






目录
7.4.2 SHA-1, SHA-256, SHA-384, SHA-512
7.5.3 SHA-3 最终候选名单的确定与 SHA-3 的最终确定
第七章
7.1 本章学习的内容
在刑事侦查中,侦查员会用到指纹。通过将某个特定人物的指纹与犯罪现场遗留的指纹进行对比,就能够知道该人物与案件是否存在关联。
针对计算机所处理的消息,有时候我们也需要用到“指纹”。当需要比较两条消息是否一致时,我们不必直接对比消息本身的内容,只要对比它们的“指纹”就可以了。
本章中,我们将学习单向散列函数的相关知识。使用单向散列函数就可以获取消息的“指纹”,通过对比“指纹”,就能够知道两条消息是否一致。
下面,我们会先简单介绍一下单向散列函数,并给大家展示具体的例子。然后再向大家介绍 SHA-1、SHA-2、SHA-3这几种单向散列函数,并对新晋单向散列函数 SHA-3 (Keccak)的结构进行讲解。此外,我们还将思考一下对单向散列函数的攻击方法。
7.2 什么是单向散列函数
首先,我们先通过 Alice的一段故事,介绍一个可能用到单向散列函数的场景。然后,我们再来讲解单向散列函数所需要具备的性质。
7.2.1 这个文件是不是真的呢
Alice在公司里从事软件开发工作。一天晚上,她的软件终于完成了,接下来只要把文件从Alice的电脑中复制出来并制作成母盘就可以了。
不过,Alice已经很累了,她决定今天晚上早点回家休息,明天再继续弄。
第二天, Alice来到公司准备把文件从自己的电脑中复制出来,但她忽然产生了这样的疑问:
“这个文件和我昨天晚上生成的文件是一样的吗?
”Alice的疑问是这样的--会不会有人操作Alice的计算机,将文件改写了呢?就算没有人直接来到 Alice的座位上,也有可能通过网络入侵 Alice的计算机。或者,也许 Alice的计算机感染了病毒,造成文件被篡改……在这里,是人干的还是病毒干的并不重要,我们姑且把篡改文件的这个主体称为“主动攻击者 Mallory”。总而言之,Alice 需要知道从昨天到今天的这段时间内,Mallory是否篡改了文件的内容。
现在,Alice 想知道自己手上的文件是不是真的。如果这个文件和昨天晚上生成的文件一模一样,那它就是真的;但只要有一点点不一样,哪怕是只有一个比特有所不同、增加或者减少,它就不是真的。这种“是真的”的性质称为完整性(integrity),也称为一致性。也就是说,这里 Alice 需要确认的,是自己手上的文件的完整性。
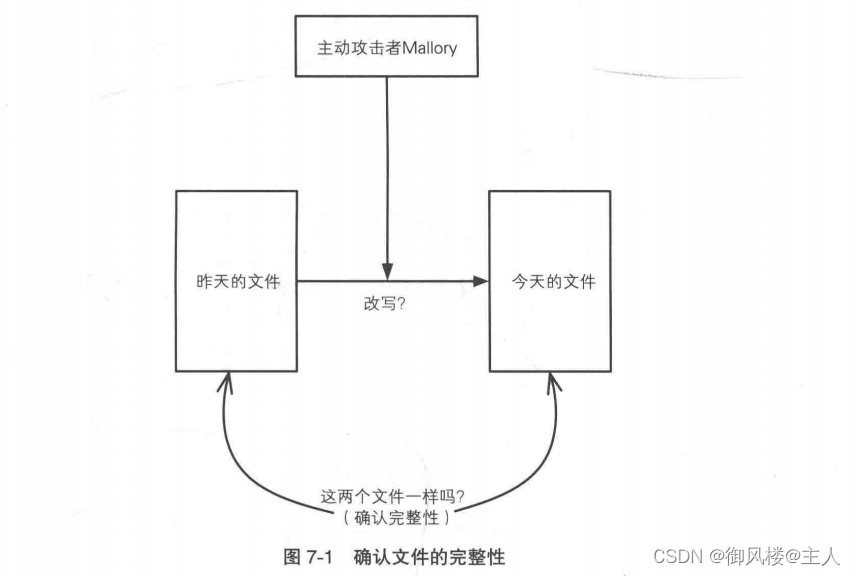
这里所说的是不是真的的问题,和Alice编写的软件里面有没有bug是两码事。文件的内容是通过比特序列来表现的,我们需要知道的是昨晚的文件的比特序列与现在手上的文件的比特序列是否完全一致。
稍微想一想我们就能找到一种确认文件完整性的简单方法——在回家之前先把文件复制到一个安全的地方保存起来,第二天在用这个文件工作之前,先将其和事先保存的文件进行对比就可以了(图 7-2)。如果两者一致,那就说明文件没有被篡改。
不过,这种确认完整性的方法其实是毫无意义的。因为如果可以事先把文件保存在一个安全的地方,那根本就不需要确认完整性,直接用事先保存的文件来工作不就行了吗?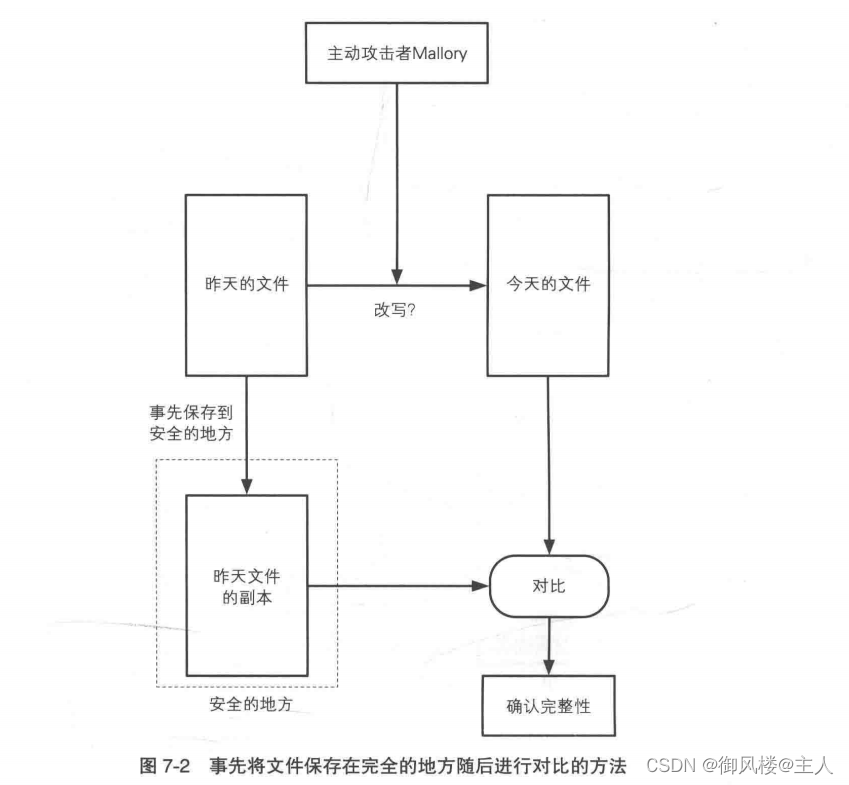
此外还存在一个效率的问题。如果需要确认完整性的文件非常巨大,那么文件的复制、保存以及比较都将非常耗时。
这里就轮到本章将要介绍的方法出场了。就像刑事侦查中获取指纹一样,我们能不能获取到Alice所生成的文件的“指纹”呢?如果我们不需要对整个巨大的文件进行对比,只需要对比一个较小的指纹就能够检查完整性的话,那该多方便啊(图 7-3)。
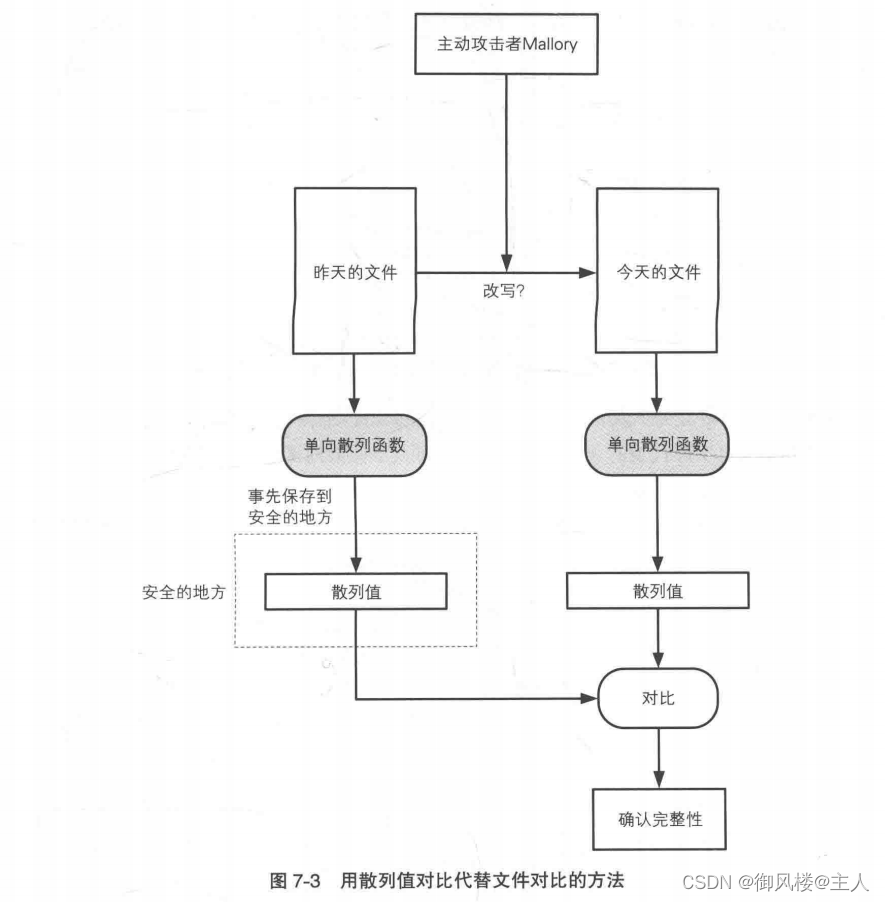
本章中要介绍的单向散列函数,就是一种采集文件“指纹”的技术。单向散列函数所生成的散列值,就相当于消息的“指纹”。
7.2.2 什么是单向散列函数
单向散列函数(one-way hash function)有一个输入和一个输出,其中输入称为消息(message),输出称为散列值(hash value)(图7-4)。单向散列函数可以根据消息的内容计算出散列值,而散列值就可以被用来检查消息的完整性。
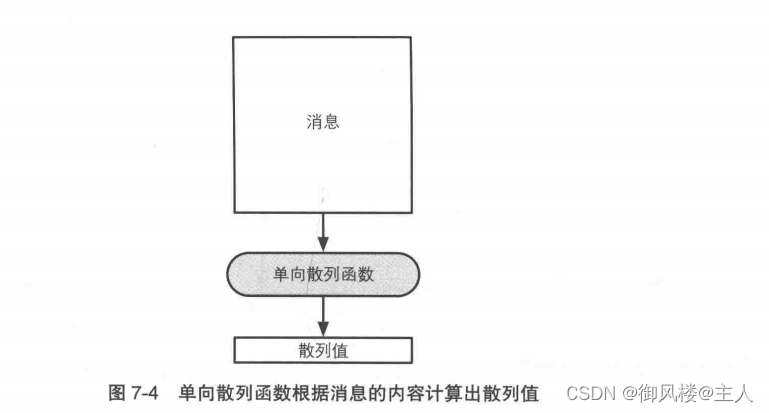
这里的消息不一定是人类能够读懂的文字,也可以是图像文件或者声音文件。单向散列函数不需要知道消息实际代表的含义。无论任何消息,单向散列函数都会将它作为单纯的比特序列来处理,即根据比特序列计算出散列值。
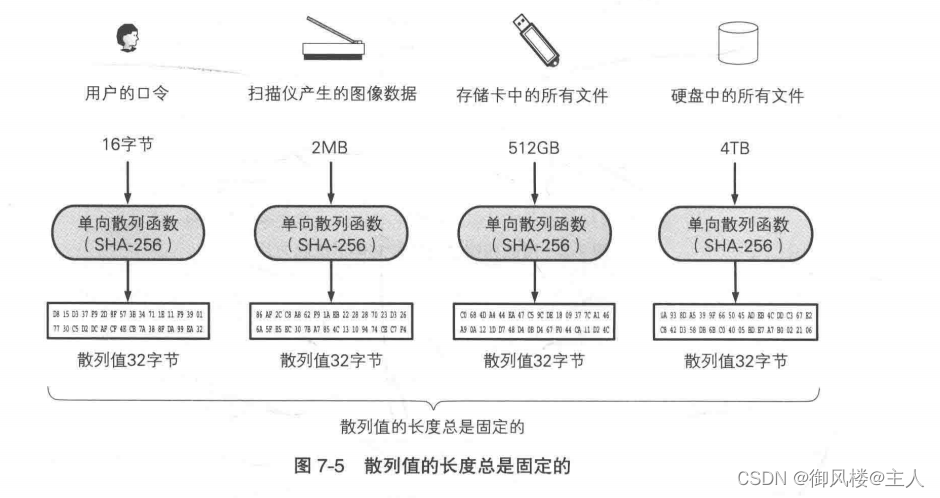
