







一、进制
计算机中底层所有的数据都是以 010101 的形式存在(图片、文本、视频等)。
二进制
八进制
十进制(也就是我们熟知的阿拉伯数字)
十六进制
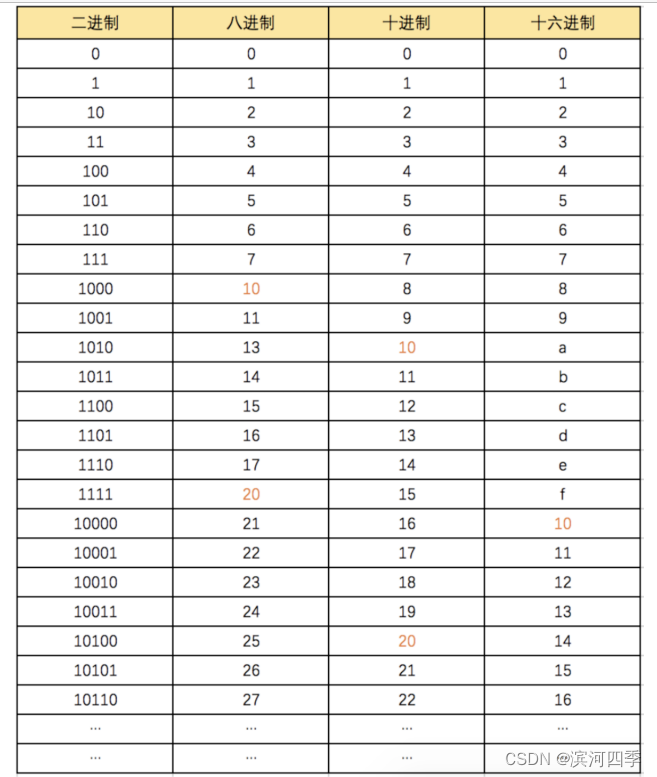
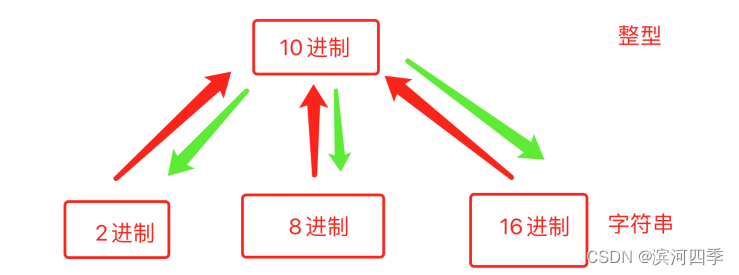
进制转换
v1 = bin(25) # 十进制转换为二进制
print(v1) # "0b11001"
v2 = oct(23) # 十进制转换为八进制
print(v2) # "0o27"
v3 = hex(28) # 十进制转换为十六进制
print(v3) # "0x1c"i1 = int("0b11001", base=2)
print(i1)
i2 = int("0o27", base=8) #
print(i2)
i3 = int("0x1c", base=16)
print(i3)
base代表着参照的进制 ,base>=2,(base也可取0,此时和base取10一样) 比如int ('20',8),代表的就是八进制的‘20’

二、计算机中的单位
由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
b(bit),位
1,1位
10,2位
111,3位
1001,4位
B(byte),字节
8位是一个字节。
10010110,1个字节
10010110 10010110,2个字节KB(kilobyte),千字节
1024个字节就是1个千字节。
10010110 11010110 10010111 .. ,1KB
1KB = 1024B= 1024 * 8 bM(Megabyte),兆
1024KB就是1M
1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 bG(Gigabyte),千兆
1024M就是1G
1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 *
1024 * 1024 * 8 bT(Terabyte),万亿字节
1024个G就是1T
...其他更大单位 PB/EB/ZB/YB/BB/NB/DB 不再赘述。
单位的转换
1 B(字节)= 8bit(比特位)
1 KB(千字节) = 1024 B(字节)
1 M(兆字节) = 1024KB(千字节)
1 G = 1024M
1 T = 1024G 三、编码
基本概念:
字符(Character)
在电脑和电信领域中,字符是一个信息单位,它是各种文字和符号的总称,包括各国家文字、标点符 号、图形符号、数字等。比如,一个汉字,一个英文字母,一个标点符号等都是一个字符。
字符集(Character set)
字符集是字符的集合。字符集的种类较多,每个字符集包含的字符个数也不同。比如,常见的字符集有ASCII 字符集、GB2312 字符集、Unicode 字符集等,其中,ASCII 字符集共有 128 个字符,包 含可显示字符(比如英文大小写字符、阿拉伯数字)和控制字符(比如空格键、回车键);GB2312 字 符集是中国国家标准的简体中文字符集,包含简化汉字、一般符号、数字等;Unicode 字符集则包含 了世界各国语言中使用到的所有字符
字符编码(Character encoding)
字符编码,是指对于字符集中的字符,将其编码为特定的二进制数,以便计算机处理。常见的字符编码 有 ASCII 编码,UTF-8 编码,GBK 编码等。一般而言,字符集和字符编码往往被认为是同义的概 念,比如,对于字符集 ASCII,它除了有「字符的集合」这层含义外,同时也包含了「编码」的含 义,也就是说,ASCII 既表示了字符集也表示了对应的字符编码。
总结:

Python相关的编码
v1 = "吕"
# 声明此字符串通过utf-8进行编码 utf-8常用汉字使用三个字节编码
v2 = "吕".encode("utf-8")
