






7、union联合查询
union: 对重复数据会去重 union all: 对重复数据不会去重 注意:union和union all中两边的字段(类型、顺序)要对应上
示例:
use day08; select * from students; select id,name from students where id in (95001,95003); select id,name from students where id=95001 or id=95003; -- union:对重复数据会进行去重处理 select id,name from students where id in (95001,95003) union select id,name from students where id in (95003,95004,95005); -- union all:对重复数据不会进行去重处理 select id,name from students where id in (95001,95003) union all select id,name from students where id in (95003,95004,95005); -- 注意:union和union all中两边的字段(名称、顺序)要对应上 select id,name from students where id in (95001,95003) union all select id,age from students where id in (95003,95004,95005); select id,name from students where id in (95001,95003) union all select name,id from students where id in (95003,95004,95005);
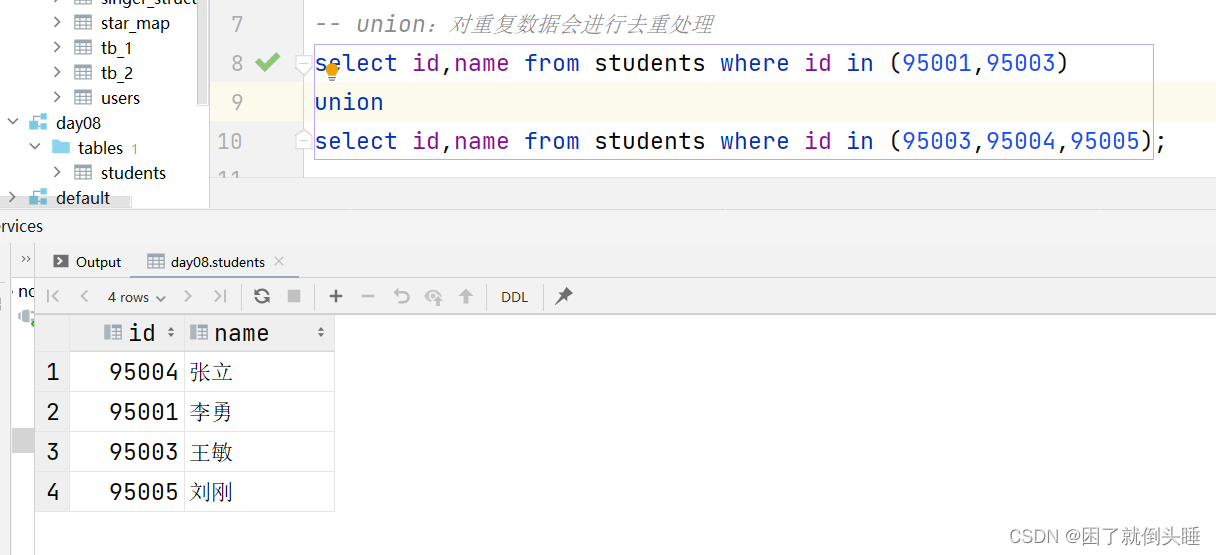
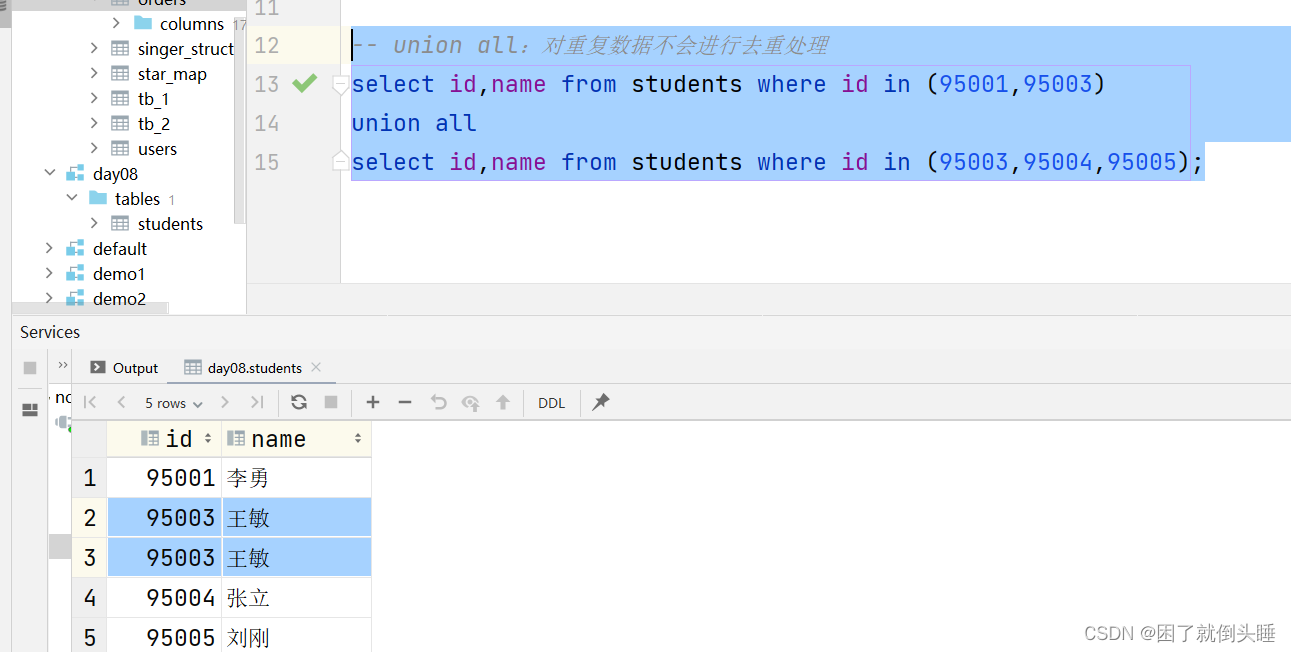
可能遇到的问题:
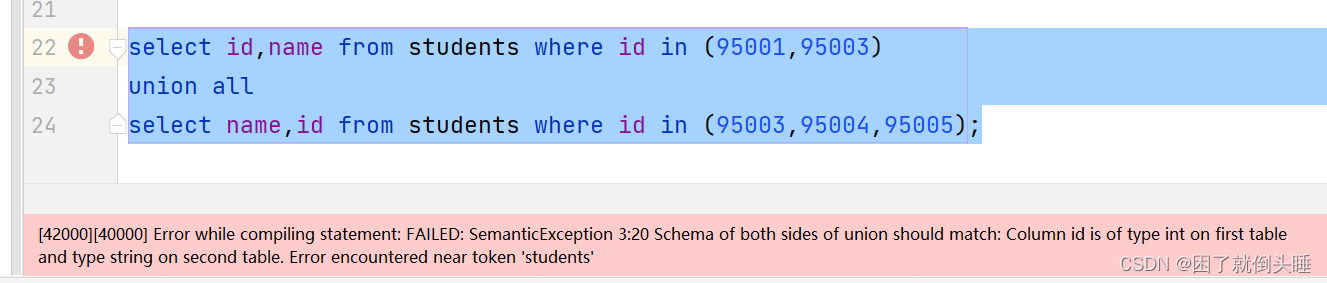
原因: union和union all中两边的字段(类型、顺序)要对应上
8、with as子查询
with 临时表的名称1 as (
数据查询语句
) select语句;
with 临时表的名称1 as (
数据查询语句
),
临时表的名称2 as (
数据查询语句
)select语句;
注意:
1- 临时表的名称要保持唯一
2- with只能写在最前面,而且只有一个
示例:
-- with as子查询 -- 子查询:普通写法 select * from ( select id, name from students where id in (95001, 95003) )tmp where id=95001; -- 子查询:with as写法 with tmp_1 as ( select id, name from students where id in (95001, 95003) ) select * from tmp_1 where id=95001; with tmp_1 as ( select id, name from students where id in (95001, 95003) ), tmp_2 as ( select id, name from students where id in (95004, 95005) ) select * from tmp_1,tmp_2; -- 这里是cross join的简写
9、抽样查询
