






这是目前paperwithcode 的榜单排行时间序列预测排名第二的模型,属于DLinear的变种(个人感觉和目前第一的Xpatch一样创新点并不是特别足,估计这也是他只发了C刊的原因)
论文链接:2312.06786
代码链接:RogerNi/MoLE
概述
我对这个模型的理解可以大致概括为从单独的A模型变成了0.5A+0.3B+0.2C这样子的模型。
先看一下他的概述(稍微看一下就好):
长期时间序列预测(LTSF)旨在根据过去的值预测时间序列的未来值。目前,线性中心模型在某些情况下达到了该问题的最先进水平(SOTA),这些模型主要具有线性映射层。然而,由于其固有的简单性,它们无法使其预测规则适应时间序列模式的周期性变化。为了应对这一挑战,我们提出了一种针对线性中心模型的专家混合风格增强方法,并提出了线性专家混合模型(MoLE)。MoLE不是训练单个模型,而是训练多个线性中心模型(即专家)和一个路由器模型,该路由器模型对它们的输出进行加权和混合。虽然整个框架是端到端训练的,但每个专家都学习专注于特定的时间模式,而路由器模型学习自适应地组合这些专家。实验表明,在我们评估的超过78%的数据集和设置中,MoLE降低了线性中心模型的预测误差,包括DLinear、RLinear和RMLP。通过使用MoLE,现有的线性中心模型可以在PatchTST报告并与之比较的实验中,在68%的实验中实现SOTA LTSF结果,而现有的单头线性中心模型仅在25%的案例中实现SOTA结果。
模型
我们先看下图,是一个普通的线性模型。
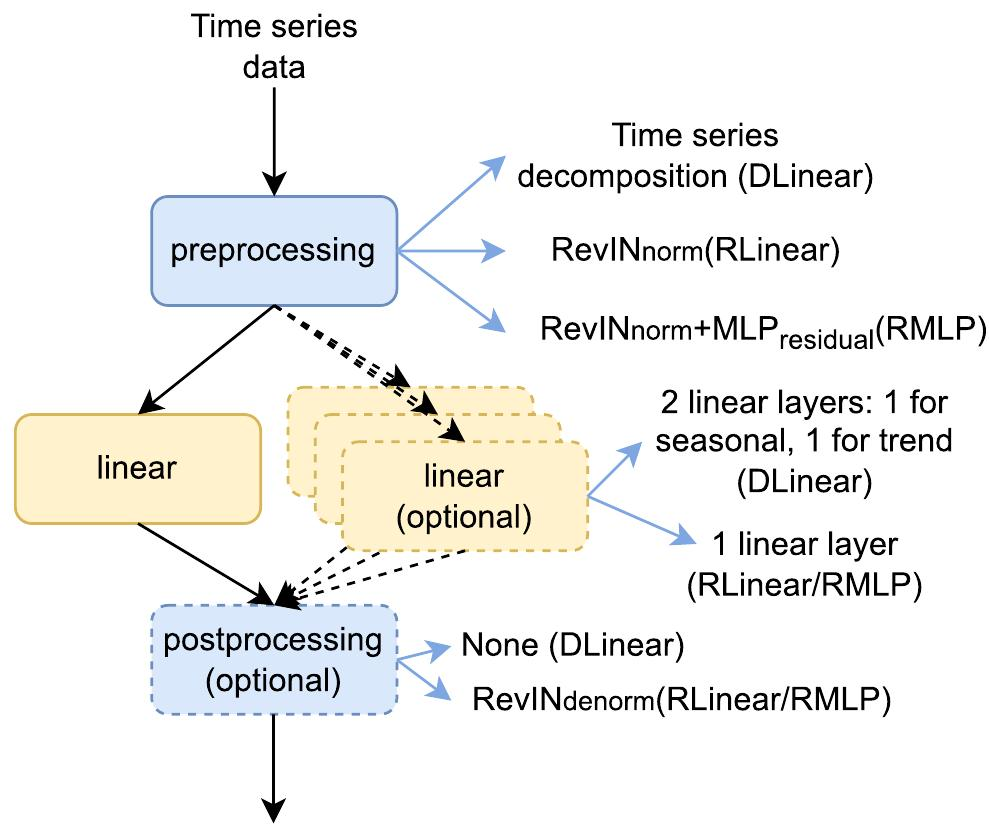
作者的思路就是将一堆这样的普通线性模型弄一起。
下图展示了他的混合专家方法如何与任意以线性为中心的LTSF模型集成。最初,将所有内容(包括线性层)分组到一个头中。