






前言
在计算机科学中,理解数据如何在内存中存储是至关重要的。这不仅有助于我们更深入地理解计算机的工作原理,还能够帮助我们编写出更高效、更健壮的程序。在所有的数据类型中,整数和浮点数无疑是最基础和最常用的两种。它们各自在内存中的存储方式既有相似之处,又有显著的不同。
整数 作为计算机中最基础的数据类型之一,其存储方式直接反映了计算机内部的二进制表示。而浮点数,作为可以表示小数点的数据类型,其存储方式则相对复杂,涉及到了指数和尾数的概念。
本文将深入探讨 整数 和 浮点数 在内存中的存储方式,从它们的定义开始,逐步揭示它们在计算机内部是如何被编码和存储的。我们将通过详细的解释和实例,帮助读者理解这两种数据类型在内存中的表示方式,以及它们之间的异同。
一:整数在内存中的存储
对于整数在内存中存储的表示方法有三种:源码 反码 补码
原码:我们将数字的 二进制表示 的最高位视为 符号位,其中 0 表示正数 ,1 表示负数,其余位表示数字的值。
反码:正数的反码与其原码相同,负数的反码是对其原码除符号位外的 所有位 取反。
补码:正数的补码与其原码相同,负数的补码是在其反码的基础上加 1 .
例如:
| 源码 | 反码 | 补码 | |
|---|---|---|---|
| +10 | 0000 .... 1010 | 0000 .... 1010 | 0000 .... 1010 |
| -10 | 1000 .... 1010 | 1111 .... 0101 | 1111....0110 |
那么,为什么计算机要这么存储?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统 一处理;同时,加法和减法也可以统一处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程 是相同的,不需要额外的硬件电路。
举个例子 :
例如在原码下计算 1+(-2),得到的结果是 -3,这显然是不对的。
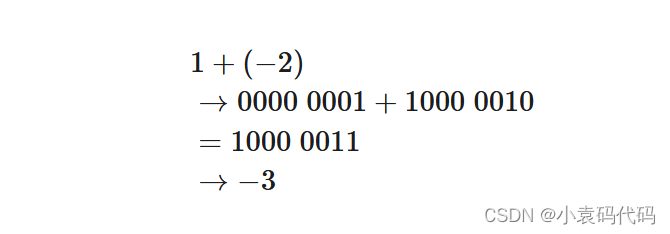
为了解决这个问题,计算机就引入 反码 ,在 反码 运算后再 返回 源码,结果就是正确的。

