







 本文介绍了MQ(消息队列)的概念、在应用解耦中的作用,如何通过异步处理加速响应时间,以及如何通过削峰填谷策略防止系统过载。MQ通过暂时存储和分发数据,优化了系统性能并增强了应用的稳定性。
本文介绍了MQ(消息队列)的概念、在应用解耦中的作用,如何通过异步处理加速响应时间,以及如何通过削峰填谷策略防止系统过载。MQ通过暂时存储和分发数据,优化了系统性能并增强了应用的稳定性。
1.什么是MQ?
MQ全称为 "Message Queue" 即消息队列,且 MQ 本身是不消费数据的,只是一个临时存储数据的容器;
那到底什么是MQ呢?到底是干什么的呢?
来....请看图



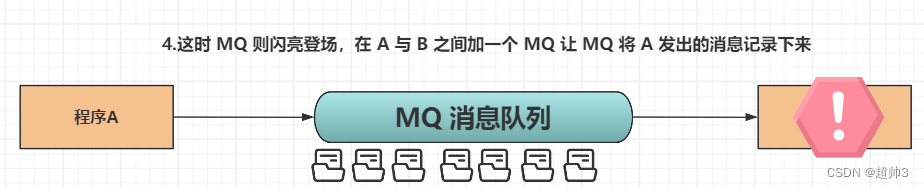

这时 A 在发送数据的时候就不用考虑 B 可不可用的问题,直接发送到 MQ 即可;
