






文章目录
Dubbo
分布式基础理论
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统
单一应用架构
当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(ORM)是关键。
适用于小型网站,小型管理系统,将所有功能都部署到一个功能里,简单易用。
缺点:
- 性能扩展比较难
- 协同开发问题
- 不利于升级维护
垂直应用架构
当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的Web框架(MVC)是关键。
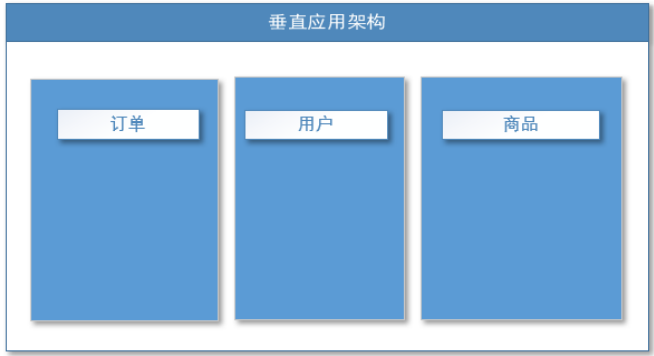
通过切分业务来实现各个模块独立部署,降低了维护和部署的难度,团队各司其职更易管理,性能扩展也更方便,更有针对性。
缺点: 公用模块无法重复利用,开发性的浪费
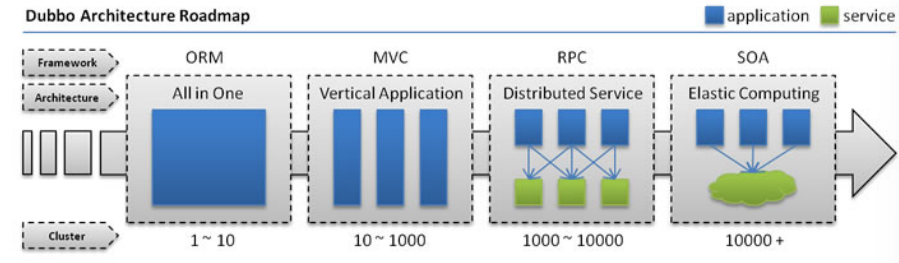
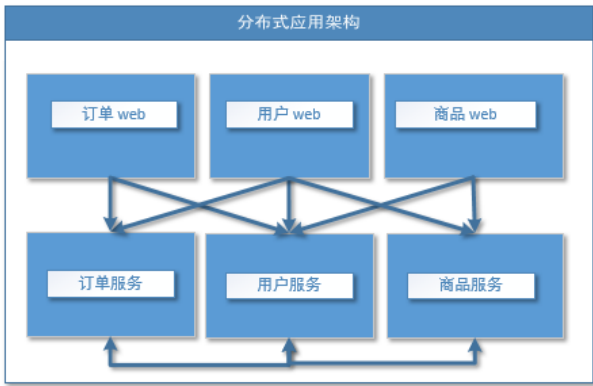
分布式服务架构
当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的**分布式服务框架(RPC)**是关键。
流动计算架构
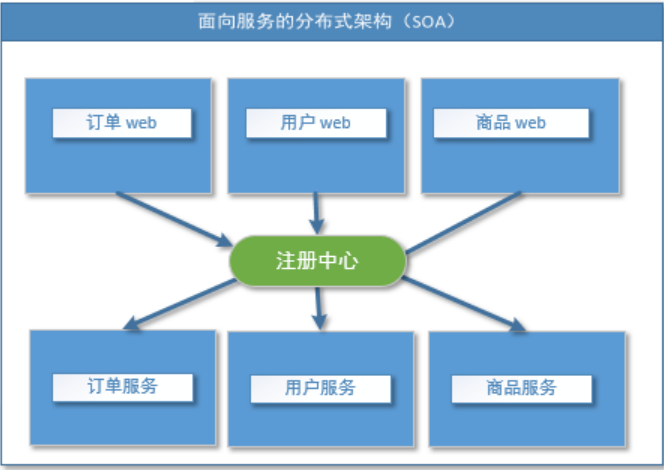
当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的资源调度和治理中心(SOA)[ Service Oriented Architecture]是关键。
RPC
概念:RPC是指远程过程调用,是一种进程通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常式共享网络的另一台机器上)的过程或函数,而不是程序员显式编码这个远程调用的细节。即程序无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同
原理图:
Dubbo核心概念
Apache Dubbo 是一款高性能、轻量级的开源 java RPC框架,它提供了三大核心能力:
- 面向接口的远程调用
- 只能容错和负载均衡
- 服务自动注册和发现
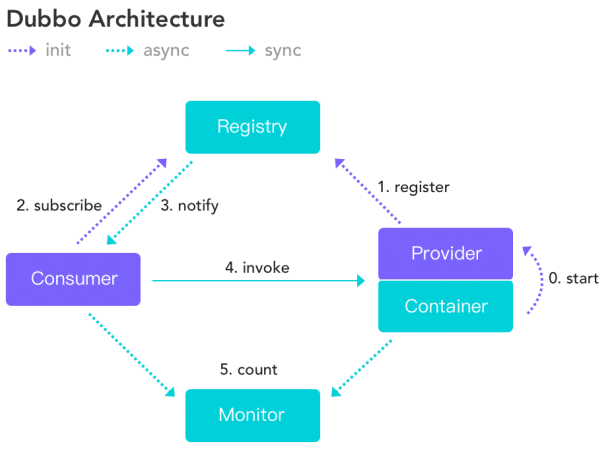
服务提供者(provider):暴露服务器的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务
服务消费者(Consumer):调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
注册中心(register):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
监控中心(Monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次数据到监控中心。
调用关系说明:
- 服务容器负责启动,加载,运行服务提供者。
- 服务提供者在启动时,向注册中心注册自己提供的服务。
- 服务消费者在启动时,向注册中心订阅自己所需的服务。
- 中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
- 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
- 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
zookeeper注册中心的搭建
zookeeperwindow本机启动地址:E:\学习资料\微服务之Dubbo\课件、资料\课件、资料\课件\software\zookeeper-3.4.11\bin
-
将下载下来的安装包进行解压后,需要conf文件夹下复制多一份
zoo_sample,并改名为zoo.cnf -
若出现闪退的情况需要进行在记事本打开
zkServer然后在最后一行加上pause -
在
zkEnv中修改自己jdk的环境变量
搭建 zookeeper 可视化监控
