




250408_解决加载Cifar10等大量数据集速度过慢,耗时过长的问题(加载数据时多线程的坑)
在做Cifar10图像分类任务时,发现每个step时间过长,且在资源管理器中查看显卡资源调用异常,主要表现为,显卡周期性调用,呈现隔一会儿动一下的情况(间隔时间过大导致不能同时截到两个峰值)。
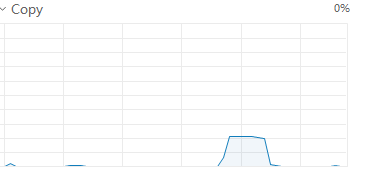
通过检测每步耗费时间发现,载入数据集的时间远远大于前向处理的时间。
在以下参数情况下
batch_size=16
num_workers=20 # 线程数
载入Cifai10数据集的时间为60s左右,前向计算时间仅为0.002s,浪费了大量的时间用于载入及传输数据。
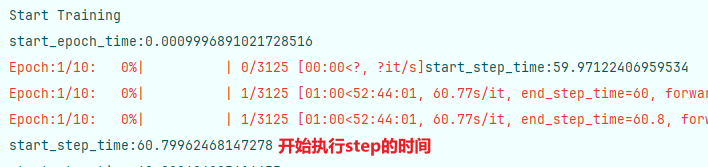
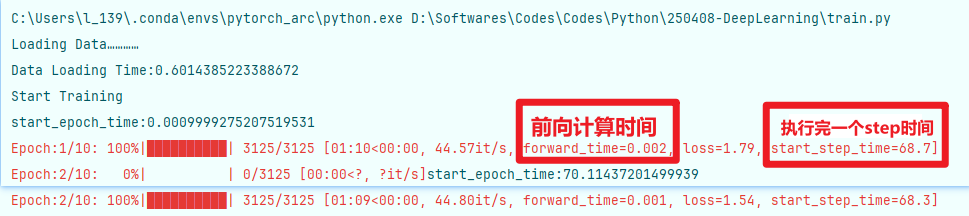
先说结论,是多线程的问题,线程过多导致多线程冲突,修改num_workers=0即可解决问题
解决过程
修改过程中查阅很多资料和大佬博客,尝试了重新定义自己的dataset方法,将transform定义到初始化方法中,避免每获取一次数据就执行一遍transform,而是改为在把数据载入内存时一次全部处理完(详见解决pytorch中Dataloader读取数据太慢的问题_dataloader数据读取慢-CSDN博客)
然后重新定义自己加载数据的方法,大佬文中没给加载的方法,我这里补充
def data_loader(batch_size=4,num_workers=2):
"""
:param batch_size: 批次大小
:param num_workers: 线程数
:return:train_loader:训练数据加载器
test_loader:测试数据加载器
class:分类类别
"""
root_dir="./data"
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)),
