







目录
查看数据类型内置方法的操作方法: 数据类型.(点)的方式

1.1 整型的内置方法:
1.1.1 类型转换
a = '123'
print(id(a),type(a))
a = int(a)
print(id(a),type(a))
# 2241061048872 <class 'str'>
# 1752928176 <class 'int'>#字符串转整型
a = '123'
print(id(a),type(a))
a = int(a)
print(id(a),type(a))
1.1.2 进制转换
num = 10
# 十进制转二进制,bin(binary)
print(bin(num))
# 十进制转八进制,oct(octal)
print(oct(num))
#十进制转十六进制,hex(hexadecimal)
print(hex(num))
num = 10
print(bin(num)) # 二进制
print(oct(num)) # 八进制
print(hex(num)) # 十六进制
#结果
0b1010
0o12
0xa#二进制,八进制,十六进制转十进制
print(int('0b1010',2))
print(int('0o12',8))
print(int('0xa',16))
print(int('0b1010',2)) # 10
print(int('0o12',8)) # 10
print(int('0xa',16)) # 10'''
二进制以0b开头
八进制以0o开头
十六进制以0x开头'''
1.2 float 浮点型内置方法
1.2.1 类型转换
res = float('11.11')
print(res, type(res)) # 11.11
res = float('11')
print(res, type(res)) # 11.0
res = float('11.11')
print(res, type(res)) # 11.11
res = float('11')
print(res, type(res)) # 11.0
浮点型在进行数据类型转换时可自动补全小数点,以符合规范.
2.str 字符串的内置方法
str可以转换所有基本数据类型
print(str(11), type(str(11)))
print(str(11.11), type(str(11.11)))
print(str([1, 2, 3, 4]), type(str([1, 2, 3, 4])))
print(str({'name': 'jason'}), type(str({'name': 'jason'})))
print(str((1, 2, 3, 4)), type(str((1, 2, 3, 4))))
print(str({1, 2, 3, 4}), type(str({1, 2, 3, 4})))
print(str(True), type(str(True)))
11 <class 'str'>
11.11 <class 'str'>
[1, 2, 3, 4] <class 'str'>
{'name': 'jason'} <class 'str'>
(1, 2, 3, 4) <class 'str'>
{1, 2, 3, 4} <class 'str'>
True <class 'str'>
s = 'hello world'
1. 索引取值 [0]
2.切片操作 [2:4]
3.步长间隔 [2:4:2] 默认步长为1
[-1] 最后一个字符
[-5:-1] 反切
[-1:-5:-1] 控制方向
4.统计字符串中字符的个数 .len()
5.成员运算 'xx' in xx
6.移除字符串首尾指定字符, 可选择方向.
.strip() 首尾
.lstrip() 左侧
.rstrip() 右侧
7.按照指定的字符切割字符串 [结果为一个列表]
.split() .split('$')使用$进行字符串切割 [默认使用空格,从左往右进行切割]
.rsplit() 从右往左切割
8.大小写相关操作
.lower() 小写
.upper() 大写
.islower() 小写 后台可进行强制规定 用于图片验证码等领域
.isupper() 大写 后台可进行强制规定 用于图片验证码等领域
9.判断字符串的开头/结尾是否是指定的字符
.startswith() 以XX开头
.enswith() 以XX结尾
10.格式化输出
1. %s 占任意数据
%d 只占数字
2. .format 方法
2.1 {} 类似于占位符%s
2.2 {变量名} 可多次取值
2.3 {0}/{1} 索引方式 可多次取值
2.4 f'{变量名}' 使用已出现过的变量名,可多次使用
11.拼接字符串
.join() 相当于对拼接的字符串进行了for循环
+ 两个字符串相加, 当字符串过大的时候会影响效率,不建议使用
12.替换字符串中指定的字符 .replace() 替换所有, 类似于文本编辑器里的替换
13.判断字符串中是否是纯数字 .isdigit()
# 1.索引取值
print(s1[0]) # h
# 2.切片操作
print(s1[2:4]) # ll 顾头不顾尾
# 3.步长
print(s1[2:9:1]) # llo wor 第三个参数是步长 默认是1 依次获取
print(s1[2:9:2]) # lowr 间隔一个取一个
# 索引取切片扩展
print(s1[-1]) # 获取最d一个字符
print(s1[-1:-5:-1]) # dlro 第三个参数还可以控制索引的方向
print(s1[-5:-1]) # worl
# 4.统计字符串中字符的个数
print(len(s1)) # 11