散列值的长度和消息的长度无关。无论消息是1比特,还是100MB,甚至是100GB,单向散列函数都会计算出固定长度的散列值。以SHA-256单向散列函数为例,它所计算出的散列值的长度永远是256比特(32字节)(图7-5)。
由于散列值很短,因此很容易处理和使用。我们来看看如何将它适用于上一节Alice的故事中。
回家之前, Alice用单向散列函数计算文件的散列值。在这里, Alice的文件就相当于消息。假设她计算出的散列值如下:
29 E2 F8 30 A5 A7 BE 60 50 4D 97 65 0C BD 5B F5 CD B5 E0 C4 25 23 61 44 3C D0 16 2B 7E 9C 45 0A
单向散列函数所输出的散列值的长度是固定的(在这个例子中是 32 字节),无论 Alice 的文件大小是几百MB,甚至是几GB,散列值的长度永远是32字节(256比特)。Alice可以将这个值打印出来,或者是保存在软盘等安全的地方,拿回家藏在枕头下面也行(只要这个地方是安全的)。
第二天早上,Alice 再次计算硬盘中文件的散列值,如果再次计算出的散列值为:
29 E2 F8 30 A5 A7 BE 60 50 4D 97 65 0C BD 5B F5 CD B5 E0 C4 25 23 61 44 3C D0 16 2B 7E 9C 45 0A
和昨晚的散列值一致,就可以判断文件是真的。只要单向散列函数工作正常,那么“只要散列值相等,消息就相等”这个判断就有很高的概率是成立的。如果再次计算出的散列值像下面这样:
3B 57 B5 95 16 8C 49 81 EE 78 41 DC 7A BB F4 64 5A 14 81 23 2F 34 44 AC 33 E5 42 DD 3C 18 E0 C3
和昨晚的散列值不一致,那么这个文件和昨晚的文件就绝对是不一样的。
上面我们介绍了单向散列函数的用法。其中的关键点在于,要确认完整性,我们不需要对比消息本身,而只要对比单向散列函数计算出的散列值就可以了。
7.2.3 单向散列函数的性质
通过使用单向散列函数,即便是确认几百MB大小的文件的完整性,也只要对比很短的散列值就可以了。那么,单向散列函数必须具备怎样的性质呢?我们来整理一下。
根据任意长度的消息计算出固定长度的散列值
首先,单向散列函数的输入必须能够是任意长度的消息。其次,无论输入多长的消息,单向散列函数必须都能够生成长度很短的散列值,如果消息越长生成的散列值也越长的话就不好用了。从使用方便的角度来看,散列值的长度最好是短且固定的。
能够快速计算出散列值
计算散列值所花费的时间必须要短。尽管消息越长,计算散列值的时间也会越长,但如果不能在现实的时间内完成计算就没有意义了。
消息不同散列值也不同
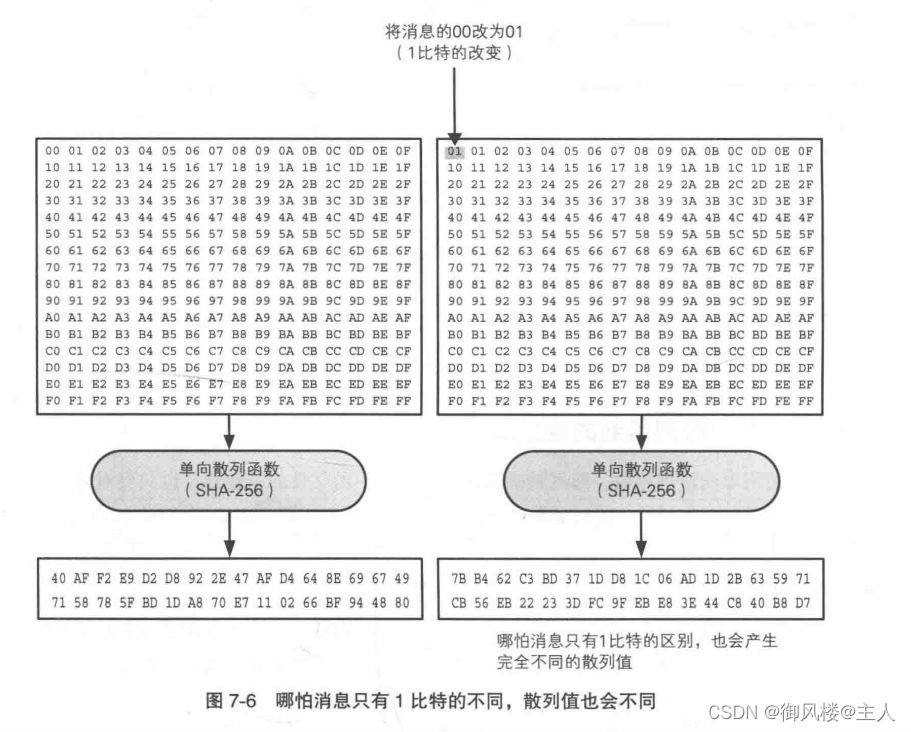
为了能够确认完整性,消息中哪怕只有 1 比特的改变,也必须有很高的概率产生不同的散列值(图 7-6)。
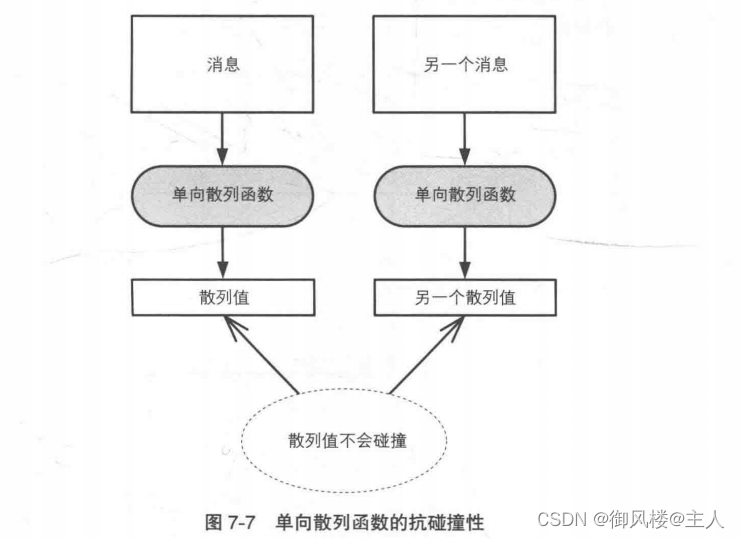
如果单向散列函数计算出的散列值没有发生变化,那么消息很容易就会被篡改,这个单向散列函数也就无法被用于完整性的检查。两个不同的消息产生同一个散列值的情况称为碰撞(collision)。如果要将单向散列函数用于完整性的检查,则需要确保在事实上不可能被人为地发现碰撞。
难以发现碰撞的性质称为抗碰撞性(collision resistance)。密码技术中所使用的单向散列函数,都需要具备抗碰撞性(图7-7)。
我们以 Alice 用单向散列函数来检查文件完整性的场景为例,讲解一下什么是抗碰撞性。现在,我们假设Alice所使用的单向散列函数不具备抗碰撞性。
Alice在回家之前得到了下面的散列值。
29 E2 F8 30 A5 A7 BE 60 50 4D 97 65 ос BD 5B F5 CD B5 E0 C4 25 23 61 44 3C DO 16 2B 7E 9C 45 OA
Alice在睡觉的时候,主动攻击者Mallory入侵了Alice的计算机,并改写了Alice的文件。
由于我们假设Alice的单向散列函数不具备抗碰撞性,因此Mallory能够找到一种改写文件的方法,使得改写后文件的散列值不发生变化。于是,虽然Mallory改写了文件,但散列值没有发生变化。
第二天早上, Alice重新计算散列值,得到了下面的结果。
29 E2 F8 30 A5 A7 BE 60 50 4D 97 65 ос BD 5B F5 CD B5 E0 C4 25 23 61 44 3C DO 16 2B 7E 9C 45 OA
这个结果和昨晚的散列值一致,Alice松了一口气。但是,实际上Mallory已经改写了文件,Alice则将Mallory改写后的文件复制出来并制作成了母盘。