启动地址:E:\学习资料\微服务之Dubbo\课件、资料\课件、资料\课件\software\incubator-dubbo-ops-master\dubbo-admin\target
zookeepr监控启动是以jar包的形式,在springboot的tomcat服务器上启动的,
所以将zookeeper 可视化监控启动命令:java -jar "jar包"即可执行,没有jar包就在dubboa-admin文件下执行mvn packge进行打包
Dubbo代码实战(Spring整合)
示例场景:某个电商系统,订单服务需要调用用户服务获取某个用户的所有地址;我们现在 需要创建两个服务模块进行测试【该示例不适用数据库】


传统的MVC架构根据这个场景就是会创建一个工程,在这一个工程中创建一个实体类UserAddress,然后创建一个业务逻辑层,分别写上UserService和OrderService的和它们各自的实现类进行业务的处理
但是随着业务的复杂,我们需要把这种架构分离,创建三个工程:
- user-service-provider【这个类只写UserService的实现类】
- order-service-consumer【这个类只写OrderService的实现类】
- gmail-interface【这个类只写实体类和OrderService接口和UserService接口】
这样就实现了架构的分离,那之间该如何联系呢,这就是Dubbo的作用,
说明:这里的 user-service-provider 其实就是服务提供者;order-service-consumer服务的消费者
构建Dubbo
流程:首先在服务提供者中,将服务提供者注册到用户中心,服务消费者到注册中心订阅服务提供者的服务地址。这样就能架起一个远程通信的链接。
-
将服务提供者注册到用户中心
-
在 user-service-provider 的maven文件中导入dubbo(2.6.2)的依赖:
<!-- https://mvnrepository.com/artifact/com.alibaba/dubbo --> <dependency> <groupId>com.alibaba</groupId> <artifactId>dubbo</artifactId> <version>2.6.2</version> </dependency> -
因为注册中心使用的是zookeeper,所以也要导入zookeeper客户端的依赖:
<!-- curator-framework --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.12.0</version> </dependency> -
在sping.xml(用SpringBoot的话在yml中配置)进行配置
- 使用
dubbo application指定当前服务的名称 - 使用
dubbo registry指定用户中心的位置 - 使用
dubbo protocol指定通信规则 - 暴露服务(暴露出去的服务才能被人调用)
<!--当前应用的名字 --> <dubbo:application name="gmall-user"></dubbo:application> <!--指定注册中心的地址 --> <dubbo:registry address="zookeeper://118.24.44.169:2181" /> <!--使用dubbo协议,将服务暴露在20880端口 --> <dubbo:protocol name="dubbo" port="20880" /> <!-- 指定需要暴露的服务 ref指向服务实现的正真对象--> <dubbo:service interface="com.atguigu.gmall.service.UserService" ref="userServiceImpl" /> <!--服务的实现--> <bean id="userServiceImpl" class="com.atguigu.gmall.service.impl.UserServiceImpl"></bean> - 使用
-
-
服务消费者订阅提供者所暴露的实现
