







一、HashMap的数据结构
1-1 HashMap jdk1.7到1.8数据结构的变化。
1.7版本的HashMap的数据结构是数组加链表,1.8版本的时候数据结构改成了数组加链表加红黑树
1-2 HashMap 数据结构快速查找逻辑
其实HashMap的数据结构就是为了实现快速查找。
HashMap怎么去存元素:
HashMap是根据key去决定存储的位置。
首先会先将key计算出他的hash值,然后再二次hash,跟数组的长度相得到得就是下标(数组中的地址),如果再这个地址中存在其他值会先去跟他做一个equals的判断是否是相同,如果是相同会将他覆盖,不相同添加到链表的下一个元素。
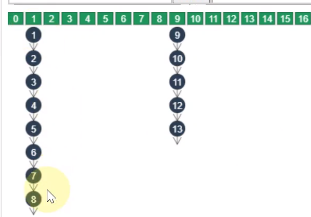
HashMap如何实现快速查找:
-
将key的值hash再二次hash.
-
拿二次hash的值跟数组相模取出桶下标。
-
去对应的桶下标进行调用equals比较获得一样的key,取出值。
1-3 链表过长解决 - 扩容
如果链表的的长度过长,那么在查找元素跟添加元素的时候的比较次数就会一直增加。
第一种链表过长的解决方法是: 当数据的数量大于数组的3/4时,数组就会扩容,然后就会重新计算桶下标实现降低链表的长度。
1-4 链表过长解决 - 链表树化
当扩容无法解决链表过长的问题,当数组的长度大于等于64 而且 链表的长度大于8 就会将链表树化成红黑树。
1-5 总结
为什么要用红黑树?
红黑树相当于长链表性能更好。
为何不一上来就树化?
短链表相对于红黑树的性能会更好,占用内存会更少,所以不到万不可以不使用红黑树。
树化阈值为何是8?
正常实际情况下没有去指定hashcode,链表很少会超过8,选择8就是为了降低链表树化的概率
何时会树化?
当扩容无法解决链表过长的问题,当数组的长度大于等于64 而且 链表的长度大于8 就会将链表树化成红黑树。
何时为退化成链表?
情况一:当扩容数组时,拆分树时,如果树的长度小于等于6,树就会退化成链表。
情况二:在remove节点之前,如果根节点的左儿子,左孙子,右儿子不存在,就会退化成链表
二、重要知识点
2-1 索引如何计算
首先会先将key计算出他的hash值,然后再二次hash,跟数组的长度相得到得就是下标(数组中的地址),如果再这个地址中存在其他值会先去跟他做一个equals的判断是否是相同,如果是相同会将他覆盖,不相同添加到链表的下一个元素。
求模的优化:
a % b =============> a & (b - 1) (只要数组的长度为2的n次方才可以使用这样的公式)
2-2 为何要二次哈希
为了让元素的哈希分布更加均匀,防止长链表的产生。
2-3 容量为何是2的n次幂
当数组长度为2的n次幂是,在计算桶下标时可以使用&来进行计算优化。
扩容时可以使用hash & odlCap 来判断元素的位置,当等于0时留在原来的位置,当不等于0使用原来的位置加上& 的结果。
2-4 容量不用2的n次幂行不行
设计者综合了各种因素选择了2的n次幂,不能说哪种设计更好,选择2的n次幂是为了优化性能。
2-5 put方法的流程,1.7 与1.8 的不同。
-
当第一次put时,会创建一个长度为16的数组。
-
计算桶下标
-
判断节点是否为空,为空创建node返回,不为空根据当前node 的添加规则添加。
-
返回前判断元素数量是不是超过数组扩容的阈值,超过的话数组进行扩容。
1.7 与 1.8的不同:
1,链表插入节点时,1.7是头插法,1.8是尾插法。
2,1.7扩容规则是大于等于阈值且无空位,1.8是到达阈值就直接扩容。
3,1.8在扩容重新计算元素的桶下标时有优化。
2-6 加载因子为何默认是0.75f
在空间占用与查询时间之间取得较好的权衡
大于这个值,空间节省了,但链表就会比较长影响性能
小于这个值,冲突减少了,但扩容就会更频繁,空间占用多
2-7 并发丢数据
扩容死链:1.7
数据错乱:1.7、1.8
数据错误的导致原因是:
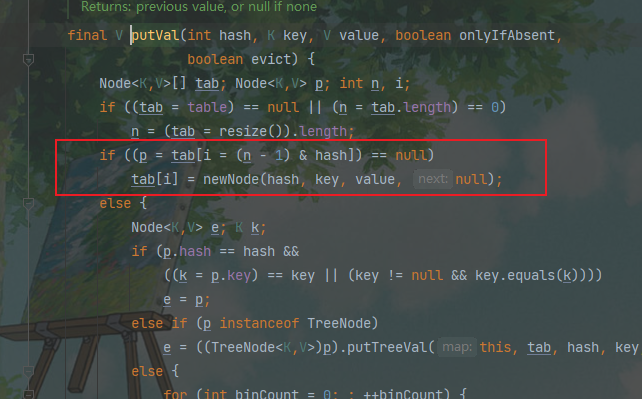
俩个线程同时进入这个判断中,导致执行较慢的线程会直接覆盖上一个线程的值。
扩容死链的导致原因:
俩个线程同时进行扩容,第一个线程已经将数据转移到新的数组,第二个线程继续转移就会造成扩容死链。
2-8 key的要求
HashMap的key可以为null
作为key的对象,需要重写hashCode方法跟equals方法,且对象的内容不可变。
2-9 String的hashCode如何设计
hashCode的设计就是为了元素均匀的散布在数组上。
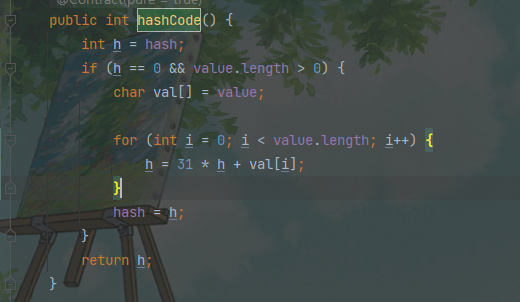
使用String作为key的优势 :
-
分布比较均匀
-
string类型是不可变的,所以hash值也是不可变的,不需要考虑线程安全。
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











