






Hive表操作
Hive乱码解决
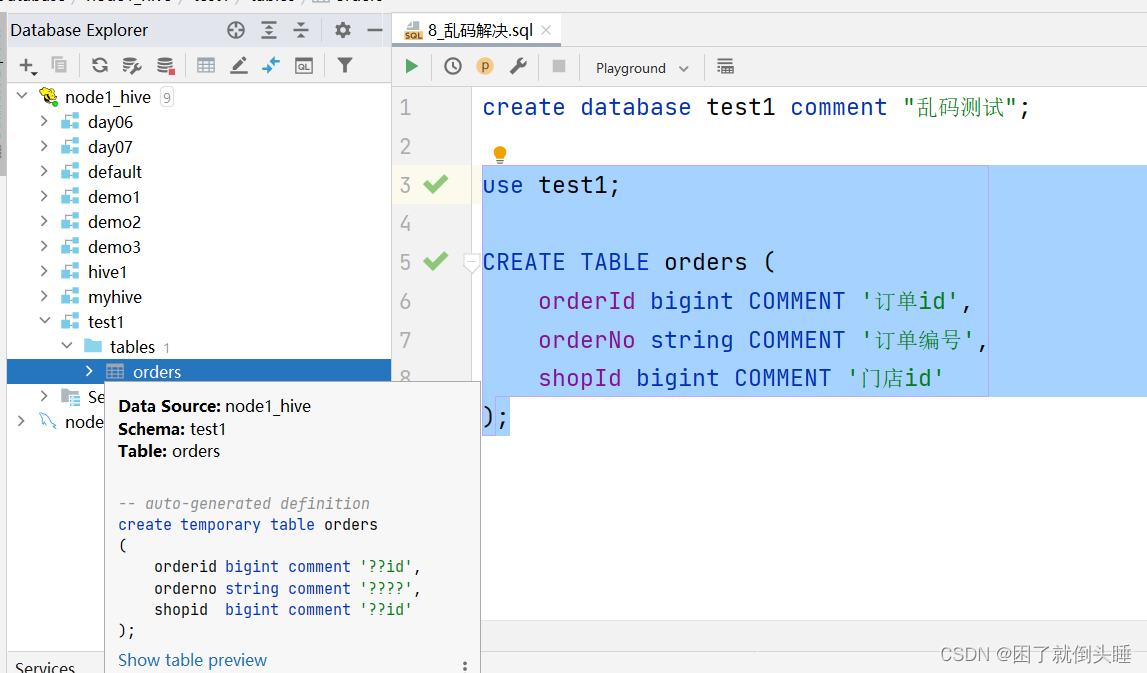
1、乱码现象
create database test1 comment "乱码测试";
use test1;
CREATE TABLE orders (
orderId bigint COMMENT '订单id',
orderNo string COMMENT '订单编号',
shopId bigint COMMENT '门店id'
);
2、处理步骤
-
注意:推荐先将node1虚拟机拍一个快照,拍完后再修改。
-
在node1上修改hive配置文件
文件路径: /export/server/hive/conf/hive-site.xml
修改内容:&useUnicode=true&characterEncoding=UTF-8
修改截图:

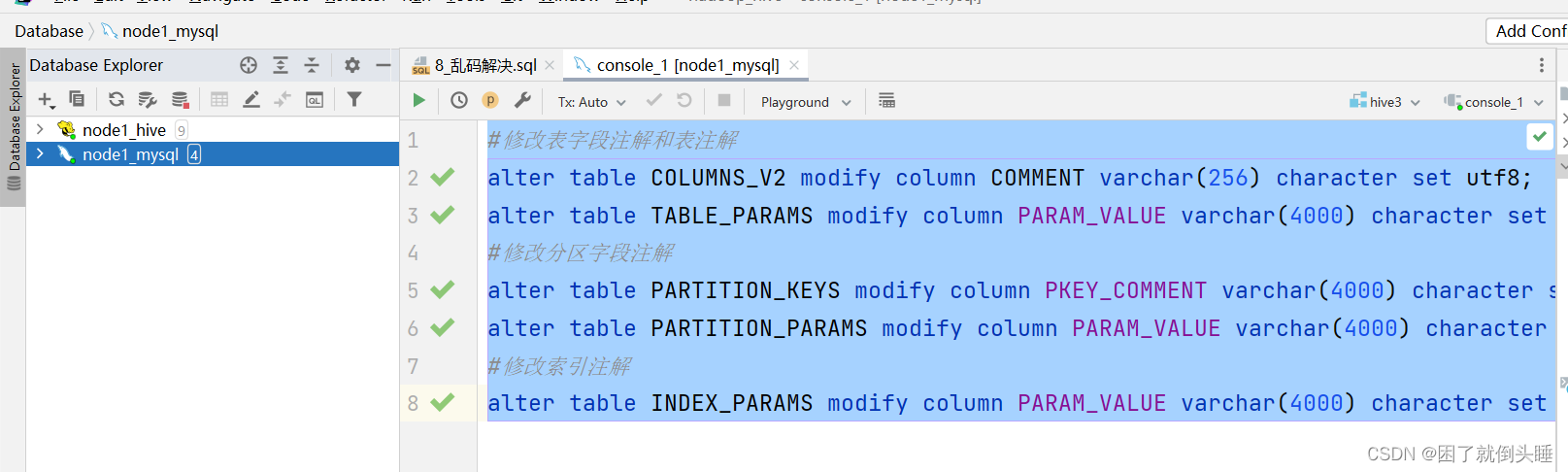
修改MySQL表:注意,下面的SQL语句,要在node1的MySQL上运行
use hive3;
#修改表字段注解和表注解
alter table DBS modify column `DESC` varchar(256) character set utf8;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改分区字段注解
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
-
重启Hive的metastore进程
先通过kill -9 杀死metastore进程。然后再通过 nohup hive --service metastore & 重启
-
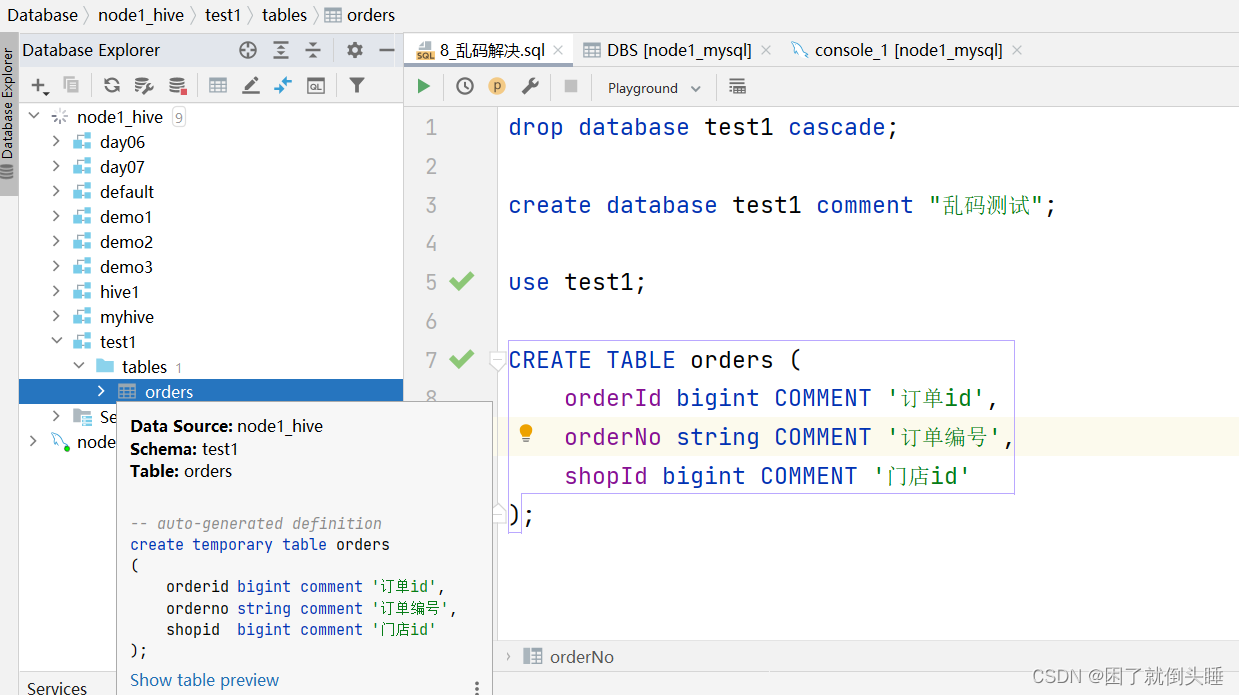
验证
drop database test1 cascade;
create database test1 comment "乱码测试";
use test1;
CREATE TABLE orders (
orderId bigint COMMENT '订单id',
orderNo string COMMENT '订单编号',
shopId bigint COMMENT '门店id'
);
建表语法
create [external] table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型 , ... )
[partitioned by (分区字段名 分区字段类型)] # 分区表固定格式
[clustered by (分桶字段名) into 桶个数 buckets] # 分桶表固定格式 注意: 可以排序[sorted by (排序字段名 asc|desc)]
[row format delimited fields terminated by '字段分隔符'] # 自定义字段分隔符固定格式
[stored as textfile] # 默认即可
[location 'hdfs://node1.itcast.cn:8020/user/hive/warehouse/库名.db/表名'] # 默认即可
; # 注意: 最后一定加分号结尾
注意:
1- 关键字顺序是从上到下从左到右,否则报错
