






1.用到的数据结构
1.8之前采用数组+链表。
1.8采用数组+链表+红黑树。
2.有参和无参构造的区别
HashMap默认提供的变量。
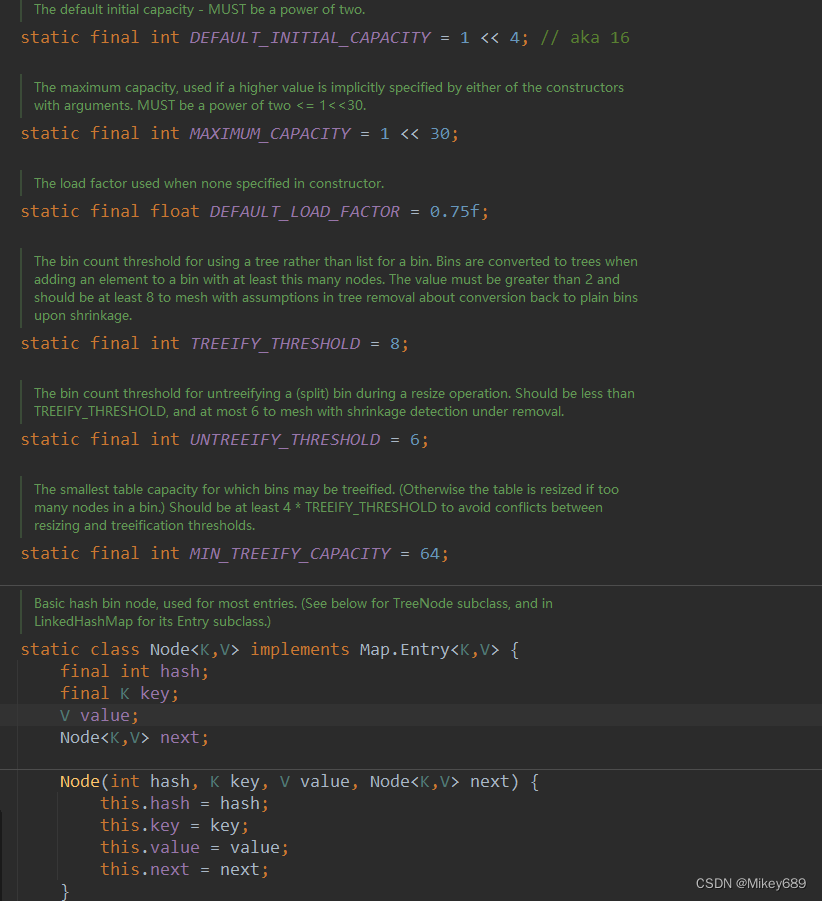
无参构造,给加载因子赋值。

有参构造的核心主要是tableSizeFor这个方法。


这个算法的目的主要是,将传进来的参数转换成2的倍数,把每个2进制的位置都变成1,然后再+1,我们看看具体过程。
假设传进来的容量是17,就会经过以下的转换,最后变成2的倍数-1,然后最后再+1就变成了32,就实现了最终的目的。

3.HashMap的put原理
put大概流程图。

4.HashMap的hash算法。
核心代码,HashMap的哈希函数,先算出key的哈希值,然后让哈希值的高16位与低16位进行异或操作,主要是为了降低哈希碰撞。核心就是,将高位的信息掺杂在低位上,增大低位的随机性。

5.HashMap的容量是2的倍数呢?
我们知道hashmap中获取下标是(n - 1) & hash。
容量是2的倍数,说明二进制只有一个1,然后-1之后,就全是1了。然后再通过&运算就可以拿到低位的数据,从而拿到下标,并且位运算是比%运算快的。
6.HashMap的扩容机制。
在初始化的时候或者是大于threshold会触发扩容机制。
我们通过源码进行剖析。
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {//初始化过了,map里面存在值
if (oldCap >= MAXIMUM_CAPACITY) {//容量已经最大,无法扩容
threshold = Integer.MAX_VALUE;
return oldTab;
}
//1.将旧值容量进行左移一位
//2.与最大容器和默认容量进行对比。
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
//有参构造,指定了容量大小。
else if (oldThr > 0)
newCap = oldThr;
else {
//无参构造,这里是一开始扩容的判断,newCap = 16, newThr = 16 * 0.75
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {//上述方法走完,如果没有阈值没有被赋值,就会执行下面的操作。
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
}我们再来看看数组迁移的过程。
核心部分主要是:
1.第一个判断如果数组不存在链表或者树节点,直接进行赋值。
2.第二个判断是红黑树的迁移,这部分有时间深入一下。
3.第三部分就是链表的迁移,比较重要的一点。
这里主要是(e.hash & oldCap) == 0这个判断,到底是什么意思?
这个条件的判断是为了确定元素在新的数组中的位置。具体来说,e.hash & oldCap操作可以简单地将元素的哈希值的低位和旧容量进行位与运算,以便确定元素在新数组中的索引位置。
如果结果为0,这意味着元素在旧数组的索引位置上的哈希值的低位不变(因为位与操作的结果是0),也就是说,元素在新数组中的索引位置与旧数组中的索引位置在哈希值的低位上是相同的,所以元素在新数组中的索引位置仍然不需要改变,可以直接放在原有位置上。
这个操作的核心思想是尽可能地保持元素在扩容后的数组中的相对位置不变,以减少元素的重新散列次数,提高性能。
如果不等于0,就会进行放到newTab[j + oldCap]这个位置。
为什么是j + oldCap,因为容量是2的倍数,新的容量的二进制比旧容量的二进制高位多了1,所以是j + oldCap。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
//01 没有形式链表获树节点
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
//02 红黑树分割
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // 03 分割成两个链表。
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) { //原位置
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {//新位置
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}参考:















 43万+
43万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











