






目录
6.1 settings.py增加日志记录部分,记录执行的SQL语句
1 ORM简介
ORM:对象关系映射(Object Relationl Mapping),用面向对象的方式去操作数据库的表,实现面向对象编程语言里不同类型系统的数据之间的转换。
优点:不用写复杂的SQL语句,避免新手写SQL带来的性能问题。
缺点:性能有所牺牲。
# 通过QuerySet的query属性查询对应操作的SQL语句
obj = models.Author.objects.filter(id = 1)
print(obj.query)2 创建表
在Django项目的models.py文件中通过创建类来创建表。
一对一(OneToOneField):一般用于某张表的补充,可以方便的从子表查询母表信息或反向查询。
一对多(ForeignKey):创建一对多关系,比如一个班级有多个学生,则在学生表中创建关联到班级的一对多外键(学生表中创建cls = models.ForeignKey(),系统会生成cls_id字段);django2.0及以上版本在使用OneToOneField和ForeignKey时,需要加上on_delete参数。
多对多(ManyToManyField):创建多对多关系,比如一个班级有多位老师,一个老师教多个班级,则在其中任一表中创建多对多字段,系统会默认创建包含多对多关系的第三张表;也可以通过手动创建第三张关系表的方式建立多对多关系,但不能使用add、remove方法。
from django.db import models
class Students(models.Model):
name = models.CharField(max_length=100)
age = models.IntegerField()
# 建立Students和Classes的一对多关系
cls = models.ForeignKey('Classes', on_delete=models.CASCADE)
def __str__(self):
return self.name
class Classes(models.Model):
name = models.CharField(max_length=100)
# 建立Classes和Teachers的多对多关系
teach = models.ManyToManyField('Teachers')
def __str__(self):
return self.name
class Teachers(models.Model):
name = models.CharField(max_length=100)
def __str__(self):
return self.name
# 手动创建多对多关系表
class MyClassesToTeachers(models.Model):
classes = models.ForeignKey('Classes', on_delete=models.CASCADE)
teachers = models.ForeignKey('Teachers', on_delete=models.CASCADE)
# 创建联合唯一约束,根据实际需求添加此项
class Meta:
unique_together = ['classes', 'teachers']3 操作表
3.1 增
# 增加数据 方式1
models.Students.objects.create(name='张三', age=18)
# 增加数据 方式2
models.Students.objects.create(**{'name': '李四', 'birth': 18})
# 增加数据 方式3
student = models.Students(name='王五', birth=81)
student.save()
# 增加数据 方式4
student = models.Students()
student.name = '刘国庆'
student.age = 50
student.save()
# 一对多表中增加数据,示例Students表中创建了关联到Classes表的外键cls
models.Students.objects.create(name='张三1', age=18, cls_id=1)
# 一对多表中增加数据,示例Students表中创建了关联到Classes表的外键cls
class1 = models.Classes.objects.filter(id=1)
models.Students.objects.create(name='张三2', age=18, cls=class1[0])
# 多对多表中增加数据(正向),示例Classes表中创建了关联到Teachers表的多对多字段teach
teacher1 = models.Teachers.objects.filter(id=1)[0]
teacher2 = models.Teachers.objects.filter(id=2)[0]
class1 = models.Classes.objects.filter(id=1)[0]
class1.teach.add(teacher1, teacher2)
# 多对多表中增加数据(反向),示例Classes表中创建了关联到Teachers表的多对多字段teach
teacher = models.Teachers.objects.filter(id=1)[0]
classes = models.Classes.objects.filter(id__gt=1)
teacher.classes_set.add(*classes)3.2 删
# 方式1 delete() 级联删除,同时删除关系
obj = models.Students.objects.filter(id=1).delete()
print(obj)
# 打印内容 (1, {'app01.Students': 1})
obj = models.Teachers.objects.filter(id=1).delete()
print(obj)
# 打印内容 (3, {'app01.Classes_teacher': 2, 'app01.Teachers': 1}) 同时删除了关系表中的2条关系数据
#方式2 remove()
teacher = models.Teachers.objects.filter(id=1)[0]
