







目录
1.4 常见元字符(支持的工具:find、grep、egrep、sed和awk)
案例1:统计root字符总行数 ; 不区分大小写查找the所有的行
案例2:将/etc/passwd中没有出现root的行取出来
案例12:查找以"."结尾的显示出来并输出行号,基础正则表达式需要用\转义
案例16:查找以ro开头,以t结尾,中间2-4个o的并输出行号
示例3:以冒号为分隔符,以数字大小对第三列进行降序(-r)排序,并将结果输出到passwd.bak文件中
示例3:与sort连用,显示所有重复行(包括不连续的重复行)
示例4:cat tst.txt | sort | uniq -u #仅显示出现一次(不重复)的行
一、正则表达式
1.1 定义:
1.正则表达式,又称正规表达式、常规表达式
2.使用字符串来描述、匹配一系列符合某个规则的字符串
3.正则表达式组成:
(1)普通字符:
大小写字母、数字、标点符号及一些其他符号
(2)元字符:
在正则表达式中具有特殊意义的专用字符
1.2 正则表达式层次
1. 基础正则表达式
2.扩展正则表达式
1.3 Linux中文本处理工具
grep
egrep
sed
awk
1.4 常见元字符(支持的工具:find、grep、egrep、sed和awk)
| 匹配符 | 表示含义 |
| . | 匹配除\n以外任意一个字符 ,如: go.d、g..d |
| \ | 转义字符 ,如\i、\n |
| ^ | 匹配字符串开始的位置 ,如:^the、^# |
| $ | 匹配字符串结束的位置 ,如: word$ |
| * | 匹配前面子表达式0次或者多次 ,如: goo*d、go.*d |
| [ ] | 匹配括号中的一个字符 ,如: go[ola]d、[abc]、[a-z]、[a-z0-9] |
| [^ ] | 匹配任意不在括号中出现的字符,取反 ,如: [^a-z]、[^0-9]、[^A-Z0-9] |
| \{n,m\} | 匹配前面的子表达式n到m次,有\{n\}、\{n,\}、\{n,m\}三种格式,如:go\{2\}d、go\{2,3\}d、go\{2,\}d |
1.5 扩展元字符
| 匹配符 | 含义 |
| + | 匹配前面子表达式1次以上,如:go+d,将匹配至少一个o |
| ? | 匹配前面子表达式0次或者1次,如:go?d,将匹配gd或god |
| () |
将括号中的字符串作为一个整体,如:(xyz)+,将匹配xyz整体1次以上,如xyzxyz |
| | | 以或的方式匹配字条串 如:good|food,将匹配good或food; g(oo|la)d,将匹配good或glad |
二、文本处理三剑客之grep
2.1 grep [选项]… 查找条件 目标文件
-E:开启扩展(Extend)的正则表达式
-c:计算找到“搜索字符串”的次数
-i:忽略大小写
-o:只显示被模式匹配到的字符串
-v:反向选择,显示出没有‘搜索字符串’内容的那一行,(反向查找,输出与查找条件不相符的行)
--color=auto:可以将找到的关键词部分加上颜色的显示
-n:顺便输出行号
案例1:统计root字符总行数 ; 不区分大小写查找the所有的行
grep -c root /etc/passwd #统计root字符总行数;或cat /etc/passwd |grep root
grep -i "the" httpd.conf #不区分大小写查找the所有的行
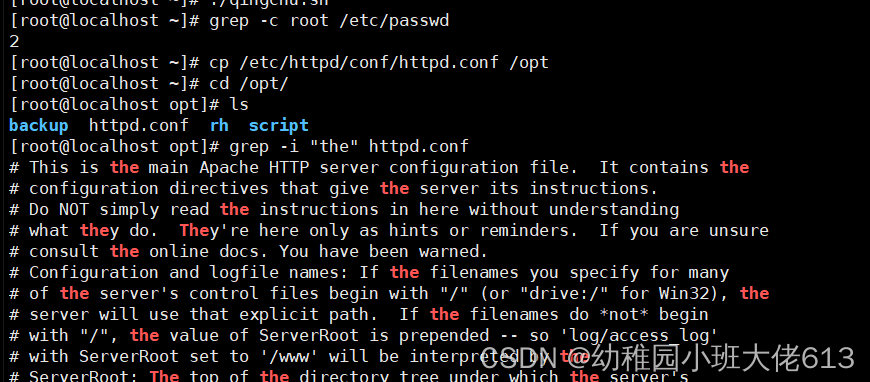
案例2:将/etc/passwd中没有出现root的行取出来