2- 关键字不区分大小写。也就是例如create可以大写也可以小写
数据类型
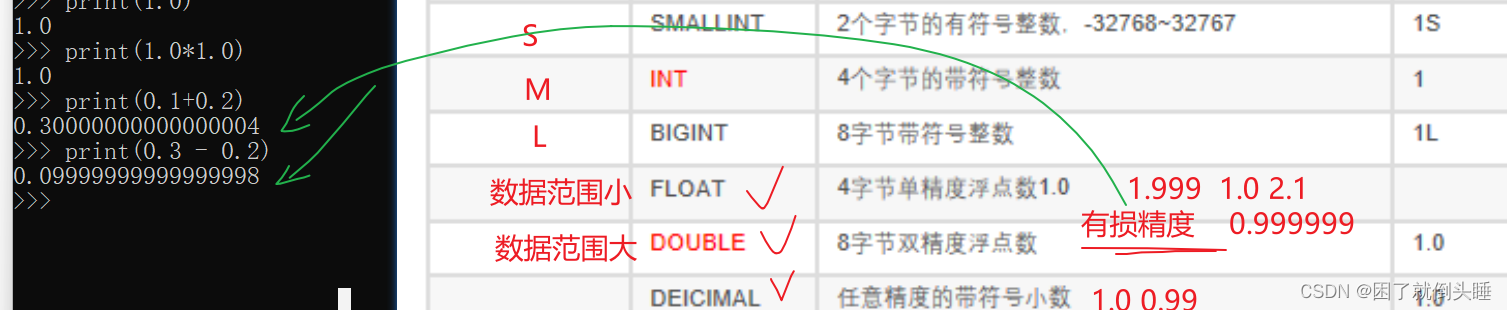
1、基本数据类型
整数: int
小数: float double
字符串: string varchar(长度)
日期: date timestamp
补充: timestamp时间戳,指的是从1970-01-01 00:00:00 到现在的时间的差值。
2、复杂数据类型
集合: array
映射: map
结构体: struct
联合体: union
表分类
Hive中可以创建的表有好几种类型, 分别是:
内部表(管理表): MANAGED_TABLE
分区表
分桶表
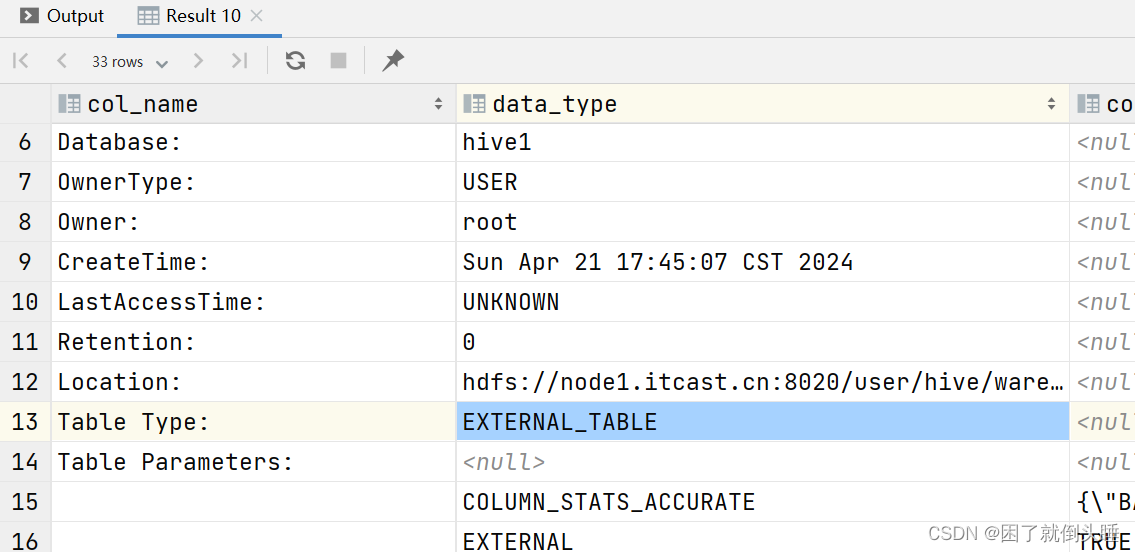
外部表(非管理表): EXTERNAL_TABLE
分区表
分桶表
default默认库存储路径: hdfs://node1:8020/user/hive/warehouse
自定义库在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db
自定义表在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db/表名称
业务数据文件在HDFS的默认存储路径: hdfs://node1:8020/user/hive/warehouse/数据库名称.db/表名称/业务数据文件
内部表和外部表区别?
内部表: 创建的时候没有external关键字,默认创建的就是内部表,也称之为普通表/管理表/托管表
删除内部表: 同时会删除MySQL中的元数据信息,还会删除HDFS上的业务数据
外部表: 创建的时候有external关键字,创建的就是外部表,也称之为非托管表/非管理表/关联表
删除外部表: 只会删除MySQL中的元数据信息,不会删除HDFS上的业务数据
-- 创建内部表 -- 注意事项: use hive1; create table stu1( id int, name string ); create table stu2( id int, name string ); -- 创建外部表 create external table stu3( id int, name string ); -- 查看表结构 desc stu1; desc stu3; -- 查看表格式化的信息 desc formatted stu1; desc formatted stu3; -- 添加数据到表里面 insert into stu1 values(1,'zhangsan'); insert into stu3 values(1,'zhangsan'); -- 删除表 drop table stu1; -- 内部表 drop table stu3; -- 外部表
删除内部表和外部表前后元数据信息的变化
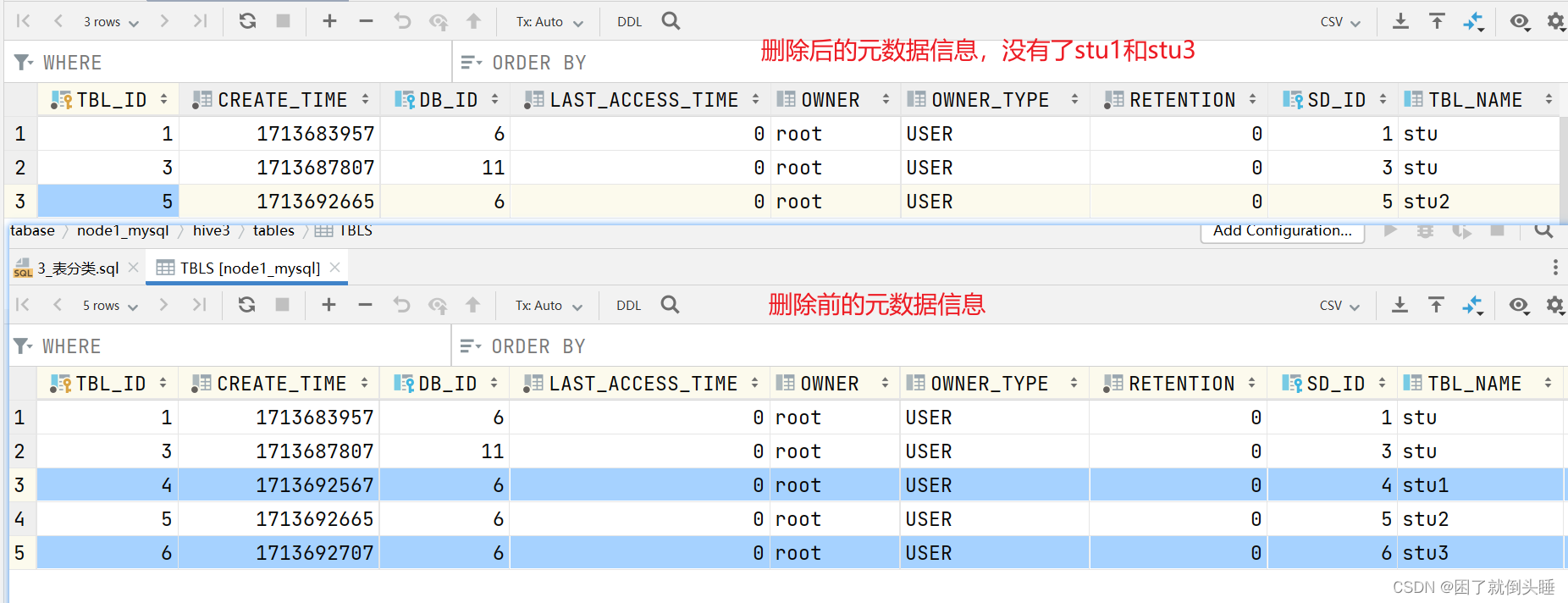
内部表信息:
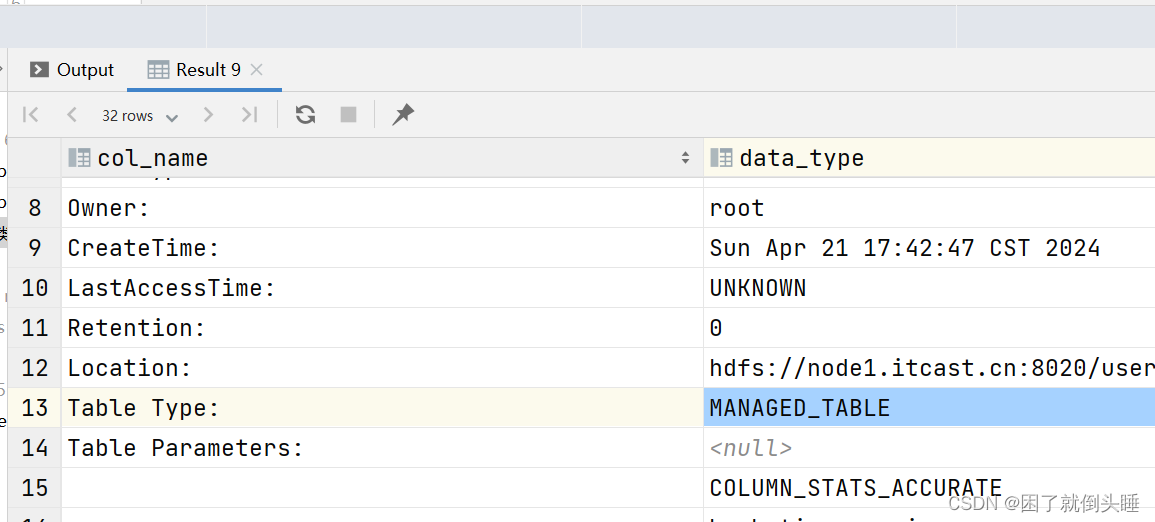
外部表信息:
Hive建表的时候可能遇到的错误:
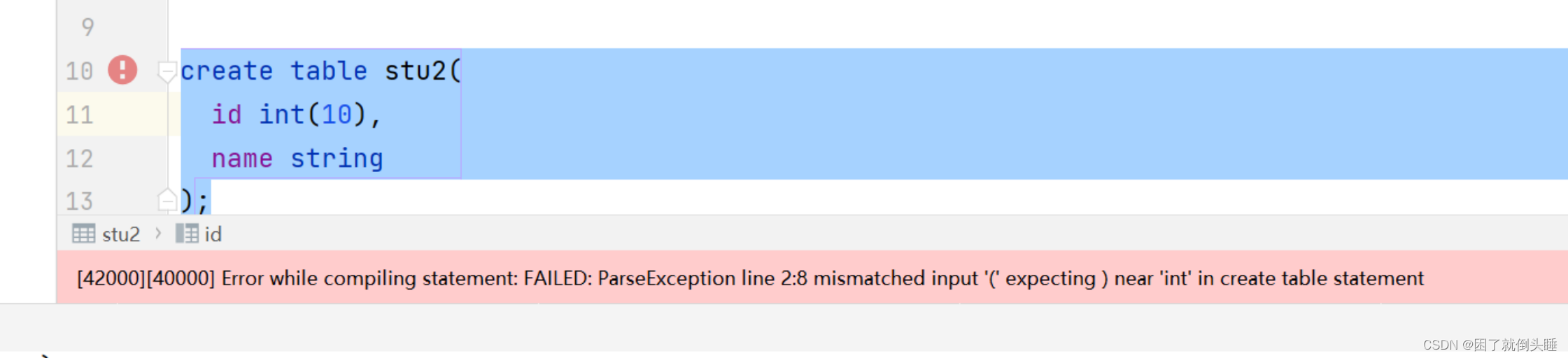