classes = models.Classes.objects.filter(id__gt=0)
teacher.classes_set.remove(*classes)
#方式3 clear() 清空3.3 改
# 修改数据 方式1
student = models.Students.objects.get(id=1)
student.name = '王三'
student.save()
# 修改数据 方式2
models.Students.objects.filter(id=1).update(name='李三')
# 修改数据 方式3 .set()注意:
1 save()方法会更新一行里的所有列。
2 get()方法返回的是model对象,没有update方法;filter()返回的是QuerySet对象可以调用update()方法。
3.4 查
1 filter(**kwargs)
obj = models.Students.objects.filter(cls_id=1)
print(obj)
# 打印结果
<QuerySet [<Students: 李三>, <Students: 李四>, <Students: 张国庆>]>
2 all()
obj = models.Students.objects.all()
print(obj)
# 打印结果
<QuerySet [<Students: 李三>, <Students: 李四>, <Students: 王五>, <Students: 张国庆>]>
3 get(**kwargs) 返回一个model对象,符合筛选结果的对象超过1个或者没有都会报错。
obj = models.Students.objects.get(id=1)
print(obj)
# 打印结果
李三4 values(*field) 返回一个字典序列。
obj = models.Students.objects.filter(age=18).values('name')
print(obj)
# 打印结果
<QuerySet [{'name': '李三'}, {'name': '李四'}]>
5 values_list(*field) 返回一个元组序列。
obj = models.Students.objects.filter(age=18).values_list('name')
print(obj)
# 打印结果
<QuerySet [('李三',), ('李四',)]>6 exclude(**kwargs) 返回与筛选条件不符合的对象。
obj = models.Students.objects.exclude(id=1)
print(obj)
# 打印结果
<QuerySet [<Students: 李四>, <Students: 王五>, <Students: 张国庆>]>
7 order_by(*field) 对查询结果排序,加负号则是反向排序。
obj = models.Students.objects.order_by('-age')
print(obj)
# 打印结果
<QuerySet [<Students: 王五>, <Students: 张国庆>, <Students: 李三>, <Students: 李四>]>8 reverse() 对查询结果反向排序。
9 distinct() 从返回结果中剔除重复记录。
10 count() 返回数据库中匹配查询(QuerySet)的对象数量。
obj = models.Students.objects.filter(age=18)
print(obj.count())
# 打印结果
211 first() 返回第一条记录。
obj = models.Students.objects.filter(age=18).first()
print(obj)
# 打印结果
李三12 last() 返回最后一条记录。
13 exists() 如果QuerySet包含数据就返回True,否则返回False。
3.5 查询条件之双下划线
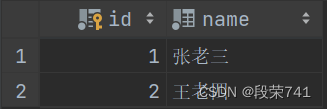
以下示例基于下表:依次是Students、Classes、Teachers。


1 id__gt 大于,id__lt 小于,id__gte 大于等于,id__lte 小于等于。
obj = models.Students.objects.filter(id__gt=1, id__lte=4)
print(obj)
# 打印结果
<QuerySet [<Students: 李四>, <Students: 王五>, <Students: 张国庆>]>2 id__in 匹配对应id值的数据。
obj = models.Students.objects.filter(id__in=[1, 3, 4])
print(obj)
# 打印结果
<QuerySet [<Students: 李三>, <Students: 王五>, <Students: 张国庆>]>3 name__contains 匹配包含对应字符的数据,name__icontains不区分大小写。
obj = models.Students.objects.filter(name__contains='张')
print(obj)
# 打印结果
<QuerySet [<Students: 张国庆>, <Students: 张三1>, <Students: 张三2>, <Students: 张三2>]>4 id__range 匹配对应范围内的数据。
obj = models.Students.objects.filter(id__range=[1, 4])
print(obj)
# 打印结果
<QuerySet [<Students: 李三>, <Students: 李四>, <Students: 王五>, <Students: 张国庆>]>5 name__startwith,name__endwith,name__istartwith,name__iendwith 匹配以对应字符开头、结尾的数据。
3.6 关联表查询
# 获取pathon一班的老师名字
names = models.Teachers.objects.filter(classes__name='python一班').values('name')
print(names)