<!--当前应用的名字 --> <dubbo:application name="gmall-user"></dubbo:application> <!--指定注册中心的地址 --> <dubbo:registry address="zookeeper://118.24.44.169:2181" /> <!--使用dubbo协议,将服务暴露在20880端口 --> <dubbo:protocol name="dubbo" port="20880" /> <!-- 指定需要暴露的服务 --> <dubbo:service interface="com.atguigu.gmall.service.UserService" ref="userServiceImpl" />
SpringBoot整合Dubbo
详情的配置看官方文档:https://cn.dubbo.apache.org/zh-cn/overview/mannual/java-sdk/reference-manual/config/annotation/
-
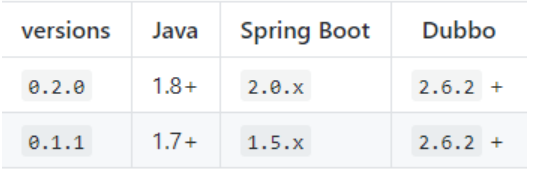
引入依赖:
<dependency> <groupId>com.alibaba.boot</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <version>0.2.0</version> </dependency>注意版本:
- 根据上面的Spring整合的配置文件,对提供者进行对
application.properties文件的配置
dubbo.application.name=gmall-user dubbo.registry.protocol=zookeeper dubbo.registry.address=192.168.67.159:2181 dubbo.scan.base-package=com.atguigu.gmall dubbo.protocol.name=dubbo #application.name就是服务名,不能跟别的dubbo提供端重复 #registry.protocol 是指定注册中心协议 #registry.address 是注册中心的地址加端口号 #protocol.name 是分布式固定是dubbo,不要改。 #base-package 注解方式要扫描的包- 对消费者进行
application.properties文件的配置
dubbo.application.name=gmall-order-web dubbo.registry.protocol=zookeeper dubbo.registry.address=192.168.67.159:2181 dubbo.scan.base-package=com.atguigu.gmall dubbo.protocol.name=dubbo - 根据上面的Spring整合的配置文件,对提供者进行对
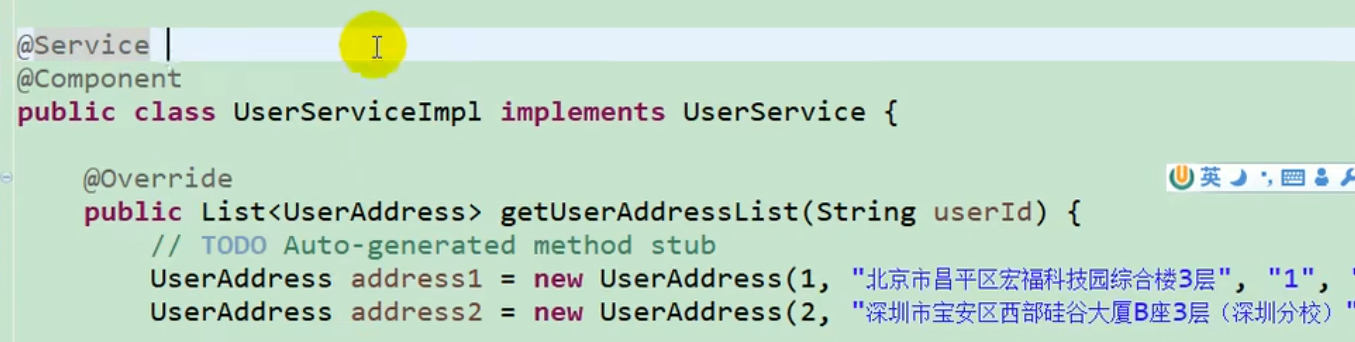
注意要使用Dubbo需要在SpringBoot启动类中加入@EnableDubbo,提供者暴露服务需要在所要暴露的类中添加上@Service注解,该@Service注解是Dubbo提供的,消费者需要使用到提供者暴露的方法,可以使用@Reference进行远程注入
Dubbo启动配置原则
Dubbo启动时读取配置文件的规则:-D命令 > XML文件 > Properties
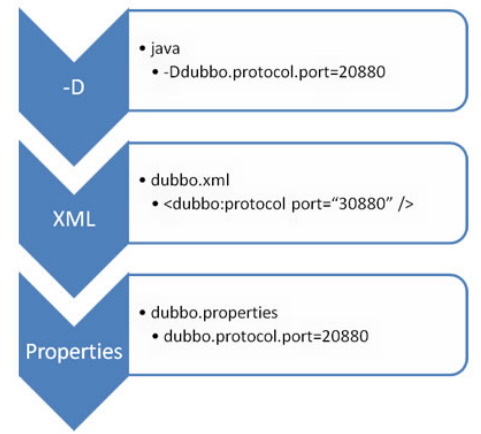
JVM 启动 -D 参数优先,这样可以使用户在部署和启动时进行参数重写,比如在启动时需改变协议的端口。
XML 次之,如果在 XML 中有配置,则 dubbo.properties 中的相应配置项无效。
Properties 最后,相当于缺省值,只有 XML 没有配置时,dubbo.properties 的相应配置项才会生效,通常用于共享公共配置,比如应用名。
超时时间
由于网络或服务端不可靠,会导致调用出现一种不确定的中间状态(超时)。为了避免超时导致客户端资源(线程)挂起耗尽,必须设置超时时间。
Dubbo消费端:
全局超时配置
<dubbo:consumer timeout="5000" />
指定接口以及特定方法超时配置
<dubbo:reference interface="com.foo.BarService" timeout="2000">
