







 本文介绍了如何使用Python爬虫获取百词斩已学单词列表,包括登录过程分析、数据解析及实战案例,适合Python爬虫初学者。通过学习路线、书籍推荐、工具包合集、面试题和兼职资源,帮助读者深入理解Python爬虫并提升技能。
本文介绍了如何使用Python爬虫获取百词斩已学单词列表,包括登录过程分析、数据解析及实战案例,适合Python爬虫初学者。通过学习路线、书籍推荐、工具包合集、面试题和兼职资源,帮助读者深入理解Python爬虫并提升技能。
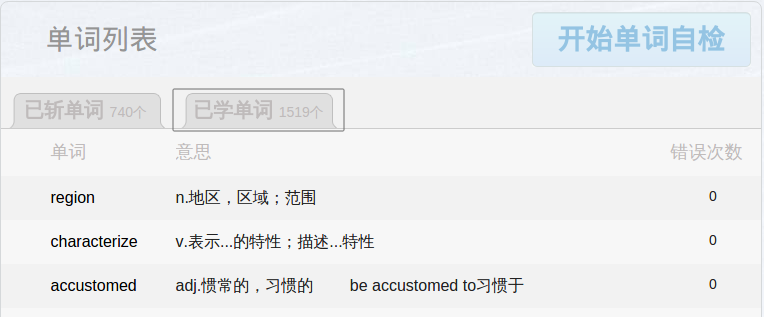
百词斩是一款很不错的单词记忆APP,在学习过程中,它会记录你所学的每个单词及你答错的次数,通过此列表可以很方便地找到自己在记忆哪些单词时总是反复出错记不住。我们来用Python来爬取这些信息,同时学习Python爬虫基础。
首先来到百词斩网站:http://www.baicizhan.com/login
这个网站是需要登录的,不过还好没验证码,我们可以先看下在登录过程中浏览器POST了哪些数据。打开浏览器开发工具(F12),以Chrome浏览器为例,记录登录过程中浏览器的Network情况:
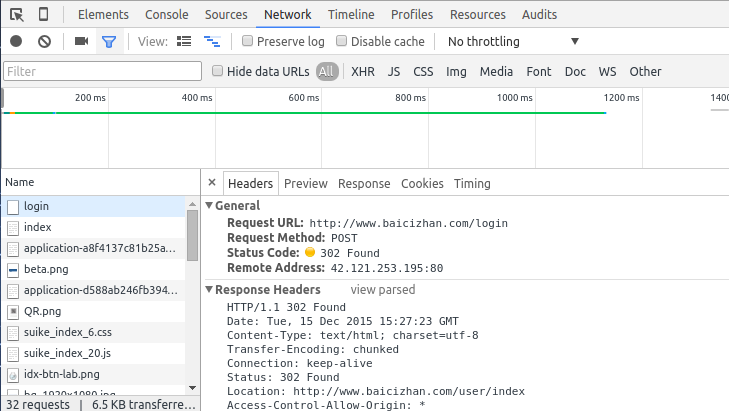
我们可以发现,在登录过程中,浏览器向http://www.baicizhan.com/login以POST方式提交了数据。提交了什么数据呢?我们可以在下面的Form Data里看到。

其中,email是用户名,raw_pwd就是密码,这里的数据是需要经过URL编码的,我们可以点view URL encoded查看编码后的样子。URL编码需要urllib库。
在请求头(Request Headers)部分,我们还看到了Cookie。因此,我们还需要cookie库,来处理我们的Cookie。
1 import urllib 2 import urllib2 3 import cookielib 4
5 email = 'your\_email'
6 pwd = 'your\_password'
7 data = {
'email':email,'raw\_pwd':pwd}
8 post\_data = urllib.urlencode(data)  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