2.MQ 的应用解耦
还是以上图为例,当 A 向 B 发送数据的时候,在没有 MQ 的情况下 A 需要一直关注着 B 是否正常运行,如果 B 挂了,则 A 无法发送数据
当在 A B 两个程序之间,加入 MQ 之后,A 发送数据的时候,则不需要考虑 B 是否正常运行,一直发就行,而 B 则 直接从 MQ 中消费数据即可
这样就将 A 与 B 之间的必然关联性解除,实现应用的解耦
3.MQ 的异步加速
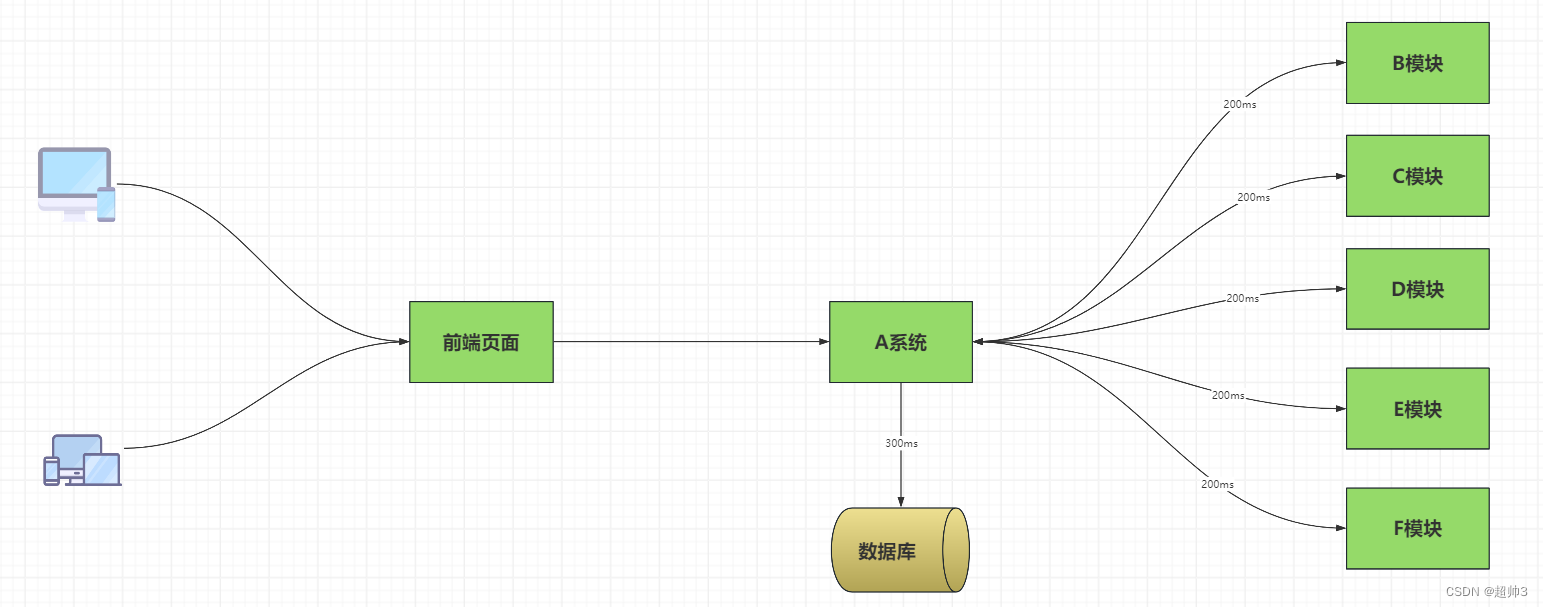
如图,当客户侧对 A 系统发起请求的后,A 系统需要往数据库进行写操作,耗时 300ms,还要往 B、C、D、E、F等5个模块写入,各耗时200ms,加上写入数据库的时间共有 200+200+200+200+200+300= 1300ms ,也就是 1.3s ,客户在1.3s后才能收到回应,这显然是很慢的。
