







6.5 拟牛顿类算法
牛顿类算法是二阶算法,其理论完备,实践中经常被用于解决规模不大的优化问题,优势是其求解效率高。但对于大规模问题就会产生困难。
拟牛顿法能够在每一步以较小的计算代价生成近似矩阵,并且使用近似矩阵代替海瑟矩阵而产生的迭代序列仍具有 Q-超线性收敛的性质。拟牛顿方法不计算海瑟矩阵 ∇ 2 f ( x ) \nabla^2f(x) ∇2f(x),而是构造其近似矩阵 B k B^k Bk 或其逆的近似矩阵 H k H^k Hk。
6.5.1 割线方程
首先回顾牛顿法的推导过程.设 f ( x ) f(x) f(x) 是二次连续可微函数,根据泰勒展开,向量值函数 ∇ f ( x ) \nabla f(x) ∇f(x) 在点 x k + 1 x^{k+1} xk+1 处的近似为
∇ f ( x ) = ∇ f ( x k + 1 ) + ∇ 2 f ( x k + 1 ) ( x − x k + 1 ) + O ( ∥ x − x k + 1 ∥ 2 ) ( 6.5.1 ) \nabla f(x)=\nabla f(x^{k+1})+\nabla^{2}f(x^{k+1})(x-x^{k+1})+\mathcal{O}(\|x-x^{k+1}\|^{2})\qquad(6.5.1) ∇f(x)=∇f(xk+1)+∇2f(xk+1)(x−xk+1)+O(∥x−xk+1∥2)(6.5.1)
令 x = x k , s k = x k + 1 − x k x=x^k,s^k=x^{k+1}-x^k x=xk,sk=xk+1−xk 及 y k = ∇ f ( x k + 1 ) − ∇ f ( x k ) y^k=\nabla f(x^{k+1})-\nabla f(x^k) yk=∇f(xk+1)−∇f(xk),得到
∇ 2 f ( x k + 1 ) s k + O ( ∥ s k ∥ 2 ) = y k ( 6.5.2 ) \nabla^{2}f(x^{k+1})s^{k}+\mathcal{O}(\|s^{k}\|^{2})=y^{k}\qquad(6.5.2) ∇2f(xk+1)sk+O(∥sk∥2)=yk(6.5.2)
忽略高阶项 ∥ s k ∥ 2 \|s^k\|^2 ∥sk∥2,只希望海瑟矩阵的近似矩阵 B k + 1 B^{k+1} Bk+1 满足方程
y k = B k + 1 s k ( 6.5.3 ) y^{k}=B^{k+1}s^{k}\qquad(6.5.3) yk=Bk+1sk(6.5.3)
或者其逆的近似矩阵 H k + 1 H^{k+1} Hk+1 满足方程
s k = H k + 1 y k ( 6.5.4 ) s^{k}=H^{k+1}y^{k}\qquad(6.5.4) sk=Hk+1yk(6.5.4)
并称 (6.5.3) 式和 (6.5.4) 式为割线方程。
还可以从另一个角度理解割线方程 (6.5.3). 牛顿法本质上是对目标函数 f ( x ) f(x) f(x) 在迭代点 x k x^k xk 处做二阶近似然后求解. 考虑 f ( x ) f(x) f(x) 在点 x k + 1 x^{k+1} xk+1 处的二阶近似
m k + 1 ( d ) = f ( x k + 1 ) + ∇ f ( x k + 1 ) T d + 1 2 d T B k + 1 d ( 6.5.5 ) m_{k+1}(d)=f(x^{k+1})+\nabla f(x^{k+1})^{\mathrm{T}}d+\frac{1}{2}d^{\mathrm{T}}B^{k+1}d\qquad(6.5.5) mk+1(d)=f(xk+1)+∇f(xk+1)Td+21dTBk+1d(6.5.5)
我们要求 m k + 1 ( d ) m_{k+1}(d) mk+1(d) 在 d = − s k d=-s^k d=−sk 和 d = 0 d=0 d=0 处的梯度与 f ( x ) f(x) f(x) 在 x = x k x=x^k x=xk 和 x = x k + 1 x=x^{k+1} x=xk+1 处的梯度分别保持一致. 注意到 ∇ m k + 1 ( 0 ) = ∇ f ( x k + 1 ) \nabla m_{k+1}(0)=\nabla f(x^{k+1}) ∇mk+1(0)=∇f(xk+1) 是自然满足的,为了使得第一个条件满足只需
∇ m k + 1 ( − s k ) = ∇ f ( x k + 1 ) − B k + 1 s k = ∇ f ( x k ) ( 6.5.6 ) \nabla m_{k+1}(-s^{k})=\nabla f(x^{k+1})-B^{k+1}s^{k}=\nabla f(x^{k})\qquad(6.5.6) ∇mk+1(−sk)=∇f(xk+1)−Bk+1sk=∇f(xk)(6.5.6)