而 补码 的存在可以避免出现数值溢出的问题。在补码的表示方式中,正负数的范围是对称的,最高位的 1 代表的是 负数 的 最小值 ,而最高位的 0 代表的是 正数 的最大值。这样,当进行运算时,如果发生溢出,即结果超出了正负数的表示范围,计算机可以自动忽略溢出部分,而不会导致错误的结果。
而在计算机内的存储,也有所不同。
大小端的介绍
对于 int 这种跨越多个字节的程序对象,我们有两个规则:
1、这个对象的地址是什么?
2、在内存中如何去排列这些字节?
第一个很好理解,地址就是存储对象的地方,我们通常用4字节、8字节大小来表示一个对象的地址
例如:
假设 int x 在32位的环境中运行 :x 的4个字节就会存储至<0x101 0x102 0x103 0x104>的位置上
第二个问题就是如何去排列这些字节。这就要引出大端、小端的知识。
大端与小端也是有起源的:
大小端之争的起源故事来自于Jonathan Swift的《格利佛游记》中的一个虚构情节。故事中有两个虚构的小人国,分别是Lilliput(利立浦特)和Blefuscu(不来夫斯库)。
原本,两国人民吃鸡蛋的方式都是从鸡蛋较大的一端开始。然而,有一天,Lilliput国的皇帝祖父小时候在按这种方式吃鸡蛋时,不小心把手指弄破了。因此,他的父亲,也就是当时的皇帝,颁布了一项法令,规定全体臣民在吃鸡蛋时必须先打破鸡蛋较小的一端,违令者将受到重罚。
这项法令在Lilliput国内引起了极大的不满和反抗,导致发生了多次叛乱。其中一个皇帝因此送了命,另一个丢了王位。而叛乱的原因之一,是Blefuscu国的国王大臣们煽动起来的。叛乱平息后,许多流亡者逃到了Blefuscu国寻求避难。
这个故事实际上是对当时英国和法国之间持续冲突的讽刺。之后,Danny Cohen,一位网络协议的早期开创者,第一次用大端、小端来表示字节的存储顺序,随后就被广泛的接纳了。
那么,到底什么是大端与小端呢?
大端(存储)模式:是指 数据的低位 保存在 内存的高地址 中,而 数据的高位 , 保存在内存的低地址 中;小端(存储)模式:是指 数据的低位 保存在 内存的低地址 中,而 数据的高位 ,, 保存在内存的高地址 中。
依旧拿着上面的 int x来说:
假设 x 的十六进制值为0x 11 22 33 44 <32位>,存储字节为:<0x101 0x102 0x103 0x104>
大端法:
| 0x101 | 0x102 | 0x103 | 0x104 | ||
| ............. | 11 | 22 | 33 | 44 | ............ |
小端法:
| 低位...... | 0x101 | 0x102 | 0x103 | 0x104 | ......高位 |
| ............. | 44 | 33 | 22 | 11 | ............ |
解释:
内存中存储是,至左向右,地址依次增加。即 左为低地址,右为高地址。
而 数据 ,与内存刚刚好相反。 左为高位,右为低位。(例如1001各个数字所对应的位数为:千 百 十 一,明显,千位数要高于百位数,依次类推)
巧记:“大端低高,小端高低”,即大端存储方式下,低位地址存放高位字节;小端存储方式下,低位地址存放低位字节。、
那么,为什么有大小端之分呢?
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8 bit。但是在C语言中除了8 bit 的char之外,还有16 bit的short 型,32 bit的long型(要看具体的编译器)另外,对于位数大于8位的处理器,例如16位或者32 位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因 此就导致了大端存储模式和小端存储模式。
我在此处就不展开去深入讲解这部分知识,有兴趣的读者可以去《深入理解计算机系统》这本书,里面会涉及到在各个不同的编译器,环境下,存储方式之差以及移植所带来的困惑。
对于这部分内容,需要慢慢去吃透,对以后的内存如何运作有所帮助。
二:浮点型数据在内存中的存储
浮点数,例如3.14 、1.12e10、 π 等等,我们都会说,使用浮点数会有失精度。为什么呢?
浮点数家族包括: float、double、long double 类型。浮点数表示的范围:float.h中定义
例子:
int main()
{
int n = 9;
float *p = (float *)&n;
printf("n的值为:%d\n",n);
printf("*p的值为:%f\n",*p);
*p = 9.0;
printf("num的值为:%d\n",n);
printf("*p的值为:%f\n",*p);
return 0;
}运行结果:
n的值为:9
*p的值为:0.000000
num的值为:1091567616
*p的值为:9.000000
接下来我将带着读者来了解,浮点数在内存中是如何存储的。
浮点数存储规则
根据国际标准IEEE(电气和电子工程协会) 754,任意一个二进制浮点数V可以表示成下面的形式: V = (-1)^S * M * 2^E
(-1)^S表示符号位,当S=0,V为正数;当S=1,V为负数。
M表示有效数字,大于等于1,小于2.
2^E表示指数位。

而对于指数位E,具有特殊的含义:
| 指数位E | 有效数字M==0 | 有效数字M!=0 |
| 0 | 正负0 | 次正常数字(失去精度的) |
| 1-254 | 正常数字 | 正常数字 |
| 255 | 正负无穷 | NaN(非常规数字) |
参考文献:
《哈喽!算法》:Hello 算法
《深入理解计算机系统》















 8360
8360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