<dubbo:method name="sayHello" timeout="3000" />
</dubbo:reference>
Dubbo服务端:
全局超时配置
<dubbo:provider timeout="5000" />
指定接口以及特定方法超时配置
<dubbo:provider interface="com.foo.BarService" timeout="2000">
<dubbo:method name="sayHello" timeout="3000" />
</dubbo:provider>
重试次数
失败自动切换,当出现失败,重试其它服务器,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。
这种做法用于对接口的幂等性进行设置,幂等性即为:操作影响的结果都是一样的。比如删除,更新操作,这些操作,如果失败了,我们可以将其设置为重试次数进行重试。
重试次数的配置如下:
<dubbo:service retries="2" />
或
<dubbo:reference retries="2" />
或
<dubbo:reference>
<dubbo:method name="findFoo" retries="2" />
</dubbo:reference>
超时时间和重试次数的配置原则
配置的覆盖规则:
- 方法级配置别优于接口级别,即小Scope优先
- Consumer端配置 优于 Provider配置 优于 全局配置,
- 最后是Dubbo Hard Code的配置值(见配置文档)

1、作服务的提供者,比服务使用方更清楚服务性能参数,如调用的超时时间,合理的重试次数,等等
2、在Provider配置后,Consumer不配置则会使用Provider的配置值,即Provider配置可以作为Consumer的缺省值。否则,Consumer会使用Consumer端的全局设置,这对于Provider不可控的,并且往往是不合理的
版本号
设置版本号可以用来实现灰度发布,什么是灰度发布?——> 一个系统要进行更新,用于将新版本的软件或服务逐步引入生产环境,而不是一次性全部用户都发布。
在xml文件中可以使用version属性进行版本号的设置:
老版本服务提供者配置:
<dubbo:service interface="com.foo.BarService" version="1.0.0" />
新版本服务提供者配置:
<dubbo:service interface="com.foo.BarService" version="2.0.0" />
老版本服务消费者配置:
<dubbo:reference id="barService" interface="com.foo.BarService" version="1.0.0" />
新版本服务消费者配置:
<dubbo:reference id="barService" interface="com.foo.BarService" version="2.0.0" />
如果不需要区分版本,可以按照以下的方式配置:
<dubbo:reference id="barService" interface="com.foo.BarService" version="*" />
高可用场景
zookeeper宕机与dubbo直连【面试高频考点】
现象:zookeeper注册中心宕机,还可以消费dubbo暴露的服务。
原因:
- 监控中心宕掉不影响使用,只是丢失部分采样数据
- 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
- 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
- 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
- 服务提供者无状态,任意一台宕掉后,不影响使用
- 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
集群下dubbo负载均衡配置
在集群负载均衡时,Dubbo提供了多种均衡策略,缺省为random随机调用
负载均衡策略:
-
Random LoadBalance随机
按权重设置随机概率。
