






都2025啦,爬虫程序又要更新更新啦!(和网站开发者斗智斗勇哈哈)
下面我将把我自己亲自实践过的代码与大家分享讨论,没有很高级的设置,全都是简朴暴力的写法,大佬们勿怪啊。最近在完成自己的毕业论文,拖拖拉拉七拼八凑完成了较为简单的一个版本,实践下来并不难,最重要的是可视化,可以看见爬到哪里了,话不多说,下面开始啦。
分析网页

整体思路是使用xpath解析html获得该页上的岗位、薪水、城市、公司等信息。 已经确定boss直聘为动态加载,需要使用selenium来模拟浏览器活动进行爬取。(动态加载怎么识别网上有一些帖子,要是大家感兴趣我也可以出一个)
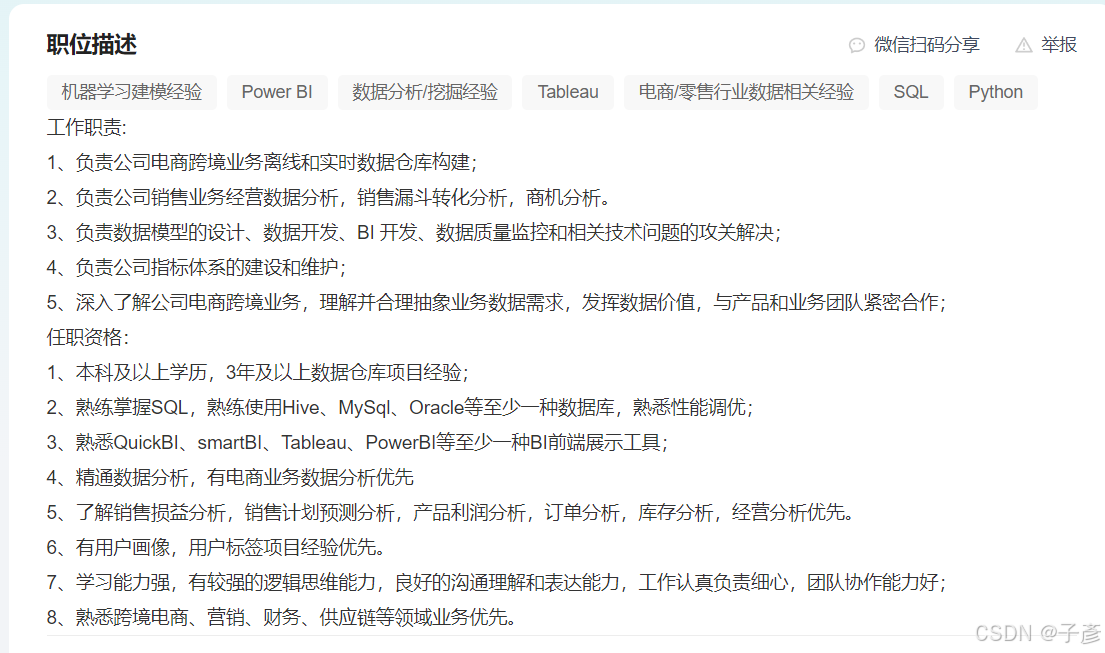
那么我主要想获取的内容就是岗位名称,地点,薪资,公司和职位描述这些,具体xpath的写法如下:
# 遍历每个岗位
for job in job_list: # 如果需要测试,可以先只爬取每页的前两条数据
# 提取岗位名称
job_name = job.xpath(".//span[@class='job-name']/text()")[0] if job.xpath('.//span[@class="job-name"]/text()') else "未知"
# 提取工作地点
job_area = job.xpath('.//span[@class="job-area"]/text()')[0] if job.xpath('.//span[@class="job-area"]/text()') else "未知"
# 详情页url
prefix = "https://www.zhipin.com"
detail_url = prefix + job.xpath('.//a/@href')[0]
# 提取薪资
salary = job.xpath('.//span[@class="salary"]/text()')[0] if job.xpath('.//span[@class="salary"]/text()') else "未知"
# 提取工作经验
experience = job.xpath('.//ul[@class="tag-list"]/li[1]/text()')[0] if job.xpath('.//ul[@class="tag-list"]/li[1]/text()') else "未知"