# 5.成员运算
print('ll' in s1) # True
# 6.移除字符串首位指定的字符(使用频率较高)
name = ' yietong '
print(len(name))
res = name.strip() # 默认移除字符串首尾的空格
print(res, len(res)) # yietong 7
name1 = '$$$$yie$tong$$$$'
print(name1.strip('$')) # yie$tong
username = input('username>>>>:').strip()
if username == 'yietong':
print('天气不错') # 天气不错
"""split方法切割完字符串之后是一个列表"""
# 7.按照指定的字符切割字符串
data = 'yietong|123|read'
print(data.split('|')) # ['yietong', '123', 'read']
name, pwd, hobby = data.split('|') # 解压赋值
print(data.split('|', maxsplit=1)) # ['yietong', '123|read']
print(data.rsplit('|', maxsplit=1)) # ['yietong|123', 'read']
# 8 大小写相关操作
print(s1.lower()) # hello world
print(s1.upper()) # HELLO WORLD
print(s1.islower()) # hello world
print(s1.isupper()) # HELLO WORLD
# 9. 判断字符串的开头结尾是否是指定字符
print(s1.startswith('h')) # True
print(s1.endswith('o')) # False
print(s1.startswith('hello')) # True
print(s1.endswith('world')) # True
# 10.格式化输出
# #1.占位符%s %d
s = 'my name is %s, my age is %d'%('yietong',22)
print(s) # my name is yietong, my age is 22
# format方法
# 1. 类似于占位符
print('my name is {}, my age is {}'.format('yietong', 22))
# my name is yietong, my age is 22
# 2. 变量名方式
name = 'yietong'
age = 22
print('my name is {name}{name}{name}, my age is {age}'.format(name='yietong', age=22))
# my name is yietongyietongyietong, my age is 22
# 3. 索引取值的方式
print('my name is{0} {0}, my age is {1}{1}'.format('yietong',22))
# my name isyietong yietong, my age is 2222
# 4.直接使用已经出现过的变量
print(f'my name is {name}{name}, my age is{age} {age}')
# my name is yietongyietong, my age is22 22
# 11. 拼接字符串
s1 = 'hello world'
s2 = '晚上好'
print(s1.join(s2)) # 晚hello world上hello world好
print(s1 + s2) # hello world晚上好
# 12.文本替换
print(s1.replace('hello','我是一个替换的文本'))
# 我是一个替换的文本 world
print(s1.replace('o','我是替换文本',2))
# hell我是替换文本 w我是替换文本rld 可指定替换个数
# 13.判断是否为数字
print(s1.isdigit()) # False
以下是了解操作
14.查找指定字符对应的索引值
.find() 查找字符对应的索引值,默认从左往右找,找不到报-1
.index() 找不到的情况下直接报错,不推荐使用
15.文本位置改变
.center() 居中
.ljust() 左对齐
.rjust() 右对齐
.zfill() 0填充
16.特殊符号
\n 换行
\a 特殊符号
\t 空格键(tab键)
取消特殊符号的方法为: 在字符串前加r
17.字母大小写变化
.capatalize() 首字母大写
.title() 每个单词的首字母大写
.swapcase() 大小写转换
s1 = 'hello world'
# 14.查找字符对应的索引值[默认从左往右,找到一个就返回]
print(s1.find('o')) # 4
print(s1.find('s')) # -1
print(s1.index('s')) # 报错
print(s1.index('w')) # 6
# 15. 文本位置的改变
s = 'good evening'
print(s.center(30,'#')) # #########good evening#########
print(s.ljust(30,'#')) # good evening##################
