








一、摘要
本研究针对甲骨文图像处理展开研究,详细阐述了相关实验过程与成果。实验涵盖图像校正、噪声去除、多边形拟合、文字提取与分割等内容。在图像预处理阶段,通过灰度化、二值化、连通域分析等操作去除背景噪声,增强文字清晰度。利用霍夫变换检测直线并旋转图像实现校正,以质心为原点建系,再经腐蚀、膨胀优化图像。多边形拟合采用bwboundaries函数得到甲骨外轮廓。文字提取经多种方法尝试,确定先膨胀再提取文字,按连通域面积排序后重新排列。
二、实验思路分析
(一)第(1)、(2)问的处理
该任务的主要目标是实现对图像的处理,包括求取图像的质心、对图像进行整体校正,以及将图像中的文字调整为垂直和水平走向。在实际处理图像的过程当中,发现原始图像中甲骨外部的白色区域是无关紧要的部分,这些区域可以视为背景噪声,不仅对任务无帮助,还可能干扰文字的识别和校正效果。因此,我设想在去除背景噪声的同时,尝试提升甲骨文上文字的清晰度,以便更准确地识别文字的走向信息。在去噪和增强文字后,我计划利用Hough变换对图像中的文字走向进行检测,提取其方向信息,并依据这一信息对图像进行校正,确保文字走向变为标准的垂直和水平。这一处理流程将帮助顺利完成实验中的(1)、(2)两个问题,为后续研究奠定基础。
(二)第(3)问的处理
该任务的核心目标是对甲骨外部轮廓进行精确拟合,以便为后续的研究与分析提供可靠的形状信息。为实现这一目标,首先需要通过边缘检测算法对图像进行处理,提取甲骨的边缘轮廓。边缘检测是一种常用的方法,可以有效地找到图像中显著的边界信息。在获取到甲骨的边缘后,可以进一步利用多边形拟合的相关算法对这些边缘进行拟合处理,生成更加规则且简洁的轮廓表示。但是为了确保轮廓提取的准确性,在此之前需要结合(1)、(2)两问中涉及的图像预处理工作,例如去除背景噪声、提升图像清晰度以及对图像方向的校正等。这些前置处理能够显著改善边缘检测和拟合的效果,避免背景干扰或不准确的边缘检测导致的误差。基于此步骤,能够顺利解决实验中的第(3)问,为甲骨形状的进一步研究提供清晰且精确的轮廓数据。
(三)第(4)问的处理
该任务的主要目标是从图像中提取出甲骨文字符,并根据字符在图中的位置进行排列。这一过程需要在图像预处理的基础上进行进一步处理。在预处理阶段,我设想将甲骨内部的白色区域视为文字符号的轨迹,通过这一假设可以初步解决字符提取的问题。然而,在实际操作中发现甲骨内部存在裂缝、字符粘连等情况,这些问题会对提取效果产生干扰,导致提取结果不准确。因此,如果能够手动圈选出认为是干扰的区域并加以处理,将会显著提升字符提取的精度。为此了解到,RIO方法可以用于对特定区域进行定向处理。通过利用RIO对干扰区域进行标注和排除,干扰问题就能够得到有效解决。在完成干扰区域的处理后,就可以对图像中的字符进行提取。这一过程需要识别所有的连通区域,并确保能够清晰区分各连通区域之间的边界。由于题目要求是有序排列,可知任务要求提取出的文字需要按照一定的顺序进行排列,考虑可以通过对文字连通域的面积大小进行排序从而实现对文字的排序。进一步查阅资料后,我发现MATLAB中自带的bwlabel和regionprops函数可以很好地实现这一功能。其中,bwlabel用于标记连通区域,而regionprops则能提取每个连通区域的属性信息,如位置、形状等。通过这些工具,可以进一步有效地提取出图像中的甲骨文字符,并根据其原始位置进行合理排列,从而完成任务目标,这也是未来工作的一部分。
三、实验流程设计
(一)第1、2问的流程设计
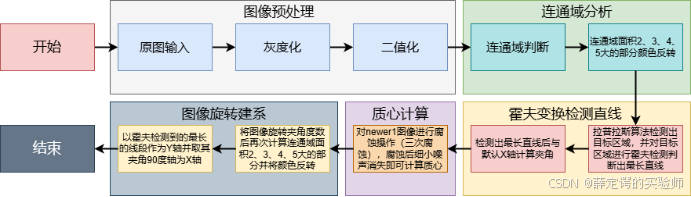