原因: 在Hive中int数据类型,不能指定长度
默认分隔符
创建表的时候,如果不指定分隔符,以后表只能识别默认的分隔符,键盘不好打印,展示形式一般为:\0001,SOH,^A,□
Hive表的默认分隔符\001
示例:
-- 默认分隔符: 创建表的时候不指定就代表使用默认分隔符 -- 1.创建表 create table stu( id int, name string ); -- insert方式插入数据,会自动使用默认分隔符把数据连接起来 -- 2.插入数据 insert into stu values(1,'zhangsan'); -- 3.验证数据 select * from stu; -- 当然也可以通过在hdfs中查看,默认分隔符是\0001,其他工具中也会展示为SOH,^A,□
内部表
创建普通内部表: create table [if not exists] 表名(字段名 字段类型 , 字段名 字段类型...) [row format delimited fields terminated by '指定分隔符']; 删除内部表: drop table 内部表名; 注意: 删除mysql中元数据同时也会删除hdfs中存储数据 修改表名: alter table 旧表名 rename to 新表名; 修改表字段名称和类型: alter table 表名 change 旧字段名 新字段名 新字段类型; 修改表之添加字段(列): alter table 表名 add columns (字段名 字段类型); 修改表之替换字段(列):alter table 表名 replace columns (字段名 字段类型); 查看所有表: show tables; 查看指定表基本信息: desc 表名; 查看指定表扩展信息: desc extended 表名; 查看指定表格式信息: desc formatted 表名; 查看指定表建表语句: show create table 表名;
示例:
-- 内部表的操作 -- 创建和使用数据库 create database myhive; use myhive; -- 创建内部表 create table if not exists stu( id int, name string ); -- 插入数据 insert into stu values(1,'张三'); -- 查询表数据 -- 下面语句被Hive进行了优化,不会变成MapReduce select * from stu; -- 这个会变成MapReduce select name,count(1) from stu group by name; -- 建表的时候指定字段间的分隔符 create table if not exists stu1( id int, name string ) row format delimited fields terminated by ','; insert into stu1 values(1,'张三'); -- 创建表的其他方式 -- 创建stu2表的时候,复制stu1的表结构,并且将select的查询结果插入到stu2的表的里面去 -- 注意不会复制原表的分隔符,新表用的还是默认 create table stu2 as select * from stu1; select * from stu2; -- 该方式只会复制stu1表的结构,没有数据。 