print(s.rjust(30,'#')) # ##################good evening
print(s.zfill(30)) # 000000000000000000good evening
# 16 特殊字符
print('yie\nto\ang\t123')
# yie
# tong 123
# 17. 字母大小写更改
print(s.capitalize()) # Good evening
print(s.title()) # Good Evening
print(s.swapcase()) # GOOD EVENING3.list 列表内置方法
1.索引 [0] [-1] 取反(最后一个元素)
2.切片操作
[1:4] 顾头不顾尾
[-4:-1] 反向切片
[-1:-4:-1] 定位方向(默认都是从左往右截取数据)
3.间隔步长
[1:4] 默认步长为1
[1:4:2] 可更改步长
4.统计元素个数 .len()
5.成员运算 'xx' in xx 最小判断单位是元素
6.添加元素
.append() 默认尾部添加
.insert() 指定位置添加
.extend() 合并列表 (相当于for循环+append)
+ 也可以使用, 但效率低
7.删除元素
.del() 通用的删除键 del([0])
.remove() 就地删除
.pop() 默认尾部弹出元素, 还可以指定索引弹出 .pop(2) 弹出第三个元素
8.修改列表元素
索引位置后进行更改 (如[0] = 'good evening')
9.排序
.sort() 默认升序
.sort(reverse=True) 进行降序
10.顺序颠倒 .reverse()
11..比较运算 结果为bool值,比较的是索引位置上元素的大小
12.指定位置的索引 .index() 定位到元素所在位置
13统计出现次数 .count()
13.清空列表 .clear()
# # 1.类型转换
print(list(11)) # 不行
print(list(11.11)) # 不行
print(list('yietong')) # ['y', 'i', 'e', 't', 'o', 'n', 'g']
print(list({'name': 'yietong', 'pwd': 123})) # ['name', 'pwd']
print(list((11,22,33,44,55))) # [11, 22, 33, 44, 55]
print(list({1, 2, 3, 4, 5})) # [1, 2, 3, 4, 5]
print(list(True))
""" list可以转换支持for循环的数据类型
可以被for循环的数据类型 字符串 列表 字典 元组 集合 """
# # 2.常见操作
name_list = ['kelly', 'kevin', 'tony', 'tom', 'jerry']
# 1.索引取值
print(name_list[0]) # kelly
print(name_list[-1]) # jerry
# 2.切片操作
print(name_list[1:4]) # ['kevin', 'tony', 'tom']
print(name_list[-4:-1]) # ['kevin', 'tony', 'tom']
print(name_list[-1:-4:-1]) # ['jerry', 'tom', 'tony']
# 3.间隔
print(name_list[0:4:1]) # ['kelly', 'kevin', 'tony', 'tom']
print(name_list[0:4:2]) # ['kelly', 'tony']
print(name_list[-1:-4:-1]) # ['jerry', 'tom', 'tony']
# 4.统计列表中元素的个数
print(len(name_list)) # 5
# 5.成员运算 最小判断单位是元素不是元素里面的单个字符
print('j' in name_list) # False
print('yietong' in name_list) # False
# 6.列表添加元素的方式
# 6.1.尾部追加'单个'元素
name_list.append('小李')
print(name_list) # ['kelly', 'kevin', 'tony', 'tom', 'jerry', '小李']
name_list.append([11, 22, 33, 44])
print(name_list) # ['kelly', 'kevin', 'tony', 'tom', 'jerry', '小李', [11, 22, 33, 44]]
# 6.2.指定位置插入'单个'元素
name_list.insert(0, 123)
name_list.insert(2, '可不可以插个队')
name_list.insert(1, [11, 22, 33])
print(name_list)
# [123, [11, 22, 33], 'kelly', '可不可以插个队', 'kevin', 'tony', 'tom', 'jerry']
# 6.3.合并列表
name_list.extend([11, 22, 33, 44, 55])
print(name_list)
# ['kelly', 'kevin', 'tony', 'tom', 'jerry', 11, 22, 33, 44, 55]
'''extend其实可以看成是for循环+append'''
for i in [11, 22, 33, 44, 55]:
name_list.append(i)