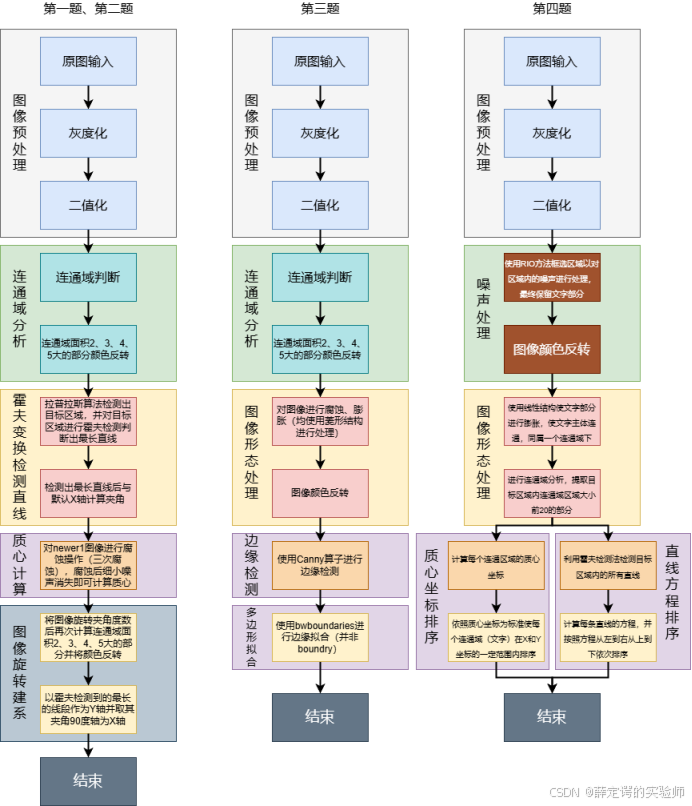
这一部分任务的目标是对原始图像进行处理和校正,使图像中的甲骨文文字排列规范化,为后续的分析和识别提供支持。整个流程从原始图像的输入开始。首先,进行图像的预处理:将原始图像转化为灰度图像,减少颜色信息的干扰并突出主要特征;然后通过二值化操作简化为黑白二值图像,使图像中的甲骨文与背景得以清晰区分。为了进一步消除噪声,通过膨胀和腐蚀操作去除二值图中的细小噪声。接下来,通过连通域分析识别图像中彼此连通的区域,并对其进行编号处理,同时剔除噪声区域,仅保留与甲骨文相关的有效区域。这些连通域的主要部分会被提取出来,并进行质心计算,计算出的质心将被用作坐标原点,为后续的校正提供参考。在此基础上,使用Canny边缘检测方法提取图像中甲骨文字的边缘,通过霍夫变换检测出图像中的直线,并标注出最长的直线。通过最长线段的方向与默认的X轴之间的夹角,判断图像的整体倾斜角度,并进行旋转校正,从而使文字的方向与垂直或水平标准保持一致。这一流程通过图像预处理、连通域分析、噪声剔除、质心计算、直线检测与校正等步骤,逐步优化了甲骨文图像的排版方向。最终,系统完成对甲骨文的分割和标准化处理,确保输出的甲骨文图像具备良好的规范性和分析价值。
(二)第3问的流程设计
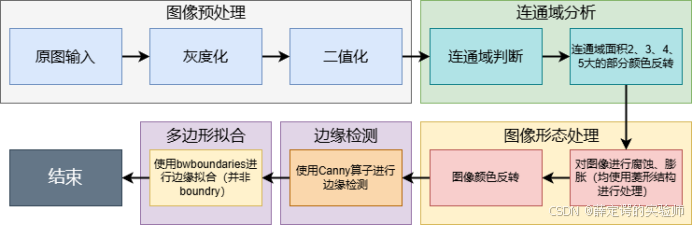
这个任务必不可少的肯定是将图像转化为灰度图,在对其进行二值化处理,然后利用膨胀和腐蚀清楚边缘处的小噪声,使得后续的边缘检测更加的准确。然后同样的利用连通区域分析,图片中有两个较大的连通区域,一个是图像的背景,一个是甲骨,背景的连通区域肯定比甲骨大,所以肯定选择连通区域面积第二大的作为甲骨区域。然后同样利用Canny边缘检测甲骨的边缘。获得其边缘后,使用bwboundaries函数来对其进行多边形拟合。
若是详细分析这个任务的具体内容,我的目标是利用多边形拟合算法提取甲骨的外轮廓,为此,我设计并执行了完整的图像处理流程。从一开始,我将甲骨的原始图像导入到系统中,这为整个过程提供了原始数据。随后,我对图像进行了预处理,首先将其灰度化,将原本复杂的彩色图像简化为单一的灰度值,这一步显著减少了不必要的信息干扰,同时保留了甲骨的形态特征。接着,我对灰度图像进行了二值化处理,将图像转化为黑白像素,从而更清晰地将甲骨与背景区分开来。这一步为后续的轮廓提取奠定了基础。
在完成图像预处理后,我开始着手对图像进行连通域分析。这一步是为了识别出图像中与甲骨相关的连通区域,同时剔除噪声和无关区域。通过连通域判断,我将目标区域提取出来,并对较小的无效区域进行了颜色反转,确保只保留甲骨的主要部分作为后续处理的对象。接下来,我对甲骨区域进行了图像形态学处理,包括膨胀和腐蚀等操作。这些处理步骤让我能够修复图像中的小缺陷,平滑甲骨边界,同时加强甲骨区域的完整性,为边缘检测做准备。在获取了形态处理后的图像后,我使用了Canny边缘检测算法。这一步让我能够准确提取甲骨的外轮廓,Canny算法的强大性能确保了边缘检测的精确性,即使甲骨表面可能存在一定的噪声或模糊区域,也可以得到清晰的边缘信息。通过边缘检测,我成功获得了甲骨的轮廓线,为外形拟合提供了必要的数据支撑。最后,在轮廓检测完成后,我使用多边形拟合算法bwboundaries对甲骨的外轮廓进行了拟合。我通过拟合方法将甲骨复杂的外形抽象成规则的多边形,从而更直观地表示甲骨的外部特征。在拟合过程中,我反复调整拟合参数,确保拟合的多边形既能贴合甲骨的实际形状,又不过度复杂化。我还对拟合结果进行了验证,确保拟合的多边形能够完整地覆盖甲骨的外轮廓,同时避免过拟合现象。