# 声明此此字符串通过gbk进行编码 gbk常用汉字使用两个字节编码
v3 = "吕".encode("gbk")
# 如果输出不进行解码,则输出对应编码的字符
print(v2)
print(v3)
# 只有通过对对应的字符编码过的字符进行同类型编码格式解码后,才可以看到原始字符串
print(v2.decode("utf-8"))
print(v3.decode("gbk"))
# 如果使用跟编码不同的类型编码方式进行解码的话,就会报错提示
# UnicodeDecodeError: 'gbk' codec can't decode byte 0x95 in position 2: incomplete multibyte sequence
v2 = "吕".encode("utf-8")
print(v2.decode("gbk"))
本章的知识点属于理解为主,了解这些基础之后有利于后面知识点的学习,接下来对
本节所有的知识点进行归纳总结:
计算机上所有的东西最终都会转换成为二进制再去运行。
ascii编码、unicode字符集、utf-8编码本质上都是字符与二进制的关系。
ascii,字符和二进制的对照表。
unicode,字符和二进制(码位)的对照表。
utf-8,对unicode字符集的码位进行压缩处理,间接也维护了字符和二进制的对照表。
ucs2和ucs4指的是使用多少个字节来表示unicode字符集的码位。
目前最广泛的编码为:utf-8,他可以表示所有的字符且存储或网络传输也不会浪费资源(对码位进行压缩了)。
二进制、八进制、十进制、十六进制其实就是进位的时机不同。
基于Python实现二进制、八进制、十进制、十六进制之间的转换。
一个字节8位
计算机中常见单位b/B/KB/M/G的关系。
汉字,用gbk编码需要用2个字节;用utf-8编码需要用3个字节。
基于Python实现将字符串转换为字节(utf-8编码)
# 字符串类型
name = "小胖"
print(name) # 小胖
# 字符串转换为字节类型
data = name.encode("utf-8")
print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90'
# 把字节转换为字符串
old = data.decode("utf-8")
print(old)基于Python实现将字符串转换为字节(gbk编码)
# 字符串类型
name = "小胖"
print(name) # 小胖
# 字符串转换为字节类型
data = name.encode("gbk")
# print(data) # b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90'
utf8,中文3个字节
print(data) # b'\xce\xe4\xc5\xe6\xc6\xeb' gbk,中
文2个字节
# 把字节转换为字符串
old = data.decode("gbk")
print(old)
四、数据类型(上)
接下来的课程都是来讲解数据类型的知识点,常见的数据类型:
int,整数类型(整形)
bool,布尔类型
str,字符串类型
list,列表类型
tuple,元组类型
dict,字典类型
set,集合类型
float,浮点类型(浮点型)
长整型
Python3:整型(无限制)
Python2:整型、长整形
在python2中跟整数相关的数据类型有两种:int(型)、long(长整型),他们都是整数只不过能表示的值范围不同。
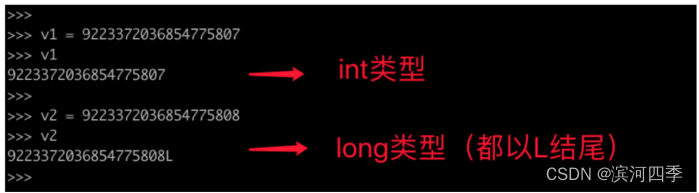
int,可表示的范围:-9223372036854775808~9223372036854775807
long,整数值超出int范围之后自动会转换为long类型(无限制).