# 提取公司名称
company_name = job.xpath('.//h3[@class="company-name"]/a/text()')[0] if job.xpath('.//h3[@class="company-name"]/a/text()') else "未知"
# 公司类型和人数等
companyScale_list = job.xpath('.//div[@class="company-info"]/ul//text()')
companyScale = " ".join(companyScale_list)
# 提取学历要求
education = job.xpath('.//ul[@class="tag-list"]/li[2]/text()')[0] if job.xpath('.//ul[@class="tag-list"]/li[2]/text()') else "未知"
# 打开详情页
driver.get(detail_url)
# 增加等待时间,确保页面加载完成
try:
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CLASS_NAME, "job-sec-text"))
)
except TimeoutException:
print(f"超时:详情页 {detail_url} 加载超时")
continue # 跳过当前岗位,继续处理下一个岗位
# 获取页面源代码
detail_html_content = driver.page_source
# 解析 HTML
detail_html = etree.HTML(detail_html_content)
# 提取岗位标签
job_tags = detail_html.xpath('//ul[@class="job-keyword-list"]/li/text()')
job_tags = ", ".join([tag.strip() for tag in job_tags if tag.strip()]) if job_tags else "未知"
# 提取具体描述
job_detail = detail_html.xpath('//div[@class="job-sec-text"]/text()')
job_detail = "\n".join([line.strip() for line in job_detail if line.strip()]) if job_detail else "未知"