这里所说的抗碰撞性,指的是难以找到另外一条具备特定散列值的消息。当给定某条消息的散列值时,单向散列函数必须确保要找到和该条消息具有相同散列值的另外一条消息是非常困难的。这一性质称为弱抗碰撞性。单向散列函数都必须具备弱抗碰撞性。
和弱抗碰撞性相对的,还有强抗碰撞性。所谓强抗碰撞性,是指要找到散列值相同的两条不同的消息是非常困难的这一性质。在这里,散列值可以是任意值。
密码技术中所使用的单向散列函数,不仅要具备弱抗碰撞性,还必须具备强抗碰撞性。
具备单向性
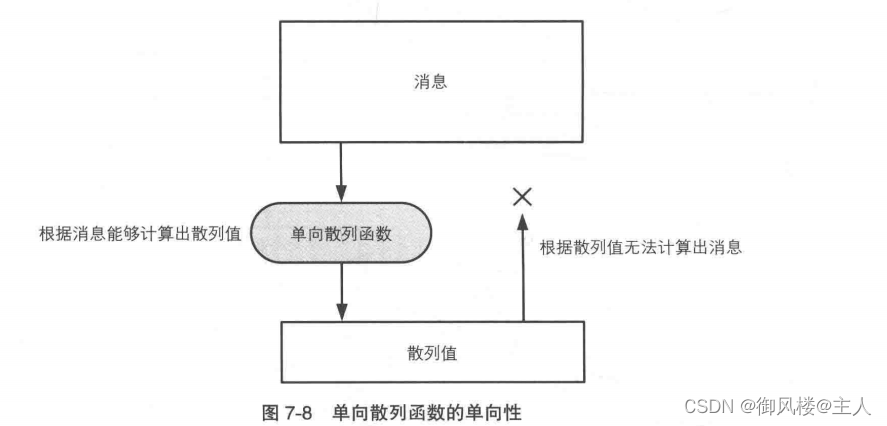
单向散列函数必须具备单向性(one-way)。单向性指的是无法通过散列值反算出消息的性质。根据消息计算散列值可以很容易,但这条单行路是无法反过来走的(图 7-8)。
正如同将玻璃砸得粉碎很容易,但却无法将碎片还原成完整的玻璃一样,根据消息计算出散列值很容易,但根据散列值却无法反算出消息。
单向性在单向散列函数的应用中是非常重要的。例如,我们后面要讲到的基于口令的加密和伪随机数生成器等技术中,就运用了单向散列函数的单向性。
在这里需要注意的一点是,尽管单向散列函数所产生的散列值是和原来的消息完全不同的比特序列,但是单向散列函数并不是一种加密,因此无法通过解密将散列值还原为原来的消息。
7.2.4 关于术
语单向散列函数的相关术语有很多变体,各种参考书中所使用的术语也有所不同,下面我们就介绍其中的几个。
单向散列函数也称为消息摘要函数(message digest function)、哈希函数或者杂凑函数。
输入单向散列函数的消息也称为原像(pre-image )。
单向散列函数输出的散列值也称为消息摘要( message digest)或者指纹(fingerprint )。
完整性也称为一致性。
顺便说一句,单向散列函数中的“散列”的英文“hash”一词,原意是古法语中的“斧子”,后来被引申为“剁碎的肉末”,也许是用斧子一通乱剁再搅在一起的那种感觉吧。单向散列函数的作用,实际上就是将很长的消息剁碎,然后再混合成固定长度的散列值。
---------------------------------------------------------------------------------------------------------------------------------
小测验 1 抗碰撞性 (答案见 7.11 节)
听了关于抗碰撞性的讲解, Alice产生了这样的想法。为什么要用“难以发现碰撞”这样模棱两可的性质呢?设计一种“不存在碰撞”的单向散列函数不是更好吗?但是, Alice的想法是错误的,你知道为什么吗?
---------------------------------------------------------------------------------------------------------------------------------
7.3 单向散列函数的实际应用
下面我们来看一些实际应用单向散列函数的例子。
7.3.1 检测软件是否被篡
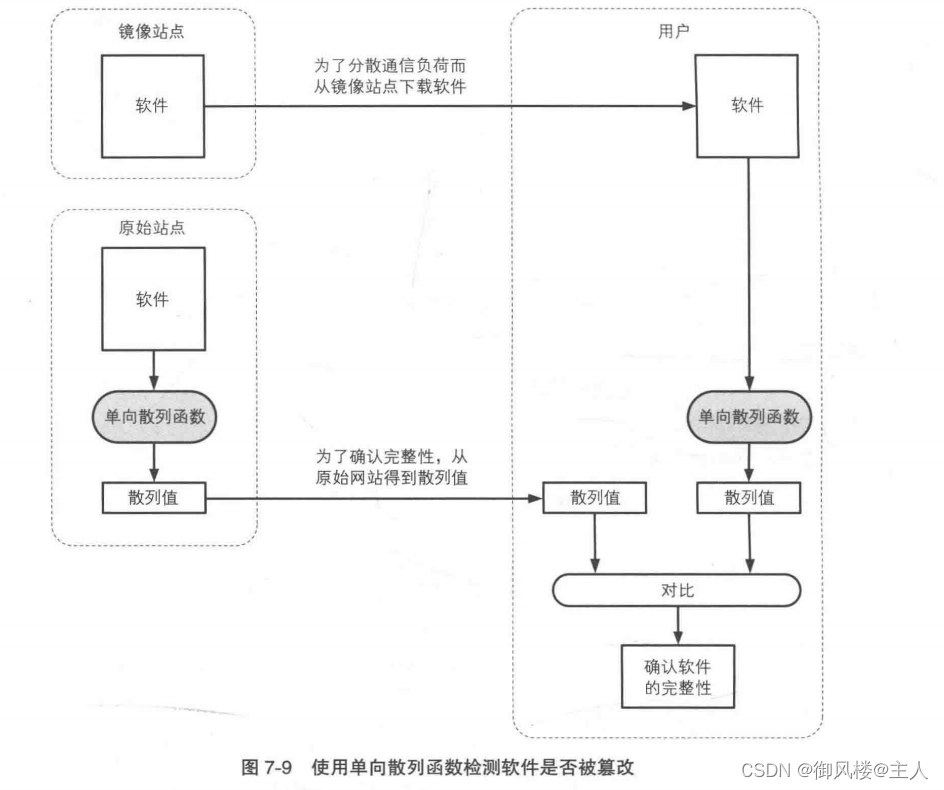
改我们可以使用单向散列函数来确认自己下载的软件是否被篡改。
很多软件,尤其是安全相关的软件都会把通过单向散列函数计算出的散列值公布在自己的官方网站上。用户在下载到软件之后,可以自行计算散列值,然后与官方网站上公布的散列值进行对比。通过散列值,用户可以确认自己所下载到的文件与软件作者所提供的文件是否一致。
这样的方法,在可以通过多种途径得到软件的情况下非常有用。为了减轻服务器的压力,很多软件作者都会借助多个网站(镜像站点)来发布软件,在这种情况下,单向散列函数就会在检测软件是否被篡改方面发挥重要作用。
---------------------------------------------------------------------------------------------------------------------------------
小测验 2 单向散列函数的误用 (答案见 7.11 节)
Alice想要知道自己所制作的一个名为 game.exe 的文件在自己睡觉的这段时间有没有被改写。于是 Alice 计算了 game.exe 这个文件的散列值,并把它记录在一个叫 hashvalue 的文件中,然后把这个文件和game.exe一起保存在一块硬盘中。这样Alice就放心地去睡觉了。第二天早上, Alice用单向散列函数重新计算了game.exe的散列值,并和昨天保存的文件hashvalue 中的内容进行对比,结果发现两者是一致的。因此,Alice 判断 game.exe 没有被主动攻击者Mallory 改写。然而, Alice的这个判断是错误的,你知道为什么吗?