create table stu3 like stu1; select * from stu3; -- 查询表信息 -- 查看当前数据库中的所有表 show tables; -- 查询表的基本信息 desc stu3; -- 查看表的扩展信息 desc extended stu3; desc formatted stu3; -- 查看指定表的建表语句 show create table stu3; -- 删除表 drop table stu; -- 清空表数据。需要保留表结构,但是不想要数据 select * from stu1; truncate table stu1; select * from stu1;
外部表
创建外部表: create external table [if not exists] 外部表名(字段名 字段类型 , 字段名 字段类型 , ... )[row format delimited fields terminated by '字段分隔符'] ;
复制表: 方式1: like方式复制表结构 注意: as方式不可以使用
删除外部表: drop table 外部表名;
注意: 删除外部表效果是mysql中元数据被删除,但是存储在hdfs中的业务数据本身被保留
查看表格式化信息: desc formatted 表名; -- 外部表类型: EXTERNAL_TABLE
注意: 外部表不能使用truncate清空数据本身
总结: 外部表对HDFS上的业务数据的管理权限并不高,drop表不会删除业务数据,同时不能使用truncate和delete来删除表数据。我们可以通过HDFS的shell来删除业务数据
示例:
-- 创建数据库 create database if not exists day06; -- 使用数据库 use day06; -- 创建外部表 create external table outer_stu1( id int, name string ); -- 添加数据 insert into outer_stu1 values (1,'zhangshan'); -- Hive底层对部分SQL语句进行了优化,不会变成MapReduce select * from outer_stu1; -- 创建外部表的方式2 -- 注意: 不管是什么方式创建外部表,一定要加上external关键字 create external table outer_stu2 like outer_stu1; desc formatted outer_stu2; -- 大小写转换快捷键: ctrl+shift+U create EXTERNAL table outer_stu3 like outer_stu1; desc formatted outer_stu3; -- 这种方式创建的还是内部表 create table stu2 like outer_stu1; -- 查看表的详细信息 desc formatted stu2; -- 创建外部表的方式3 -- 注意: 针对外部表,不能使用create external table 外部表名 as select 来创建 create external table outer_stu4 