整理即可得到 (6.5.3) 式。
另外,注意到近似矩阵 B k B^k Bk 的正定性是一个很关键的因素,在 (6.5.3) 式两边同时左乘 ( s k ) T (s^k)^\mathrm{T} (sk)T 可得 ( s k ) T B k + 1 s k = ( s k ) T y k (s^k)^\mathrm{T}B^{k+1}s^k=(s^k)^\mathrm{T}y^k (sk)TBk+1sk=(sk)Tyk,因此条件
( s k ) T y k > 0 ( 6.5.7 ) (s^k)^\mathrm{T}y^k>0\qquad(6.5.7) (sk)Tyk>0(6.5.7)
为 B k + 1 B^{k+1} Bk+1 正定的一个必要条件。曲率条件: 在迭代过程中始终满足 ( s k ) T y k > 0 (s^k)^\mathrm{T}y^k>0 (sk)Tyk>0。对于一般的目标函数 f ( x ) f(x) f(x),需要使用 Wolfe 准则线搜索来保证曲率条件成立。实际上,根据 Wolfe 准则的条件 (6.1.4b) 有 ∇ f ( x k + 1 ) T s k ⩾ c 2 ∇ f ( x k ) T s k \nabla f(x^{k+1})^\mathrm{T}s^k\geqslant c_2\nabla f(x^k)^\mathrm{T}s^k ∇f(xk+1)Tsk⩾c2∇f(xk)Tsk,其中 c 2 ∈ ( 0 , 1 ) c_2\in(0,1) c2∈(0,1),两边同时减去 ∇ f ( x k ) T s k \nabla f(x^k)^\mathrm{T}s^k ∇f(xk)Tsk 得,
( y k ) T s k ⩾ ( c 2 − 1 ) ∇ f ( x k ) T s k > 0 (y^k)^\mathrm{T}s^k\geqslant(c_2-1)\nabla f(x^k)^\mathrm{T}s^k>0 (yk)Tsk⩾(c2−1)∇f(xk)Tsk>0
这是因为 c 2 − 1 < 0 c_2-1<0 c2−1<0 且 s k = α k d k s^k=\alpha_k d^k sk=αkdk 是下降方向。
注意,仅仅使用 Armijo 准则不能保证曲率条件成立。
在通常情况下,近似矩阵 B k + 1 B^{k+1} Bk+1 或 H k + 1 H^{k+1} Hk+1 是由上一步迭代加上一个修正得到的,并且要求满足割线方程 (6.5.3)。拟牛顿方法的一般框架 (算法 6.5),下一小节将讨论一些具体的矩阵更新方式。

# 算法 6.5 拟牛顿算法(Wolf准则和BFGS拟牛顿更新方法)
def line_search_Wolf(x, alpha_hat, d, gamma = 0.5, c1 = 0.1, c2 = 0.9):
alpha = alpha_hat
while (f(x + alpha * d) > f(x) + c1 * alpha * np.dot(grad_f(x), d)) and (grad_f(x + alpha * d) < c2 * np.dot(grad_f(x), d)) :
alpha = gamma * alpha
return alpha
def quasi_newton_algorithm(x0, B0, alpha, c, gamma, tol=1e-6):
x = x0
B = B0
k = 0
x_history = [x]
while not np.linalg.norm(grad_f(x)) < tol: # 判断当前点梯度的范数是否小于阈值 tol
grad = grad_f(x)
d= -np.dot(np.linalg.inv(B), grad) # or d = -np.dot(H, gradient)
alpha = line_search_Wolf(x, alpha, d)
x = x + alpha * d
x_history.append(x)
s = alpha * d
grad_next = grad_f(x)
y = grad_next - grad
B = B + np.outer(y, y) / np.dot(y, s) - np.outer(np.dot(B, s), np.dot(B, s)) / np.dot(s, np.dot(B, s))
# np.outer(y, y)计算了向量y的外积
k = k + 1
return x_history, k
# 目标函数及其梯度、海瑟矩阵的计算(同例6.3)
def f(x):
return x[0]**2 + 10*x[1]**2
def grad_f(x):
