







LeetCode官方解法,使用哈希集合进行查找:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// 哈希集合,记录每个字符是否出现过
unordered_set<char> occ;
int n = s.size();
// 右指针,初始值为 -1,相当于我们在字符串的左边界的左侧,还没有开始移动
int rk = -1, ans = 0;
// 枚举左指针的位置,初始值隐性地表示为 -1
for (int i = 0; i < n; ++i) {
if (i != 0) {
// 左指针向右移动一格,移除一个字符
occ.erase(s[i - 1]);
}
while (rk + 1 < n && !occ.count(s[rk + 1])) {
// 不断地移动右指针
occ.insert(s[rk + 1]);
++rk;
}
// 第 i 到 rk 个字符是一个极长的无重复字符子串
ans = max(ans, rk - i + 1);
}
return ans;
}
};
运行结果:
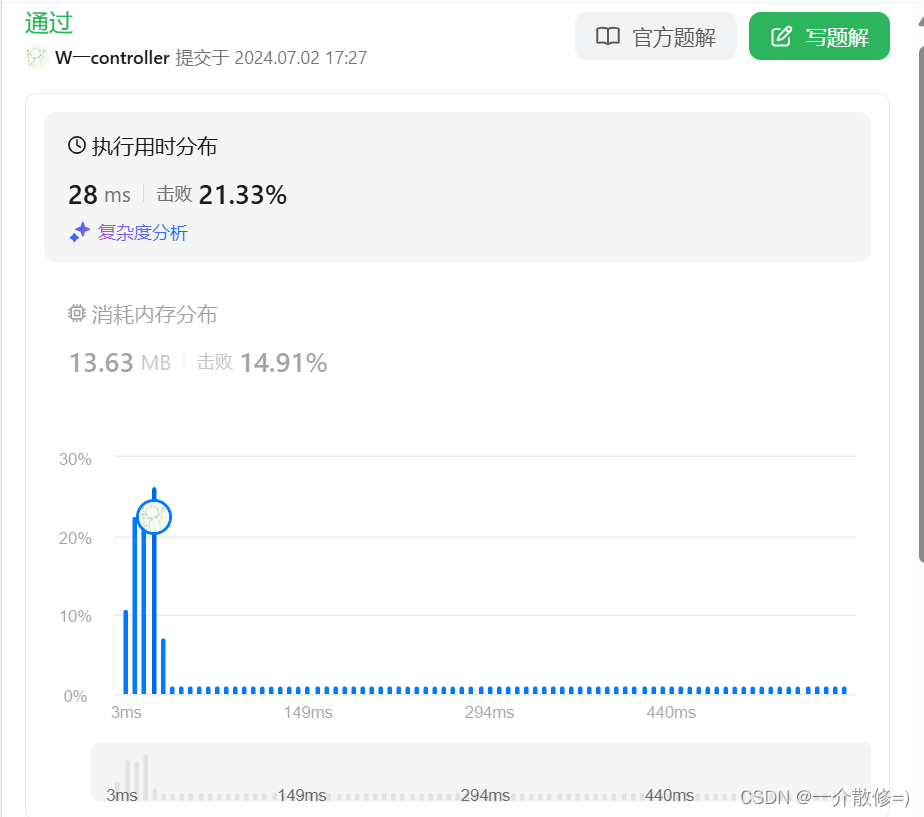
耗时20+ms,消耗内存13.63MB。
我的解法,直接使用string,通过find()找到重复元素下标pos,直接删除pos及之前的元素,因此不需要使用第二个while循环。(理论上,使用哈希集合查询元素会比使用string的find()更快,但结果却出乎意料)。
解法如下:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int len = s.size();
string str;
int result = 0;
for (int left = 0, right = 0, pos = 0; right < len;) {
pos = str.find(s[right]);
if (pos != -1) {
str.erase(0, pos + 1);
left += pos + 1;
}
str += s[right];
result = max(result, right - left + 1);
++right;
}
return result;
}
};运行结果:
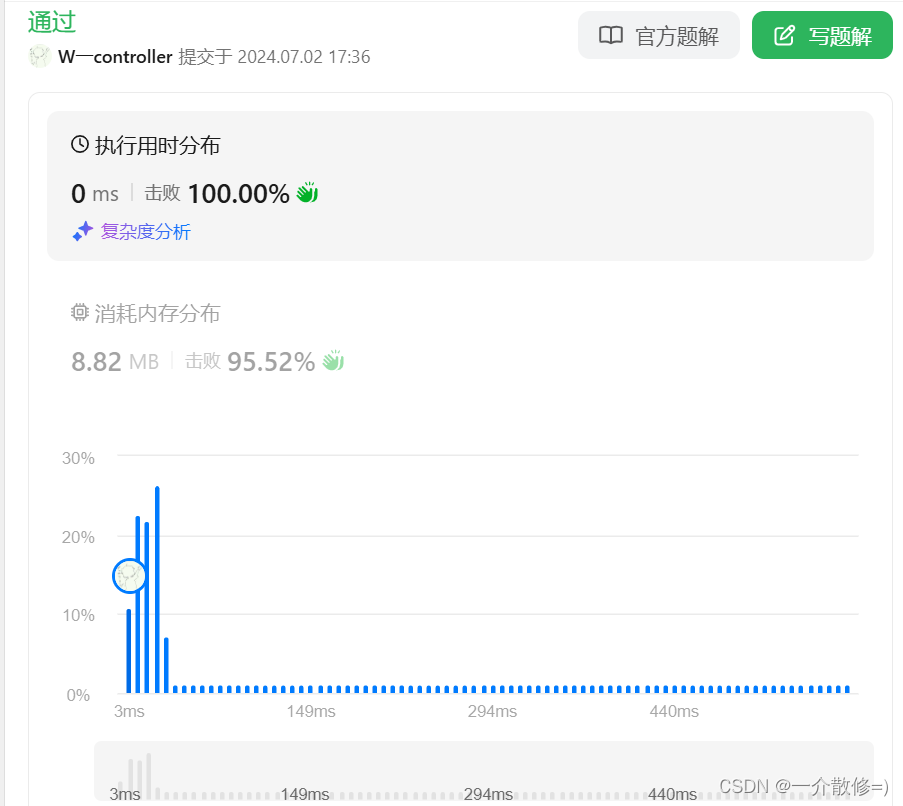

