






其他源码获取可以看首页:代码老y
个人简介:专注于毕业设计项目定制开发:springboot+vue系统,Java微信小程序,javaSSM系统等技术开发,并提供远程调试部署、代码讲解、文档指导、ppt制作等技术指导。源码获取,毕设定制文章末尾查看联系方式
技术范围:SpringBoot、Vue、SSM、Nodejs、小程序等设计与开发。
本人负责:系统功能设计、毕设开题报告的撰写、任务书的制定、中期检查PPT的制作、系统功能的具体实现、论文的撰写与辅导以及长期的答辩答疑辅导。大家在毕设选题,项目以及论文编写等相关问题都可以和我沟通,我会尽自己所能给大家解答。
感兴趣的同学可在文末获取联系
1、开发相关技术介绍
1.1 SpringBoot框架
SpringBoot 是由 Pivotal 团队开发的开源 Java 基础框架,旨在简化 Spring 应用的初始搭建以及开发过程。它通过提供一系列的“Starters”来自动配置 Spring 及其集成的第三方库,极大地降低了开发者的配置难度。SpringBoot 应用通常可以独立运行,通常打包成 JAR 文件,内置了如 Tomcat、Jetty 或 Undertow 等 Web 服务器,无需外部 Servlet SpringBoot 提倡使用 Java 注解 来优化配置流程,简化了设置步骤。此外,它还包含了一些高级的监控和管控工具,特别是 Actuator 模块,它让开发者能够方便地追踪应用程序的运行状况和性能表现。这些特点使得 SpringBoot 成为开发微服务和云应用的优选,同样适用于企业级应用。
1.2 Vue框架
Vue 是一款专为构建动态和响应式的用户界面而设计的渐进式前端框架。Vue 在与一些更为庞大和全面的框架相比之中以其轻量级和模块化的特性脱颖而出,它的核心专注于视图层的构建,这样降低学习曲线的同时也便于与现有的项目或库进行无缝集成。 Vue 的设计理念强调简洁性和实用性,使开发者可以逐步地将框架的功能集成到项目中,不管是构建小型的交互界面还是处理大型应用,Vue 均能提供强大的功能支持。这种灵活性和易用性使前端开发更加高效和灵活,也是 Vue 受到广泛欢迎的关键因素之一。
1.3 MySQL数据库