as select * from outer_stu1; -- 删除表 -- 该表的数据存放路径 hdfs://node1:8020/user/hive/warehouse/day06.db/outer_stu1 -- HDFS的路径中为什么是node1,因为namenode运行在node1上面 drop table outer_stu1; -- 清空表 insert into outer_stu3 values (1,'zhangshan'); select * from outer_stu3; -- truncate table outer_stu3; delete from outer_stu3; update outer_stu3 set name='wangwu'; select * from outer_stu3; -- 创建数据库 create database if not exists day06; -- 使用数据库 use day06; -- 创建外部表 create external table outer_stu1( id int, name string ); -- 添加数据 insert into outer_stu1 values (1,'zhangshan'); -- Hive底层对部分SQL语句进行了优化,不会变成MapReduce select * from outer_stu1; -- 创建外部表的方式2 -- 注意: 不管是什么方式创建外部表,一定要加上external关键字 create external table outer_stu2 like outer_stu1; desc formatted outer_stu2; -- 大小写转换快捷键: ctrl+shift+U create EXTERNAL table outer_stu3 like outer_stu1; desc formatted outer_stu3; -- 这种方式创建的还是内部表 create table stu2 like outer_stu1; -- 查看表的详细信息 desc formatted stu2; -- 创建外部表的方式3 -- 注意: 针对外部表,不能使用create external table 外部表名 as select 来创建 create external table outer_stu4 as select * from outer_stu1; -- 删除表 -- 该表的数据存放路径 hdfs://node1:8020/user/hive/warehouse/day06.db/outer_stu1 -- HDFS的路径中为什么是node1,因为namenode运行在node1上面 drop table outer_stu1; -- 清空表 insert into outer_stu3 values (1,'zhangshan'); select * from outer_stu3; -- truncate table outer_stu3; delete from outer_stu3; update outer_stu3 set name='wangwu'; select * from outer_stu3;
快速创建外部表不支持的操作:
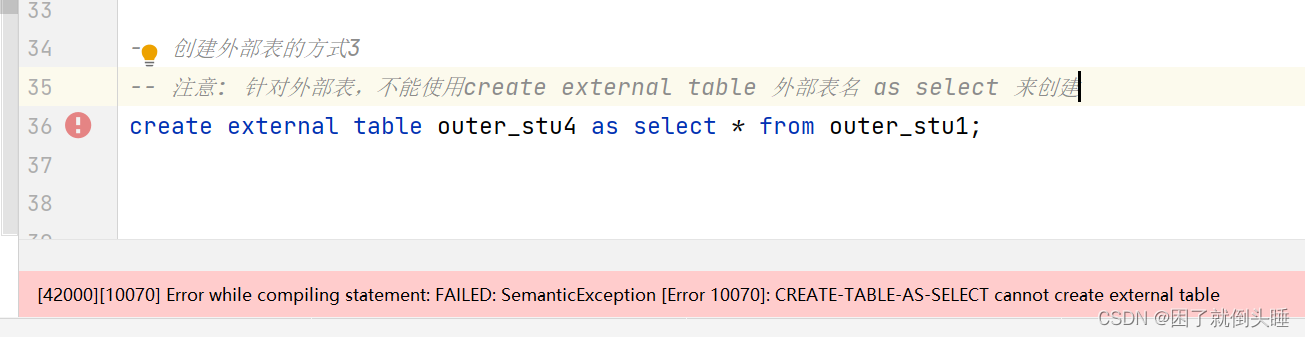
注意: 针对外部表,不能使用create external table 外部表名 as select 来创建
清空外部表的时候遇到的错误:
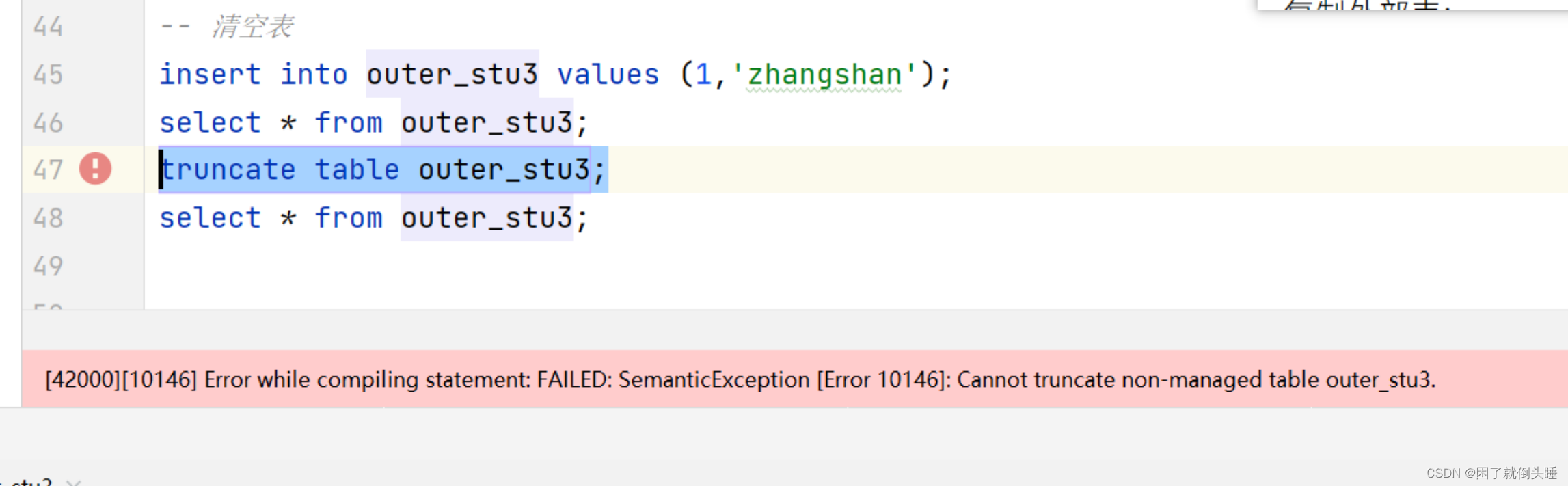
原因: 不能使用truncate语句来清空外部表
解决办法: 可以使用delete from 外部表名称。但是有前提条件,需要开启表对事务的支持
如果执行delete会报如下错误:
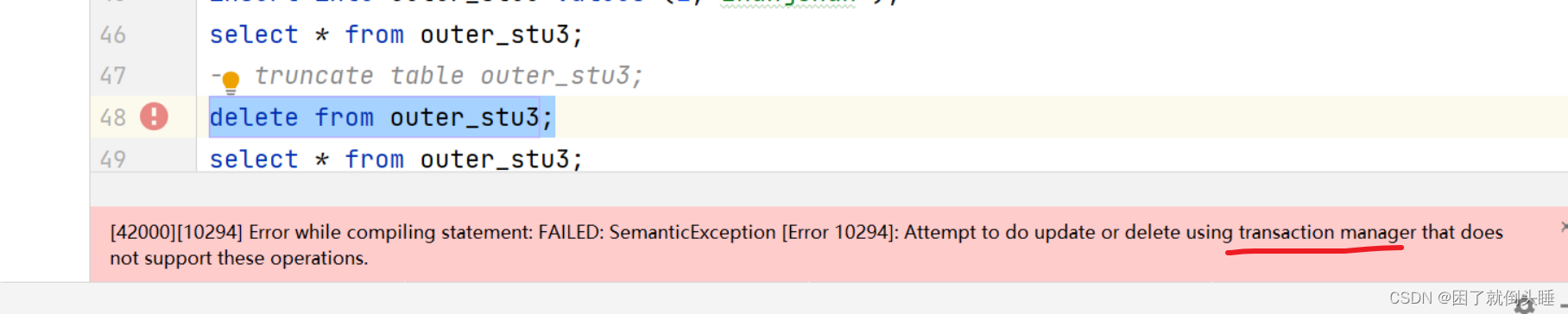
原因: 对表数据使用delete进行删除的时候,需要先开启事务
注意: 默认不会去开启Hive对事务的支持,事务开启后比较消耗性能。https://cwiki.apache.org/confluence/display/Hive/Hive+Transactions

查看和修改表
查看所有表: show tables;
查看建表语句: show create table 表名;
查看表信息: desc 表名;
查看表结构信息: desc 表名;
查看表格式化信息: desc formatted 表名; 注意: formatted能够展示详细信息
修改表名: alter table 旧表名 rename to 新表名
字段的添加: alter table 表名 add columns (字段名 字段类型);
字段的替换: alter table 表名 replace columns (字段名 字段类型 , ...);
替换的时候注意: 替换的时候,是使用新的字段信息替换原有的所有字段。也就是如果某些字段不想变化,你也需要把它写到替换的信息后面。
字段名和字段类型同时修改: alter table 表名 change 旧字段名 新字段名 新字段类型;
注意: 字符串类型不能直接改数值类型,这句话是有方向的。也就是字符串不能随便变成数值,但是数值可以变成字符串。举例:"hello world"变成数值的时候,Hive内部是不知道它对应的数值是多少;123 可以变成 "123"字符串
修改表路径: alter table 表名 set location 'hdfs中存储路径';
注意: 建议使用默认路径
location: 建表的时候不写有默认路径/user/hive/warehouse/库名.db/表名,当然建表的时候也可以直接指定路径
修改表属性: alter table 表名 set tblproperties ('属性名'='属性值'); 注意: 经常用于内外部表切换
内外部表类型切换: 外部表属性: 'EXTERNAL'='true' 内部表属性: 'EXTERNAL'='false'
注意: 属性中的EXTERNAL名称不能随意改动,必须与Hive官网保持一致。
表支持的属性: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL#LanguageManualDDL-listTableProperties
示例:
use day06;
-- 创建内部表和外部表
create table inner_stu (
id int,
name string
);
create external table outer_stu (
id int,