在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
-
RoundRobin LoadBalance轮循
按公约后的权重设置轮循比率。
存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
-
LeastActive LoadBalance【最少活跃调用数】
相同活跃数的随机,活跃数指调用前后计数差。
使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
-
ConsistentHash LoadBalance【一致性 Hash】
相同参数的请求总是发到同一提供者。
当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
缺省只对第一个参数 Hash,如果要修改,请配置 <dubbo:parameter key=“hash.arguments” value=“0,1” />
缺省用 160 份虚拟节点,如果要修改,请配置 <dubbo:parameter key=“hash.nodes” value=“320” />
服务降级
当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略。
降级的方法:
- mock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。
- 还可以改为 mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响。
集群容错
在集群一个服务调用另一个服务失败时,Dubbo 提供了多种容错方案,缺省为 failover 重试。
-
Failover Cluster
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=“2” 来设置重试次数(不含第一次)。
重试次数配置如下:
<dubbo:service retries="2" /> 或 <dubbo:reference retries="2" /> 或 <dubbo:reference> <dubbo:method name="findFoo" retries="2" /> </dubbo:reference> -
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
-
Failsafe Cluster
失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作。
-
Failback Cluster
失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作。
-
Forking Cluster
并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=“2” 来设置最大并行数。
-
Broadcast Cluster
广播调用所有提供者,逐个调用,任意一台报错则报错 [2]。通常用于通知所有提供者更新缓存或日志等本地资源信息。
整合hystrix
一般在实际的项目中是整合hystrix进行集群的容错。
Hystrix 旨在通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix具备拥有回退机制和断路器功能的线程和信号隔离,请求缓存和请求打包,以及监控和配置等功能
1、配置spring-cloud-starter-netflix-hystrix
spring boot官方提供了对hystrix的集成,直接在pom.xml里加入依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>1.4.4.RELEASE</version>
</dependency>
然后在Application类上增加@EnableHystrix来启用hystrix starter:
@SpringBootApplication
@EnableHystrix
public class ProviderApplication {
2、配置Provider端