(三)第4问的流程设计
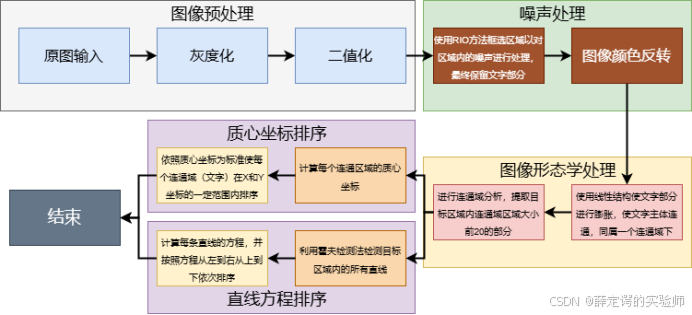
首先,我从原始甲骨文图像的导入开始,这是整个处理流程的基础。我将原始图像输入系统后,立即进入图像预处理阶段。在这一阶段,我通过灰度化操作将原始彩色图像转化为灰度图像,这一过程有效地减少了多余的颜色信息,同时突出甲骨文的主要特征,使文字的结构更加清晰可见。接着,我对灰度图像进行了二值化处理,将图像中的像素值转化为仅包含黑白两色的二值图,从而能够更好地分离甲骨文与背景。这一步的目的是明确区分目标区域(甲骨文文字)和无关区域(背景或噪声)。完成图像预处理后,我进入了连通域分析阶段。这一步至关重要,我通过连通域判断技术对图像中的连通区域进行分析,提取出甲骨文所在的主要连通区域,并对这些区域进行编号。与此同时,我剔除了小的噪声区域以及不相关的连通域,确保只保留真正与甲骨文文字相关的部分。通过这一操作,我有效地筛选出图像中与文字相关的核心区域,为后续的处理提供了可靠的数据基础。
在获得文字的主要连通域后,我开始处理文字的连通域区域。首先,我通过区域划分技术,将连通域中包含的多个字符进行分割,确保每个字符能够单独提取出来。这一步需要对每个区域的几何特性进行分析,例如面积、宽高比等,确保文字的分割是准确的。此外,我还利用区域间的距离等几何特性,进一步优化字符分割的效果。这一步的重点是将原本连在一起的文字块分割为独立的字符,同时保证每个字符的完整性和清晰度。在完成文字的分割后,我对分割得到的字符进行排序。为此,我设计了一套基于字符几何位置的有序规则。例如,根据甲骨文的书写规律,从上到下、从左到右的顺序,对所有分割后的字符进行重新排列,确保输出的符号是有序的。这一步不仅需要考虑字符的位置关系,还要结合甲骨文的实际书写习惯进行调整,确保最终输出的符号符合逻辑和规范。
这套有序的排列需要考虑怎么有序,可以是考虑连通域的面积大小,按照连通域面积大小进行排序;也可以按照位置从左到右从上到下进行排序,若是按照位置顺序进行排序,则有两种方式可以选择,可以选择质心排序法或者直线排序法,本文选用的是按照连通域面积大小进行有序排列方法。
(四)补充工作
补充工作部分可以自行寻找更加清晰的甲骨文图片,本任务所提供的甲骨文图片清晰度较差,导致最终得到的效果并不理想,然而方法是简单且高效的,后续实验结果表明,更换清晰度更好的甲骨文图片后文字分割的效果有了极大的改善。本部分考虑的思路与上述步骤相同,需要注意的是由于图片的形态及明暗部分并不相同,需要考虑使用自适应阈值法方可对图像进行更好的二值化处理。
四、第4问实验代码分析
(一)霍夫变换检测所有直线
%读取图像
I=imread('newer0.png'); %rice.png
%旋转图像并寻找图像边缘
I_rotate=imrotate(I,-30,'crop'); %基本旋转操作
I_rotate_edge=edge(I_rotate,'canny');% Canny边缘检测
%执行霍夫变换得到霍夫矩阵
[H,T,R]=hough(I_rotate_edge);
imshow(H,[],'XData',T,'YData',R,'InitialMagnification','fit');
xlabel('\theta'),ylabel('\rho');
axis on,axis normal,hold on;
%在霍夫矩阵中寻找前5个大于霍夫矩阵中最大值0.4倍的峰值
P=houghpeaks(H,5,'threshold',ceil(0.4*max(H(:))));