MySQL 数据库是一个使用 SQL 作为查询语言的开源关系型数据库管理系统。这个系统一开始是 MySQL AB 公司所开发的,之后经历了 Sun Microsystems 的收购,最终成为 Oracle 公司旗下的产品。MySQL 因其出色的性能、可靠性和用户友好的特性而受到青睐,正因如此它也被广泛地应用于网站开发、数据存储解决方案和企业级软件系统中。它不但支持多种操作系统,而且还功能丰富且配置灵活,基本上都能满足从小型应用到大型数据仓库的需求,也正因如此是众多开发者和企业第一个选择的数据库解决方案。
1.4 协同过滤算法
协同过滤算法 通常是用于个性化推荐,继而通过分析用户行为进行相关推荐。可以分为用户基础和项目基础两种,用户基础协同过滤推荐相似用户喜欢的内容;项目基础协同过滤推荐相似项目。此算法提升推荐准确性,帮助用户发现潜在兴趣点,增强体验。协同过滤算法在解决新用户或新内容的冷启动问题上具有明显优势,能够为这些新元素提供初步的个性化推荐然后提高推荐系统的整体性能和用户体验。该算法广泛应用于多个推荐平台,如电商网站的产品推荐、音乐和视频流媒体服务的内容推荐等。
2、数据库表设计(展示部分表)
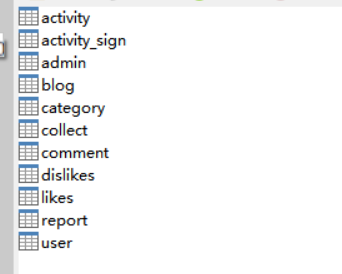
- 用户表(user),用于存放论坛用户的个人信息。
| 字段名 | 数据类型 | 主键/允许空 | 字段含义 |
| id | int | PRIMARY KEY | 用户ID |
| username | varchar | NULL | 用户名 |
| password | varchar | NULL | 密码 |
| name | varchar | NULL | 姓名 |
| avatar | varchar | NULL | 用户头像 |
| role | varchar | NULL | 用户角色 |
| sex | varchar | NULL | 性别 |
| phone | varchar | NULL | 手机号 |
| | varchar | NULL | 邮箱 |
| info | varchar | NULL | 个人简介 |
