信息。
工具
URLFinder
URLFinder是一款用于快速提取检测页面中JS与URL的工具。
功能类似于JSFinder,但JSFinder好久没更新了。
这一款足以,或者JSFINDER也OK
历史界面
https://archive.org/web/
wayback会记录网站版本更迭,可以获取到之前版本的网站,不仅可以用于收集历史js文件,也有可能找到一些后来删除的敏感资产信息,或者一些漏洞
历史信息查找工具:
waybackurls
获取 Wayback Machine 知道的域的所有 URL
收集历史js文件
webbackurls target.com | grep “.js” | uniq |sort
通过Wayback Machine收集到的url js列表需要进行存活检验,避免误报,可以使用curl命令或者hakcheckurl工具进行检验。最后在做url提取即可。
反混淆
对于存在混淆的代码需要进行反混淆美化下,使其更易看懂
js-beautify
这个小美化器将重新格式化和重新缩进书签、丑陋的 JavaScript、由 Dean Edward 的流行打包程序打包的解包脚本,以及由 npm 包 javascript-obfuscator处理的部分去混淆脚本。
8. github信息收集
高级搜索:https://github.com/search/advanced
Github高级搜索语法:https://docs.github.com/cn/search-github/getting-started-with-searching-on-github/understanding-the-search-syntax?spm=a2c6h.12873639.article-detail.6.55db74b8e8hJQq
语法简单看一下就行,这一块很多监控都搞起的
下面有一些常用的语法:
"token"
"password"
"secret"
"passwd"
"username"
"key"
"apidocs"
"appspot"
"auth"
"aws\_access"
"config"
"credentials"
"dbuser"
"ftp"
"login"
"mailchimp"
"mailgun"
"mysql"
"pass"
"pem private"
"prod"
"pwd"
"secure"
"ssh"
"staging"
"stg"
"stripe"
"swagger"
"testuser"
"jdbc"
extension:pem private
extension:ppk private
extension:sql mysql dump password
extension:json api.forecast.io
extension:json mongolab.com
extension:yaml mongolab.com
extension:ica \[WFClient\] Password\=
extension:avastlic “support.avast.com”
extension:js jsforce conn.login
extension:json googleusercontent client\_secret
“target.com” send\_keys
“target.com” password
“target.com” api\_key
“target.com” apikey
“target.com” jira\_password
“target.com” root\_password
“target.com” access\_token
“target.com” config
“target.com” client\_secret
“target.com” user auth
我这一块还在学习,目前只会使用一些工具,包括ARL的监控这些
等我整明白了再跟大家分享一下
这里有一些工具
收集工具
GitDorker
https://github.com/obheda12/GitDorker
GitDorker 是一款github自动信息收集工具,它利用 GitHub 搜索 API 和作者从各种来源编译的大量 GitHub dorks 列表,以提供给定搜索查询的 github 上存储的敏感信息的概述。
trufflehog
https://github.com/trufflesecurity/trufflehog
Truffle Hog是一款采用Python开发的工具,它可以检索GitHub代码库的所有代码提交记录以及分支,并搜索出可以表示密钥(例如AWS密钥)的高熵字符串。一般用来探测泄漏密钥的工具,支持扫描的数据源包括git、github、gitlab、S3、文件系统、文件和标准输入。



















 1727
1727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











