







目录
基本的操作数据库的语句
show databases; >>>> 查看所有的数据库
show tables; >.>> 查看所有的表
select * from mysql.user; >>>> 查看user表里面所有的记录
SQL语句的结束符是英文状态下的分号 ;
取消SQL语句的执行 >>> \C
操作库的基本SQL语句
1.增
create database 库名;
2.查
show databases;
show create database 库名;
3.改
alter database 库名 charset='gbk';
4.删
drop database 库名;
create database 库名 charset utf8mb4 collate utf8mb4_bin;
数据库名 字符集 排序规则
建库规范:
1.库名不能有大写字母 #多平台兼容问题
2.建库要加字符集
3.库名不能有数字开头
4.库名要和业务相关
5.库名不要太长
6.不要使用内置字符
create database xiaowu;
show create database xiaowu; #查看建库的基本命令(建库语句)
show create database school;
alter database xiaowu charset utf8;
注意:修改字符集,修改后的字符集一定是原字符集的严格超集
只能改库属性,不能改库名。
show databases;
show create database xiaowu; #查看建库的基本命令(建库语句)
针对表的基本SQL语句
查看当前所在的库名 select database(); 如果没有切换指定的库 那么默认是NULL use 库名; 1.增 create table 表名(字段名 字段类型,字段名 字段类型,字段名 字段类型); 新增字段: alter table 表名 add 字段名 字段类型(数字) 约束条件; alter table 表名 add 字段名 字段类型(数字) 约束条件 after 已经存在的字段; alter table 表名 add 字段名 字段类型(数字) 约束条件 first; 2.查 show tables; show create table 表名; describe 表名; desc 表名; 3.改 alter table 旧表名 rename 新表名; # 改表名 修改字段 alter table 表名 change 旧字段 新字段 字段类型(数字) 约束条件; alter table 表名 modify 字段名 新的字段类型(数字) 约束条件; 4.删 drop table 表名;
alter table 表名 drop 字段名;
create table stu(
列1 属性(数据类型、约束、其他属性) ,
列2 属性,
列3 属性
)
USE school;
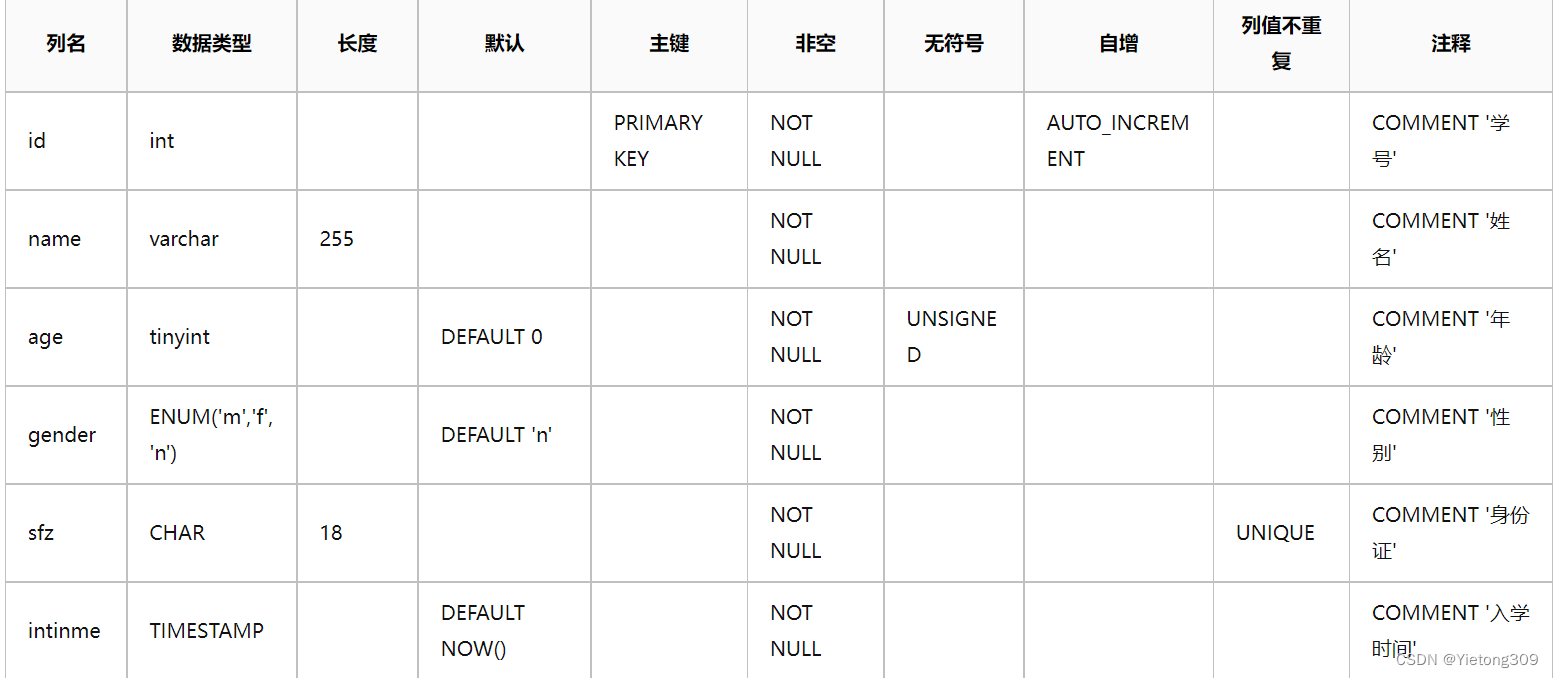
CREATE TABLE stu(
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(255) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '年龄',
sgender ENUM('m','f','n') NOT NULL DEFAULT 'n' COMMENT '性别' ,
sfz CHAR(18) NOT NULL UNIQUE COMMENT '身份证',
intime TIMESTAMP NOT NULL DEFAULT NOW() COMMENT '入学时间'
) ENGINE=INNODB CHARSET=utf8mb4 COMMENT '学生表';
ENGINE=INNODB CHARSET=utf8mb4 COMMENT '学生表'