| birth | varchar | NULL | 生日 |
2.管理员表(admin),用来存放管理员的个人信息。
| 字段名 | 数据类型 | 主键/允许空 | 字段含义 |
| id | int | PRIMARY KEY | 管理员ID |
| username | varchar | NULL | 管理员名 |
| password | varchar | NULL | 管理员密码 |
| name | varchar | NULL | 管理员昵称 |
| avatar | varchar | NULL | 管理员头像 |
| role | varchar | NULL | 管理员个人简介 |
| phone | varchar | NULL | 手机号 |
| | varchar | NULL | 邮箱 |
3.帖子分类表(category),用来存放帖子分类信息。
| 字段名 | 数据类型 | 主键/允许空 | 字段含义 |
| id | int | PRIMARY KEY | 分类ID |
| name | varchar | NULL | 分类名称 |
4.喜欢表(likes),用来存放被用户喜欢的帖子或活动的信息。
| 字段名 | 数据类型 | 主键/允许空 | 字段含义 |
| id | int | PRIMARY KEY | ID |
| fid | int | NULL | 帖子关联ID |
| module | varchar | NULL | 模块 |
| user_id | int | NULL | 点赞人ID |
3、协同过滤算法实现
本高校在线论坛系统的推荐内容模块旨在通过协同过滤算法来分析用户对论坛帖子的各种互动行为,如点赞、收藏和评论,从而识别并推荐用户可能感兴趣的相关帖子。该模块的核心是基于物品的协同过滤算法,它通过计算帖子之间的相似性来推荐用户可能喜欢的其他帖子。具体来说,推荐过程包括以下几个步骤:
-
用户行为数据的采集:系统首先收集用户对论坛帖子的各种互动行为数据,这些数据反映了用户对不同类型帖子的偏好。
-
相似度计算:接着,算法计算不同帖子之间的相似度。在本系统中,我们采用余弦相似度作为相似度计算方法。余弦相似度通过测量两个向量间的夹角的余弦值来确定它们是否指向同一方向,从而计算用户之间的相似度或物品之间的相似度。这种方法在推荐系统中广泛应用,尤其是在文本分析领域。