x=T(P(:,2));y=R(P(:,1));%将行、列索引转换成实际坐标
plot(x,y,'s','color','white');%在霍夫矩阵图像中标出峰值位置
%绘制直线
lines=houghlines(I_rotate_edge,T,R,P,'FillGap',5,'MinLength',7);
%合并距离小于5的线段,丢弃距离所有长度小于7的直接段
figure
imshow(I_rotate),hold on
max_len=0;
for k=1:length(lines) %依次标出各条直线段
xy=[lines(k).point1;lines(k).point2];
plot(xy(:,1),xy(:,2),'LineWidth',2,'Color','green');
% 绘制线段端点
plot(xy(1,1),xy(1,2),'X','LineWidth',2,'Color','Yellow');
plot(xy(2,1),xy(2,2),'X','LineWidth',2,'Color','red');
%确定最长的线段
len=norm(lines(k).point1-lines(k).point2);
if (len>max_len)
max_len=len;
xy_long=xy;
end
end
plot(xy_long(:,1),xy_long(:,2),'LineWidth',2,'Color','cyan');
上述代码的主要目标是对输入的图像进行处理,提取直线特征,并可视化检测结果,包括旋转图像、边缘检测、霍夫变换、检测直线和绘制结果。
(二)菱形膨胀(可选择)
%菱形区域膨胀
clear;
close all;
% 读取二值图像
bw = imread('newer0.png'); % 替换为实际图像路径
% 显示原始图像
figure;
imshow(bw);
title('原始二值图像');
% 创建菱形结构元素,大小为2
se = strel('diamond', 1);
% 对图像进行膨胀操作(细微膨胀)
dilated_img = imdilate(bw, se);
% 显示膨胀后的图像
figure;
imshow(dilated_img);
title('膨胀后的图像');
% 保存去噪和腐蚀后的图像
imwrite(dilated_img, 'peng2.png');
上述代码的目标是对一个二值图像进行形态学膨胀操作,膨胀的核为菱形结构元素。主要步骤包括读取图像、创建结构元素、执行膨胀操作、可视化结果,并保存处理后的图像。
(三)先菱形膨胀后线性膨胀
% 读取二值图像
bw = imread('newer0.png'); % 替换为你实际的图像路径
% 菱形结构元素膨胀
se_diamond = strel('diamond', 1); % 菱形结构元素,半径为2
bw_diamond = imdilate(bw, se_diamond); % 使用菱形结构元素进行膨胀
% 显示菱形膨胀后的图像
figure;
imshow(bw_diamond);
title('菱形膨胀后的图像');
% 线性结构元素膨胀
se_line = strel('line', 1, 90); % 线性结构元素,长度为2,角度为90(竖直线)
bw_line = imdilate(bw_diamond, se_line); % 对菱形膨胀后的图像进行线性膨胀
% 显示线性膨胀后的图像
figure;
imshow(bw_line);