存储引擎 字符集 注释
1. 表名小写 #多平台兼容问题
2. 不能是数字开头
3. 注意字符集和存储引擎
4. 表名和业务有关
5. 选择合适的数据类型 #合适,简短,足够
6. 每个列都要有注释
7. 每个列设置为非空,无法保证非空,默认值或用0来填充。
8. 必须要有主键
9. 列名不要太长
针对记录的基本SQL语句
"""
既然想操作记录 那么肯定的先有库和表
"""
1.增
insert into 表名 values(数据,数据);
insert into 表名 values(数据,数据),(数据,数据),(数据,数据);
2.查
select * from 表名; # *表示查看所有字段
select 字段1,字段2 from 表名;
ps:如果表中字段较多出现了错乱 可以结尾写\G
3.改
update 表名 set 字段名=新数据 where 筛选条件;
4.删
delete from 表名; # 删除表中所有的数据
delete from 表名 where 筛选条件 # 按照条件删除数据
扩展知识
1、伪删除
用update来替代delete,最终保证业务中查不到(select)即可
删除id为1
原操作:
mysql> delete from stu where id=1;
伪删除:
1.添加状态列
ALTER TABLE stu ADD state TINYINT NOT NULL DEFAULT 1 ;
SELECT * FROM stu;
2. UPDATE 替代 DELETE
UPDATE stu SET state=0 WHERE id=6;
3. 业务语句查询
SELECT * FROM stu WHERE state=1;
2、delete from stu ,drop table stu,truncate table stu的区别
1.都可以删除全表
2.区别
delete
逻辑上,逐行删除。数据行多,操作慢
并没有真正从磁盘删除,只是在存储层面打标记,磁盘空间不立即释放。HWM高水位线()不会降低。(自增列继续)
drop
将表结构(元数据)和数据行物理层次删除
truncate
清空表段中的所有数据页。物理层次删除全表数据磁盘空间立即释放,HWM高水位会降低。(自增列重新开始)
#delete,drop,truncate如果不小心删除了,他们都可以恢复吗?
可以
常规方法:
都可以通过 备份+日志,恢复数据。
灵活办法
delete可以通过,翻转日志(binlog)
三种删除数据情况,也可以通过《延时从库进行恢复》
数据查询之select
1.配合内置函数使用
mysql> select now(); #查看当前时间
mysql> select database(); #查看当前所在库
mysql> select concat("hello word!"); #命令拼接,显示某字符串
2.计算
mysql> select 10*100; #进行计算
3.查询数据库的参数
mysql> select @@port; #查询当前端口
mysql> select @@datadir; #查看数据存储位置
show variables; ##查看所有参数
mysql> show variables like '%trx%'; #like 模糊查询
select 标准用法
单表
前提:
select
1.from 表1,表2,。。。
2.where 过滤条件1,过滤条件2...
3.group by 条件列1 条件列2。。。分组字段
4.select_list 列名
5.having 过滤条件1 过滤条件2。。。
6.order by 条件列1 条件列2。。。排序字段
7.limit 分页限制















 1377
1377











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