return np.array([2*x[0], 20*x[1]])
def hess_f(x):
return np.array([[2, 0], [0, 20]])
x0 = np.array([-10, -1])
B0 = np.eye(2)
alpha = 0.085
c = 0.1
gamma = 0.5
quasi_Newton_history, k = quasi_newton_algorithm(x0, B0, alpha, c,gamma)
print("Optimal solution:", quasi_Newton_history[-1])
'''Optimal solution: [-3.84435347e-07 3.05062008e-08]'''
print("迭代次数:", k)
'''迭代次数: 188'''
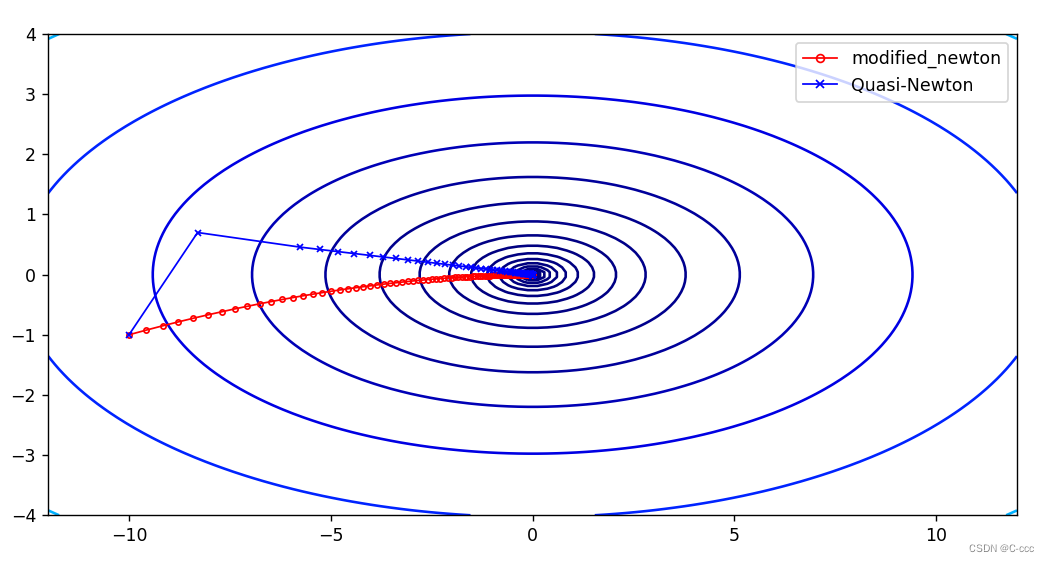
# 绘制等高线图
x = np.linspace(-12, 12, 100)
y = np.linspace(-4, 4, 100)
X, Y = np.meshgrid(x, y)
Z = X**2 + 10*Y**2
plt.figure(figsize=(10, 5))
plt.contour(X, Y, Z, levels=np.logspace(-2, 3, 20), cmap='jet') # levels 参数控制等高线的密集程度
plt.plot([x[0] for x in M_Newton_history], [x[1] for x in M_Newton_history], markersize = 3, marker='o', markerfacecolor='none', linewidth=1, color='r', label='modified_newton')
plt.plot([x[0] for x in quasi_Newton_history], [x[1] for x in quasi_Newton_history], markersize = 3, marker='x', markerfacecolor='none', linewidth=1, color='b', label='Quasi-Newton')
plt.legend(loc='best', markerscale=1.5) # 设置标签位置为最佳位置,调整图例的大小
plt.show()
在实际应用中基于 H k H^k Hk 的拟牛顿法更加实用,这是因为根据 H k H^k Hk 计算下降方向 d k d^k dk 不需要求解线性方程组。基于 B k B^k Bk 的拟牛顿法有比较好的理论性质,产生的迭代序列比较稳定。如果有办法快速求解线性方程组,我们也可采用基于 B k B^k Bk 的拟牛顿法。此外在某些场景下,比如有些带约束的优化问题的算法设计,由于需要用到海瑟矩阵的近似, B k B^k Bk 的使用也很常见。
6.5.2 拟牛顿矩阵更新方式
这一小节介绍一些常见的拟牛顿矩阵的更新方式 秩一更新 (SR1)、BFGS 公式和DFP 公式。
1. 秩一更新 (SR1)
秩一更新 (SR1) 公式是结构最简单的拟牛顿矩阵更新公式.设 B k B^k Bk 是第 k k k 步的近似海瑟矩阵,我们通过对 B k B^k Bk 进行秩一修正得到 B k + 1 B^{k+1} Bk+1,使其满足割线方程 (6.5.3).为此使用待定系数法求出修正矩阵,并设
B k + 1 = B k + a u u T ( 6.5.8 ) B^{k+1}=B^{k}+auu^{\mathrm{T}}\qquad(6.5.8) Bk+1=Bk+auuT(6.5.8)
其中 u ∈ R n , a ∈ R u\in\mathbb{R}^n,a\in\mathbb{R} u∈Rn,a∈R 待定. 根据割线方程 (6.5.3)
B k + 1 s k = ( B k + a u u T ) s k = y k B^{k+1}s^{k}=(B^{k}+auu^{\mathrm{T}})s^{k}=y^{k} Bk+1sk=(Bk+auuT)sk=yk
进而得到
a u u T s k = ( a ⋅ u T s k ) u = y k − B k s k auu^\mathrm{T}s^k=(a\cdot u^\mathrm{T}s^k)u=y^k-B^ks^k auuTsk=(a⋅uTsk)u=yk−Bksk
由于 a ⋅ u T s k a\cdot u^\mathrm{T}s^k a⋅uTsk 是一个标量,因此 u u u 和 y k − B k s k y^k-B^ks^k yk−Bksk 方向相同.