---------------------------------------------------------------------------------------------------------------------------------
7.3.2 基于口令的加密
单向散列函数也被用于基于口令的加密( Password Based Encryption, PBE)。
PBE 的原理是将口令和盐(salt,通过伪随机数生成器产生的随机值)混合后计算其散列值,然后将这个散列值用作加密的密钥。通过这样的方法能够防御针对口令的字典攻击,详细内容我们将在第11章中介绍。
7.3.3 消息认证码
使用单向散列函数可以构造消息认证码。
消息认证码是将“发送者和接收者之间的共享密钥”和“消息”进行混合后计算出的散列值。使用消息认证码可以检测并防止通信过程中的错误、篡改以及伪装。消息认证码在 SSL/TLS 中也得到了运用,关于 SSL/TLS 我们将在第 14 章中介绍。
7.3.4 数字签名
在进行数字签名时也会使用单向散列函数。数字签名是现实社会中的签名和盖章这样的行为在数字世界中的实现。数字签名的处理过程非常耗时,因此一般不会对整个消息内容直接施加数字签名,而是先通过单向散列函数计算出消息的散列值,然后再对这个散列值施加数字签名。详细内容我们将在第9 章中介绍。
7.3.5 伪随机数生成器
使用单向散列函数可以构造伪随机数生成器。密码技术中所使用的随机数需要具备“事实上不可能根据过去的随机数列预测未来的随机数列”这样的性质。为了保证不可预测性,可以利用单向散列函数的单向性。详细内容我们将在第 12 章中介绍。
7.3.6 一次性口令
使用单向散列函数可以构造一次性口令( one-time password)。一次性口令经常被用于服务器对客户端的合法性认证。在这种方式中,通过使用单向散列函数可以保证口令只在通信链路上传送一次(one-time),因此即使窃听者窃取了口令,也无法使用。
7.4单向散列函数的具体例子
下面我们来具体介绍几种单向散列函数。
7.4.1 MD4, MD5
MD4是由Rivest于1990年设计的单向散列函数,能够产生128比特的散列值(RFC1186,修订版RFC1320)。不过,随着Dobbertin提出寻找MD4散列碰撞的方法,现在它已经不安全了。
MD5是由Rivest于1991年设计的单项散列函数,能够产生128比特的散列值(RFC1321)。
MD5的强抗碰撞性已经被攻破,也就是说,现在已经能够产生具备相同散列值的两条不同的消息,因此它也已经不安全了。
MD4 和 MD5 中的 MD 是消息摘要(Message Digest)的缩写。
7.4.2 SHA-1, SHA-256, SHA-384, SHA-512
SHA-1 是由 NIST(National Institute of Standards and Technology,美国国家标准技术研究所)设计的一种能够产生160比特的散列值的单向散列函数。1993年被作为美国联邦信息处理标准规格(FIPS PUB 180)发布的是SHA, 1995年发布的修订版FIPS PUB 180-1称为SHA-1。在《CRYPTREC 密码清单》中, SHA-1 已经被列入“可谨慎运用的密码清单”,即除了用于保持兼容性的目的以外,其他情况下都不推荐使用。
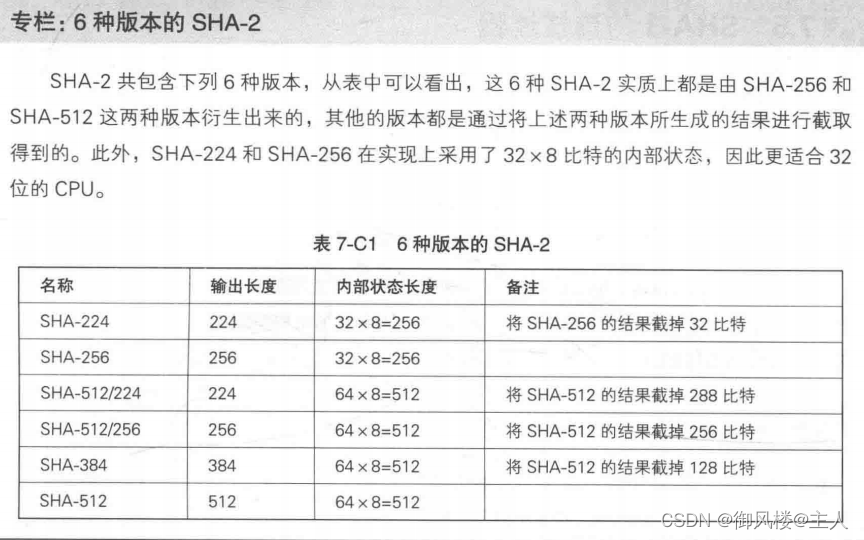
SHA-256、SHA-384 和 SHA512 都是由 NIST 设计的单向散列函数,它们的散列值长度分别为256比特、384比特和512比特。这些单向散列函数合起来统称SHA-2,它们的消息长度也存在上限(SHA-256的上限接近于24比特, SHA-384和SHA-512的上限接近于2128比特)。这些单向散列函数是于 2002 年和 SHA-1 一起作为 FIPS PUB 180-2 发布的。
SHA-1 的强抗碰撞性已于2005年被攻破①,也就是说,现在已经能够产生具备相同散列值的两条不同的消息。不过, SHA-2还尚未被攻破。
7.4.3 RIPEMD-160
RIPEMD-160 是于 1996 年由 Hans Dobbertin, Antoon Bosselaers 和 Bart Preneel 设计的一种能够产生160比特的散列值的单向散列函数。RIPEMD-160是欧盟RIPE项目所设计的RIPEMD单向散列函数的修订版。这一系列的函数还包括 RIPEMD-128、RIPEMD-256、RIPEMD-320 等其他一些版本。在《CRYPTREC 密码清单》中,RIPEMD-160 已经被列入“可谨慎运用的密码清单”,即除了用于保持兼容性的目的以外,其他情况下都不推荐使用。
RIPEMD 的强抗碰撞性已经于 2004 年被攻破,但 RIPEMD-160 还尚未被攻破。顺便一提,比特币中使用的就是RIPEMD-160 (15.3节)。
7.4.4 SHA-3
在 2005 年 SHA-1 的强抗碰撞性被攻破的背景下, NIST 开始着手制定用于取代 SHA-1 的下一代单向散列函数 SHA-3。SHA-3 和 AES(3.7 节)一样采用公开竞争的方式进行标准化。SHA-3 的选拔于 5 年后的2012年尘埃落定,一个名叫 Keccak的算法胜出,最终成为了 SHA-3。关于 SHA-3 的算法,稍后我们将详细讲解。