输入时间序列数据被传递到所有头,并且所有头的输出被传递到混合层(混合层充当混合专家中的路由器)。混合层包含一个两层MLP,它接受起始时间戳的嵌入作为输入,并为每个头的输出生成一个权重。这些权重是通道特定的,这意味着每个通道将具有不同的权重集,这些权重集总和为1。
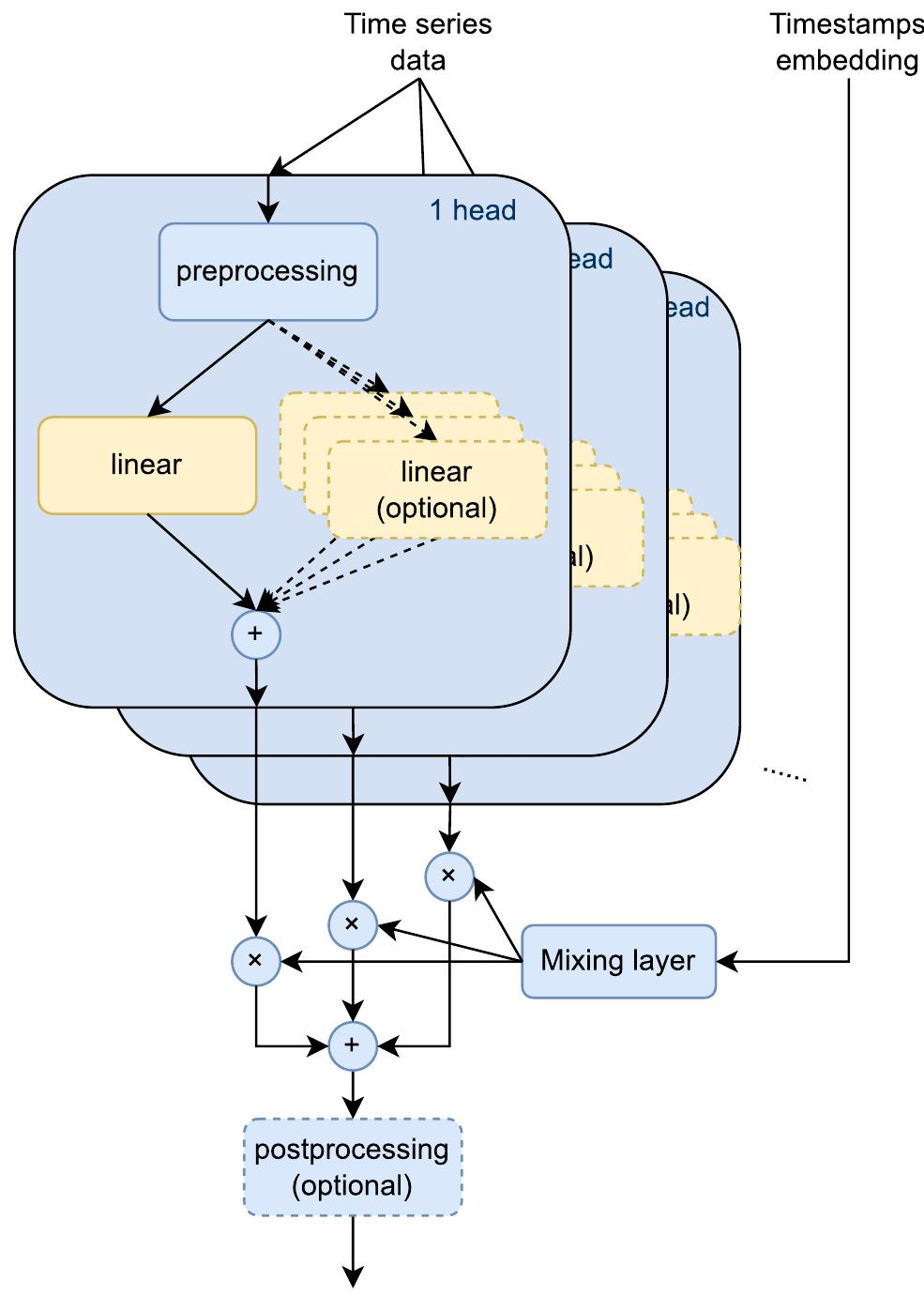
消融实验
我先放消融实验而不是实验结果因为这里还是有些值得学习的地方。
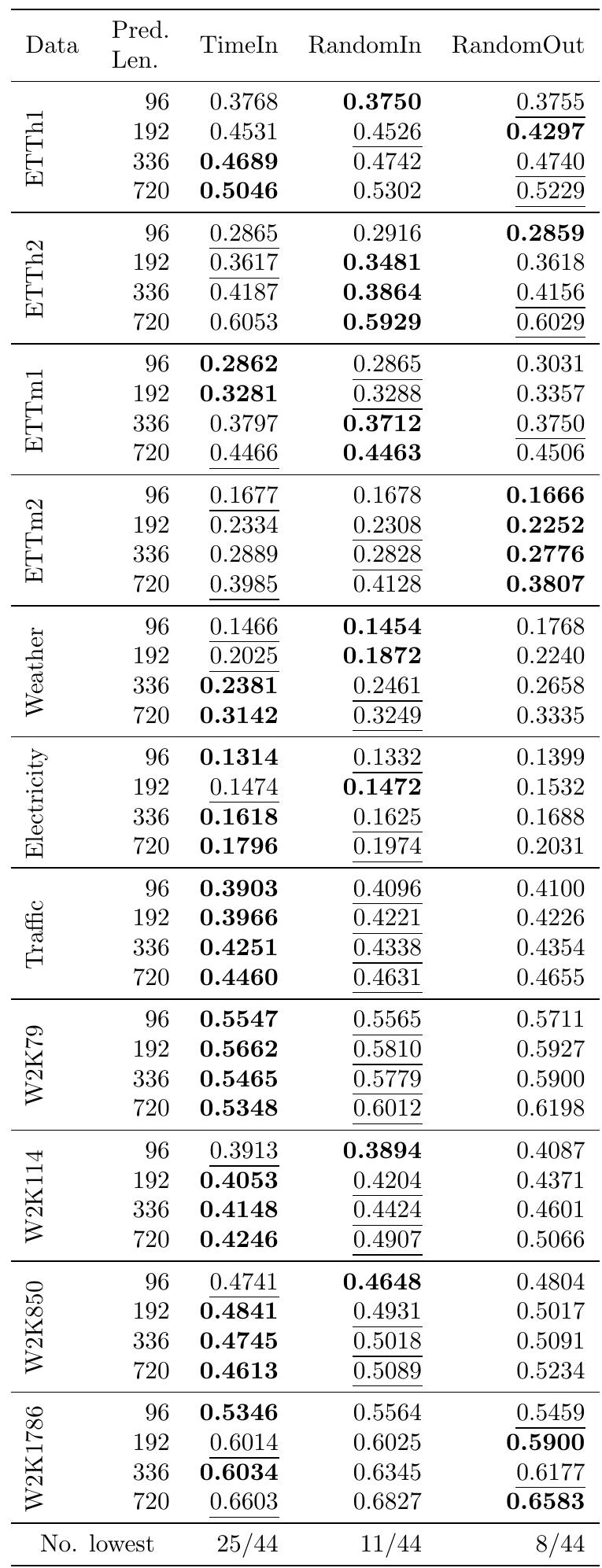
第一个消融实验的基础上,引入了第二个修改,即使用随机权重而不是混合层的输出来计算来自头的输出的加权和。这在训练和测试时都进行。称此变体为RandomOut。将具有时间戳输入的原始MoLE称为TimeIn。
RandomIn和RandomOut偶尔会产生比TimeIn更低的损失,作者有了以下两个猜想:
1:RandomIn 和 RandomOut 可能具有正则化效应,类似于 dropout,它可以防止网络将头部权重过度拟合到训练数据。这具有使所有头部都变得更好的效果。
2:假设时间序列可以大致分为具有不同时间模式的区域(例如,工作日与周末)。对于长输入序列,该序列可能会遍历多个区域。因此,无论起始时间如何,没有单个头部能够捕获完整的动态。然而,随着输入序列的延长,线性层有更多的过去数据需要考虑,并且这些数据中的一些模式可以暗示序列中即将发生的改变。因此,我们预测以起始时间为条件的效应应该不那么有利。相反,随着输入序列长度的减少,输入时间的效果应该更有利。
对此做了以下的实验:
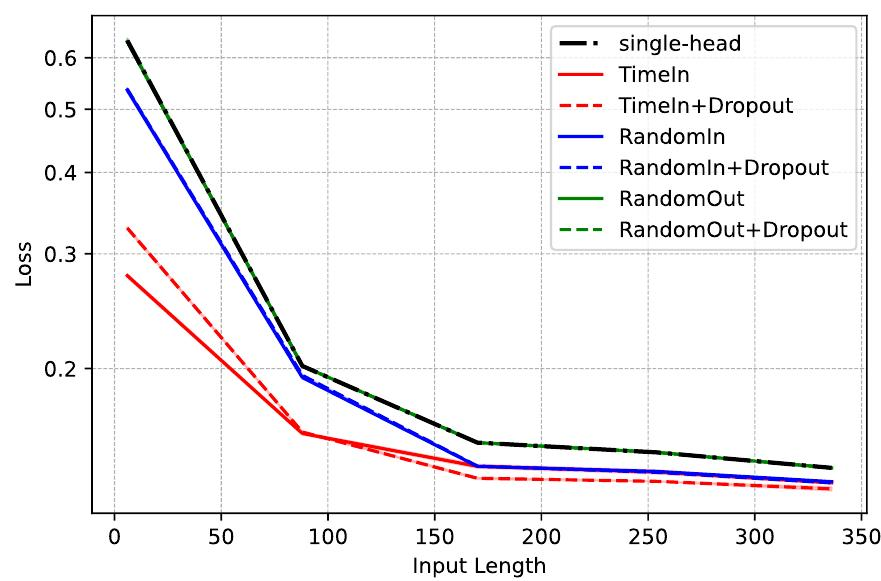
作者的结论:
(1)随着输入长度的增加,TimeIn 的性能接近单头基线,以及 RandomIn 和 RandomOut。