name string
);
-- 添加数据
insert into inner_stu values(1,'zhangshan');
insert into outer_stu values(1,'zhangshan');
-- 查看当前数据库下面的所有表
show tables;
-- 查看建表语句
show create table inner_stu;
show create table outer_stu;
-- 不管是查看内部表还是外部表的建表语句,都是show create table 表名称的语法
-- show create external table outer_stu;
-- 查看表的详细信息
desc inner_stu;
desc formatted inner_stu;
-- 表字段的操作
-- 表添加字段(列名是同一个意思)
alter table inner_stu add columns(age int);
desc inner_stu;
-- 替换表中的字段
-- 替换指的是将表中原有的所有字段都替换
alter table outer_stu replace columns(age int);
alter table outer_stu replace columns(id int,age int);
alter table outer_stu replace columns(id int,age int,name string);
-- 注意:字符串类型的字段不能随便直接改成数值类型。
alter table outer_stu replace columns(id int,name string,age int);
alter table outer_stu replace columns(id int,name string,age string);
desc outer_stu;
select * from outer_stu;
-- 同时修改字段名称和数据类型
alter table outer_stu change age new_age varchar(10);
-- 注意:字符串类型的字段不能随便直接改成数值类型。
-- 其中的解决办法:重新建一张表,然后把旧表的数据全部插入到新表里面去
alter table outer_stu change new_age age int;
desc outer_stu;
-- 表的修改操作
-- 修改表名称
alter table inner_stu rename to my_inner_stu;
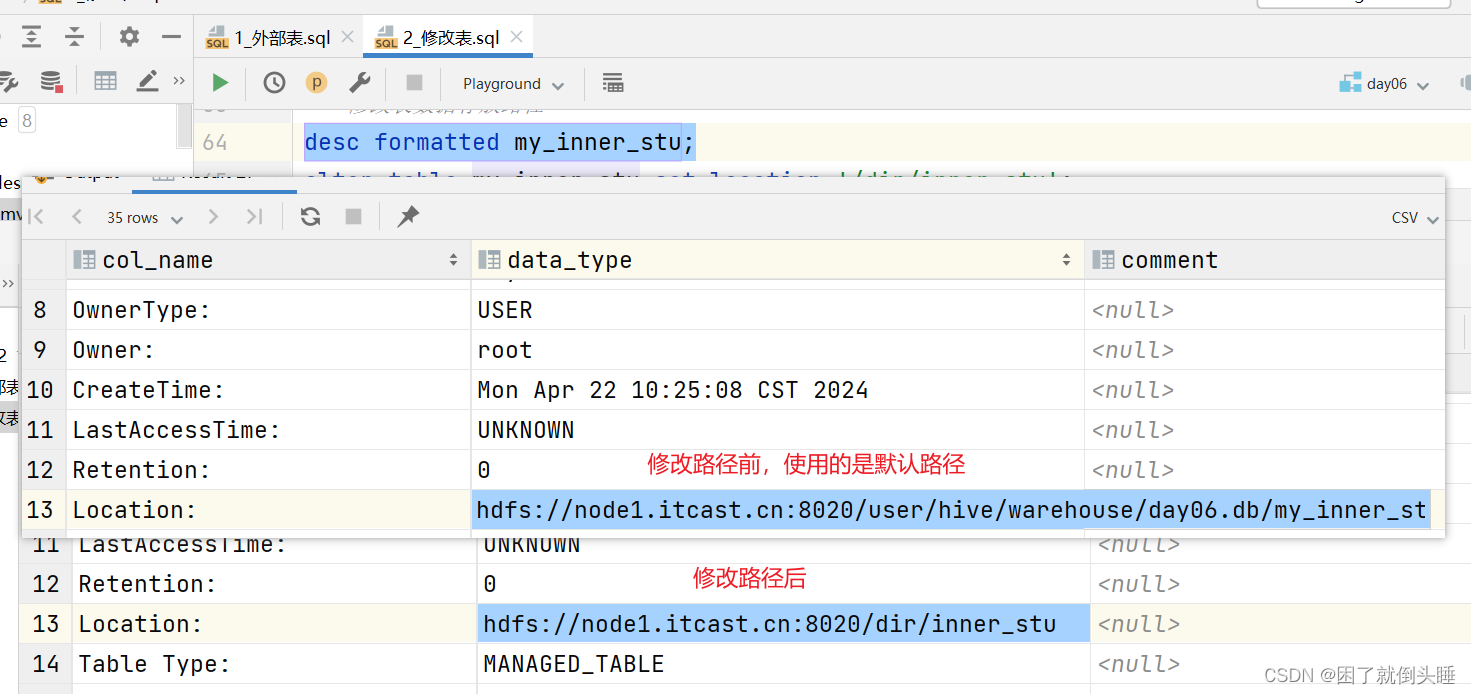
-- 修改表数据存放路径
-- 注意: 不推荐修改,就使用默认路径
desc formatted my_inner_stu;
alter table my_inner_stu set location '/dir/inner_stu';
desc formatted my_inner_stu;
-- 添加数据
insert into my_inner_stu values(1,'zhangshan',18);
select * from my_inner_stu;
desc formatted my_inner_stu;
-- 修改表属性
