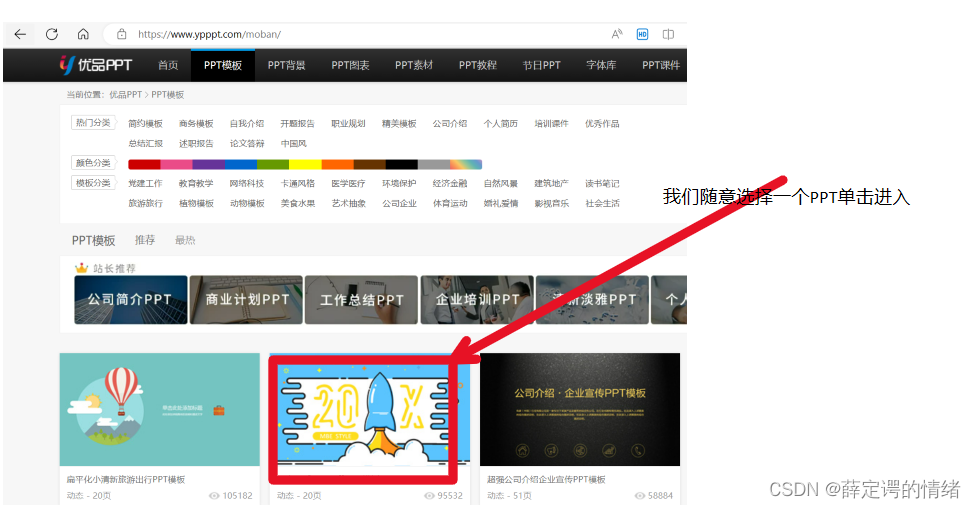
目录 一、网络爬虫是什么? 二、网站分析 1.进行网站分析: 2.分析完毕,开始反推 三、代码分析 1.引入库 2.网页源码 四、运行结果 五、总结 一、网络爬虫是什么? 网络爬虫(又称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫 二、网站分析 网站网址: https://www.ypppt.com/moban/ 1.进行网站分析: (1)点击下载,可以看到这样一个界面








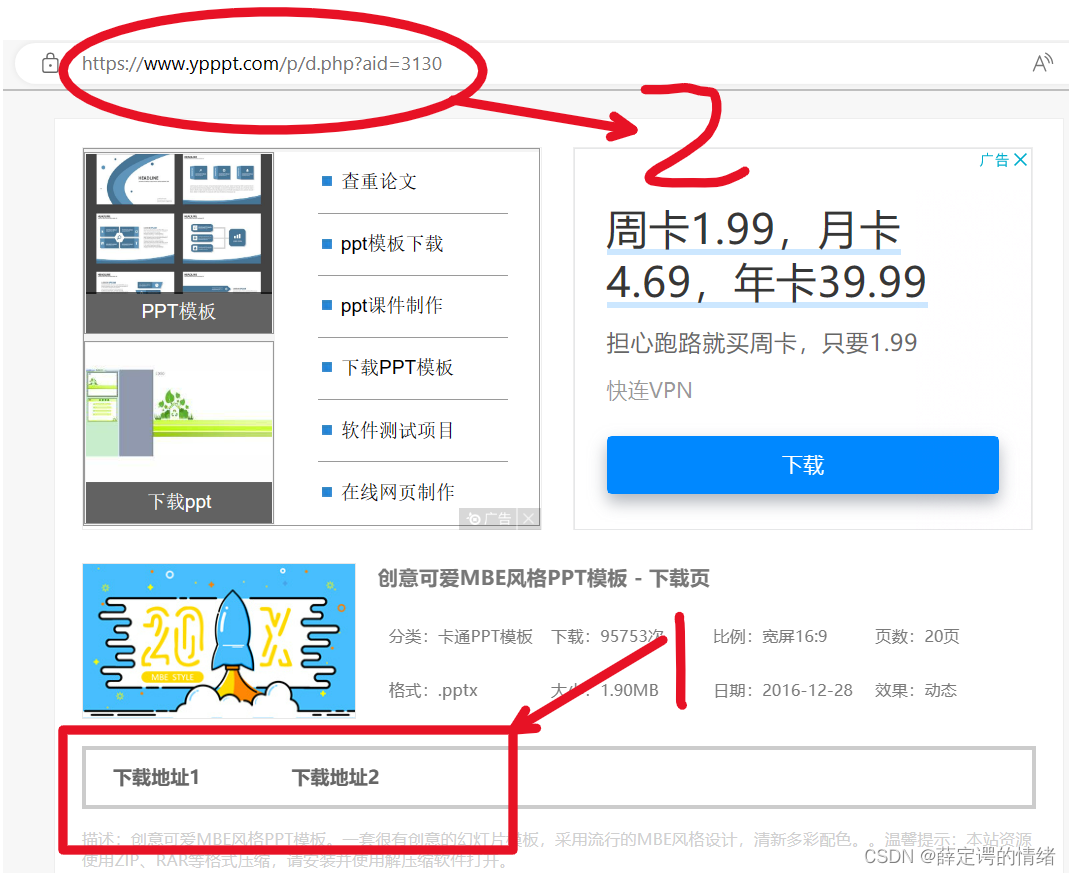
 文章介绍了如何使用Python的requests库进行网络爬虫,通过分析网页源码获取PPT模板的下载地址。首先定义URL,伪装成浏览器发送请求,然后通过正则表达式提取所需信息,找到aid参数,进一步构造新的URL以获取下载链接,最后保存下载内容。
文章介绍了如何使用Python的requests库进行网络爬虫,通过分析网页源码获取PPT模板的下载地址。首先定义URL,伪装成浏览器发送请求,然后通过正则表达式提取所需信息,找到aid参数,进一步构造新的URL以获取下载链接,最后保存下载内容。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 393
393

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