7.5 SHA-3 的选拔过程
本节中我们将介绍单向散列函数的新标准——SHA-3。本节的内容参考了 Keccak 开发者的网页0、 NIST的网页2以及《散列函数SHA-224, SHA-512/224,SHA-512/256和SHA-3(Keccak)的实现评估》[Sakiyama]。
7.5.1 什么是 SHA-3
SHA-3 (Secure Hash Algorithm-3)是一种作为新标准发布的单向散列函数算法,用来替代在理论上已被找出攻击方法的 SHA-1 算法。全世界的企业和密码学家提交了很多 SHA-3 的候选方案,经过长达 5 年的选拔,最终于 2012 年正式确定将 Keccak 算法作为 SHA-3 标准。
7.5.2 SHA-3 的选拔过程
和 AES 一样,举办 SHA-3 公开选拔活动的依然是美国国家标准与技术研究院 NIST。本次选拔出的单向散列函数算法同时成为了联邦信息处理标准 FIPS 202°。尽管这只是美国的国家标准,但实质上也将会作为国际标准被全世界所认可。
和 AES 一样,SHA-3 的选拔过程也是向全世界公开的,密码学家需要互相对彼此的算法进行评审。也就是说,这也是一次通过竞争来实现标准化的过程。
7.5.3 SHA-3 最终候选名单的确定与 SHA-3 的最终确定
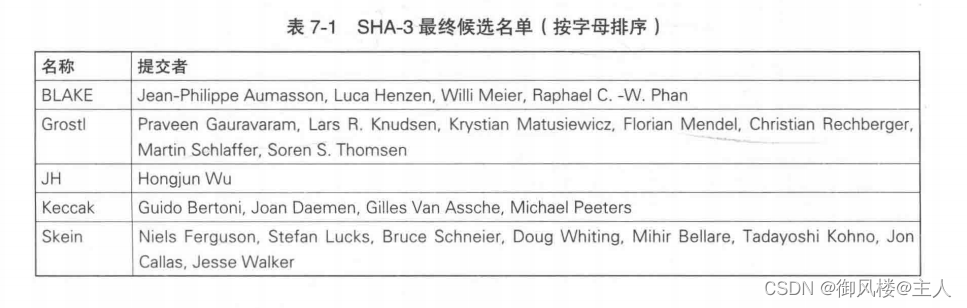
2007 年, NIST 开始了 SHA-3 的公开征集,截止到 2008年共征集到 64 个算法。2010 年, SHA-3 最终候选名单出炉,其中包括 5 个算法。SHA-3 最终候选名单请参见表 7-1。2012年,由Guido Bertoni、 Joan Daemen、 Gilles Van Assche、Michaël Peeters共同设计的Keccak 算法被最终确定为 SHA-3 标准,其中 Joan Daemen 也是对称密码算法 AES 的设计者之一。基于 NIST 所设定的条件,我们能够免费、自由地使用 SHA-3 算法,这与 AES 的情形完全相同。不过,SHA-3 的出现并不意味着 SHA-2 就不安全了,在一段时间内,SHA-2 和 SHA-3还将会共存。
Keccak 最终被选为SHA-3 的理由如下。
⚪采用了与 SHA-2 完全不同的结构
⚪结构清晰,易于分析
⚪能够适用于各种设备,也适用于嵌入式应用
⚪在硬件上的实现显示出了很高的性能
⚪比其他最终候选算法安全性边际更大
7.6 Keccak
7.6.1 什么是Keccak
如前所述,Keccak 是一种被选定为 SHA-3 标准的单向散列函数算法。
Keccak可以生成任意长度的散列值,但为了配合 SHA-2 的散列值长度, SHA-3 标准中共规定了 SHA3-224、SHA-3-256、SHA3-384、SHA3-512 这 4 种版本。在输入数据的长度上限方面,SHA-1为24-1比特,SHA-2为2128-1比特,而SHA-3则没有长度限制。
此外, FIPS 202中还规定了两个可输出任意长度散列值的函数( extendable-output function,XOF),分别为SHAKE128和SHAKE256。据说SHAKE这个名字取自Secure Hash Algorithm与Keccak 这几个单词。
顺便一提, Keccak的设计者之一Gilles Van Assche在GitHub上发布了一款名为KeccakTools的软件。
7.6.2 海绵结构
下面我们来看一看Keccak 的结构。Keccak 采用了与 SHA-1、SHA-2 完全不同的海绵结构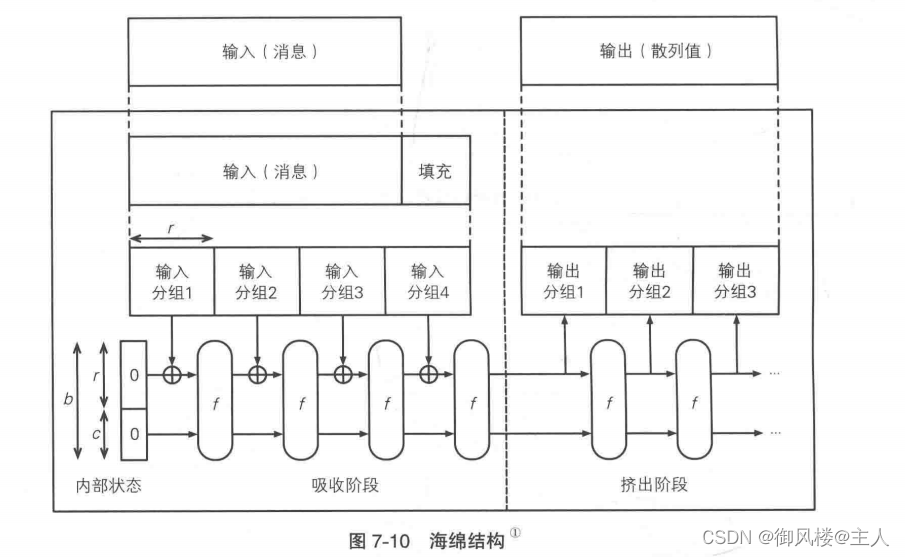
Keccak 的海绵结构中,输入的数据在进行填充之后,要经过吸收阶段(absorbing phase )和挤出阶段(squeezing phase),最终生成输出的散列值。
“海绵结构”这个名字听上去有点怪,请大家想象一下将一块海绵泡在水里吸水,然后再将里面的水挤出来的情形。同样地,Keccak的海绵结构是先将输入的消息吸收到内部状态中,然后再根据内部状态挤出相应的散列值。
吸收阶段的流程如下。
⚪将经过填充的输入消息按照每r个比特为一组分割成若干个输入分组
⚪首先,将“内部状态的 r个比特”与“输入分组 1”进行 XOR,将其结果作为“函数f的输入值”
⚪然后,将“函数f的输出值r个比特”与“输入分组2”进行XOR,将其结果再次作为“函数f的输入值”
⚪反复执行上述步骤,直到到达最后一个输入分组
⚪ 待所有输入分组处理完成后,结束吸收阶段,进入挤出阶段
函数f的作用是将输入的数据进行复杂的搅拌操作并输出结果(输入和输出的长度均为b=r+c个比特),其操作对象是长度为b=r+c个比特的内部状态,内部状态的初始值为0也就是说,通过反复将输入分组的内容搅拌进来,整个消息就会被一点一点地“吸收”到海绵结构的内部状态中,就好像水分被一点一点地吸进海绵内部一样。每次被吸收的输入分组长度为r个比特,因此r被称为比特率( bit rate)。
通过图 7-10 我们可以看出,函数f的输入长度不是r个比特,而是 r + c 个比特,请大家注意这一点,这意味着内部状态中有c个比特是不受输入分组内容的直接影响的(但会通过函数f受到间接影响)。这里的 c 被称为容量(capacity)。