令 u = y k − B k s k u=y^k-B^ks^k u=yk−Bksk,代入上式可知
a ( ( y k − B k s k ) T s k ) ( y k − B k s k ) = y k − B k s k a((y^k-B^ks^k)^\mathrm{T}s^k)(y^k-B^ks^k)=y^k-B^ks^k a((yk−Bksk)Tsk)(yk−Bksk)=yk−Bksk
如果假设 ( y k − B k s k ) T s k ≠ 0 (y^k-B^ks^k)^\mathrm{T}s^k\neq0 (yk−Bksk)Tsk=0,可以得到 a = 1 ( y k − B k s k ) T s k a=\displaystyle\frac{1}{(y^k-B^ks^k)^\mathrm{T}s^k} a=(yk−Bksk)Tsk1,最终得到更新公式为
B k + 1 = B k + ( y k − B k s k ) ( y k − B k s k ) T ( y k − B k s k ) T s k ( 6.5.9 ) B^{k+1}=B^k+\frac{(y^k-B^ks^k)(y^k-B^ks^k)^\mathrm{T}}{(y^k-B^ks^k)^\mathrm{T}s^k}\qquad(6.5.9) Bk+1=Bk+(yk−Bksk)Tsk(yk−Bksk)(yk−Bksk)T(6.5.9)
我们称 (6.5.9) 式为基于 B k B^k Bk 的 SR1 公式. 由完全一样的过程我们可以根据割线方程 (6.5.4) 得到基于 H k H^k Hk 的 SR1 公式:
H k + 1 = H k + ( s k − H k y k ) ( s k − H k y k ) T ( s k − H k y k ) T y k ( 6.5.10 ) H^{k+1}=H^k+\frac{(s^k-H^ky^k)(s^k-H^ky^k)^\mathrm{T}}{(s^k-H^ky^k)^\mathrm{T}y^k}\qquad(6.5.10) Hk+1=Hk+(sk−Hkyk)Tyk(sk−Hkyk)(sk−Hkyk)T(6.5.10)
基于 H k H^k Hk 的 SR1 公式推导(待定系数法):
设 H k H^k Hk 是第 k k k 步的海瑟矩阵逆的近似矩阵,通过对 H k H^k Hk 进行秩一修正得到 H k + 1 H^{k+1} Hk+1,使其满足割线方程 (6.5.4).使用待定系数法求出修正矩阵,并设
H k + 1 = H k + b v v T H^{k+1}=H^{k}+bvv^{\mathrm{T}} Hk+1=Hk+bvvT其中 v ∈ R n , b ∈ R v\in\mathbb{R}^n,b\in\mathbb{R} v∈Rn,b∈R 待定. 根据割线方程 (6.5.4)
H k + 1 y k = ( H k + b v v T ) y k = s k H^{k+1}y^{k}=(H^{k}+bvv^{\mathrm{T}})y^{k}=s^{k} Hk+1yk=(Hk+bvvT)yk=sk进而得到
b v v T y k = ( b ⋅ v T y k ) v = s k − H k y k bvv^\mathrm{T}y^k=(b\cdot v^\mathrm{T}y^k)v=s^k-H^ky^k bvvTyk=(b⋅vTyk)v=sk−Hkyk由于 b ⋅ v T y k b\cdot v^\mathrm{T}y^k b⋅vTyk 是一个标量,因此 v v v 和 s k − H k y k s^k-H^ky^k sk−Hkyk 方向相同.
令 v = s k − H k y k v=s^k-H^ky^k v=sk−Hkyk,代入上式可知
b ( ( s k − H k y k ) T y k ) ( s k − H k y k ) = s k − H k y k b((s^k-H^ky^k)^\mathrm{T}y^k)(s^k-H^ky^k)=s^k-H^ky^k b((sk−Hkyk)Tyk)(sk−Hkyk)=sk−Hkyk假设 ( s k − H k y k ) T y k ≠ 0 (s^k-H^ky^k)^\mathrm{T}y^k\neq0 (sk−Hkyk)Tyk=0,可以得到
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