title('线性膨胀后的图像');
% 腐蚀操作(去除膨胀后可能产生的噪声)
se_erosion = strel('disk', 1); % 使用半径为1的圆形结构元素进行腐蚀
bw_eroded = imerode(bw_line, se_erosion); % 对线性膨胀后的图像进行腐蚀操作
% 显示腐蚀后的图像
figure;
imshow(bw_eroded);
title('线性膨胀后进行腐蚀的图像');
% 保存最终处理后的图像
imwrite(bw_eroded, 'peng1.png');
由于不同的图像所适宜的最佳膨胀方式各不相同,经过圆形、矩形、菱形、线形膨胀后得到如上的先菱形后线性膨胀及对应的参数为最佳膨胀方式。
(四)文字二值化处理
% 读取二值图像
img = imread('modified_binary_image.png'); % 这里假设你的图像是二值图像
% 显示图像并获取用户的多边形框
imshow(img);
h = impoly; % 用户用鼠标点击并绘制一个多边形区域
position = wait(h); % 获取多边形顶点的坐标
% 使用 poly2mask 函数将多边形区域转为一个二值掩膜
mask = poly2mask(position(:,1), position(:,2), size(img, 1), size(img, 2));
% 将多边形区域设置为黑色 (0)
img(mask) = 0;
% 显示修改后的图像
imshow(img);
% 如果需要,可以保存修改后的图像
imwrite(img, 'heise.png');
(五)文字提取并排列
% 排列连通区域前20大的连通域并输出为一行
clear;
close all;
clc;
% 读取二值图像
bw = imread('quzao1.png'); % 替换为实际图像路径
% 使用bwlabel标记图像中的连通区域
[labeled_img, num] = bwlabel(bw); % 标记图像中的连通区域
% 提取每个区域的属性
stats = regionprops(labeled_img, 'BoundingBox', 'Area', 'Centroid');
% 根据区域的面积进行排序
[~, sortedIndexes] = sort([stats.Area], 'descend'); % 根据面积降序排序
% 选择面积前35大的区域
topNIndexes = sortedIndexes(2:min(35, num)); % 如果区域少于35个,则取所有区域
% 创建一个新的图形窗口来显示排序后的字符区域
figure;
hold on;
axis off; % 不显示坐标轴
title('按面积排序后的前35个连通区域');
% 目标高度,调整每个区域的高度一致
target_height = 50; % 可以根据需要调整高度
% 创建一个空的列表来保存每个区域的图像
cropped_regions = cell(1, length(topNIndexes));
% 依次显示每个排序后的区域,并标上序号
for k = 1:length(topNIndexes)
% 获取当前连通区域的BoundingBox
thisBB = stats(topNIndexes(k)).BoundingBox;
% 从原图中裁剪出该区域的图像
cropped_region = imcrop(bw, thisBB);
% 调整区域图像的大小,使其高度一致