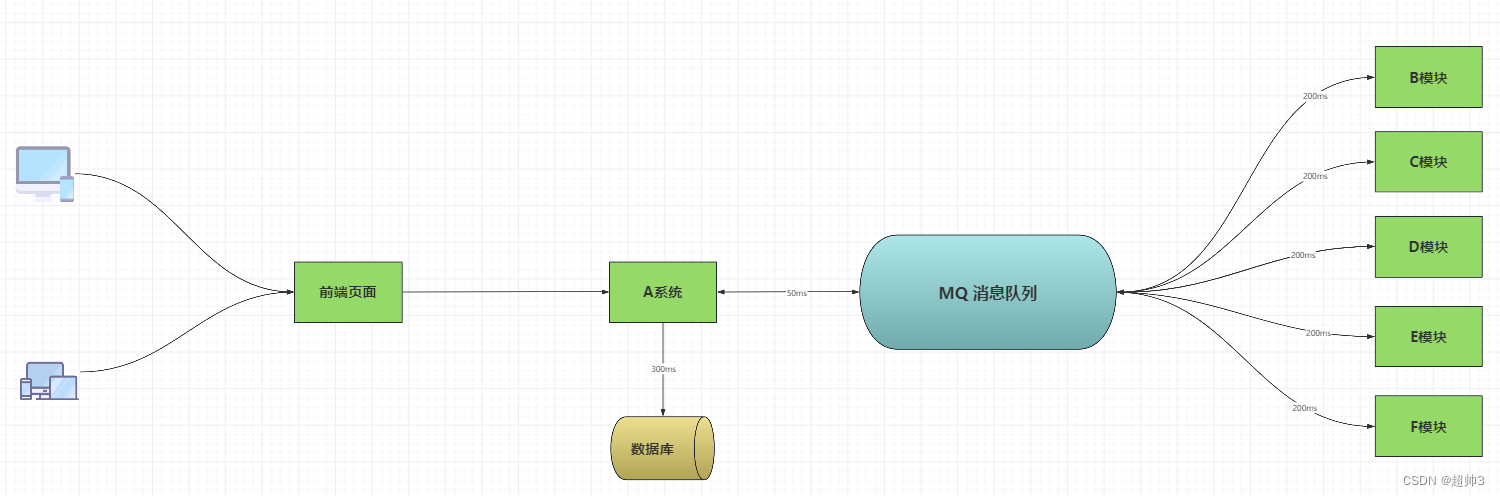
如图,在 A 系统与各个模块之间加一个MQ,则 A 系统将数据写入到 MQ 及数据库中后直接给客户回应,图中可以看出,A 系统写入 MQ 的时间为 35ms,写入数据库的时间为350ms,共计时间为 385 ms,与之前的1300毫秒,缩短了3倍多的时间。
4.MQ 的削峰填谷
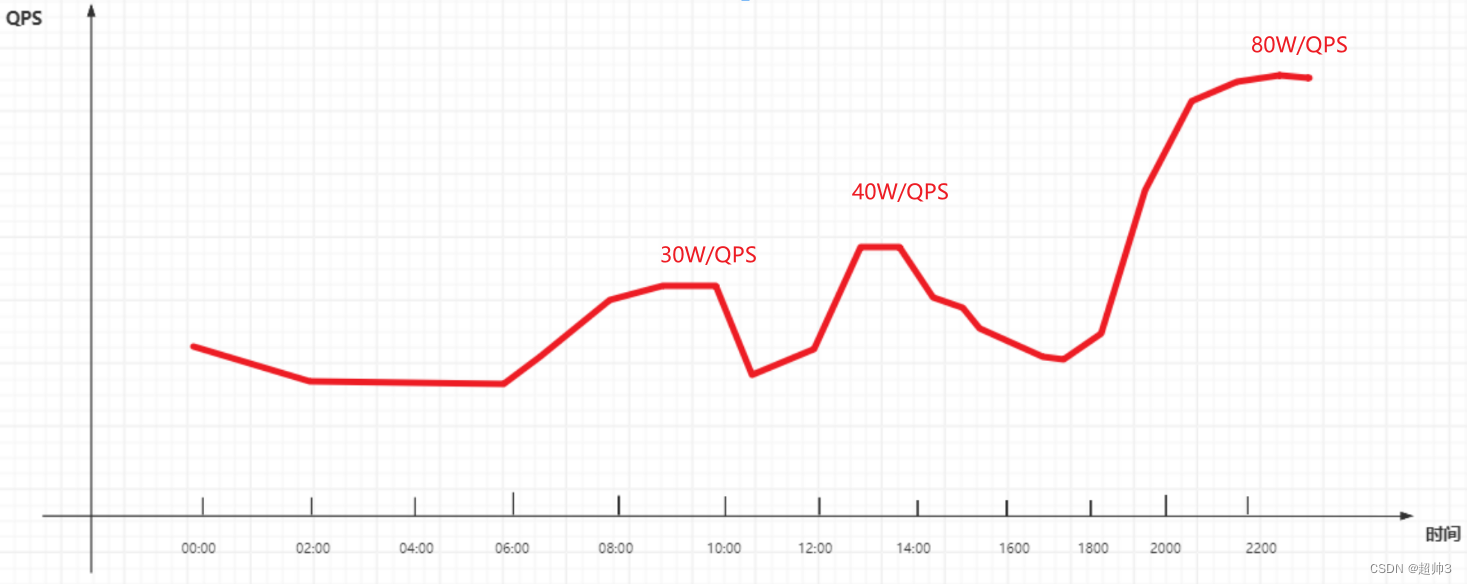
图为每个时间段的流量图,可以看出,每天大部分时间的QPS是在30W,只有两个时间段的QPS超过了30W。
下图可看到 A 系统处理请求的瓶颈在 30W/QPS,
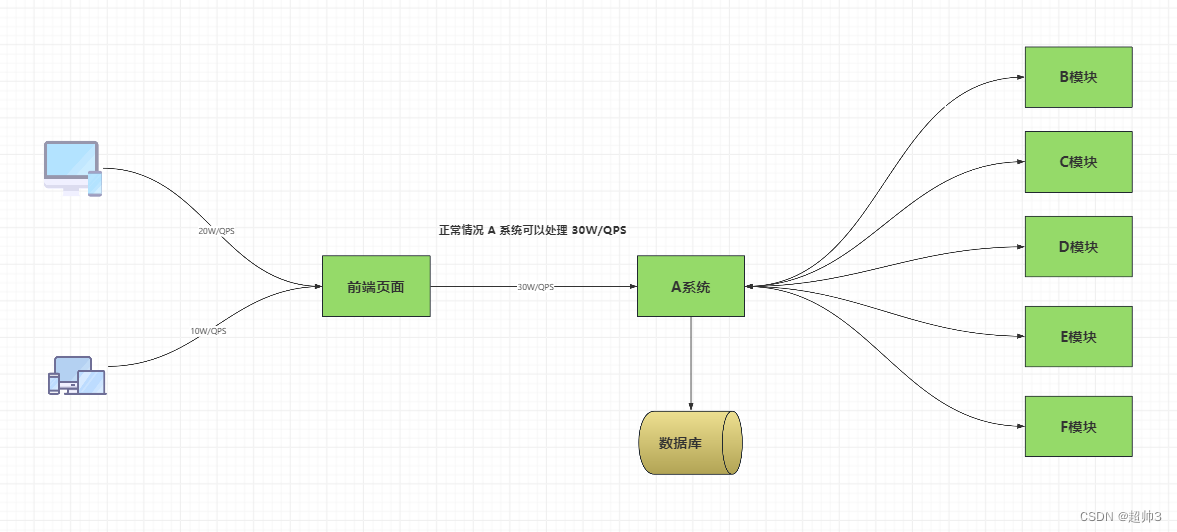
