






 文章介绍了机器学习中的线性回归模型,用于连续值预测。通过实例解释了如何利用训练数据找到x与y之间的线性关系,并通过损失函数和均方误差评估模型的拟合效果,以求得最佳权重。文章还展示了简单的代码实现,以求解权重w并确定最优模型。
文章介绍了机器学习中的线性回归模型,用于连续值预测。通过实例解释了如何利用训练数据找到x与y之间的线性关系,并通过损失函数和均方误差评估模型的拟合效果,以求得最佳权重。文章还展示了简单的代码实现,以求解权重w并确定最优模型。
目录
概述
机器学习这一领域可以利用已有的数据或者经验,对未知事物进行判断或预测。例如男性身高的预测,已知一位年龄为8岁的男孩身高为120cm,9岁的男孩身高为125.1cm, 10岁的男孩身高为139.5cm,11岁的男孩身高为143.6cm,若已知一位男孩13岁,预测他的身高应该为多少?例如例如在房价预测 中,面积为80的房子房价为122.5万元,面积为100
的房子价格在150万元,面积为125
的房子价格在175万元。那么如果某个人的朋友买了一栋130
的房子,那么我们如何预测这房子的价格为多少?我们可以记x为房子面积大小,y为对应的房价,为了预测房价,我们应该找到x与y之间的一种对应方式,即函数(function)。
| X(房子面积)/ | Y(房价)/万 |
| 80 | 142.5 |
| 100 | 150 |
| 125 | 175 |
| 130 | ? |
为了方便,我们将已知x的所有取值和对应的y值称为数据集,可以在得到上例中数据集就是(80,142.5),(100,150),(125,175)。机器学习,所谓学习就是可以利用已知的数据或判断经验进行训练,从而对新数据进行推测,因此我们又将(x,y)称为训练集,x称为属性,每一对(x , y)称为一个训练样本
在上面两个例子中,可以看出(年龄,身高)中对13岁男孩身高的预测值是连续的,意思是说身高有可能是150.3,155.2,155.3,161.2,161.4这样的连续值。房价预测同理。对于这样预测值是一个连续值,我们则称此类学习为“回归”,对应的如果预测值是离散值,例如好与坏,恶性与良性等,此类学习称为“分类”。
线性回归模型
前面说到,为了从已知数据或经验中对新的数据进行预测,我们应该找到x与y之间的对应关系,也就是函数。那么线性回归模型就是我们找到的函数是线性函数,并且是回归类型的学习。我们来看一个简单的例子:一位学生在一周投入学习时间(x),则在周末小测试获得的分数(y),现在有如下训练集:
| x(学习时间) | y(获得分数) |
| 1 | 2 |
| 2 | 4 |
| 3 | 6 |
如果这为学生在某一周投入学习的时间为4小时,那么应该得到多少分数?在该训练集的每一个样本只有一个属性x,我们可以写出函数应该为: = f(x) = w * x,其中w未知,这正是我们要通过训练确定的值,我们希望通过训练,给定一个属性x,能达到
= f(x)
y的效果。那么记下来的问题是我们应该如何确定w的值?我们不妨先猜测一下,如果w=3,
= f(1) = 3 ,
= f(2) = 6,
= f(3) = 9 ; 如果w = 1 的时候呢?
为了评估拟合效果,我们引入损失函数 :loss(x) = =
,损失函数值越小说明拟合效果越好。
| x | y | | loss(w=3) |
| 1 | 2 | 3 | 1 |
| 2 | 4 | 6 | 4 |
| 3 | 6 | 9 | 9 |
| 均值 = |
| x | y | | loss |
| 1 | 2 | 2 | 0 |
| 2 | 4 | 4 | 0 |
| 3 | 6 | 6 | 0 |
| 均值= 0 |
| x | y | | loss(w=4) |
| 1 | 2 | 4 | 4 |
| 2 | 4 | 8 | 16 |
| 3 | 6 | 12 | 36 |
| 均值= |
在实际训练中,很难得到损失为0的情况,因此损失为0的情况为理想情况。在训练中,如何确定权重w使得损失最小是我们的目标。为了评估该权重的效果,我们引入均方误差(Mean Square Error): ,其中N为样本总数。上面三个表格中的“均值”即指的是均方误差,可以简写为MSE。由此我们训练的目标即为确定权重w,使得MSE最小。
我们如何确定w呢?我们可以使用穷举法来寻找最佳的w。接下来我们用代码来实现这个例子:
x_data = [1.0 , 2.0 , 3.0] #x属性取值
y_data = [2.0 , 4.0 , 6.0]
def forward(x): #函数f(x)
return x*w
def loss(x,y): #损失函数
y_hat = forward(x)
return (y_hat - y) * (y_hat - y)
w_list = [] #权重
mse_list = [] #MSE
for w in np.arange(0.0,4.1,0.1): #穷举0.0到4.0之间,0.1为间隔的所有权重取值
print('w=',w)
l_sum = 0
for x , y in zip(x_data , y_data):
y_hat_val = forward(x)
loss_val = loss(x,y)
l_sum += loss_val
print('\t',x , y , y_hat_val , loss_val)
print('MSE=', l_sum/3)
w_list.append(w)
mse_list.append(l_sum/3)
plt.plot(w_list , mse_list)
plt.ylabel('mse')
plt.xlabel('w')
plt.show()运行结果为:
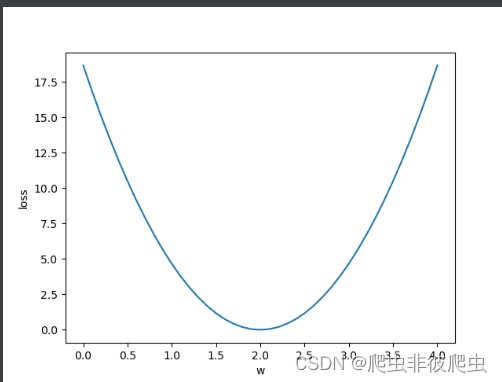
可以看出当w = 2时, MSE最小且为0.由此我们训练得出权重等于2时预测效果最佳,因此我们找到了线性函数 y = f(x) = 2 * x
需要注意的是,这只是一个特别简单的例子,属性只有一个。若属性有n个(n个属性就是有n个特征),每一个属性对应一个权重即
(),则对应的线性回归模型为:
若将属性和权重均写为矩阵
那么线性回归模型可以写成:
我们可以知道,属性越多,维数越多,训练难度也随之增加。在实际的机器学习训练中,往往会花费几天甚至几周的时间,所有在今后实际训练中,要注意及时保存备份,以免意外情况导致代码崩溃停止运行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