# 打印结果
<QuerySet [{'name': '张老三'}, {'name': '王老四'}]>3.7 聚合查询和分组查询
aggregate(*args,**kwargs): 返回一个聚合值的字典,aggregate()中的每一个参数都制定一个包含在字典中的返回值。
annotate(*args,**kwargs):查询每个对象所关联的结果集合。
from django.db.models import Avg, Max, Min, Sum
ret = models.Students.objects.aggregate(Avg('age'), Max('age'), minimum_age=Min('age'))
print(ret)
# 打印结果 minimum_age=Min('age')可以指定返回值中的键名称
{'minimum_age': 18, 'age__avg': 31.5714, 'age__max': 81}
# 查询python一班所有学生的平均年龄
ret = models.Students.objects.filter(cls__name='python一班').aggregate(Avg('age'))
print(ret)
# 打印结果
{'age__avg': 18.0}
# 查询每个班级的平均年龄,以values()的结果进行分组并计算每个对象的统计结果
ret = models.Students.objects.values('cls__name').annotate(Avg('age'))
print(ret)
# 打印结果
<QuerySet [{'cls__name': 'python一班', 'age__avg': 18.0}, {'cls__name': 'python二班', 'age__avg': 65.5}]>3.8 F查询和Q查询
from django.db.models import F, Q
# F:取某列的值进行操作
models.Students.objects.all().update(age=F('age')+1)
# Q:将单个条件包装成Q对象,通过逻辑运算符组合构造复杂的查询条件
# Q对象与关键字参数一起使用时,Q对象必须放在关键字参数的前面
obj = models.Students.objects.filter(Q(id__gt=1) & Q(age__lt=60) | ~Q(cls__name='python一班'))
print(obj)
# 打印结果
<QuerySet [<Students: 李四>, <Students: 王五>, <Students: 张国庆>, <Students: 张三1>, <Students: 张三2>, <Students: 张三2>]>
4 惰性机制
models.Students.objects.filter()等方法只是返回了一个QuerySet对象,它并不会马上执行SQL,而是当调用QuerySet的时候才执行。
QuerySet特点:可迭代,可切片
objs = models.Students.objects.all()
for obj in objs:
print(obj)
# 打印结果
李三
李四
王五
张国庆
objs = models.Students.objects.all()
print(objs[1:2])
# 打印结果
<QuerySet [<Students: 李四>]>
5 admin使用
5.1 简介
admin是Django提供的一个后台管理app
5.2 文件配置
# 终端
# 第1步 迁移数据库
python manage.py makemigrations
python manage.py migrate
# 第2步 创建用户名、密码
python manage.py createsuperuser
# 第3步 启动服务器
python manage.py runserver 8000
# 浏览器
# 第4步 浏览器访问http://127.0.0.1:8000/admin 输入账号、密码登录!# admin.py文件配置
from app01.models import *
# ModelAdmin是管理界面的定制类,如需扩展特定的model界面需从该类继承
class Myadmin(admin.ModelAdmin):
# 设置显示字段
list_display = ('name', 'age', 'cls')
# 设置搜索字段
search_fields = ('name',)
# 设置过滤器
list_filter = ('name',)
# 设置排序字段
ordering = ('-id',)
# 注册model类到anmin
admin.site.register(Students, Myadmin)# 字段设置
# verbose_name 设置字段的显示内容,如将‘name’显示为‘书名’
# editable 设置是否可编辑,默认为True
name = models.CharField(max_length=100, verbose_name='书名', editable=False)6 其他
6.1 settings.py增加日志记录部分,记录执行的SQL语句
# settings.py中添加代码
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level': 'DEBUG',
},
},
}
# views.py
objs = models.Teachers.objects.filter(id__gt=0)
for obj in objs:
print(obj)
# 执行结果
(0.000) SELECT `app01_teachers`.`id`, `app01_teachers`.`name` FROM `app01_teachers` WHERE `app01_teachers`.`id` > 0; args=(0,); alias=default
张老三
王老四
# 执行第一遍for循环时会将数据放入缓存,之后每次循环都在缓存内取数据;为避免缓存中放入大量数据,使用迭代器......(待补充)















 590
590











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