])
train_dataset = CUDACIFAR10(
root=root_dir,
train=True,
to_cuda=True, # 使用XPU(或GPU)
half=False, # 不使用半精度浮点数
download=True, # 如果数据集尚未下载,则下载
pre_transform=transform
)
trainloader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
test_dataset = CUDACIFAR10(
root=root_dir,
train=False,
to_cuda=True, # 使用XPU(或GPU)
half=False, # 不使用半精度浮点数
download=True, # 如果数据集尚未下载,则下载
pre_transform=transform
)
testloader = DataLoader(
dataset=test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers
)
classes=('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
return trainloader,testloader,classes
然后加载数据集发现报错:
RuntimeError: _share_filename_: only available on CPU
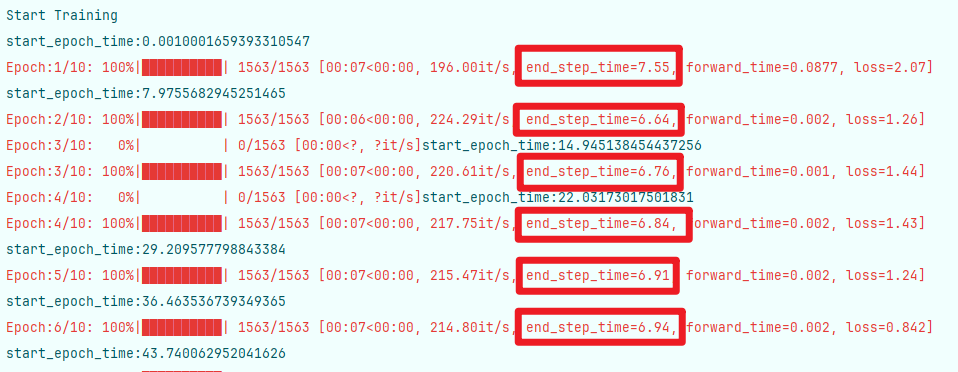
多线程加载仅支持在cpu上进行,我们这样的处理方法已经提前将数据载入到gpu或xpu上,无法使用多线程,遂将num_workers修改为0,发现问题解决了。数据载入速度变得很快。遂准备复现并记录问题,发现把大佬数据类代码注释后,使用官方cifar10数据类代码,加载速度仍较快,核实发现应该是多线程的问题。