-
推荐列表的生成:系统根据帖子间的相似度为每位用户生成个性化的推荐列表。系统会识别与用户过去互动过的帖子相似的其他帖子,并根据相似度得分进行排序,优先推荐相似度得分高的帖子。
-
推荐内容的展示:最终,系统在用户的推荐页面上展示这些经过个性化筛选的帖子,使用户能够便捷地访问可能吸引他们的内容。这种个性化推荐机制不仅优化了用户体验,还增加了论坛内容的曝光率和互动性,提升了用户的参与度和论坛的吸引力。
package com.example.service;
import com.example.entity.Blog;
import com.example.entity.User;
import com.example.mapper.BlogMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.stream.Collectors;
@Service
public class RecommendationService {
@Autowired
private BlogMapper blogMapper;
@Autowired
private BlogService blogService;
/**
* 为指定用户生成帖子推荐。
* @param userId 用户ID
* @param numRecommendations 需要生成的推荐数量(至少20个)
* @return 推荐帖子的列表
*/
public List<Blog> recommendBlogs(Long userId, int numRecommendations) {
// 确保推荐数量至少为20
numRecommendations = Math.max(numRecommendations, 20);
// 获取用户点赞或评论的帖子
// List<Blog> interactedBlogs = blogMapper.findBlogsByUserInteractions(userId);
//获取用户点赞或收藏或评论的帖子