在python3中去除了long只剩下:int(整型),并且 int 长度不在限制。
字符串类型
字符串的功能方法
name = "Hello,welcome to python"
# 正向对应下标 012345678910..."(从左到右,索引值从0开始)
# 负向对应下标 ...-4-3-2-1 (从右到左,索引值从-1开始)
# index()方法返回子字符串在字符串中的对应索引 如果这个字符或字符串出现多次,则只返回第一次出现的索引值
print(name.index('H'))
# 字符串是一个序列 也就是说字符串是按照从左至右的顺序排列的 字符串的索引是从0开始
print(name.index('e'))
索引
正向索引表示,索引值从0开始,从左至右依次递增
负向索引表示,索引值从-1开始,从右至左依次递减
step大于零,表示从左往右读取;step小于零表,示从右向左读取:
name = 'ABCDEFGHIJKLMN'
print(name[-1:-7]) #这里拿不到值 因为步长step是1,代表正向去读取索引name[-1:] & name[:-7]的交集,刚好为空,所以拿不到值;
你也可以这么理解,你正向取的,只能正向读;你负向取的,只能负向读;不能正向取了负向读,这是不行的,也不能负向取了正向读;
想要拿到值就要让step小于1,或者再负向输出一次
print(name[-1:-7:-1])
字符串切片
字符串切片var[start_index:end_index:step] 如果省略end_index和step,则默认截取到整个字符串的末尾,
另外如果指定了截止索引(end_index),则这个截止索引是拿不到的,也就是说切片的索引使用是左包右不包
name2 = 'ABCDEFGH'
print(name2[0:4:1])
print(name2[0:4:2])

step指定间隔索引的长度
step表示每一个都取,step为2,表示隔一个取一个,隔一个取一个
name = "Hello,welcome to python"
print(name[0:4])
print(name[0:5])
从左开始,H的索引值是0,e的索引值是1,第一个l的索引值是2,第二个l的索引值是3,o的索引值是4,但是因为他是左包右不包的,所以你如果写成[0:4]的话,他是取不到o的,所以他要给截止索引值加一,相当于是[0:5],这样才可以取到完整的Hello
name = 'ABCDEFGHHIJKLMN'
# 也可以指定起始索引
print(name[2:6])
# 同理也可以省略起始索引,省略起始索引相当于从0开始
print(name[:5])
# 也可以起始索引跟截止索引都省略,代表输出整个字符串,跟直接输出字符串效果一样
print(name[:])
print(name)
count()方法
# count()方法用来去做字符或者字符串出现次数的一个统计
my_string = "China is a country!"
print(my_string.count('i'))
print(my_string.count('a'))
print(my_string.count('a', 0, 5)) #指定在索引值范围为0~5中统计字符a出现的次数
find()方法
my_string = "China is a country!"
# find()方法用来去查询子字符串在某字符串中出现的第一次的索引位置
print(my_string.find('a', 0, 12))和index()方法英语只查询子字符在某字符第一次出现位置的索引值
replace()方法
my_string = "China is a country!"