在Dubbo的Provider上增加@HystrixCommand配置,这样子调用就会经过Hystrix代理。
@Service(version = "1.0.0")
public class HelloServiceImpl implements HelloService {
@HystrixCommand(commandProperties = {
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "10"),
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "2000") })
@Override
public String sayHello(String name) {
// System.out.println("async provider received: " + name);
// return "annotation: hello, " + name;
throw new RuntimeException("Exception to show hystrix enabled.");
}
}
3、配置Consumer端
对于Consumer端,则可以增加一层method调用,并在method上配置@HystrixCommand。当调用出错时,会走到fallbackMethod = "reliable"的调用里。
@Reference(version = "1.0.0")
private HelloService demoService;
@HystrixCommand(fallbackMethod = "reliable")
public String doSayHello(String name) {
return demoService.sayHello(name);
}
public String reliable(String name) {
return "hystrix fallback value";
}
Dubbo原理
RPC原理
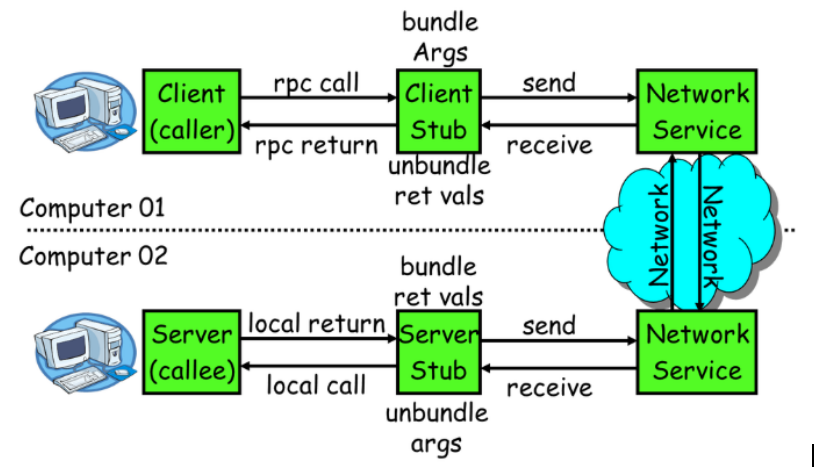
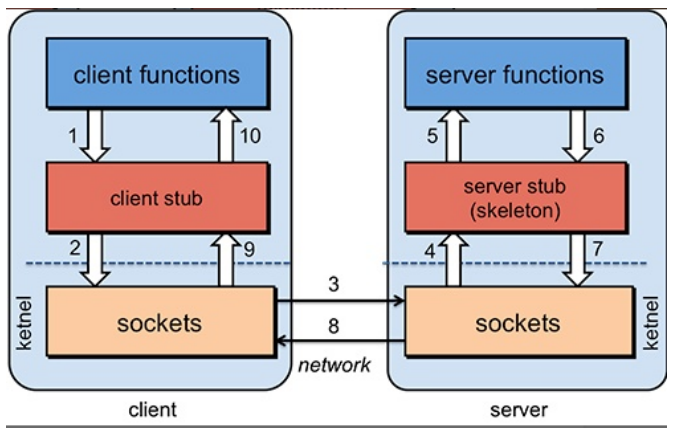
一次完成的RPC调用流程(同步调用):
- 服务消费方(client)调用以本地调用方式调用服务;
- client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体
- client stub找到服务地址,并将消息发送到服务端
- server stub收到消息后进行解码
- server stub根据解码结果调用本地的服务
- 本地服务执行并将结果返回给server stub
- server stub将返回结果打包成消息并发送至消费方
- client stub接收到消息,并进行解码
- 服务消费方得到最终结果
(RPC框架的目标就是要2~8这些步骤都封装起来,这些细节对用户来说是透明的,不可见的。)
dubbo原理框架设计图
架构图:https://cn.dubbo.apache.org/zh-cn/overview/mannual/java-sdk/reference-manual/architecture/code-architecture/
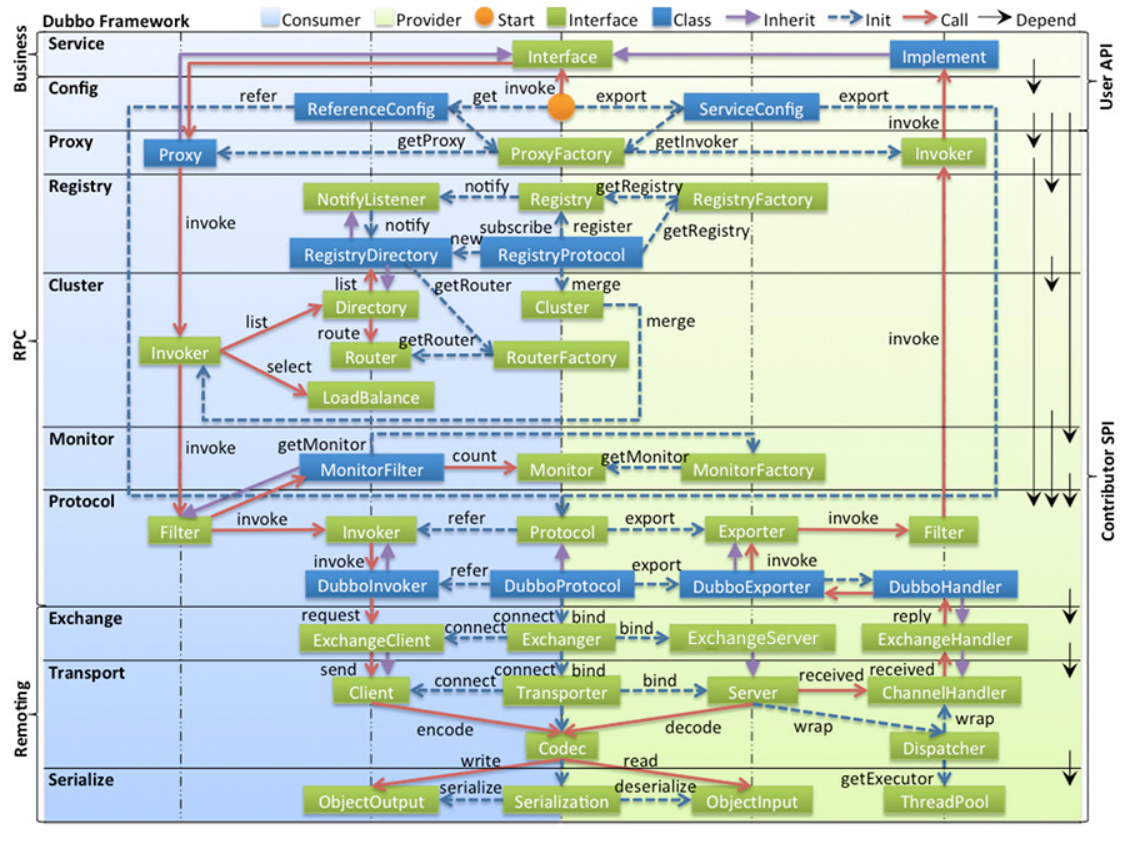
- config 配置层:对外配置接口,以 ServiceConfig, ReferenceConfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类
- proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton, 以 ServiceProxy 为中心,扩展接口为 ProxyFactory
- registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为 RegistryFactory, Registry, RegistryService
- cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 Invoker 为中心,扩展接口为 Cluster, Directory, Router, LoadBalance