吸收阶段结束后,便进入了挤出阶段,流程如下。
⚪首先,将“函数f的输出值中的r个比特”保存为“输出分组 1”,并将整个输出值(r+c个比特)再次输入到函数f中
⚪然后,将“函数f的输出值中的r个比特”保存为“输出分组2”,并将整个输出值(r+c个比特)再次输入到函数f中
⚪反复执行上述步骤,直到获得所需长度的输出数据
无论是吸收阶段还是挤出阶段,函数f的逻辑本身是完全相同的,每执行一次函数f,海绵结构的内部状态都会被搅拌一次。
挤出阶段中实际上执行的是“对内部状态进行搅拌并产生输出分组(r个比特)”的操作,也就是以比特率(r个比特)为单位,将海绵结构的内部状态中的数据一点一点地“挤”出来,就像从海绵里面把水分挤出来一样。
在挤出阶段中,内部状态r+c个比特中的容量(c个比特)部分是不会直接进入输出分组的,这部分数据只会通过函数f间接影响输出的内容。因此,容量c 的意义在于防止将输入消息中的一些特征泄漏出去。
7.6.3双工结构
作为海绵结构的变形,Keccak 中还提出了一种双工结构(图 7-11)。
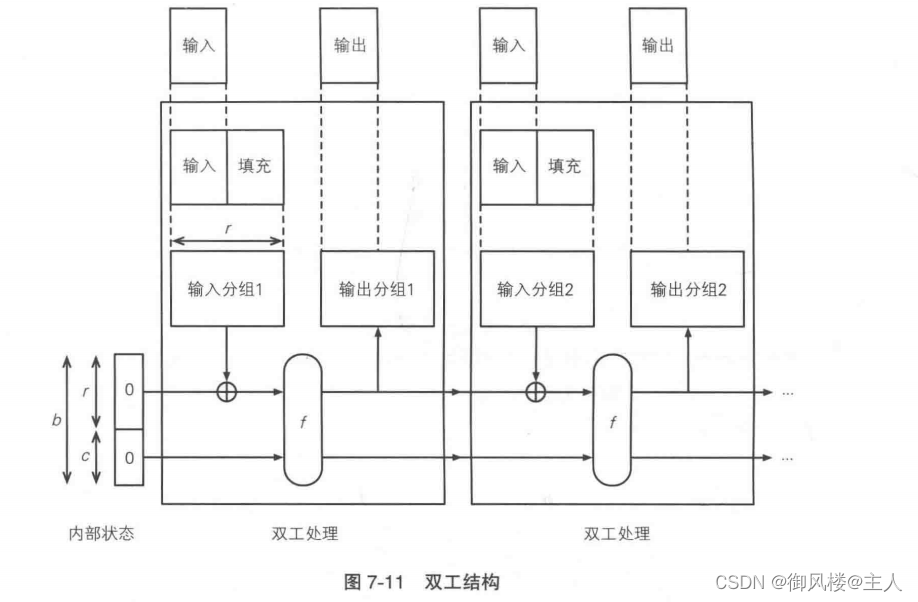
在海绵结构中,只有将输入的消息全部吸收完毕之后才能开始输出,但在双工结构中,输入和输出是以相同的速率进行的。在双向通信中,发送和接收同时进行的方式称为全双工(fullduplex), Keccak的双工结构也代表同样的含义。
通过采用双工结构,Keccak 不仅可用于计算散列值,还可以覆盖密码学家的工具箱中的其他多种用途,如伪随机数生成器、流密码、认证加密、消息认证码等。
7.6.4 Keccak的内部状态
刚才我们介绍了Keccak中b=r+c个比特的内部状态是如何通过函数f进行变化的,下面我们来深入地看一看内部状态。
Keccak 的内部状态是一个三维的比特数组,如图 7-12所示。图中的每个小方块代表 1 个比特,b个小方块按照5x5xz的方式组合起来,就成为一个沿z轴延伸的立方体。
我们将具备x、y、z三个维度的内部状态整体称为state, state共有b个比特。三如果我们只关注内部状态中的两个维度,可以将xz平面称为plane,将xy平面称为slice,状将 yz 平面称为 sheet(图 7-13)。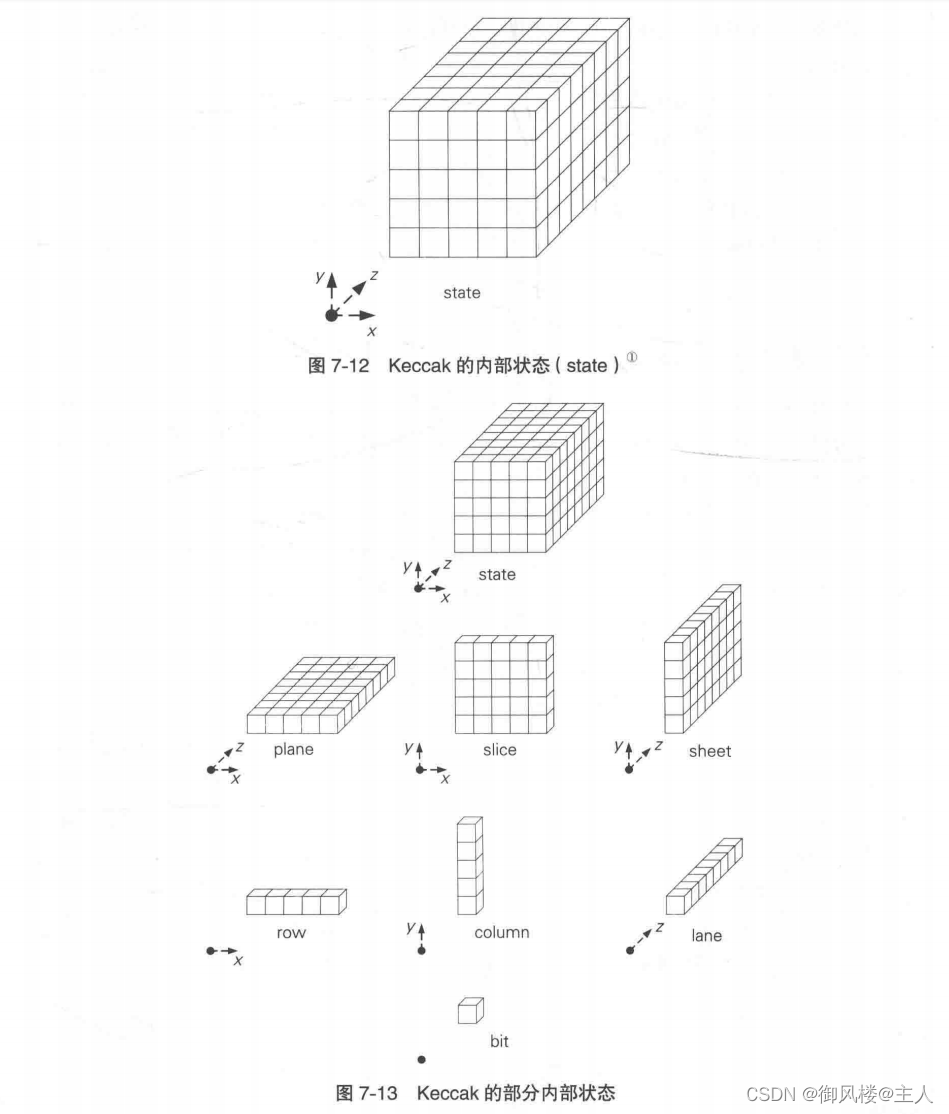
同样地,如果我们只关注其中一个维度,可以将 x轴称为 row,将 y轴称为 column,将 z轴称为 lane。
因此,我们可以将 state 看成是由 5×5 = 25 条 lane 构成的,也可以看成是由与 lane 的长度相同数量的 slice 堆叠而成的。
Keccak 的本质就是实现一个能够将上述结构的 state 进行有效搅拌的函数f,这与分组密码设计中的搅拌过程非常相似。此外,由于内部状态可以代表整个处理过程中的全部中间状态,因此有利于节约内存。Keccak用到了很多比特单位的运算,因此被认为可以有效抵御针对字节单位的攻击。
7.6.5 函数Keccak-f[b]
下面我们来看一看负责对内部状态进行搅拌的函数f。Keccak的函数f实际上应该叫作Keccak-f[b],从这个名称可以看出,这个函数带有一个参数 b,即内部状态的比特长度。这里的参数 b 称为宽度(width)。
根据Keccak的设计规格,宽度b可以取25、50、100、200、400、800、1600共7种值,SHA-3 采用的是其中的最大宽度,即b=1600。宽度 b 的 7 种取值的排列看起来好像有点怪,其实这7个数字都是25的整数倍,即25的1(=2°)倍、2(=2^1)倍、4(=2^2)倍、8(=2^3)倍、16(=2^4)倍、32(=2^5)倍和 64(=2^6)倍。根据图 7-13 可知,一片 slice 的大小为 5×5=25 个比特,因此b/25就相当于slice的片数(即lane的长度)。 SHA-3的内部状态大小为b=5x5x64=1600个比特。
由此可见,在Keccak中,通过改变宽度b就可以改变内部状态的比特长度。但无论如何改变, slice 的大小依然是 5×5,改变的只是 lane 的长度而已,因此 Keccak 宽度的变化并不会影响其基本结构。Keccak 的这种结构称为套娃结构,这个名字取自著名的俄罗斯套娃,每个娃娃的形状都是相同的,只是大小不同而已。利用套娃结构,我们可以很容易地制作一个缩水版Keccak模型并尝试对其进行破解,以便对该算法的强度进行研究。
Keccak-f[b] 中的每一轮包含 5 个步骤:θ(西塔)、p(柔)、π(派)、x(凯)、ι(伊欧塔),总共循环 12 +2e 轮①。具体到 SHA-3 中所使用的 Keccak-f[1600]函数,其循环轮数为 24 轮。
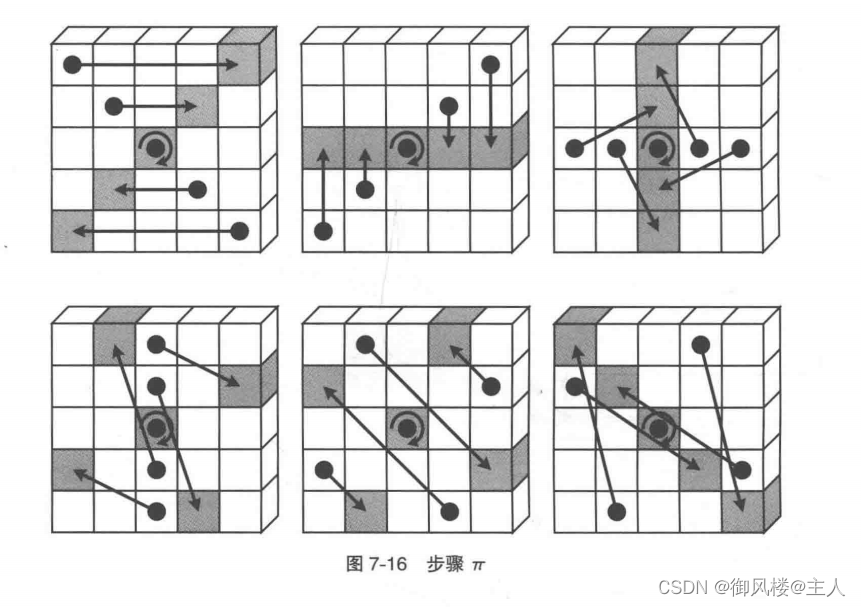
步骤θ图
7-14 所示为对其中 1 个比特应用步骤 θ时的情形,这一步的操作是将位置不同的两个column 中各自 5 个比特通过 XOR 运算加起来(图中的 Σ 标记),然后再与置换目标比特求 XOR并覆盖掉目标。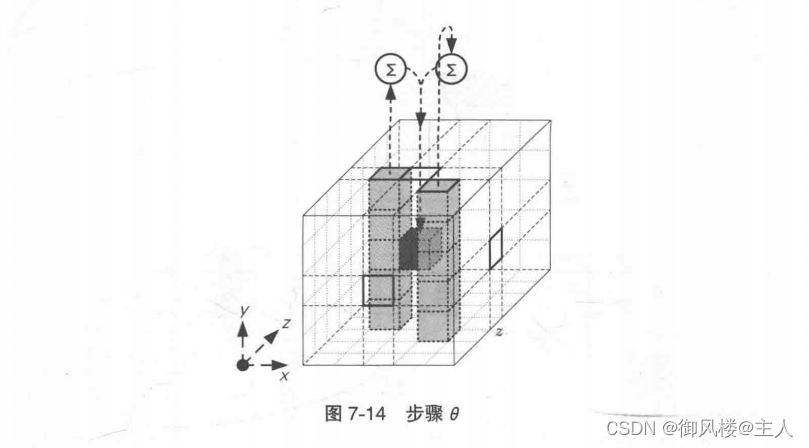
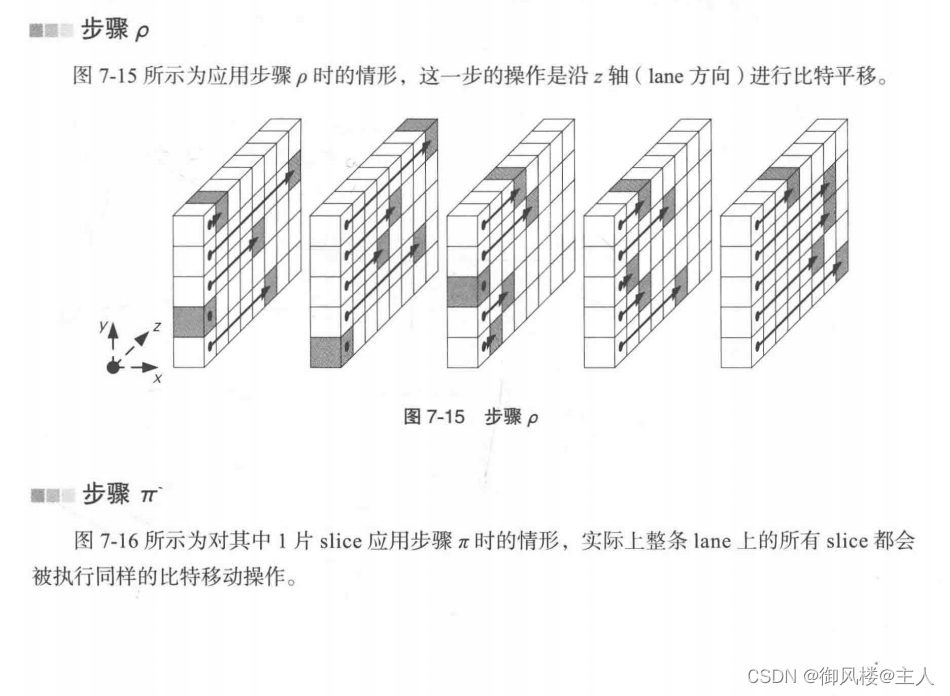
步骤ι