语法: tablesample (bucket 抽样桶的个数 out of 桶的总数 on [字段名称 | rand()]) 抽样查询的用途: 当Hive表中的数据非常多的时候,我们想快速的对数据整体情况有一个大概的了解
示例:
use day07; -- 分桶的时候按照字段进行分桶 select * from orders tablesample (bucket 1 out of 20 on orderId); -- 分桶的时候进行随机分桶。内部会尽可能的做到均衡 select * from orders tablesample (bucket 1 out of 20 on rand());
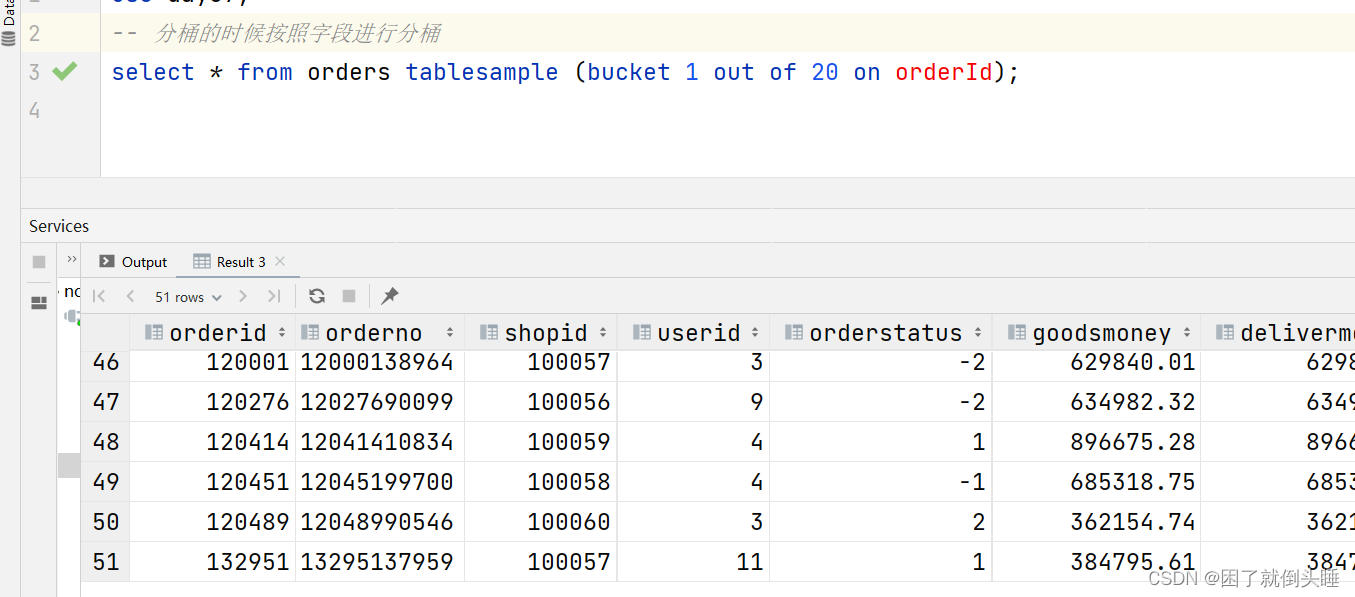
10、内置虚拟列
虚拟列是Hive内置的可以在查询语句中使用的特殊标记,可以查询数据本身的详细参数。 Hive目前可用3个虚拟列: INPUT__FILE__NAME,显示数据行所在的具体文件 BLOCK__OFFSET__INSIDE__FILE,显示数据行所在文件的偏移量 ROW__OFFSET__INSIDE__BLOCK,显示数据所在HDFS块的偏移量 此虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
示例:
use day07; -- 开启ROW__OFFSET__INSIDE__BLOCK使用 set hive.exec.rowoffset=true; SELECT *, INPUT__FILE__NAME, -- 数据所在的文件位置 BLOCK__OFFSET__INSIDE__FILE, -- 数据所在的字节位置 ROW__OFFSET__INSIDE__BLOCK -- 数据文件所在的block块的偏移量 FROM course_bucket_tb_sort;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