cropped_region_resized = imresize(cropped_region, [target_height NaN]); % 高度固定,宽度自适应
% 将调整后的区域保存到列表中
cropped_regions{k} = cropped_region_resized;
% 在subplot中显示区域图像
subplot(1, 35, k); % 显示为一行20列
imshow(cropped_region_resized);
title(['#' num2str(k)], 'FontSize', 8); % 标上序号
end
% 合并图像,将20个字拼接为一行
% 每个区域图像都会被拉伸为相同的高度,按横向拼接
all_regions_concat = horzcat(cropped_regions{:});
% 显示拼接后的图像
figure;
imshow(all_regions_concat);
title('拼接后的前35个连通区域');
% 保存拼接后的图像
imwrite(all_regions_concat, 'merged1.jpg'); % 保存为图片
disp('拼接后的图像已保存为 "merged1.jpg"');
五、第4问实验结果分析
旋转后的图像如下图所示。

对旋转后的甲骨文图像使用连通域面积第二大部分颜色反转的方法得到如下图的背景颜色反转图像,但是其得到的效果并不佳。

采用先去除噪声再旋转的方法得到如下图所示的图片,但效果仍一般,可以观察到文字失真较为严重。

经过对比所得决定不采用先旋转再提取文字的方式,故而选择先线性结构膨胀再提取文字的方式得到如下图所示的图像。

对上图所示的图像进行文字连通域提取,选择提取其面积前35大的部分得到如下图17所示的图片,所有文字部分被提取出来。

对上图所示所提取出来的文字计算其文字连通域面积得到如下表所示的表格。
| 区域 | 值 | 区域 | 值 | 区域 | 值 | 区域 | 值 |
| 区域 2 | 103 | 区域 11 | 77 | 区域 21 | 43 | 区域 31 | 30 |
| 区域 3 | 99 | 区域 12 | 75 | 区域 22 | 42 | 区域 32 | 29 |
| 区域 4 | 91 | 区域 13 | 70 | 区域 23 | 41 | 区域 33 | 28 |
| 区域 5 | 85 | 区域 14 | 70 | 区域 24 | 36 | 区域 34 | 28 |
| 区域 6 | 82 | 区域 15 | 62 | 区域 25 | 35 | 区域 35 | 26 |
| 区域 7 | 79 | 区域 16 | 59 | 区域 26 | 33 | ||
| 区域 8 | 78 | 区域 17 | 56 | 区域 27 | 33 | ||
| 区域 9 | 77 | 区域 18 | 50 | 区域 28 | 33 | ||
| 区域 10 | 77 | 区域 19 | 48 | 区域 29 | 32 | ||
| 区域 20 | 44 | 区域 30 | 31 |
连通域面积前2至35大的文字被提取出来排布成为一整列,效果如下图所示。

在调整文字图片尺寸后将其重新排布成为一列得到如下图的甲骨文文字。
![]() 其中有序即为按文字连通域面积递减排列,连通域面积之序即为有序。
其中有序即为按文字连通域面积递减排列,连通域面积之序即为有序。

















 6081
6081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