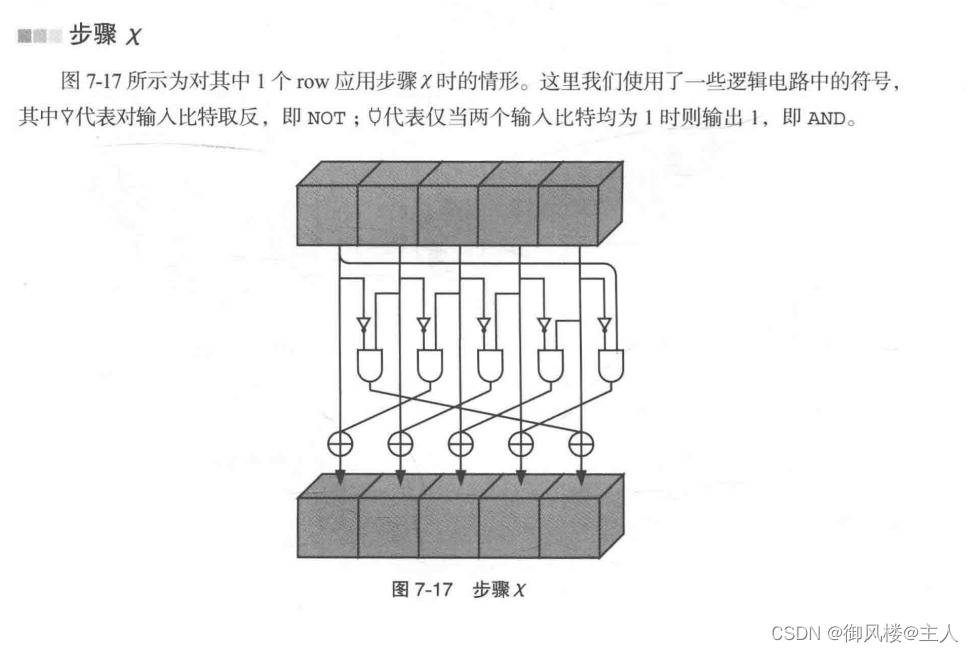
步骤ι是用一个固定的轮常数对整个state的所有比特进行XOR运算,目的是让内部状态具备非对称性。
根据《散列函数SHA-224、 SHA-512/224, SHA-512/256和SHA-3 ( Keccak )的实现评估》[Sakiyama],除了步骤θ中的奇偶性处理(Σ标记)以及步骤x中的NOT和AND以外,其余的操作仅通过硬件电路就都可以实现。
7.6.6 对 Keccak 的攻击
Keccak之前的单向散列函数都是通过循环执行压缩函数的方式来生成散列值的,这种方式称为MD结构( Merkle-Damgard construction)。MD4、MD5、 RIPEMD、 RIPEMD-160、SHA-1、SHA-2 等几乎所有的传统单向散列函数算法都是基于 MD 结构的。
当初之所以开始征集 SHA-3 算法,就是因为针对当时广泛使用的 SHA-1 算法已经出现了理论上可行的攻击方法。为了规避 SHA-1 的风险,SHA-2 应运而生,但SHA-2 依然是基于和SHA-1 相同的 MD结构,针对SHA-1 的攻击方式很有可能也会适用于 SHA-2,问题没有得到根本解决。Keccak则采用了和MD结构完全不同的海绵结构,因此针对SHA-1的攻击方法对Keccak 是无效的。
到目前为止,还没有出现能够对实际运用中的 Keccak 算法形成威胁的攻击方法。
7.6.7 对缩水版Keccak的攻击竞赛
由于Keccak具备套娃结构,其实现中包含对轮处理的多次迭代,因此我们很容易实现一个强度较低的“缩水版Keccak".通过设计一个比实际作为SHA-3标准运用的Keccak强度低一些d的版本,并尝试对其进行攻击,就可以据此来评估实际运用的标准版Keccak的强度。
Keccak的设计者还举办了名叫Keccak Crunchy Crypto Collision and Pre-image Contest"的相关“竞赛”,内容就是对缩水版的Keccak进行攻击。在竞赛中使用的缩水版Keccak比标准版减少了迭代轮数,参赛者可以通过改变宽度b等各种方法来进行攻击。
Keccak 被选为SHA-3 标准的其中一个原因就是“结构清晰,易于分析”。这个原因似乎有点违背常识,因为“易于分析”也就表示“容易找到弱点”。而一个容易找到弱点的算法为什么会被选为SHA-3呢?其实,正是因为我们可以比较容易地分析缩水版的Keccak,也就能够比较容易地对实际运用的标准版算法的强度进行评估,而作为一个将在全世界广泛使用的单向散列函数算法, “易于分析”可以说是一个十分优秀的特性。
7.7 应该使用哪种单向散列函数呢
刚刚我们介绍了几种单向散列函数,那么我们到底应该使用哪种单向散列函数算法呢?
首先,MD5 是不安全的,因此不应该使用。
SHA-1除了用于对过去生成的散列值进行校验之外,不应该被用于新的用途,而是应该迁移到 SHA-2。
SHA-2有效应对了针对SHA-1的攻击方法,因此是安全的,可以使用。
SHA-3 是安全的,可以使用。
2013年发布І《CRYPTREC密码清单》中, SHA-2 (SHA-256, SHA-384, SHA-512)被列入了“电子政府推荐使用的密码清单”中。
和对称密码算法一样,我们不应该使用任何自制算法。
---------------------------------------------------------------------------------------------------------------------------------
小测验 3 Alice 的算法 (答案见 7.11 节)
在听了关于单向散列函数的讲解之后, Alice想: “什么嘛,单向散列函数不就是像校验和(checksum)一样的东西吗?”于是她设计了下面这样的算法。(1)以 256 比特为一个单位分割消息,将分割出的每一份数据当成一个 256 比特所能表达的整数,然后将这些整数全部相加,并将得到的结果中超过 256 比特的部分丢弃。(2)上述相加的结果就是散列值(256比特)。这样的算法能够用作单向散列函数吗?
---------------------------------------------------------------------------------------------------------------------------------
7.8 对单向散列函数的攻击
和对密码进行攻击相比,对单向散列函数进行攻击有点难以想象吧。下面就让我们通过两个具体的故事,来了解一下对单向散列函数的攻击方式。
7.8.1 暴力破解(攻击故事1)
Alice在计算机上写了一份合同。工作做完后,她把合同文件保存在公司的电脑上,将合同文件的散列值保存在存储卡中带回了家里。
晚上,主动攻击者Mallory入侵了计算机,找到了Alice的合同文件,他想将其中的
“Alice要支付的金额为100万元。”
改成
“Alice要支付的金额为1亿元。”
不过,仅仅改写合同是不行的,因为 Mallory知道第二天 Alice会重新计算文件的散列值并进行对比。哪怕文件中有 1个比特被改写,Alice都会有所察觉。那么Mallory怎样才能在不改变散列值的前提下,将“100 万元”改成“1 亿元”呢?
