






 OpenAI发布了视频生成模型Sora,被称赞为视频生成领域的GPT-3。Sora凭借其准确性和多样性、强大的语言理解、图像/视频编辑能力、视频扩展功能以及设备适配性,预示着人工智能在视频制作上的重大进步,可能加速向通用人工智能(AGI)靠近。
OpenAI发布了视频生成模型Sora,被称赞为视频生成领域的GPT-3。Sora凭借其准确性和多样性、强大的语言理解、图像/视频编辑能力、视频扩展功能以及设备适配性,预示着人工智能在视频制作上的重大进步,可能加速向通用人工智能(AGI)靠近。
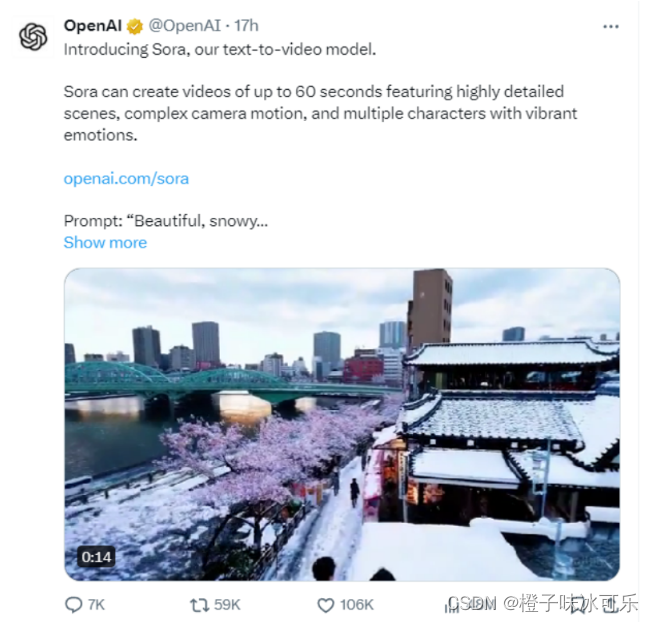
当地时间2月15日,OpenAI发布了最新的视频生成模型Sora
出色的视频制作能力瞬间“点燃”科技圈
英伟达人工智能研究院首席研究科学家Jim Fan直言,这是视频生成领域的GPT-3时刻
360集团创始人、董事长周鸿祎则称,随着Sora的到来,人类离AGI真的就不远了,不是10年、20年的问题,可能一两年很快就可以实现
OpenAI首席执行官阿尔特曼在X平台上发布了一系列视频,精美的场景让用户惊叹不已
而这些视频全都是通过OpenAI 2月15日发布的最新视频生成模型Sora制作的,用户震惊之余,也给予了Sora高度评价,将其描述为“绝无仅有”和“游戏规则改变者”
英伟达人工智能研究院首席研究科学家Jim Fan也对Sora的能力发出感叹,称这是视频生成领域的GPT-3时刻。
他表示,Sora是一个“数据驱动的物理引擎”,一个可学习的模拟器或“世界模型”。
360集团创始人、董事长周鸿祎则称,随着Sora的到来,人类离AGI真的就不远了,不是10年、20年的问题,可能一两年很快就可以实现
技术报告揭秘Sora六大核心优势
(1)准确性和多样性:Sora的显著特征之一是能够准确解释长达135个单词的长提示。
它可以准确地解释用户提供的文本输入,并生成具有各种场景和人物的高质量视频剪辑。这一新工具可将简短的文本描述转化成长达1分钟的高清视频。
它涵盖了广泛的主题,从人物和动物到郁郁葱葱的风景、城市场景、花园,甚至是水下的纽约市,可根据用户的要求提供多样化的内容。
(2)强大的语言理解:OpenAI利用Dall-E模型的re-captioning(重述要点)技术,生成视觉训练数据的描述性字幕,不仅能提高文本的准确性,还能提升视频的整体质量。
此外,与DALL·E 3类似,OpenAI还利用GPT技术将简短的用户提示转换为更长的详细转译,并将其发送到视频模型。
这使Sora能够精确地按照用户提示生成高质量的视频。
(3)以图/视频生成视频:Sora除了可以将文本转化为视频,还能接受其他类型的输入提示,如已经存在的图像或视频。
这使Sora能够执行广泛的图像和视频编辑任务,如创建完美的循环视频、将静态图像转化为动画、向前或向后扩展视频等。
OpenAI在报告中展示了基于DALL·E 2和DALL·E 3的图像生成的demo视频。
这不仅证明了Sora的强大功能,还展示了它在图像和视频编辑领域的无限潜力。
(4)视频扩展功能:由于可接受多样化的输入提示,用户可以根据图像创建视频或补充现有视频。
作为基于Transformer的扩散模型,Sora还能沿时间线向前或向后扩展视频。
从OpenAI提供的4个demo视频看,都从同一个视频片段开始,向时间线的过去进行延伸。
因此,尽管开头不同,但视频结局都是相同的。
(5)优异的设备适配性:Sora具备出色的采样能力,从宽屏的1920x1080p到竖屏的1080x1920,两者之间的任何视频尺寸都能轻松应对。
这意味着Sora能够为各种设备生成与其原始纵横比完美匹配的内容。
而在生成高分辨率内容之前,Sora还能以小尺寸迅速创建内容原型。
(6)场景和物体的一致性和连续性:Sora可以生成带有动态视角变化的视频,人物和场景元素在三维空间中的移动会显得更加自然。
Sora 能够很好地处理遮挡问题。现有模型的一个问题是,当物体离开视野时,它们可能无法对其进行追踪。
而通过一次性提供多帧预测,Sora可确保画面主体即使暂时离开视野也能保持不变。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