print(name_list)
# ['kelly', 'kevin', 'tony', 'tom', 'jerry', 11, 22, 33, 44, 55]
name_list += [11, 22, 33, 44, 55]
print(name_list) # 加号的效率不高#
# ['kelly', 'kevin', 'tony', 'tom', 'jerry', 11, 22, 33, 44, 55]
# 7.删除元素
# 7.1 通用的删除方式
del name_list[0]
print(name_list) # ['kevin', 'tony', 'tom', 'jerry']
# 7.2 就地删除
# 指名道姓的直接删除某个元素
print(name_list.remove('jerry')) # None
print(name_list) # ['kelly', 'kevin', 'tony', 'tom']
# 7.3 延迟删除
print(name_list.pop()) # 默认是尾部弹出 jerry
print(name_list) # ['kelly', 'kevin', 'tony', 'tom']
print(name_list.pop(2)) # 还可以指定索引值 tony
print(name_list) # ['kelly', 'kevin', 'tom']
# 8.修改列表元素
print(id(name_list[0])) # 3019608068360
name_list[0] = 'yietonglovely'
print(id(name_list[0])) # 3019608110128
print(name_list)
# ['yietonglovely', 'kelly', 'kevin', 'tony', 'tom', 11, 22, 33, 44, 55, 11, 22, 33, 44, 55, 11, 22, 33, 44]
# 9.排序
ss = [44, 77, 99, 11, 22, 33, 88, 66]
ss.sort() # 默认是升序
print(ss) # [11, 22, 33, 44, 66, 77, 88, 99]
ss.sort(reverse=True) # 可以修改尾降序
print(ss) # [99, 88, 77, 66, 44, 33, 22, 11]
# 10.翻转
ss = [44, 77, 99, 11, 22, 33, 88, 66]
ss.reverse() # 前后颠倒
print(ss) # [66, 88, 33, 22, 11, 99, 77, 44]
# 11.比较运算
s1 = [11, 22, 33]
s2 = [1, 2, 3, 4, 5, 6, 7, 8]
print(s1 > s2) # True
"""列表在做比较的时候 其实比的是对应索引位置上的元素"""
s1 = ['A', 'B', 'C'] # A>>>65
s2 = ['a'] # a>>>97
print(s1 > s2) # False
# 12. 索引指定位置
ss = [44, 77, 99, 11, 22, 33, 88, 66]
print(ss.index(99)) # 2
# 13.统计列表中某个元素出现的次数
l1 = [11, 22, 33, 44, 33, 22, 11, 22, 11, 22, 33, 22, 33, 44, 55, 44, 33]
print(l1.count(11)) # 统计元素11出现的次数 3
# 14.清空列表
l1.clear()
print(l1) # []补充知识点:
1. ASCII码
a-z 对应数字97-122
A-Z 对应数字65-90
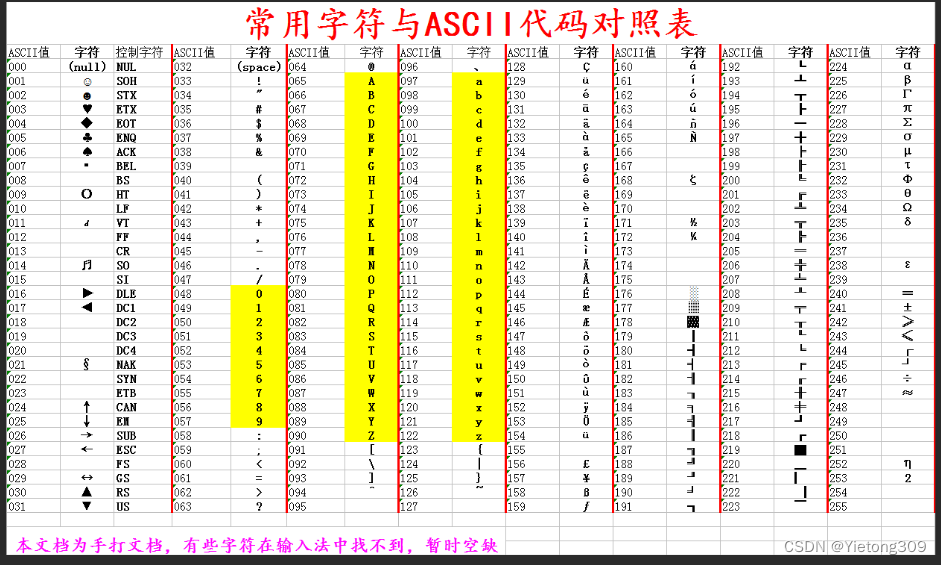
2. 队列与堆栈
队列特点: 先进先出 .append()
堆栈特点:先进后出 .pop()
# 队列
new_list = []
# 先进
new_list.append(111)
new_list.append(222)
new_list.append(333)
# 先出
for i in new_list:
print(i)
print(new_list.pop(0)) # 111
print(new_list.pop(0)) # 222
print(new_list.pop(0)) # 333
# 堆栈
new_list = []
# 先进
new_list.append(111)
new_list.append(222)
new_list.append(333)
# 后出
print(new_list.pop()) # 333
print(new_list.pop()) # 222
print(new_list.pop()) # 1113. 可变类型与不可变类型
可变类型
值改变 内存地址不变 修改的是本身
可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)
不可变类型
值改变 内存地址肯定遍 修改过程产生了新的值
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
id查看变量的'内存地址'
4.dict 字典的内置方法
K 是可变类型 ,V是不可变类型, key 是对values的描述
内置方法:
1. 按K取值 .name()
get 方法取值 .get('name') 推荐使用
2.修改值 d['name'] = 'xxx 键存在时修改值
3.添加键值对 键不存在就新增一个键值对
