






一、哈希表
哈希表,也称为散列表,是一种数据结构,它利用散列函数将关键码值(通常是数据的某个特征)映射到表中一个位置来访问记录,这样可以加快查找和插入的速度。
怎么去理解呢?举个简单的例子:
假设现在有个数组a如下:
| 7 | 12 | 3 | 4 | 8 | 5 | 20 | 9 | 6 | 1 |
这是一个长度为10的数组,如果我们要查找key = 4是否存在数组a中,原始方法为:
#include <stdio.h>
int a[10] = {7,12,3,4,8,5,20,9,6,1};
int find_key(int a[], int n, int key){
for(int i = 0; i < n; i++){
if(key = a[1]){
return 1;
}
}
return 0;
}
这种方式虽然简单直接,但是效率很低,如果数组长度为100,1000甚至10000呢,而且如果要同时查找多个数的话,如:
int main()
{
int a[] = {7,12,3,4,8,5,20,9,6,1};
//循环查找1,2,3到10,这十个数字是否存在于数值中
for(int i = 1; i <=10; i++)
{
if(find key(a, 10, i)){
printf('%d is in array.\n', i);
}
else{
printf('%d is not in array.\n', i);
}
}
return 0;
}
从数组中判断1,2,3到10这10个数字是否存在,每次都需要调用find_key函数,都要比较n次,查询的时间复杂度为O(n),结合查询次数也为n,整体的复杂度就是O(n*2)
那是否存在一种算法,每次查找的复杂度都为常数级0(1),也就是查找效率与待查表中的元素数量是无关的,这种方法就是哈希表:
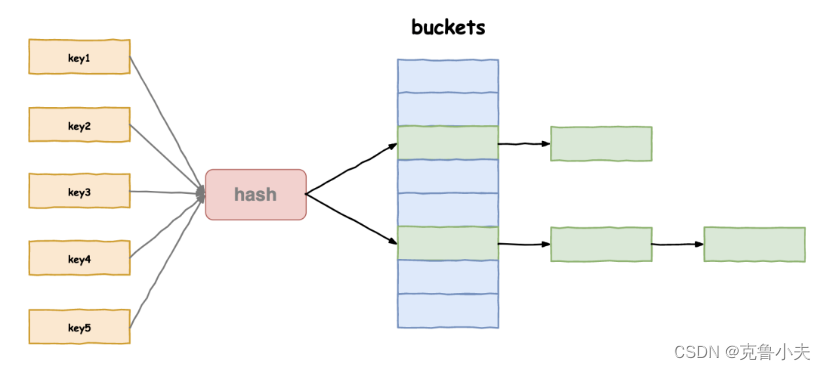
关于 哈希表的实现方法我们可以举个例子:
定义数值:a[100] = {0}
使用数组下标记录元素是否存在以及出现次数:
如:a[1] = 1,则1出现了一次
table:
| 数组参数 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ... | 100 |
代码实现:
//建立哈希表的函数
void create_hash(int a[], int n, int table[])
{
//循环遍历数组a中的所有元素
for (int i = 0; i < n; i++)
{
//通过a[i]中的元素对应table数组的下标,并使其参数++
table[a[i]]++;
}
}
int main()
{
int a[] = { 7,12,3,5,8,5,12,12,6,1 };
//创建哈希表
int table[100] = { 0 };
create_hash(a, 10, table);
//完成哈希表建立,遍历数组
for (int i = 0;i < 100; i++)
{
//如果参数大于0则说明数组a出现过
if (table[i] > 0)
{
printf("%d appear %d times.\n", i, table[i]);
}
}| 数组参数 | 1 | 0 | 1 | 0 | 2 | 1 | 1 | 1 | 0 | 0 | 0 | 3 | ... | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | ... | 100 |
代码2:查找哈希表中是否存在key值
int find_key(int table[], int key)
{
return table[key] != 0;
}
int main()
{
int a[] = { 7,12,3,4,8,5,20,9,6,1 };
//创建哈希表
int table[100] = { 0 };
create_hash(a, 10, table);
for (int i = 0;i < 100; i++)
{
if (find_key(table, i))
{
printf("%d is in a.\n", i );
}
else
{
printf("%d is not in a.\n", i);
}
}
}二、哈希函数
以上实例参数类型都为int,如果要使用浮点型,对象等更复杂的数据类型,这需要使用到哈希函数,它通过设计将输入数据映射到固定大小的输出值,这个过程通常被称为散列。
意思就是将数据转换为哈希表长范围内的整数,将这个整数作为数组下标,访问哈希表。
如字符串的哈希函数:
#define MAX_TABLE_LEN 100
int string_func(const char* key)
{
int sum = 0;
while (*key)//遍历字符串
{
sum += *key;//将字符对应的ASCII表的数相加
key++;
}
return sum % MAX_TABLE_LEN;//取余表长的到哈希值
}如字符串‘hello’,每个字符对应的ASCII码值相加为:h: 104 e: 101 l: 108 l: 108 o: 111
总和为:532
假如表长为100(数组a长度100),532%100 = 32
得到下表为:32
| 数组参数 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ... | 1 | ... | 0 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 下标 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 32 | ... | 100 |
还有其他常见实用的哈希函数,简单了解:
- MD5:数据填充:首先对输入的数据进行填充,确保其长度满足特定条件。具体来说,原始数据会被加上一个特定的值(通常是128位的长度字段和一个64位的初始值),使得填充后的数据长度模512的余数为448。分组处理:将填充后的数据分割成512位(64字节)的小组,每个小组再细分为16个32位的子组。压缩函数:针对每个子组,应用一系列位操作和模运算,这包括逻辑函数、加常数等操作。这些操作的结果会进一步参与下一轮的操作。输出生成:将上述过程中产生的16个32位的中间结果累加,最终得到一个128位的散列值。
- SHA-1:它可以产生一个160位的散列值。与MD5相比,它提供了更长的散列值,但同样由于安全性问题
还有SHA-256、SHA-3等
需要注意的是,为了避免内存资源的浪费,我们制定表长时合理制定。
设定哈希表长度的通用指导原则:
- 避免频繁扩容:哈希表的长度通常是固定的,且在存储数据前应预先确定。合理的大小能够减少因频繁扩容造成的性能损耗。
- 减少哈希冲突:理想情况下,哈希表的大小应当足够大,以减少数据项之间的冲突,从而提高存取效率。
- 空间利用率:同时,过大的哈希表会浪费内存空间。因此,大小选择需要平衡冲突率与空间使用率,确保高效利用内存资源。
- 素数选择:通常建议将哈希表的大小设为一个素数,因为当哈希表的总长度为素数时,能够帮助分散哈希值,降低冲突的可能性。
所以对于超出表长的哈希值,我们同样可以进行取余
二、哈希冲突
从上面的例子我们可以发现一个问题,字串串‘hello’和整形532,或者字符串‘hello’和‘helol’,他们经过哈希函数得到的哈希值都是相同的,映射到同一个数组下标。这不就冲突了吗?
这就是哈希冲突,即不同的数据项通过同一个哈希函数产生了相同的哈希值,从而映射到哈希表中相同的位置。
解决冲突的方法有多种,常见的比如开放地址法,链地址法等,简单解释:
- 开发地址法:如果两个键的哈希值相同,那么后插入的元素会查找哈希表中下一个空闲的位置,查找的过程通常是线性探测(单向寻找)、二次探测(前后寻找)或双重散列。
- 链地址法: 将每个哈希表的槽位作为一个链表的头结点。当发生冲突时,具有相同哈希值的元素会被添加到相应槽位的链表中。
总结,哈希算法出了可以快速查找,还有其他实用的地方:
- 安全加密:哈希算法在安全加密领域得到了广泛应用。例如,用户密码的存储通常会使用MD5或SHA等哈希函数进行加密,由于其不可逆的特性,即使数据被盗取,也难以破解原始密码,从而保障了安全性。
- 唯一标识:哈希算法能够将数据映射为固定长度的字符串,这可以用来生成数据的唯一标识。例如,通过MD5处理URL或图片字段,可以得到32位长度的唯一标识,这有助于数据库索引构建和查询,以及快速判定重复文件等场景。
- 数据校验:在网络上下载文件时,常常会用到MD5值来校验数据的完整性。这样可以避免数据在传输过程中被篡改或劫持,确保用户下载到的文件是完整且未经修改的。
- 散列函数:在编程实践中,哈希算法常用于构建哈希表等数据结构,以实现快速的查找和访问。通过哈希函数将键转换为数组索引,可以快速定位到相应的值。
- 区块链技术:区块链的底层原理之一就是哈希算法。在区块链中,哈希算法用于确保每个区块的唯一性和完整性,同时也连接着区块链中的前后区块,形成了一个不可篡改的链条。















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