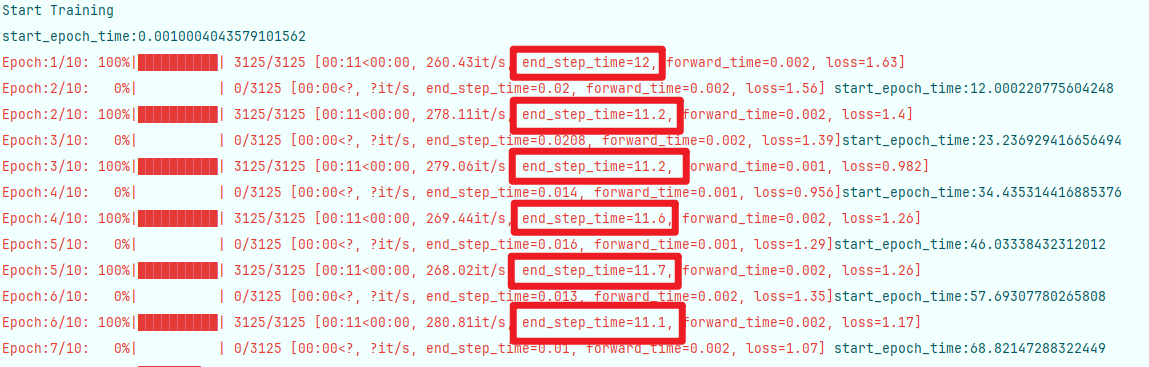
尝试多组参数
batch_size=16
num_workers=0
每个step执行时间为11-12s左右
调整参数
batch_size=32
num_workers=1
此时显卡调用情况为长矩形,持续调用,但占用率并不高,在33-34左右波动
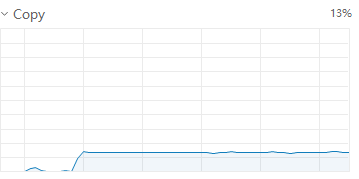
此时显卡占用情况呈现连续峰谷,占用波峰为50左右,每个step执行时间缩短为6-8秒
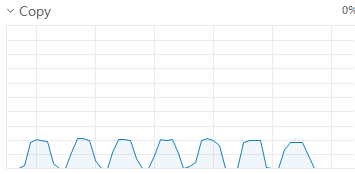
因显卡调用仍有间隙,尝试增大batchsize
batch_size=64
num_workers=1
显卡占用情况仍呈现连续峰谷,占用波峰为30左右,每个step执行时间缩短为6-7秒
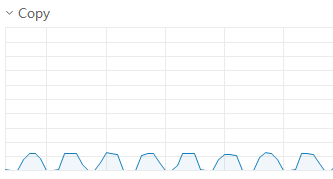
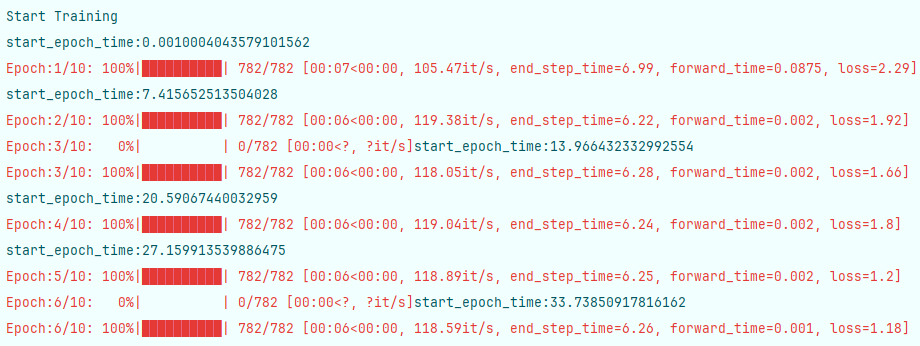
将batch_size进一步放大到128,显卡占用波峰继续缩小为20左右,但每个step的时间未明显降低
尝试64与2的搭配,仍与32与1的搭配执行时间及显卡占用大致相同,执行时间误差1s,占用误差50%。
尝试128与2的搭配,结果与64,1的搭配情况大致相同,得结论,与比值有关。
| batch_size | num_workers | 每个step执行时间(秒) | 显卡占用情况描述 | 显卡占用率波峰(%) | 性能优化效果(与初始参数对比) |
|---|---|---|---|---|---|
| 16 | 20 | 70 | 显卡周期性调用,间隔时间过长,不能充分利用显卡资源,大部分时间在等待数据加载 | - | 数据载入时间过长,显卡资源浪费严重 |
| 16 | 0 | 11-12 | 显卡调用情况为长矩形,持续调用,但占用率不高,波动在33-34%左右 | 33-34 | 数据载入速度显著提高,显卡资源利用率有所提升,但仍有提升空间 |