案例3:将非空行写入到test.txt文件

案例4:使用egrep过滤出IP

案例5:使用grep过滤出IP

案例6:匹配列表中r、v中的一个字符并且输出行号

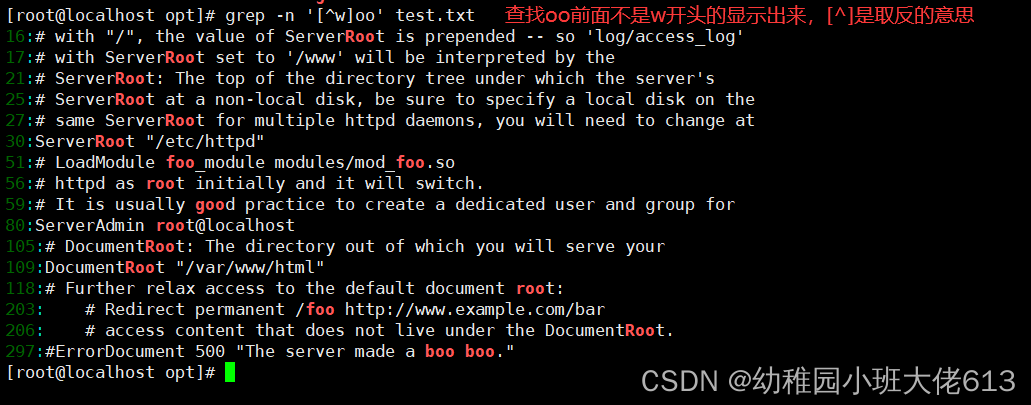
案例7:查找oo前面不是w开头的显示出来并且输出行号
[^]是取反的意思
案例8:查找oo前面不是小写字母a-z显示出来并输出行号

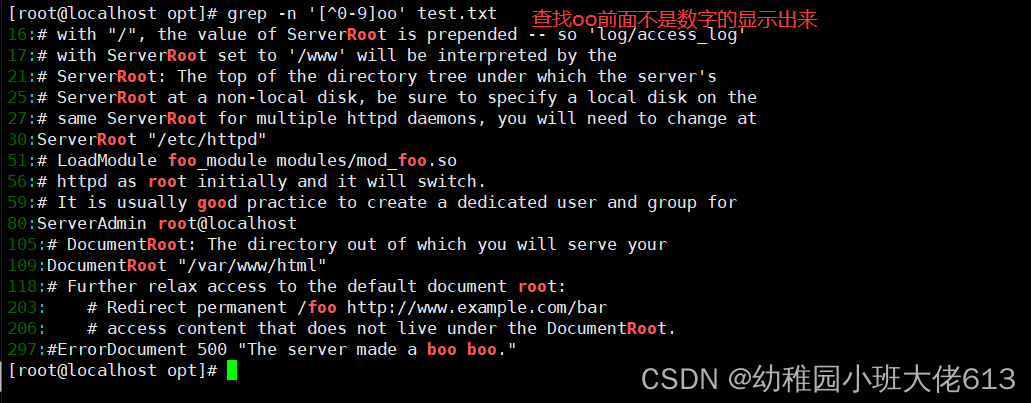
案例9:查找oo前面不是数字的显示出来并输出行号
案例10:查找以大写字母A-Z开头的显示出来并输出行号

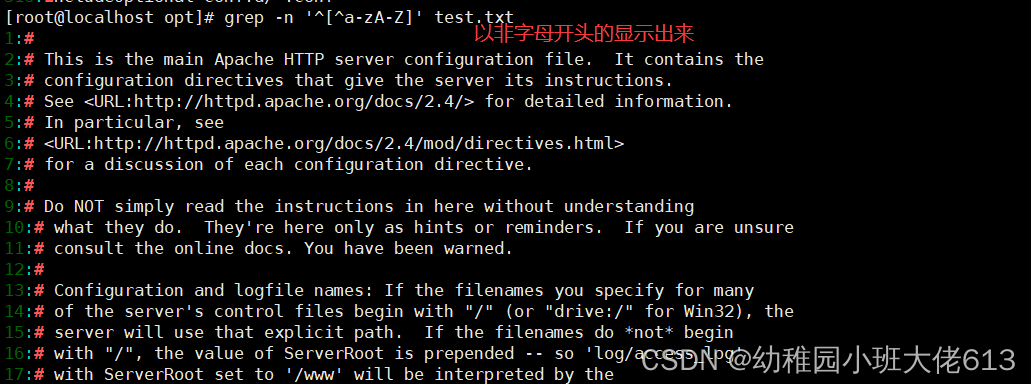
案例11:查找以非字母开头的显示出来并输出行号
案例12:查找以"."结尾的显示出来并输出行号,基础正则表达式需要用\转义

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 78
78











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