List<Blog> interactedBlogs = blogMapper.findBlogsByUserActivities(userId);
// 计算帖子之间的相似度矩阵
Map<Blog, Map<Blog, Double>> similarityMap = calculateSimilarityMatrix(interactedBlogs);
// 生成推荐
List<Blog> recommendations = generateRecommendations(interactedBlogs, similarityMap, numRecommendations);
// 如果推荐数量不足20个,补充热门帖子或其他相关帖子
if (recommendations.size() < numRecommendations) {
recommendations = supplementWithPopularBlogs(recommendations, numRecommendations);
}
return recommendations;
}
/**
* 计算帖子之间的相似度矩阵。
* @param blogs 帖子列表
* @return 帖子之间的相似度矩阵
*/
private Map<Blog, Map<Blog, Double>> calculateSimilarityMatrix(List<Blog> blogs) {
Map<Blog, Map<Blog, Double>> similarityMap = new HashMap<>();
// 先初始化所有 blog,确保它们有 key,即使没有相似项
for (Blog blog : blogs) {
similarityMap.putIfAbsent(blog, new HashMap<>());
}
for (int i = 0; i < blogs.size(); i++) {
for (int j = i + 1; j < blogs.size(); j++) {
double similarity = calculateCosineSimilarity(blogs.get(i), blogs.get(j));