耗时10ms以内,运气好可以达到0ms,消耗内存8.82MB。
这是偶然情况吗?
让我们模拟不同的情况进行测试,测试代码如下,第一种是我的方法,第二种是官方的方法。
#include <iostream>
#include <vector>
#include <string>
#include <unordered_set>
#include <algorithm>
#include <chrono>
using namespace std;
using namespace std::chrono;
// 第一种实现(我的代码)
class Solution1 {
public:
int lengthOfLongestSubstring(string s) {
int len = s.size();
string str;
int result = 0;
for (int left = 0, right = 0, pos = 0; right < len;) {
pos = str.find(s[right]);
if (pos != -1) {
str.erase(0, pos + 1);
left += pos + 1;
}
str += s[right];
result = max(result, right - left + 1);
++right;
}
return result;
}
};
// 第二种实现(官方的代码)
class Solution2 {
public:
int lengthOfLongestSubstring(string s) {
unordered_set<char> occ;
int n = s.size();
int rk = -1, ans = 0;
for (int i = 0; i < n; ++i) {
if (i != 0) {
occ.erase(s[i - 1]);
}
while (rk + 1 < n && !occ.count(s[rk + 1])) {
occ.insert(s[rk + 1]);
++rk;
}
ans = max(ans, rk - i + 1);
}
return ans;
}
};
// 测试函数
void testFunction(Solution1& sol1, Solution2& sol2, const string& testCase, const string& testName) {
const int numRuns = 100; // 运行次数
// 测试 Solution1
auto start1 = high_resolution_clock::now();
for (int i = 0; i < numRuns; ++i) {
sol1.lengthOfLongestSubstring(testCase);
}
auto end1 = high_resolution_clock::now();
auto duration1 = duration_cast<microseconds>(end1 - start1).count() / numRuns;
// 测试 Solution2
auto start2 = high_resolution_clock::now();
for (int i = 0; i < numRuns; ++i) {
sol2.lengthOfLongestSubstring(testCase);
}
auto end2 = high_resolution_clock::now();
auto duration2 = duration_cast<microseconds>(end2 - start2).count() / numRuns;
// 输出结果和时间
cout << testName << ":\n";
cout << "Solution1 average duration: " << duration1 << " microseconds" << endl;
cout << "Solution2 average duration: " << duration2 << " microseconds" << endl;
}
int main() {
// 创建不同的测试用例
string smallTestCase = "abcabcbb";
string mediumTestCase = "";
for (int i = 0; i < 1000; ++i) {
mediumTestCase += "abcdefghijklmnopqrstuvwxyz";
}
string largeTestCase = "";
for (int i = 0; i < 10000; ++i) {
largeTestCase += "abcdefghijklmnopqrstuvwxyz";
}
string repetitiveTestCase = "aaaaaaaaaa"; // 大量重复字符
// 实例化两个解决方案
Solution1 sol1;
Solution2 sol2;
// 测试并打印结果
testFunction(sol1, sol2, smallTestCase, "Small Test Case");
testFunction(sol1, sol2, mediumTestCase, "Medium Test Case");
testFunction(sol1, sol2, largeTestCase, "Large Test Case");
testFunction(sol1, sol2, repetitiveTestCase, "Repetitive Test Case");
return 0;
}
运行结果:还是我的方法更快一些。

目前不知道为什么会快这么多,理论上,使用哈希集合查询元素会比使用string的find()更快,欢迎评论区讨论。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