这表明效应 2 可能确实是正确的:当输入序列长度减小时,以时间戳为条件更有益。(请注意,在 表 中的早期结果使用了固定的输入长度 336,这是上图的最右端点,MoLE 的增益在此处最不明显。)
(2)Dropout对RandomIn或RandomOut几乎没有影响,但它确实会影响TimeIn。这表明使用随机输入可能确实具有正则化效果(效果1),这大致相当于对head进行dropout。为了同时利用这两种效果,可以以时间戳为条件,同时对head进行dropout。
(3) 随着输入序列长度的增长,dropout对TimeIn的影响变得更有益。这表明,对于更长的输入序列,过度拟合起始时间戳更有害。
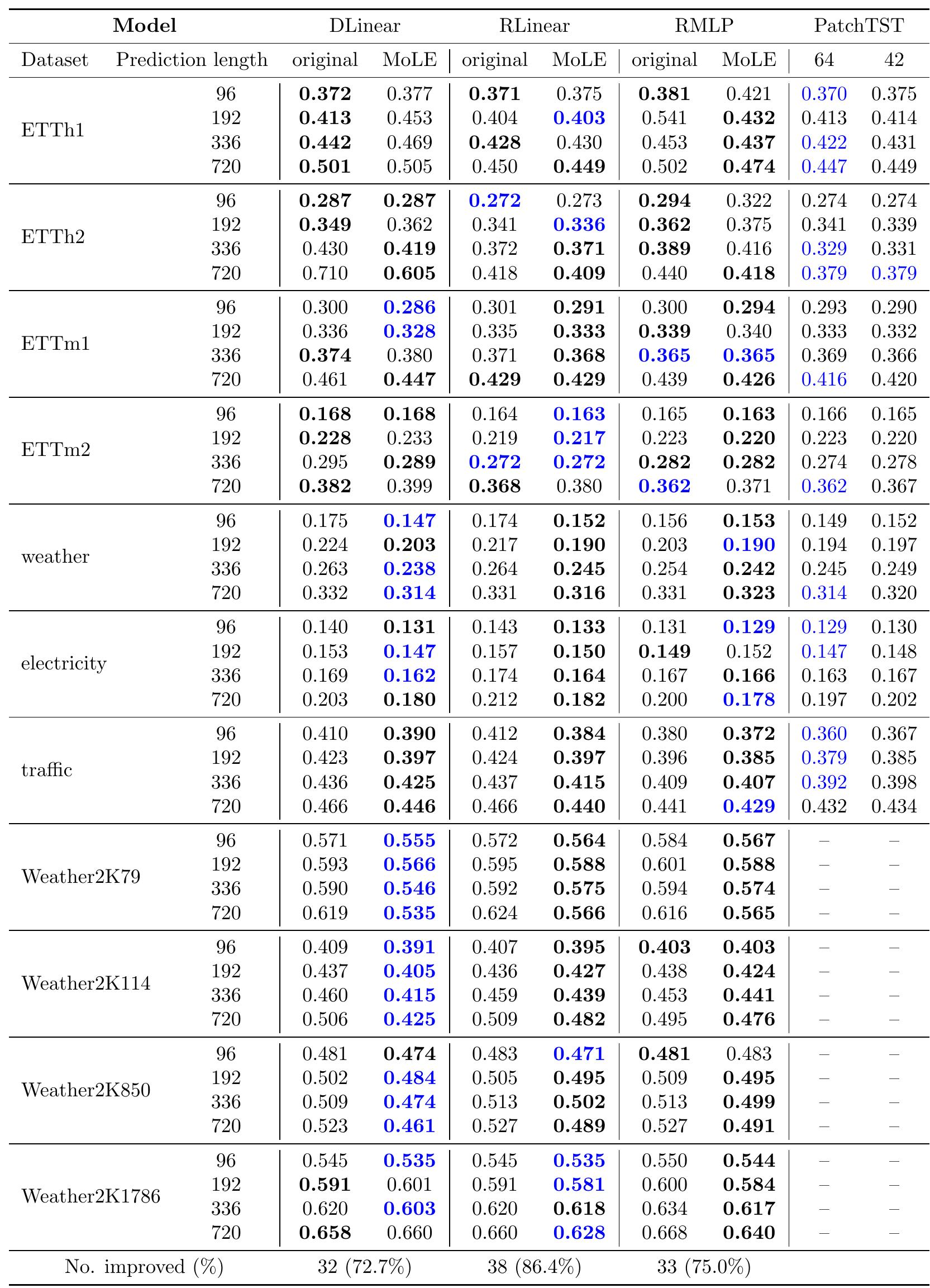
实验结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