-- 内外部表相互转换
-- 内部表 -> 外部表
alter table my_inner_stu set tblproperties ('EXTERNAL'='true');
desc formatted my_inner_stu;
-- 外部表 -> 内部表
desc formatted outer_stu;
alter table outer_stu set tblproperties ('EXTERNAL'='false');
desc formatted outer_stu;
修改表路径前后对比:
show create table中可能遇到的问题:
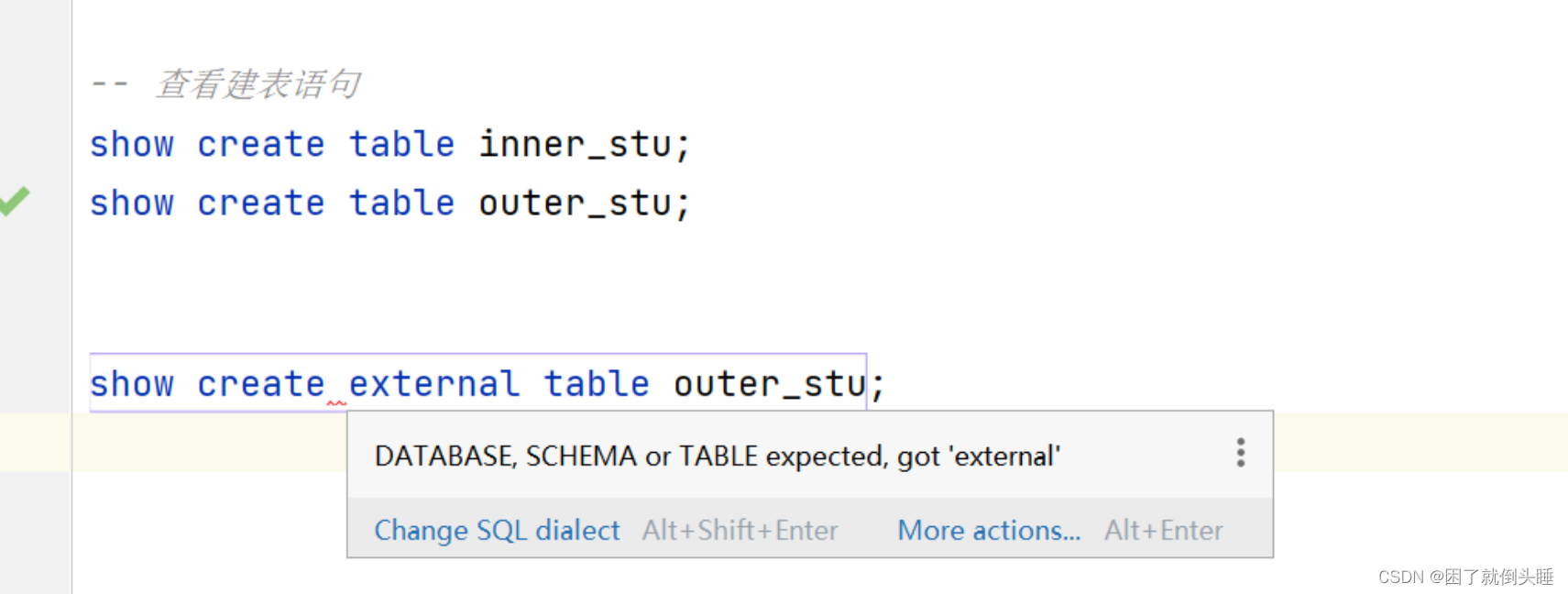
原因: 不管是查看内部表还是外部表的建表语句,都是show create table 表名称的语法
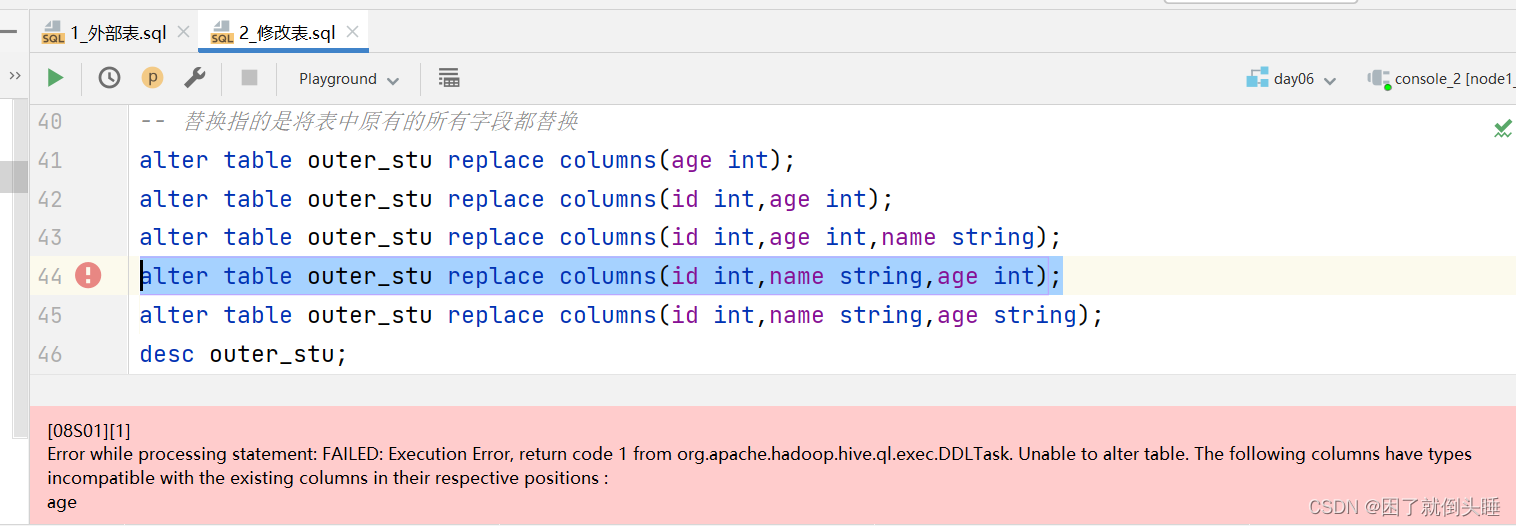
原因: 字符串类型的字段不能随便变成数值类型
快速映射表
创建表的时候指定分隔符: create [external] table 表名(字段名 字段类型)row format delimited fields terminated by 符号; 加载数据: load data [local] inpath '文件路径' into table Hive表名称
示例:
HDFS示例:
use day06; -- 1- 创建表 create table jd_products( id int, name string, price float, c_id string )row format delimited fields terminated by ','; -- 2- 数据上传到HDFS中 -- hdfs dfs -put products.txt /day06 -- 3- 加载前先检查表数据 select * from jd_products; -- 4- 将HDFS中的数据加载到Hive表中 load data inpath '/day06/products.txt' into table jd_products; -- 5- 数据验证 select * from jd_products;
本地映射示例:
use day06; -- 1- 创建表 create table jd_products_local( id int, name string, price float, c_id string )row format delimited fields terminated by ','; -- 2- 加载前先检查表数据 select * from jd_products_local; -- 4- 将本地中的数据加载到Hive表中 -- 推举使用从HDFS上面将数据加载到Hive load data local inpath '/home/products.txt' into table jd_products_local; -- 5- 数据验证 select * from jd_products_local;
















 1766
1766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