当请求达到 30W 以上,40W的时候,A 系统会因为承受不住这么大的流量,导致系统崩溃,此时整个生产线将会断裂,无法正常运转
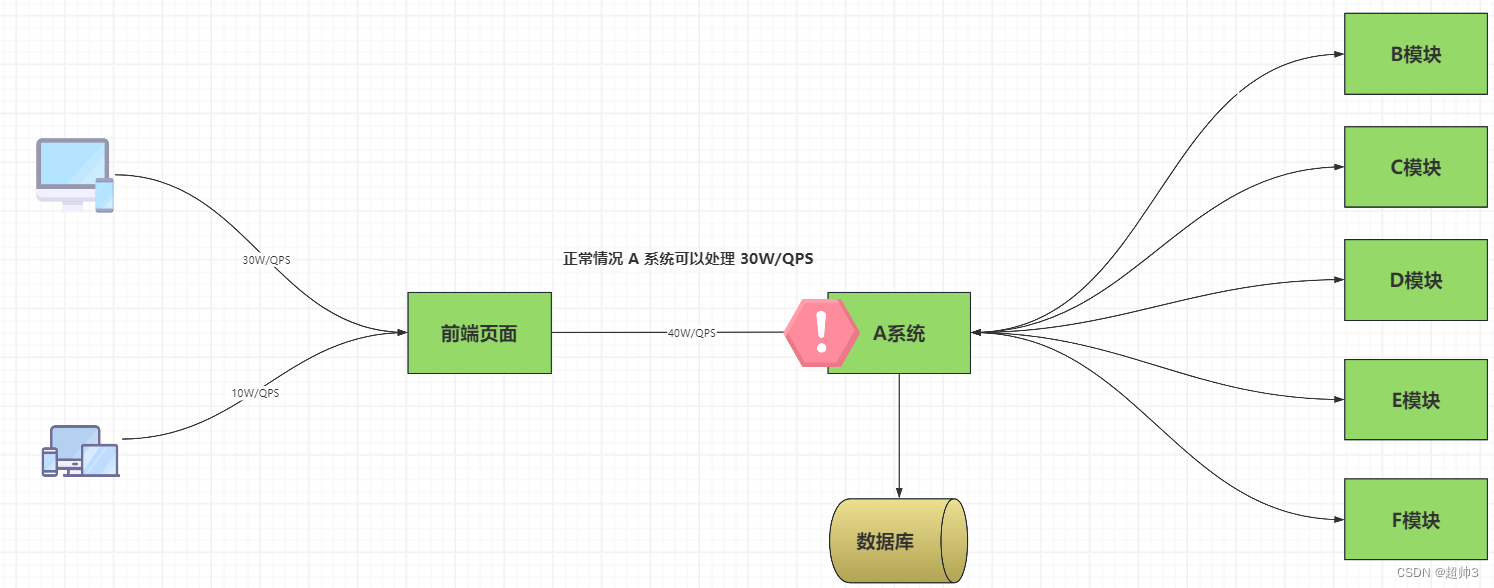
如下图:
在 A 系统前面加一个 MQ ,不管用户发送多少请求数据,都会被 MQ 接收进行临时存储,以备 A 系统读取,A 系统则可以一直处于 30W/QPS 的工作量,直到将 MQ 中存储的数据消费完。

这时 A 系统将不再直接面临客户发送大量请求数据,导致 A 系统的崩溃而影响到整个业务的运行。
这就是 MQ 的流量削峰,将峰值流量暂存到 MQ 中,等待业务系统消费。
交流平台,
有不当,望指出
有建议,请提出















 9106
9106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