similarityMap.get(blogs.get(i)).put(blogs.get(j), similarity);
similarityMap.get(blogs.get(j)).put(blogs.get(i), similarity);
}
}
return similarityMap;
}
/**
* 计算两个帖子之间的余弦相似度。
* @param blog1 第一个帖子
* @param blog2 第二个帖子
* @return 两个帖子之间的余弦相似度
*/
private double calculateCosineSimilarity(Blog blog1, Blog blog2) {
Set<User> users1 = new HashSet<>(blog1.getLikers());
users1.addAll(blog1.getCommenters());
Set<User> users2 = new HashSet<>(blog2.getLikers());
users2.addAll(blog2.getCommenters());
Set<User> intersection = new HashSet<>(users1);
intersection.retainAll(users2);
Set<User> union = new HashSet<>(users1);
union.addAll(users2);
// 计算余弦相似度
return intersection.size() / (double) union.size();
}
/**
* 根据计算出的相似度生成推荐帖子列表。
* @param interactedBlogs 用户互动过的帖子列表
* @param similarityMap 帖子相似度矩阵
* @param numRecommendations 需要生成的推荐数量
* @return 推荐帖子的列表
*/
private List<Blog> generateRecommendations(List<Blog> interactedBlogs, Map<Blog, Map<Blog, Double>> similarityMap, int numRecommendations) {