| 32 | 1 | 6-8 | 显卡调用情况呈现连续峰谷,占用波峰约为50% | 50 | 数据载入速度进一步提高,显卡资源利用率提升,step执行时间缩短 |
| 64 | 1 | 6-7 | 显卡调用情况仍呈现连续峰谷,占用波峰约为30% | 30 | 数据载入速度进一步提高,显卡资源利用率提升,step执行时间进一步缩短 |
| 128 | 1 | 未明显降低 | 显卡占用波峰继续缩小为20%左右 | 20 | 数据载入速度未明显提升,显卡资源利用率降低,step执行时间未明显缩短 |
| 64 | 2 | 与32,1搭配大致相同 | 与32,1搭配大致相同 | - | 与32,1搭配大致相同,执行时间误差1秒,占用误差5% |
| 128 | 2 | 与64,1搭配大致相同 | 与64,1搭配大致相同 | - |
batch_size 和 num_workers 的比值对性能影响较大,需要根据具体情况进行调整。在测试中,batch_size=32, num_workers=1 和 batch_size=64, num_workers=1 的搭配效果较好,能够在数据载入速度和显卡资源利用率之间取得较好的平衡
进一步思考
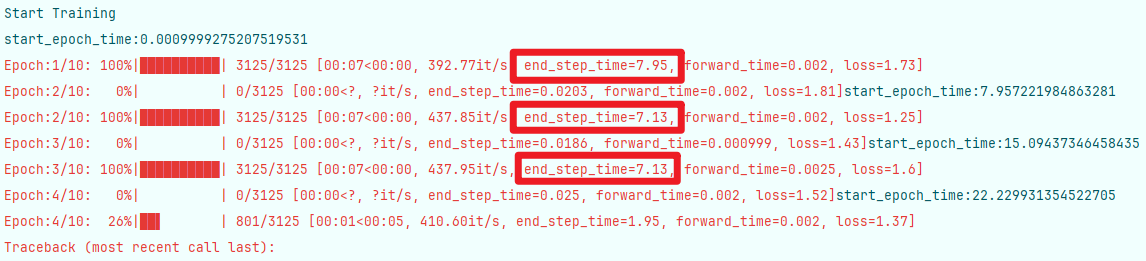
发现若如所测数据,
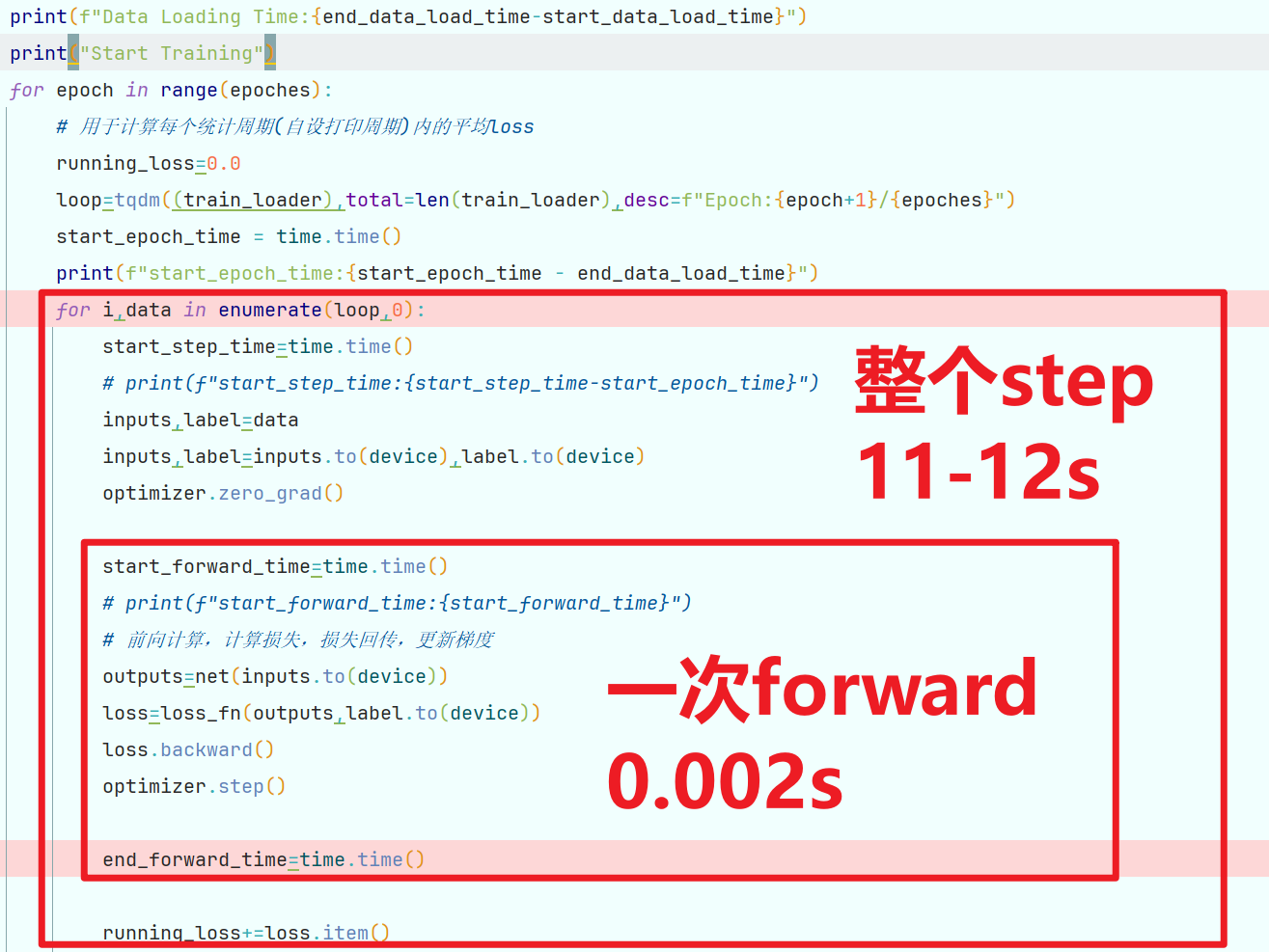
仍有大量时间浪费在cpu与gpu的通信及其他步骤上
使用前文所提到的大佬的数据类初始化方法(避免多次transform),在batch_size=16,num_workers=0的参数基础上,测得单次step时间可压缩到7-8s,即节省3-4s。其余参数大家自行尝试。
本人初学小白,如有错误劳烦大佬指正

















 2274
2274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