# 将提取的数据添加到列表中
jobs_data.append({
"岗位名称": job_name,
"工作地点": job_area,
"公司名称": company_name,
"薪资范围": salary,
"工作经验": experience,
"学历要求": education,
"公司类型": companyScale,
"岗位标签": job_tags,
"具体描述": job_detail,
"详情页url": detail_url
})进入网页,获取job_list
我是登录进去再开始爬虫的,所以我先找到登录页面,进行一个手动登录。
# 设置 Selenium 驱动
driver = webdriver.Chrome() # 确保已安装 ChromeDriver
# 打开Boss直聘登录页面
driver.get("https://www.zhipin.com/web/user/?ka=header-login")
# 手动登录
print("请手动完成登录操作...")
time.sleep(30) # 等待用户手动登录(根据实际情况调整时间)运行完之后会出现下面这个页面,然后登录就好,如果觉得30秒时间不够,可以选择增加时间,但是我更建议的做法是可以单独运行这段程序,运行完之后再在运行下面的程序,可以选择使用jupyter notebook一行行运行,报错了还可以随时检查,很方便。
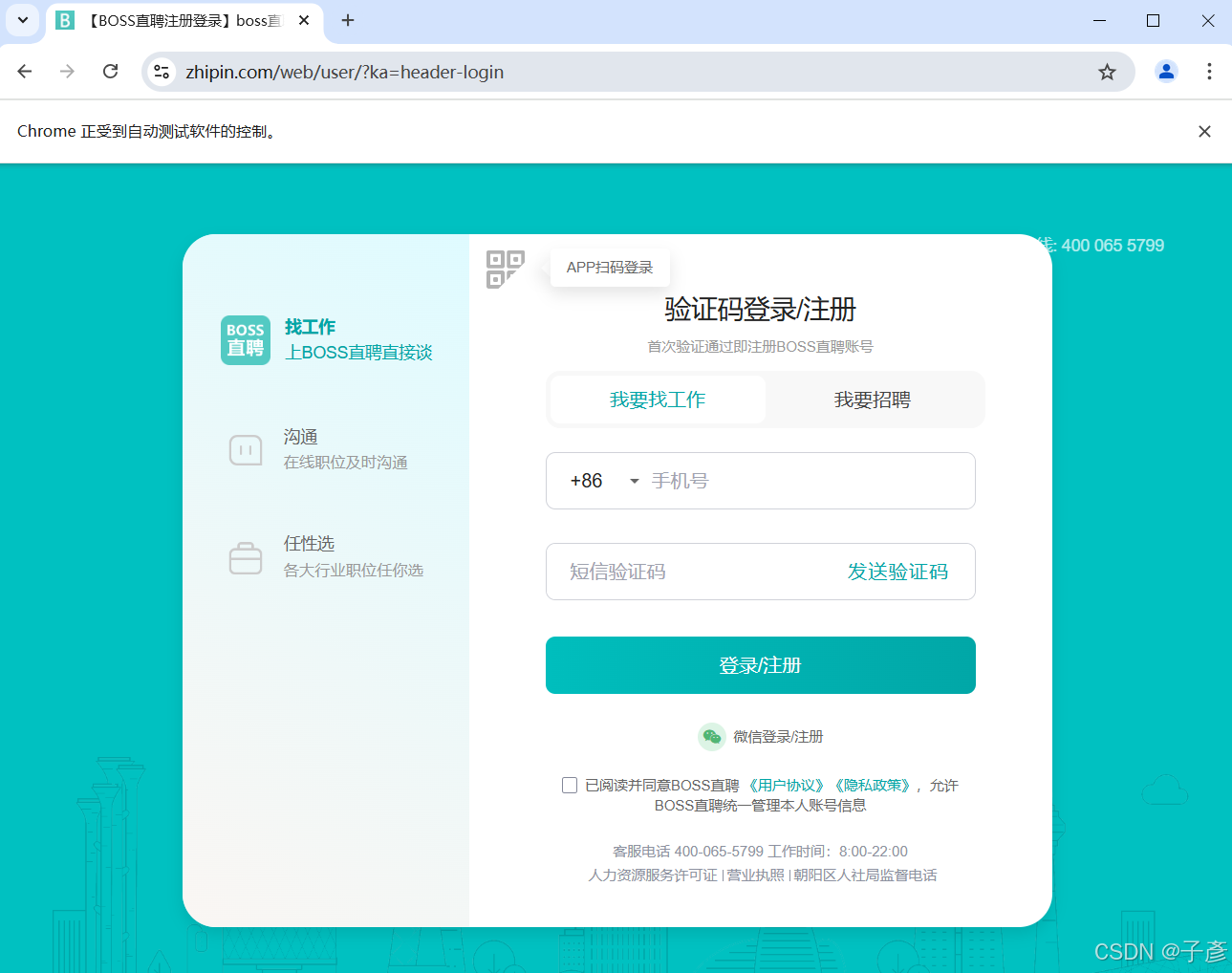
登录完之后,那我们就要进入到自己指定的页面。图一中我的想法是查找数据分析岗的全职岗位的信息,那么我在自己单独设置后筛选后选择后几页的网站,可以发现网站的规律,在后几页中有page=X,也就说明我们可以通过遍历直达多个页面,然后我实验了虽然第一页不会显示page等于1,但是你把这个加在后面同样可以出来这个页面,那么代码如下:
# 创建一个空列表,用于存储所有岗位数据,放在循环外面,实现数据收集不被覆盖
jobs_data = []
# 遍历每一页
for page in range(1, 11):
# 构造每页的 URL
url = f"https://www.zhipin.com/web/geek/job?city=100010000&position=100511&jobType=1901&page={page}"
# 打开目标页面
driver.get(url)