Map<Blog, Double> scores = new HashMap<>();
for (Blog blog : interactedBlogs) {
for (Map.Entry<Blog, Double> entry : similarityMap.get(blog).entrySet()) {
Blog similarBlog = entry.getKey();
double score = entry.getValue();
scores.merge(similarBlog, score, Double::sum);
}
}
// 根据分数排序并选择分数最高的帖子作为推荐
return scores.entrySet().stream()
.sorted(Map.Entry.<Blog, Double>comparingByValue().reversed())
.limit(numRecommendations)
.map(Map.Entry::getKey)
.collect(Collectors.toList());
}
/**
* 如果推荐数量不足,补充热门帖子或其他相关帖子。
* @param currentRecommendations 当前推荐列表
* @param numRecommendations 需要达到的推荐数量
* @return 补充后的推荐列表
*/
private List<Blog> supplementWithPopularBlogs(List<Blog> currentRecommendations, int numRecommendations) {
// 获取热门帖子(假设有一个方法可以获取热门帖子)
List<Blog> popularBlogs = blogService.selectTop();
// 确保补充的帖子不在当前推荐列表中
Set<Blog> existingBlogs = new HashSet<>(currentRecommendations);
List<Blog> filteredPopularBlogs = popularBlogs.stream()
.filter(blog -> !existingBlogs.contains(blog))
.limit(numRecommendations - currentRecommendations.size())
.collect(Collectors.toList());
// 合并当前推荐和补充的热门帖子
List<Blog> combinedRecommendations = new ArrayList<>(currentRecommendations);
combinedRecommendations.addAll(filteredPopularBlogs);
return combinedRecommendations;
}
}
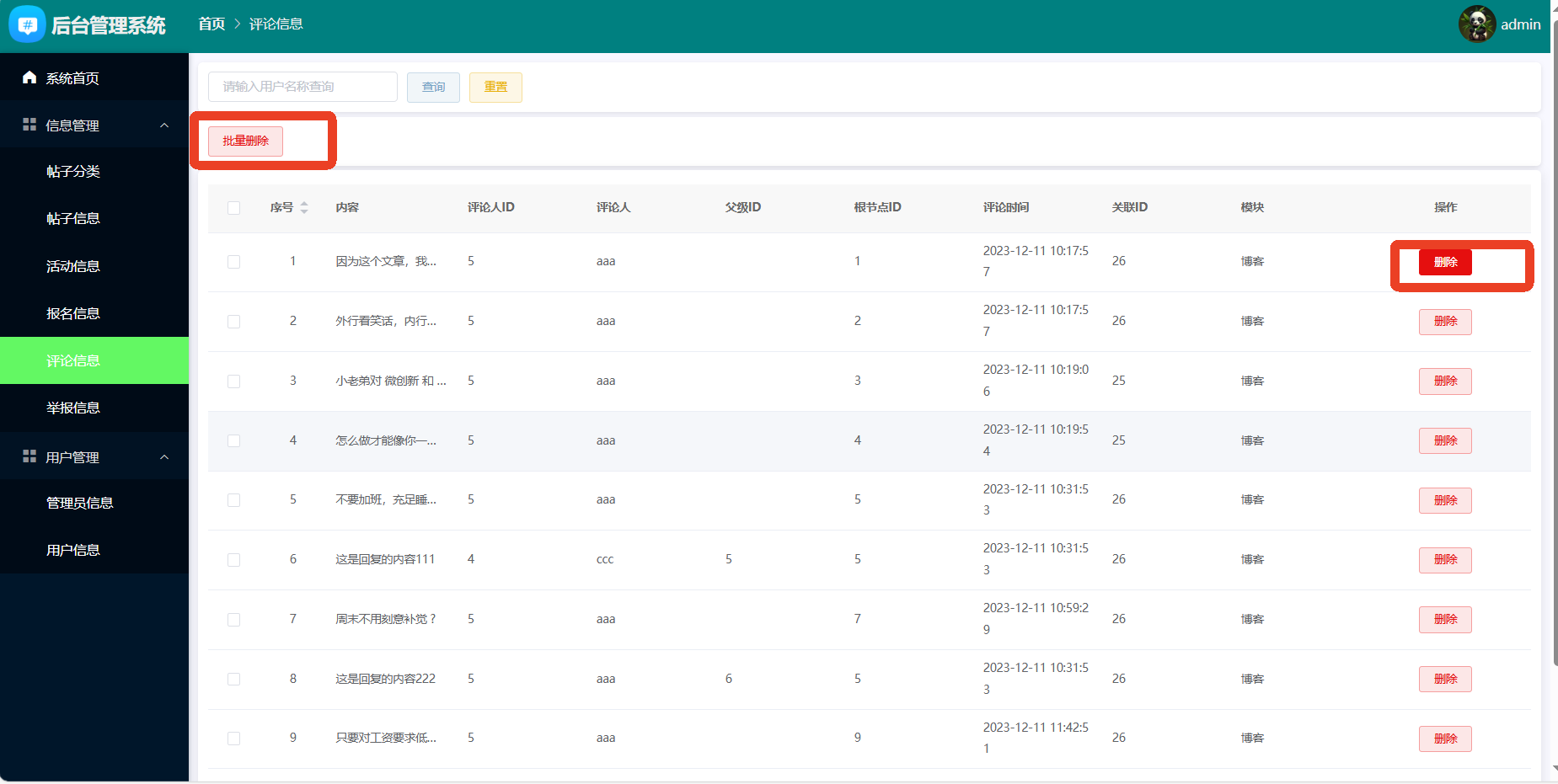
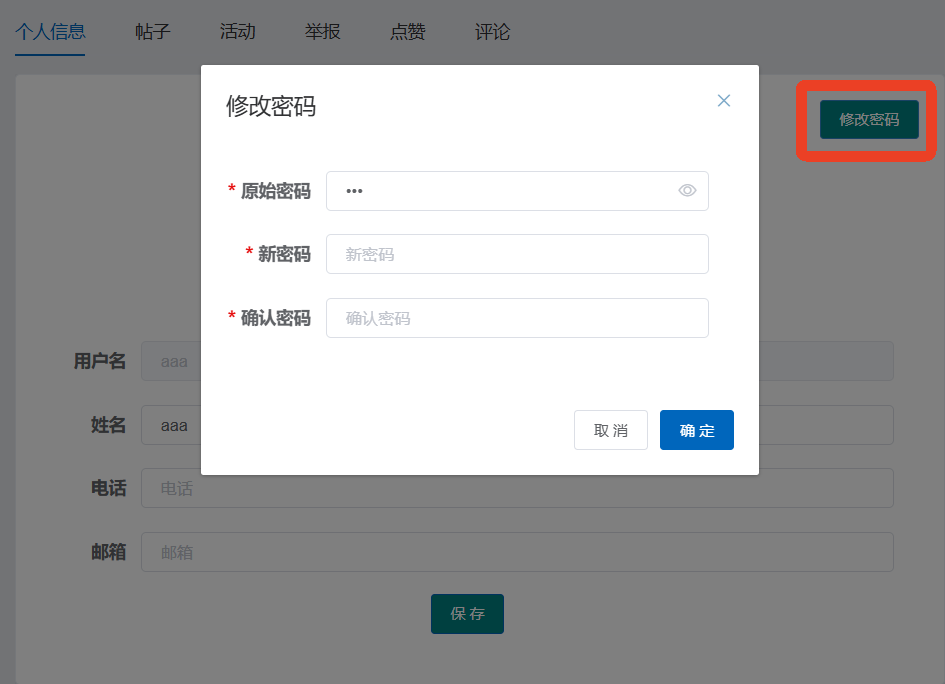
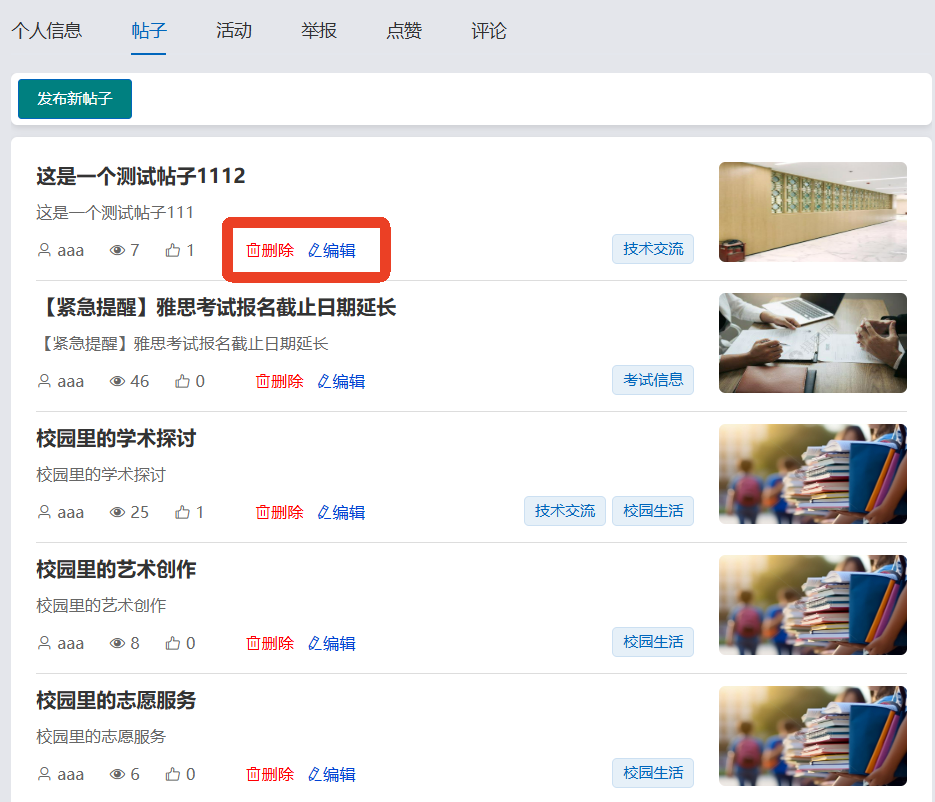
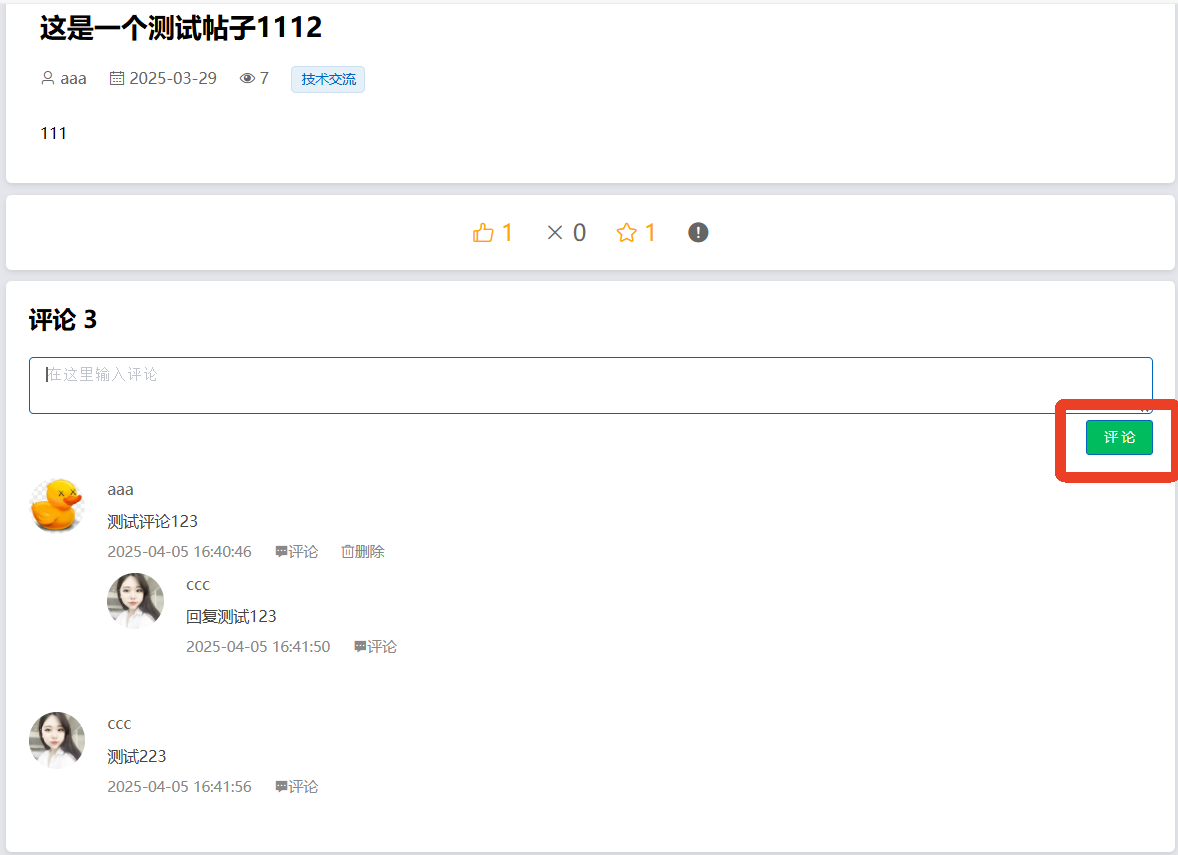
4、系统实现部分截图
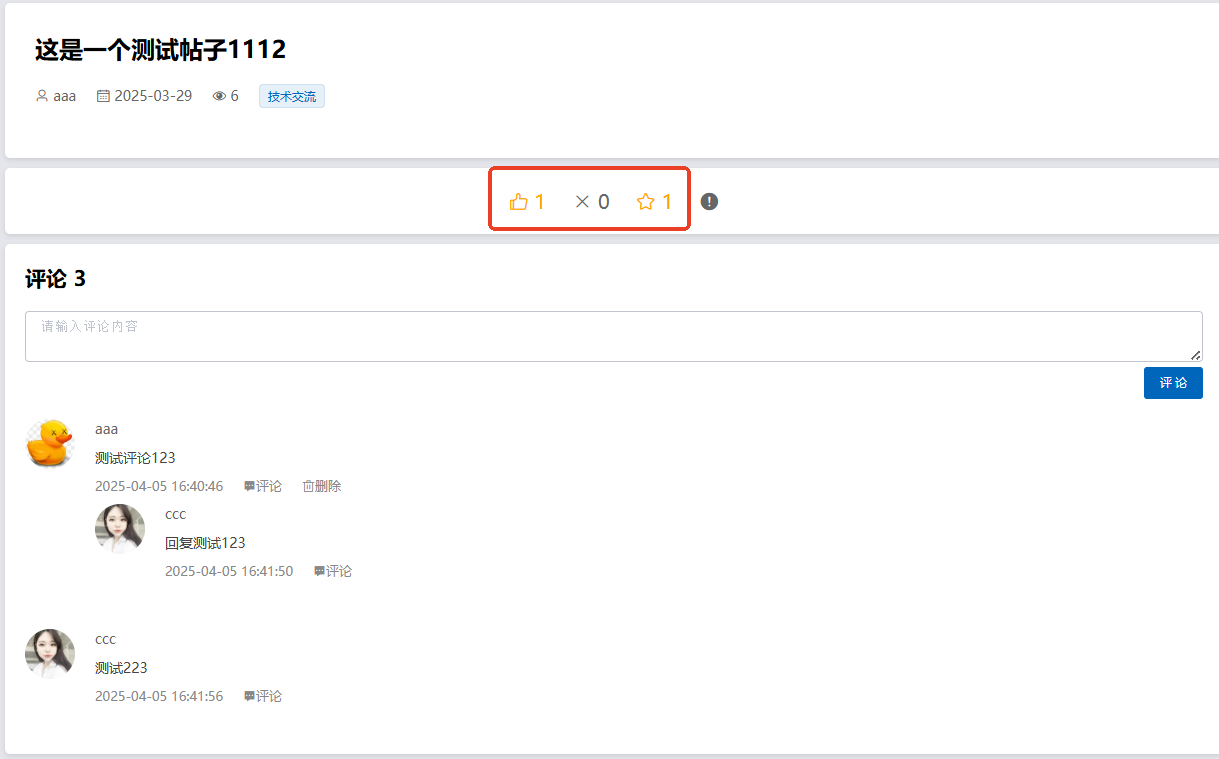
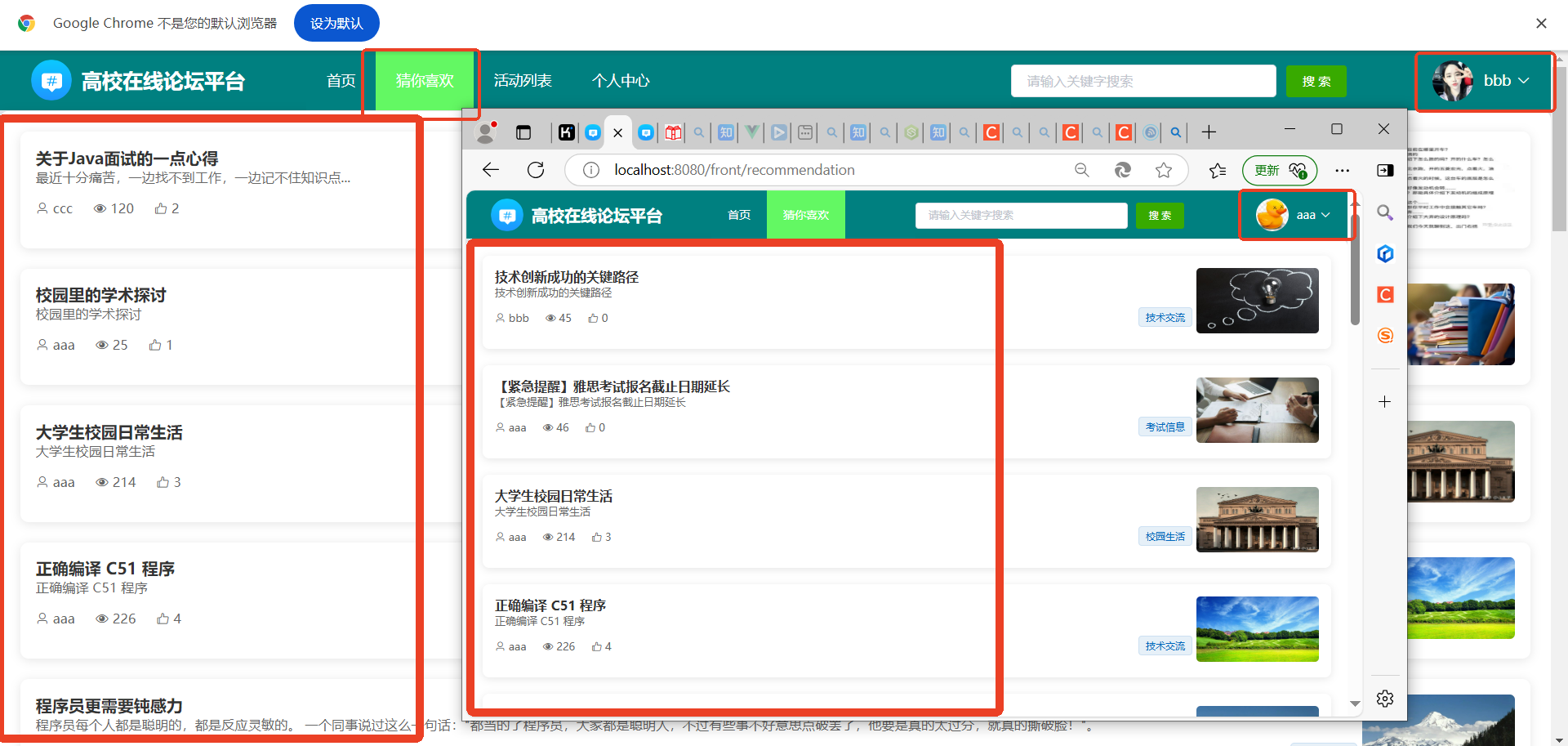
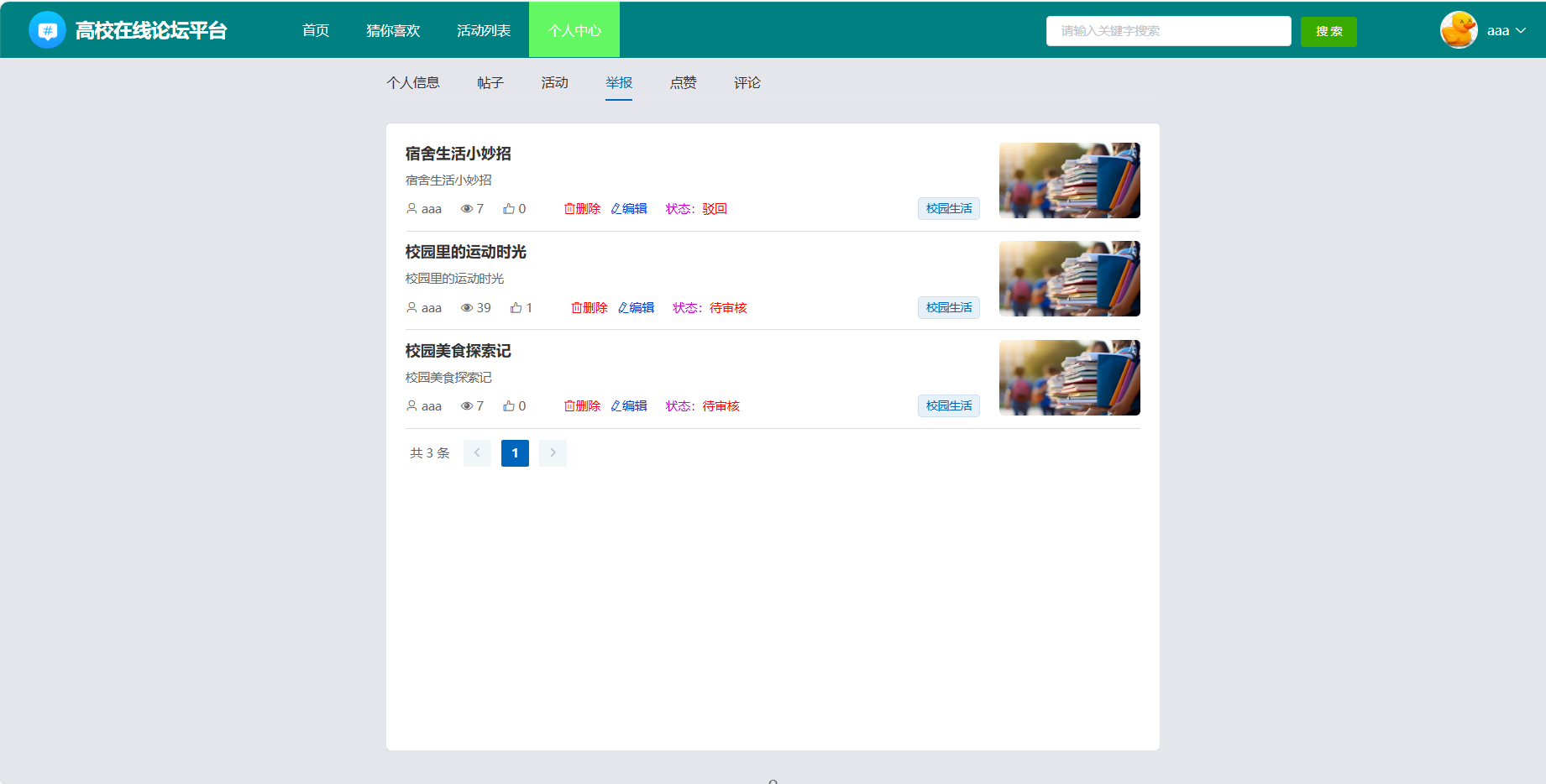
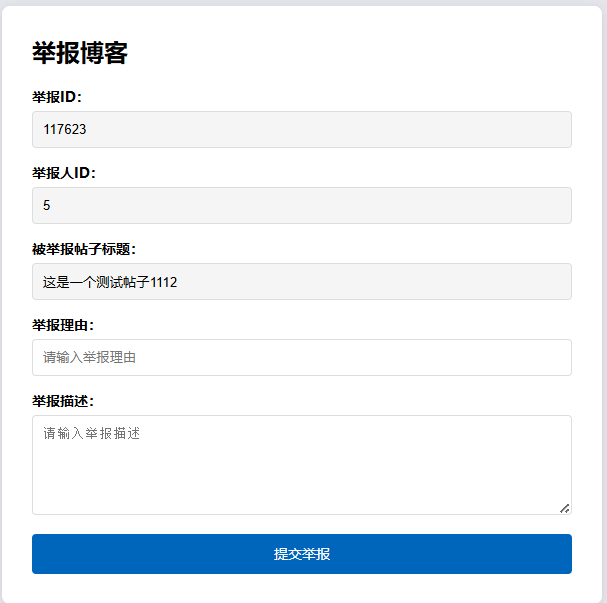
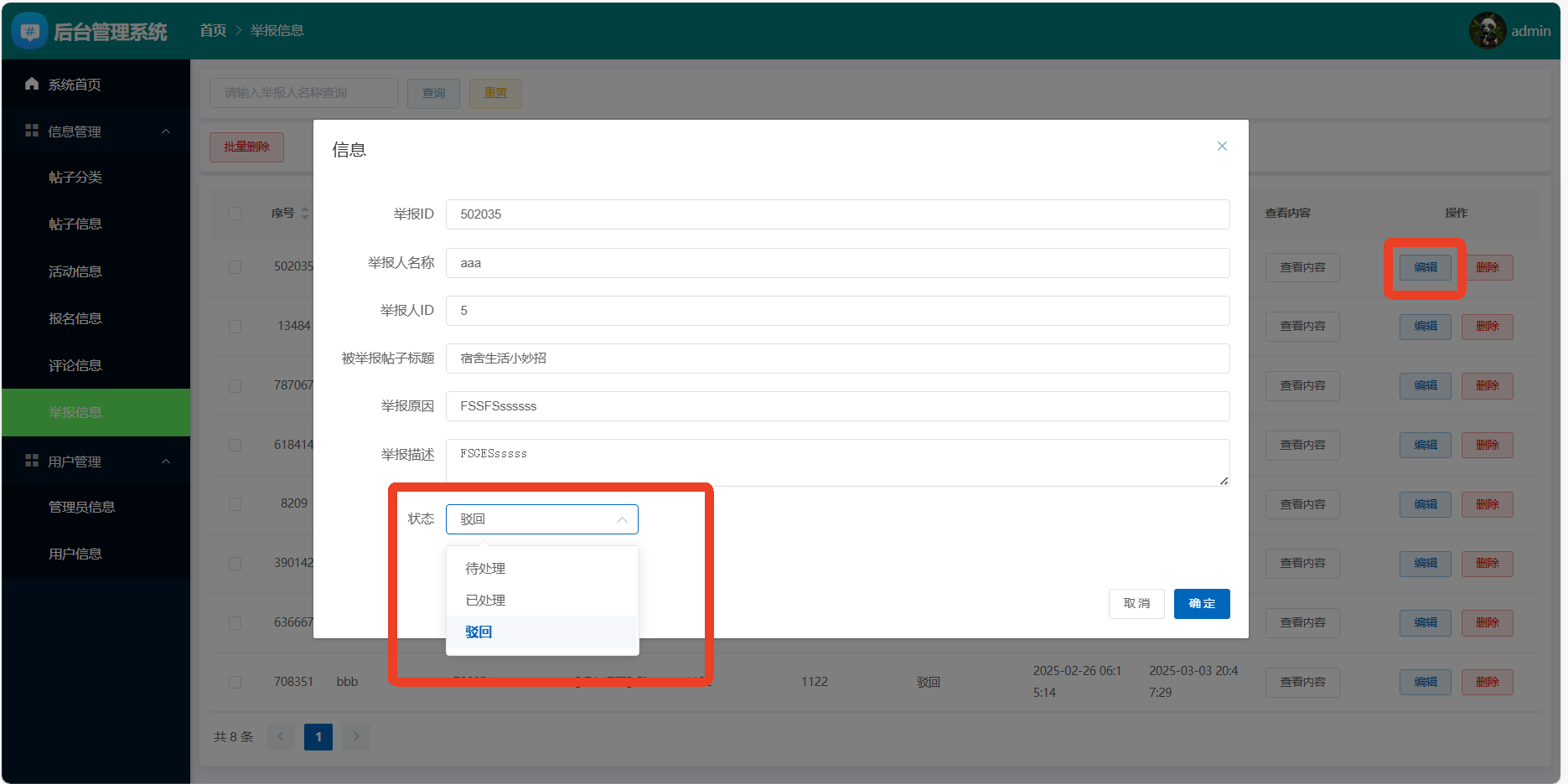
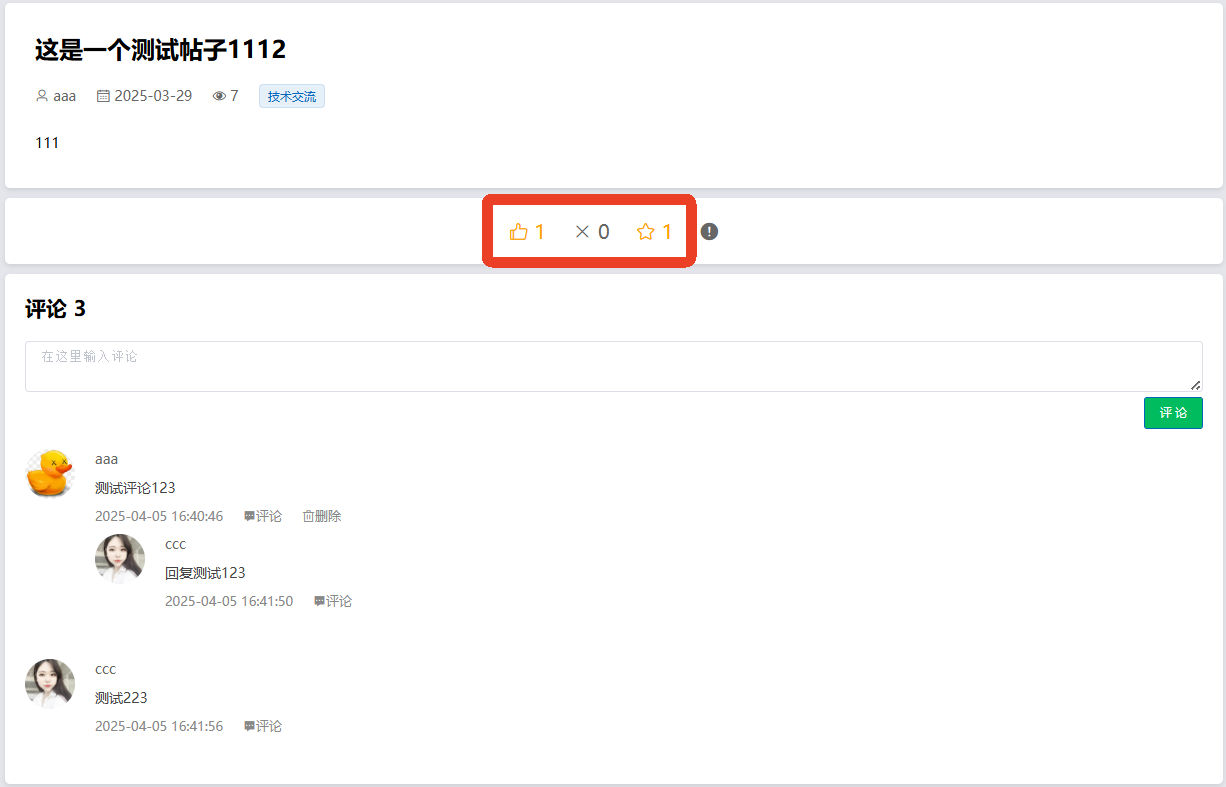
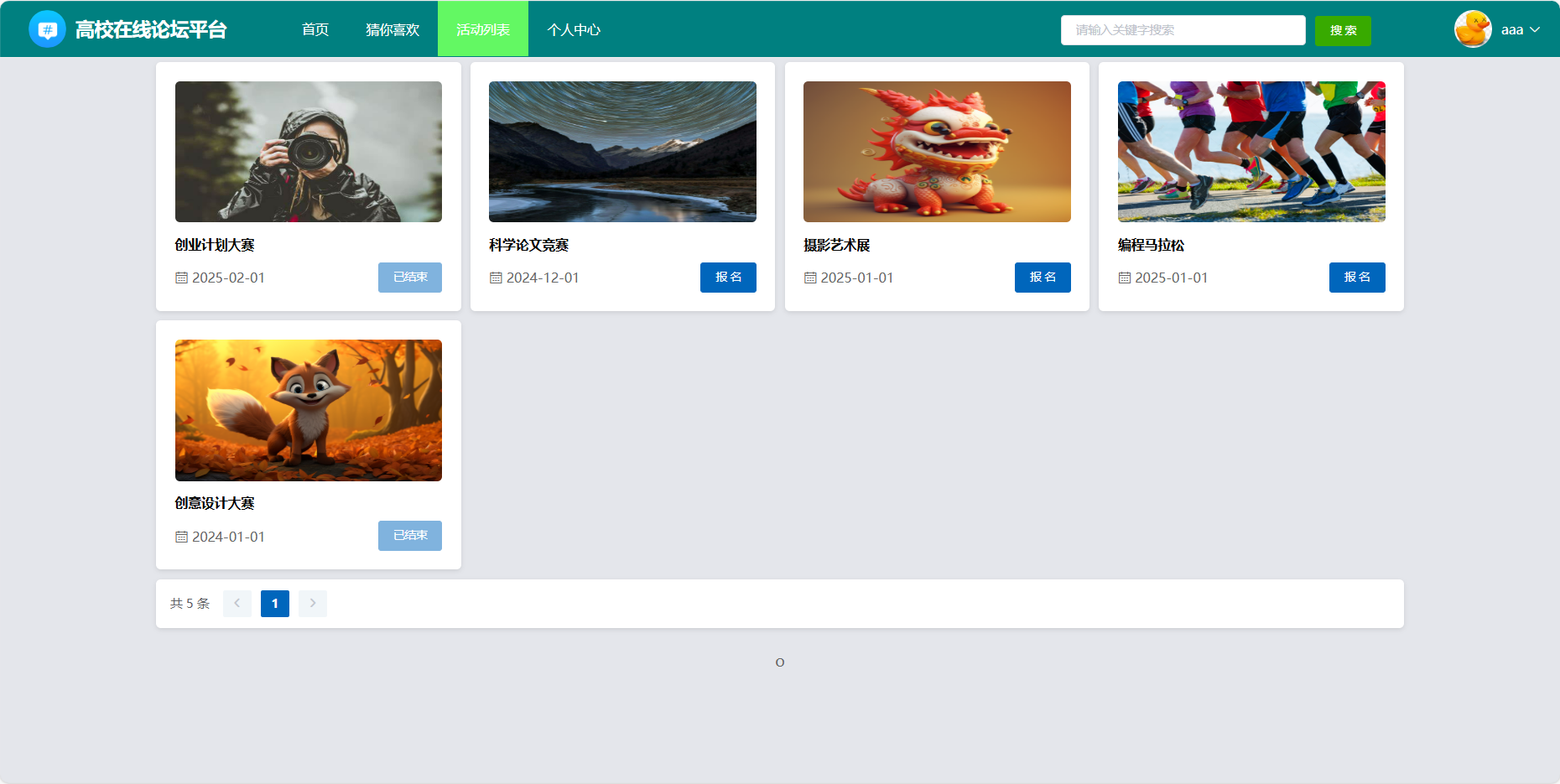
源码获取
谢谢大家点赞、收藏、关注、评论,👇🏻获取联系方式👇🏻
2420178212@qq.com


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