4.统计字典中键值对的个数 .len()
5.成员运算 只能判断key 'name' in d1
6. 删除键值对
del() 通用的删除方式
.pop(key) 默认尾部弹出元素
popitem() 随机弹出一个元素
7.获取所有的键/值/对
.keys() 多所的键, 可以看成是列表
.values() 多所的值, 可以看成是列表
.items() 多所的键值对, 可以看成是列表套元组
8.字典更新 .update() 键存在就修改,不在就新增
9.快速生成字典 .fromkeys()
10. setdefault() 键不存在就新增键值对, 键存在就不做修改
# 1.类型转换
dict()
d1 = {
'name': 'yietong',
'age': 22,
'hobbies': ['reading', 'cooking']
}
# 1.按key取值
print(d1['name']) # yietong 键存在
print(d1['xxx']) # 键不存在直接报错
"""涉及到字典取值 更加推荐下面的方式"""
print(d1.get('name')) # yietong 键存在
print(d1.get('xxx')) # None 键不存在不会报错 而是返回None
print(d1.get('xxx', '这个键不存在')) # 第二个参数不写默认返回None 写了则返回写了的
print(d1.get('name', '这个键不存在')) # 如果键存在 则不需要使用到第二个参数
# 2.修改值 字典也是可变类型
print(id(d1)) # 2390824815784
d1['name'] = 'yietonglovery' # 键存在是修改值
print(d1, id(d1))
# {'name': 'yietonglovery', 'age': 22, 'hobbies': ['reading', 'cooking']} 2498471431336
# 3.添加键值对
d1['pwd'] = 123 # 键不存在则是新增一个键值对
print(d1)
# {'name': 'yietonglovery', 'age': 22, 'hobbies': ['reading', 'cooking'], 'pwd': 123}
# 4.统计字典中键值对的个数
print(len(d1)) # 4
# 5.成员运算 也只能判断key而已
print('jason' in d1) # False
print('name' in d1) # True
# 6.删除键值对
del d1['name'] # 通用的删除方式
print(d1) # {'age': 22, 'hobbies': ['reading', 'cooking']}
print(d1.pop('age')) # 22 弹出
print(d1) # {'name': 'yietong', 'age': 22, 'hobbies': ['reading', 'cooking']}
d1.popitem() # 随机弹出一个(使用频率很低 可以忽略)
print(d1) # {'name': 'yietong', 'age': 22}
# 7.获取所有的键 所有的值 所有的键值对
print(d1.keys()) # dict_keys(['name', 'age']) 可以看成是列表
print(d1.values()) # dict_values(['yietong', 22]) 可以看成是列表
print(d1.items()) # dict_items([('name', 'yietong'), ('age', 22)]) 可以看成是列表套元组
for v in d1.values():
print(v)
# yietong
# 22
# ['reading', 'cooking']
"""在python2中上述三个方法就是直接返回一个列表 """
#######################需要了解######################
# 1.update更新字典
dic = {'k1': 'kelly', 'k2': 'Tony', 'k3': 'tim'}
dic.update({'k1': 'GN', 'k4': 'xxx'})
print(dic) # 键存在则修改 键不存在则新增 {'k1': 'GN', 'k2': 'Tony', 'k3': 'tim', 'k4': 'xxx'}
# 2.fromkeys()快速生成字典
dic = dict.fromkeys(['k1', 'k2', 'k3'], [])
print(dic) # {'k1': [], 'k2': [], 'k3': []}
# """笔试题"""
dic['k1'].append(111) # 三个键指向的是同一个列表
print(dic) # {'k1': [111], 'k2': [111], 'k3': [111]}
# 3.setdefault()
dic = {'k1': 111, 'k2': 222}
print(dic.setdefault('k3', 333)) # 键不存在则新增键值对 并且有返回结果是新增的v 333
print(dic) # {'k1': 111, 'k2': 222, 'k3': 333}
print(dic.setdefault('k1', '嘿嘿嘿')) # 键存在 则返回对应的值 不做修改 111
print(dic) # {'k1': 111, 'k2': 222, 'k3': 333}6.tuple 元组
元组被称为不可变的列表.支持for循环的数据类型均可转换成元组.