# 等待页面加载完成
time.sleep(30) # 根据实际情况调整等待时间
# 获取页面源代码
html_content = driver.page_source
# 解析 HTML
html = etree.HTML(html_content)
# 提取数据(根据实际 HTML 结构调整 XPath)
#job_list = html.xpath('//div[@class="job-list"]/ul/li')
job_list = html.xpath('//div[@class="search-job-result"]/ul/li')job_list是可以输出的,调试代码时可以print一下,看是否有内容,一般就是一堆代码,咱也不懂,但是一数刚好和页面数量对上了,那就没问题。
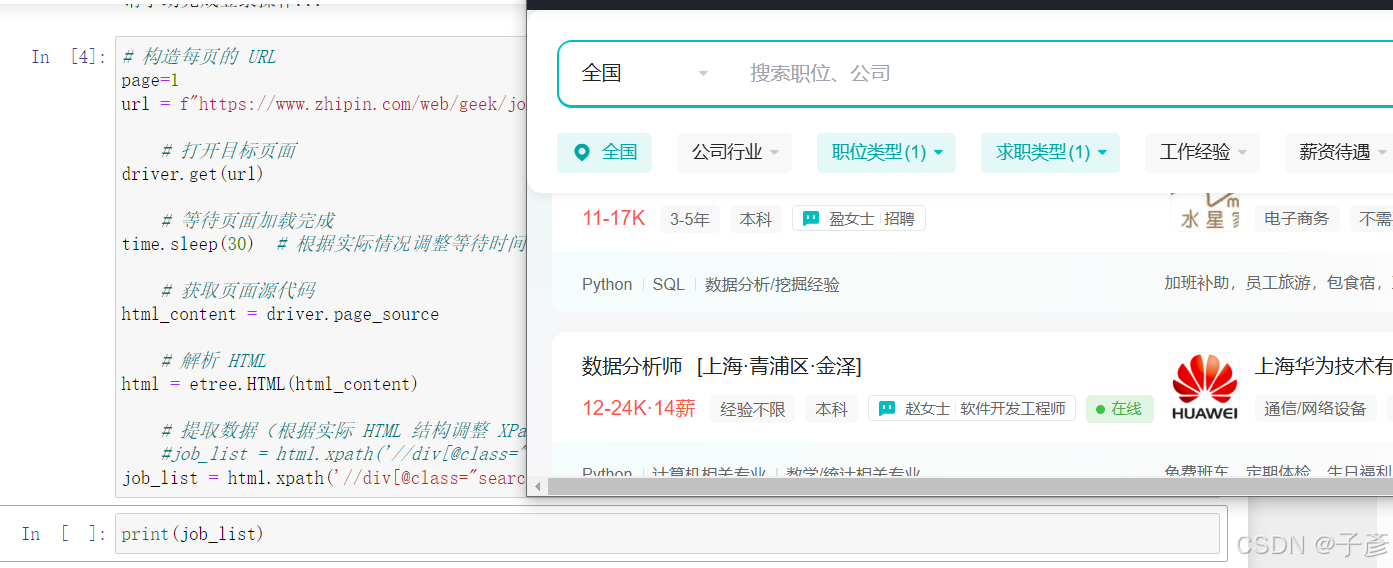
给大家亲自展示一下。画面中可以正常打开网页,而且jupyter运行完没有报错。
然后就会显示这个,数数一共30个,对得上。
导出数据
最后数据都在job_data里面,导出为Excel表格,这一步很简单。
# 使用 pandas 创建 DataFrame
df = pd.DataFrame(jobs_data)
# 导出为 CSV 文件
df.to_csv("bosszp_jobs_data2.csv", index=False, encoding="utf-8-sig")
print("数据已成功导出到 bosszpjobs_data.csv 文件中!")完整代码
下面是完整代码,包括要导入哪些包,这些包建议大家一个个试,没装的pip装一下就好,有什么问题也可以问问kimi(老打工人了)。
import time
import pandas as pd
from lxml import etree
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support import expected_conditions as EC
# 设置 Selenium 驱动
driver = webdriver.Chrome() # 确保已安装 ChromeDriver
# 打开Boss直聘登录页面
driver.get("https://www.zhipin.com/web/user/?ka=header-login")
# 手动登录
print("请手动完成登录操作...")