# replace()函数可以用来去做子字符串的一个替换 常用
print(my_string.replace('China', 'USA'))
split()方法
# split()方法可以实现按照分隔符去进行切分字符串,并生成对应的列表 默认分隔符为空格 也可以自己指定分隔符
print(my_string.split())
print(my_string.split('a'))
join()方法
# join()方法用来把列表或者其他序列拼接起来
print('='.join(['hello', 'world']))
print('='.join(['hello''world']))
print('-'.join('nihao'))如果想指定拼接符,必须使用,隔开,否则没有效果

strip()方法
# strip()方法去除字符串两边的空白;lstrip()去除左边空白 rstrip()去除右边的空白
new_string = ' This a test string '
print(new_string.strip())
print(new_string.lstrip())
print(new_string.rstrip())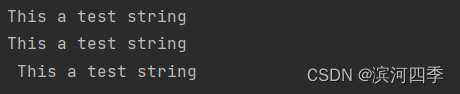
isalpha()方法
# isalpha()方法用来判断是否为纯字母
my_name = 'nebula'
print(my_name.isalpha())
my_name1 = 'nebula1'
print(my_name1.isalpha())
isdigit()方法
# isdigit()方法用来判断是否为纯数字
my_name = 'nebula'
print(my_name.isdigit())
isdecimal()方法
# isdecimal()判断这个字符串是否是十进制的数字 不常用
print('11'.isdecimal())
istitle()方法
# istitle()方法代表判断这个字符串是否是英文的标题 也就是说每个单词首字母大写 不常用
print('Hello World'.istitle())
print('Hello world'.istitle())
print('Hello1 World'.istitle())
print('1Hello World'.istitle())
注意不能整个字符串都为大写字母,否则输出False
isspace()方法
# isspace()方法用来判断是否是空白
print(' asdf'.isspace())
print(' '.isspace())
isnumberic()方法
# isnumberic()方法用来判断是否为数字化的字符串 跟isdigit等效 不常用
print('1234565'.isnumeric())
print('12sd333'.isnumeric())
print('1.2'.isnumeric())
只能为整数,如果有小数,输出False
isalnum()方法
# isalnum()方法用来判断是否为字母跟数字的组合
print('123sdf'.isalnum())
print('123,abcsd'.isalnum())
islower()方法
# islower()方法用来判断是否为纯小写
print('lower'.islower())
print('Lower'.islower())
isupper()方
# isupper()方法用来判断是否为纯大写
print('UPPER'.isupper())startswith()方法
# startswith()方法用来判断字符串是否以某个字符开头
print('Abcd'.startswith('A'))
print('Abcd'.startswith('b'))
endswith()方法
# endswith()方法用来判断字符串是否以某个字符结尾
print('abctxt'.endswith('txt'))
upper()方法
# upper()方法用来转化字母为大写 lower()方法用来转化字母为小写
print('lower'.upper().lower())
removesuffix()方法
# removesuffix()方法是移除字符串的后缀
print('testtxt'.removesuffix('txt'))
removeprefix()方法
# removeprefix()方法是移除字符串的前缀
print('text.txt'.removeprefix('text'))capitalize()方法
# capitalize()方法实现将字符串首字母转化成大写 不常用
print('this is a page'.capitalize())
zfill()方法
# zfill用来指定特定的长度,当字符串长度不够时,使用0在字符串左侧进行填充补齐长度 不常用
print('hello'.zfill(10))
casefold()方法
# casefold()方法返回适合无大小写比较的字符串版本。 等同于lower()方法 不常用
print('AbcD'.casefold())
partition()方法
# partition()方法实现将按照指定的字符串的分隔符进行分割字符串,生成一个三个部分元组,类似于split() 不常用
print('Hello my world hhh'.partition(' '))
print('Hello,my world hhh'.partition('H'))
splitlines()方法
# splitlines()方法可以实现将字符串按照换行符进行切割,生成多个元素组成的一个列表
poem = """春眠不觉晓,
处处闻啼鸟,
夜来风雨声,
花落知多少。
"""
print(poem.splitlines())
swapcase()方法
# # swapcase()方法是交换大小写 不常用
# print('AbCdef'.swapcase())
















 5149
5149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