- monitor 监控层:RPC 调用次数和调用时间监控,以 Statistics 为中心,扩展接口为 MonitorFactory, Monitor, MonitorService
- protocol 远程调用层:封装 RPC 调用,以 Invocation, Result 为中心,扩展接口为 Protocol, Invoker, Exporter
- exchange 信息交换层:封装请求响应模式,同步转异步,以 Request, Response 为中心,扩展接口为 Exchanger, ExchangeChannel, ExchangeClient, ExchangeServer
- transport 网络传输层:抽象 mina 和 netty 为统一接口,以 Message 为中心,扩展接口为 Channel, Transporter, Client, Server, Codec
- serialize 数据序列化层:可复用的一些工具,扩展接口为 Serialization, ObjectInput, ObjectOutput, ThreadPool
dubbo的工作原理

大概总结:
首先先将配置文件的中标签(即你所设置的属性)全部加载到ServiceBean中,再ServiceBean解析完成后,就会触发ContextRefreshEvent,在这个事件回调中,会触发export方法对服务进行暴露
那服务是怎么暴露的呢?
-
先加载一堆的参数,加载完成,有一个关键的方法进行暴露
doExport -
在
doExport方法中,仍是先获取我们配置文件中的一些参数,判断是否为空等,最后又一个重要的方法,doExportUrls -
在
doExportUrls中:-
首先读取到注册中心的地址,
-
遍历配置文件中的协议
-
将遍历出来的每一个协议放到一个
doExportUrlsFor1Protocol()中,该方法的参数为协议和注册中心地址:
-
接下来就进入到
doExportUrlsFor1Protocol()中-
追踪到一个关键的代码:

这段代码的含义是通过一个工厂,获取到注册中心地址和所要暴露的方法(这里所要暴露的方法为UserServiceImpl)组合称为了一个
invoker,然后再将invoker封装成wrapperInvoker -
暴露
wrapperInvoker
这个
protocol是一个接口,有许多不同的实现类实现了这个protocol,这些实现类都是某种协议,这里我们使用的是dubbo,所以执行的是DubboProtocol,并且我们要将其注册到注册中心,所以也存在一个RegisterProtocol需要执行 -
首先执行
protocol.export方法后,先会走到RegisterProtocol进行注册,在RegisterProtocol类中会执行一个export方法,这个方法怎么执行?继续深入:-
首先会执行一个本地暴露

- 进到这个本地暴露的方法中,首先会创建一个暴露的执行者,拿到之前的
invoker进行暴露 - 最后仍会使用
protocol的erporter进行暴露,这一步跟暴露wrapperInvoker的步骤很像,之前执行后是跳到了RegisterProtocol,这次的执行会跳到DubboProtocol中
- 跳到了
DubboProtocol后,有一个关键的方法openServer,在这个方法中拿到服务的地址,然后创建一个信息交换的服务器,这个信息交换机服务器使用的是Netty的底层原理进行通信,其实整个openServer方法就是启动Netty服务器,监听20880即Dubbo的端口
- 进到这个本地暴露的方法中,首先会创建一个暴露的执行者,拿到之前的
-
执行完本地暴露这个方法后,接下来一个重要的方法就是注册提供者:

点进这个方法中,使用了两个线程安全的map保存了url的地址,下图中的两个map即为注册表,远程调用时根据注册表进行注册

-
-
-
服务引用流程
在消费者获取到注册中心所暴露的方法是通过
@Autowire,注解进行引用的注入的,具体的流程是怎样的呢? -
















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