当元组内只有一个元素时,一定要加逗号.
内置方法
1.索引取值 [0] [-1]
2.切片操作 [1:4] [-4:-1]反取 [-1:-4:-1] 规定方向
3.间隔步长 [1:4:2] 默认步长为1
4.统计员组内元素的个数 .len()
5.成员运算 xx in t1
6.统计某个元素出现的次数 .count()
7.元素不可修改(索引指向的内存地址不可修改)
# 可以看成是不可变的列表
# 1.类型转换
# 支持for循环的数据类型都可以转成元组.
# print(tuple(11)) # 报错
# print(tuple(11.11)) # 报错
print(tuple('jason'))
print(tuple([11,22,33,44]))
print(tuple({'name':'yietong'}))
print(tuple({11,22,33,44}))
# print(tuple(True)) # 报错
# 2.元组的特性
t1 = (11, 22, 33, 44)
print(type(t1)) # <class 'tuple'>
t2 = (11)
print(type(t2)) # int
t2 = (11.11)
print(type(t2)) # float
t2 = ('yietong')
print(type(t2)) # str
"""当元组内只有一个元素的时候 一定要在元素的后面加上逗号"""
t2 = (11,)
print(type(t2)) # tuple
t2 = (11.11,)
print(type(t2)) # tuple
t2 = ('yietong',)
print(type(t2)) # tuple
"""
一般情况下 我们会习惯性的将所有可以存储多个数据的类型的数据
如果内部只有一个元素 也会加逗号
(1,)
[1,]
{1,}
{'name':'yietong',}
"""
t1 = (11, 22, 33, 44, 55, 66)
# 1.索引取值
print(t1[0])
print(t1[-1])
# 2.切片操作
print(t1[1:4])
print(t1[-1:-4:-1])
print(t1[-4:-1])
# 3.间隔
print(t1[1:4:2]) # (22, 44)
# 4.统计元组内元素的个数
print(len(t1)) # 6
# 5.成员运算
print(11 in t1) # True
# 6.统计某个元素出现的次数
print(t1.count(22))
# 7.元组内元素不能"修改": 元组内各个索引值指向的内存地址不能修改
# t1[0] = 111
"""
笔试题
tt = (11, 22, 33, [11, 22])
tt[-1].append('heiheihei')
问:执行之后的结果 正确答案选B
A.报错 B.正常添加 C.不知道
"""
tt = (11, 22, 33, [11, 22])
print(id(tt[-1])) # 2332847804872
tt[-1].append('heiheihei')
print(id(tt[-1])) # 2332847804872
print(tt) # (11, 22, 33, [11, 22, 'heiheihei'])7.set 集合的内置方法
集合两大功能:
1.去重
集合内不能出现重复的元素(自带去重特性)
如果出现了 会被集合自动去重
2.关系运算
判断两个群体内的差异
两个数据集的交集; &
其中一个数据集独有的数据 : -
两个数据集的所有数据: |
各自独有的数据集: ^
















 536
536











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









