







利用Keras组件,构建合适的Transformer模型,并完成影评分类任务。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
help(layers.MultiHeadAttention)
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
# embedding 维度
self.embed_dim = embed_dim
# 全连接层维度
self.dense_dim = dense_dim
# 要几个头
self.num_heads = num_heads
self.attention = layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential([
layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim), # 设置 Dense 层的输出维度为 embed_dim
])
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs):
attention_output = self.attention(inputs, inputs)
# 残差连接和正则化
proj_input = self.layernorm_1(inputs + attention_output)
# 全连接映射以及残差连接和正则化
dense_output = self.dense_proj(proj_input)
# 残差连接和正则化
output = self.layernorm_2(dense_output + proj_input)
return output
def get_config(self):
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
from keras.datasets import imdb
from keras_preprocessing.sequence import pad_sequences
(x_train, y_train), (x_test, y_test) = imdb.load_data(path="imdb.npz",
num_words=vocab_size,
skip_top=0,
maxlen=None,
seed=2023,
start_char=1,
oov_char=2,
index_from=3)
max_len = 150
x_train = pad_sequences(x_train, maxlen=max_len)
x_test = pad_sequences(x_test, maxlen=max_len)
callbacks = [keras.callbacks.ModelCheckpoint("transformer_encoder.keras", save_best_only=True)]
history = model.fit(x_train, y_train, validation_split=0.2, epochs=4, batch_size=32, callbacks=callbacks)
model = keras.models.load_model(
"transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder}
)
print(f"Test acc: {model.evaluate(x_test,y_test)[1]:.3f}")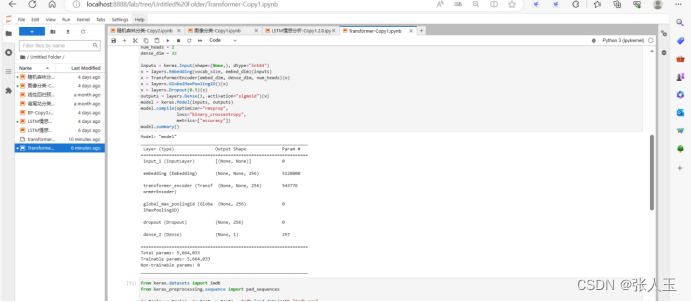


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