Mallory 可以从文档文件所具有的冗余性入手。所谓文档文件的冗余性,是指在不改变文档意思的前提下能够对文件的内容进行修改的程度。
举个例子,下面这些句子基本上说的都是一个意思。
Alice 要支付的金额为 1 亿元。
Alice 要支付的金额为壹亿元。
Alice要支付的金额为100000000元。
Alice 要支付的金额为 ¥ 100,000,000。
Alice要支付的金额为:1亿元。
Alice需要支付的金额为1亿元。
Alice 应支付 1 亿元。
作为报酬, Alice需要支付1亿元。
上面这些都是人们可以想象出的意思相近的句子,除此之外,还有一些通过机器来进行修改的方法。例如,可以在文件的末尾添加1个、2个、3个甚至更多的空格,或者还可以对文档中的每一个字稍微改变一下颜色,这都不会影响文档的意思。在这里需要注意的是,即便我们对文件所进行的修改是无法被人类察觉的,但只要是对文件进行了修改,单向散列函数就会产生不同的散列值。
于是,Mallory 利用文档的冗余性,通过机器生成了一大堆“支付 1 亿元的合同”。
如果在这一大堆“1 亿元合同”中,能够找到一个合同和 Alice 原本的“100 万元合同”恰好产生相同的散列值,那Mallory就算是成功了,因为这样就可以天衣无缝地用1亿元合同来代替 100 万元合同了。替换了文件之后,Mallory 悄无声息地离开。到这里,文件的内容就被成功篡改了。
在这个故事中,为了方便大家理解,我们用人类能够读懂的合同作为例子。然而,无论人类是否能够读懂,任何文件中都或多或少地具有一定的冗余性。利用文件的冗余性生成具有相同散列值的另一个文件,这就是一种针对单向散列函数的攻击。
在这里 Mallory所进行的攻击,就是暴力破解。正如对密码可以进行暴力破解一样,对单向散列函数也可以进行暴力破解。
在对密码进行暴力破解时,我们是按顺序改变密钥的值,如0、1、2、3、……然后分别用这些密钥进行解密操作的。对单向散列函数进行暴力破解时也是如此,即每次都稍微改变一下消息的值,然后对这些消息求散列值。
现在我们需要寻找的是一条具备特定散列值的消息,例如在攻击故事 1 中,Mallory 需要寻找的就是和“100万元合同”具备相同散列值的另一条不同的消息。这相当于一种试图破解单向散列函数的“弱抗碰撞性”的攻击。在这种情况下,暴力破解需要尝试的次数可以根据散列值的长度计算出来。以SHA3-512为例,由于它的散列值长度为512比特,因此最多只要尝试2^512次就能够找到目标消息了,如此多的尝试次数在现实中是不可能完成的。
由于尝试次数纯粹是由散列值长度决定的,因此散列值长度越长的单向散列函数,其抵御暴力破解的能力也就越强。找出具有指定散列值的消息的攻击分为两种,即“原像攻击”和“第二原像攻击”。原像攻击(Pre-Image Attack)是指给定一个散列值,找出具有该散列值的任意消息;第二原像攻击(Second Pre-Image Attack)是指给定一条消息 1,找出另外一条消息 2,消息 2 的散列值和消息1 相同。
7.8.2 生日攻击(攻击故事2)
让我们再来看一个和攻击故事 1 很相似的故事。
在这次的故事中,编写合同的人不是Alice而是主动攻击者Mallory。他事先准备了两份具备相同散列值的“100万元合同”和“1亿元合同”,然后将“100万元合同”交给Alice让她计算散列值。随后, Mallory再像故事1 中一样,把“100万元合同”掉包成“1 亿元合同”。
在故事 1 中,编写 100 万元合同的是 Alice,因此散列值是固定的,Mallory 需要根据特定的散列值找到符合条件的消息。然而,故事2则不同, Mallory需要准备两份合同,而散列值可以是任意的,只要100万元合同和1亿元合同的散列值相同就可以了。
在这里,Mallory 所进行的攻击不是寻找生成特定散列值的消息,而是要找到散列值相同的两条消息,而散列值则可以是任意值。这样的攻击,一般称为生日攻击(birthday attack)或者冲突攻击( collision attack),这是一种试图破解单向散列函数的“强抗碰撞性”的攻击。
这里我们先把话题岔开,请大家想一想下面这个生日问题的答案。
【生日问题】
设想由随机选出的N个人组成一个集合。
在这 N 个人中,如果要保证至少有两个人生日一样的概率大于二分之一,那么 N 至少是多少?(排除 2 月29日的情况)
一般人应该会这样想:“一年有 365 天,那么要使其中两个人生日相同的概率为二分之一的话,差不多得要 365 的一半这么多人才行吧。150 个人左右?也许更少一点,差不多是 N= 100 吧?”这个问题的答案一定会让你惊讶:N = 23。也就是说,只要有 23 个人,就有超过二分之一的概率出现至少有两个人生日一样的情况。如果有100个人的话,那么这个概率就已经非常接近1了。“两个人的生日都是某个特定日期”的可能性确实不高,但如果是“只要有两个人生日相同,不管哪一天都可以”的话,可能性却是出乎意料的高的。具体的计算方法如下。解这道题目的窍门在于,我们并非直接计算“N个人中至少有两个人生日一样的概率”,而是先计算“N个人生日全都不一样的概率”,然后再用 1减去这个值就可以了。第1个人的生日可以是365天中的任意一天;第2个人的生日需要在365天中去掉第1个人生日的那一天,也就是还有 364 天;第 3 个人的生日需要去掉第 1 个和第 2 个人生日的那一天,还有 363 天……到了第 N个人,就需要去掉1~N-1个人的生日,因此还有 365-N+1 天。我们将所有人可选的生日的数量相乘,就可以得到所有人生日都不一样的组合的数量,即:

当N取23时,这个值约等于0.507297,大于二分之一。从上面的计算可以看出,任意生日相同的概率比我们想象的要大,这个现象称为生日悖看论(birthday paradox)。
下面我们将生日问题一般化,即:“假设一年的天数为Y天,那么N人的集合中至少有两个人生日一样的概率大于二分之一时,N 至少是多少?
”这里暂且省略详细的计算过程,当y非常大时,近似的计算结果为:
N=√ ̄Y(一年天数的平方根) ……(※)
现在让我们回到生日攻击的话题。生日攻击的原理就是来自生日悖论,也就是利用了“任意散列值一致的概率比想象中要高”这样的特性。这里的散列值就相当于生日,而“所有可能出现的散列值的数量”就相当于“一年的天数”。
故事 2 中Mallory所进行的生日攻击的步骤如下。
(1) Mallory生成N个100万元合同(我们稍后来计算N)。
(2) Mallory生成 N个 1 亿元合同。
(3) Mallory将(1)的 N个散列值和(2)的 N个散列值进行对比,寻找其中是否有一致的情况。
(4)如果找出了一致的情况,则利用这一组100万元合同和1亿元合同来欺骗Alice。
问题是N的大小。N太小的话,Mallory的生日攻击很容易就会成功,而N太大的话,就会需要更多的时间和内存,生日攻击的难度也会提高。N的大小是和散列值的长度相关的。
假设 Alice 所使用的单向散列函数的散列值长度为 M 比特,则 M 比特所能产生的全部散列值的个数为2^M个(这相当于“一年的天数Y”)。
根据上文中(※)的计算结果可得:
N=√ ̄Y=√ ̄2^M= 2M/2
因此当 N=2^M/2 时,Mallory 的生日攻击就会有二分之一的概率能够成功。
我们以 512比特的散列值为例,对单向散列函数进行暴力破解所需要的尝试次数为2512次,而对同一单向散列函数进行生日攻击所需的尝试次数为2256次,因此和暴力破解相比,生日攻击所需的尝试次数要少得多①。
7.9单向散列函数无法解决的问题
使用单向散列函数可以实现完整性的检查,但有些情况下即便能够检查完整性也是没有意义的。
例如,假设主动攻击者Mallory伪装成Alice,向Bob同时发送了消息和散列值。这时Bob能够通过单向散列函数检查消息的完整性,但是这只是对Mallory发送的消息进行检查,而无法检查出发送者的身份是否被 Mallory进行了伪装。也就是说,单向散列函数能够辨别出“篡改”,但无法辨别出“伪装”。
当我们不仅需要确认文件的完整性,同时还需要确认这个文件是否真的属于Alice时,仅靠完整性检查是不够的,我们还需要进行认证。用于认证的技术包括消息验证码和数字签名。消息认证码能够向通信对象保证消息没有被篡改,而数字签名不仅能够向通信对象保证消息没有被篡改,还能够向所有第三方做出这样的保证。认证需要使用密钥,也就是通过对消息附加Alice的密钥(只有Alice才知道的秘密信息)来确保消息真的属于 Alice。
7.10 本章小结
本章中我们学习了用于确认消息完整性的单向散列函数。单向散列函数能够根据任意长度的消息计算出固定长度的散列值,通过对比散列值就可以判断两条消息是否一致。这种技术对辨别篡改非常有效。我们还学习了一种具有代表性的单向散列函数——SHA-3的具体实现方法,同时还介绍了针对单向散列函数的攻击--暴力破解和生日攻击。现在散列值的长度正在逐步提升到256比特以上。使用单向散列函数,我们可以辨别出篡改,但无法辨别出伪装。要解决这个问题,我们需要消息验证码和数字签名。
下一章我们将介绍消息验证码。
---------------------------------------------------------------------------------------------------------------------------------
小测验 4 单向散列函数的基础知识 (答案见 7.11 节)
下列关于单向散列函数的说法中,请在正确的旁边画⚪。,错误的旁边画×。
(1) SHA3-512是一种能够将任意长度的数据转换为512比特的对称密码算法。
(2)要找出和某条消息具备相同散列值的另一条消息是非常困难的。
(3)要找出具有相同散列值但互不相同的两条消息是非常困难的。
(4) SHA3-512 的散列值长度为64字节。(5)如果消息仅被改写了1比特,则散列值也仅发生1 比特的改变。
---------------------------------------------------------------------------------------------------------------------------------

小测验3的答案: Alice的算法
不能使用。例如,某条消息的散列值如下所示。

------------------------------------------
感谢您阅读本文!如果您对文章内容有任何疑问或者想要提出任何问题,欢迎在评论区留言。我会尽力回答您的疑问,并与您交流。期待与您互动!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