time.sleep(30) # 等待用户手动登录(根据实际情况调整时间)
# 创建一个空列表,用于存储所有岗位数据,放在循环外面,实现数据收集不被覆盖
jobs_data = []
# 遍历每一页
for page in range(1, 11):
# 构造每页的 URL
url = f"https://www.zhipin.com/web/geek/job?city=100010000&position=100511&jobType=1901&page={page}"
# 打开目标页面
driver.get(url)
# 等待页面加载完成
time.sleep(30) # 根据实际情况调整等待时间
# 获取页面源代码
html_content = driver.page_source
# 解析 HTML
html = etree.HTML(html_content)
# 提取数据(根据实际 HTML 结构调整 XPath)
#job_list = html.xpath('//div[@class="job-list"]/ul/li')
job_list = html.xpath('//div[@class="search-job-result"]/ul/li')
# 遍历每个岗位
for job in job_list: # 如果需要测试,可以先只爬取每页的前两条数据
# 提取岗位名称
job_name = job.xpath(".//span[@class='job-name']/text()")[0] if job.xpath('.//span[@class="job-name"]/text()') else "未知"
# 提取工作地点
job_area = job.xpath('.//span[@class="job-area"]/text()')[0] if job.xpath('.//span[@class="job-area"]/text()') else "未知"
# 详情页url
prefix = "https://www.zhipin.com"
detail_url = prefix + job.xpath('.//a/@href')[0]
# 提取薪资
salary = job.xpath('.//span[@class="salary"]/text()')[0] if job.xpath('.//span[@class="salary"]/text()') else "未知"
# 提取工作经验
experience = job.xpath('.//ul[@class="tag-list"]/li[1]/text()')[0] if job.xpath('.//ul[@class="tag-list"]/li[1]/text()') else "未知"
# 提取公司名称
company_name = job.xpath('.//h3[@class="company-name"]/a/text()')[0] if job.xpath('.//h3[@class="company-name"]/a/text()') else "未知"
# 公司类型和人数等
companyScale_list = job.xpath('.//div[@class="company-info"]/ul//text()')
companyScale = " ".join(companyScale_list)
# 提取学历要求
education = job.xpath('.//ul[@class="tag-list"]/li[2]/text()')[0] if job.xpath('.//ul[@class="tag-list"]/li[2]/text()') else "未知"
# 打开详情页
driver.get(detail_url)
# 增加等待时间,确保页面加载完成
try:
WebDriverWait(driver, 30).until(
EC.presence_of_element_located((By.CLASS_NAME, "job-sec-text"))
)
except TimeoutException:
print(f"超时:详情页 {detail_url} 加载超时")
continue # 跳过当前岗位,继续处理下一个岗位
# 获取页面源代码
detail_html_content = driver.page_source
# 解析 HTML
detail_html = etree.HTML(detail_html_content)
# 提取岗位标签
job_tags = detail_html.xpath('//ul[@class="job-keyword-list"]/li/text()')
job_tags = ", ".join([tag.strip() for tag in job_tags if tag.strip()]) if job_tags else "未知"
# 提取具体描述
job_detail = detail_html.xpath('//div[@class="job-sec-text"]/text()')
job_detail = "\n".join([line.strip() for line in job_detail if line.strip()]) if job_detail else "未知"
# 将提取的数据添加到列表中
jobs_data.append({
"岗位名称": job_name,
"工作地点": job_area,
"公司名称": company_name,
"薪资范围": salary,
"工作经验": experience,
"学历要求": education,
"公司类型": companyScale,
"岗位标签": job_tags,
"具体描述": job_detail,
"详情页url": detail_url
})
time.sleep(60)
# 使用 pandas 创建 DataFrame
df = pd.DataFrame(jobs_data)
# 导出为 CSV 文件
df.to_csv("bosszp_jobs_data.csv", index=False, encoding="utf-8-sig")
print("数据已成功导出到 bosszpjobs_data.csv 文件中!")
就是这么多啦,简单粗暴的代码,不过看着程序自己调动网站蹦来蹦去真的很快乐。
我是子彦,信管专业的小菜菜,第一次写博客没有想那么多,也是自己成长的一个记录吧,欢迎大家关注我,在评论区相互讨论,大家有问题我也尽力解答,代码拿走自己玩吧,希望不会被拿去卖了,那我就是为爱发光啦呜呜呜,喜欢的话可以点个赞嘛,一个赞我能开心很久滴!

















 600
600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









