






在写此课程设计的时候发现目前关于分布估计算法(Estimation of Distribution Algorithm,EDA)的实际应用算法还比较少,记录分享一下本人的计算智能课程设计作业方便大家讨论
一、主要实验内容
本项目对问题的解决方法和研究目标总结为以下几点:
(
1
)结合数据探索性分析和优化算法的方法进行特征选择:利用数据探索性分析对原始高维特征数据进行降维处理。在特征选择过程中,采用分布估计算法进行优化。EDA
能够模拟潜在的特征子集,并依据其性能(例如分类准确率或其他评价指标)进行搜索和优化,以期得到保留最具信息量的特征子集。
(
2
)选用高维数据集:本项目对乳腺癌数据集进行特征处理。该数据集具有高维度、小样本和高噪声等特点,数据集特征维度为 30
。
(
3
)选取合适的分类器来进行模型性能评估:选用多种机器学习分类器针对得出的特征子集做分类测试,通过分类准确率来验证提出方法在乳腺癌诊断分类问题上的有效性,以及所得出的特征子集对于模型预测能力的影响。在分类问题中,高分类准确率和低特征数量通常是相互矛盾的目标。我们迫切需要一种方法来综合考虑这两个因素,以实现在提升高维度数据分类准确率的同时,最大限度地减少特征数量。
在特征选择中,
EDA
尝试模拟和更新特征子集的分布情况,利用进化过程中的选择、交叉和变异等操作来不断调整和更新特征子集的概率分布,以逐步优化特征组合,以便更有效地发现具有良好分类性能的特征组合。其中,常用的概率模型有高斯模型、多项式模型、边缘分布模型以及
联合分布模型。

分布估计算法用于特征选择流程图
二、问题分析
本项目选用威斯康星州乳腺癌(诊断)数据集(
Breast Cancer Wisconsin (Diagnostic) Data Set)进行特征分析研究。乳腺癌(诊断)数据集是由威斯康星 大学医学院的 Dr. William H. Wolberg
等人收集的数据集,它包含了针对乳腺肿瘤的细胞核样本的特征信息,最初是用于乳腺癌细胞核样本的特征提取和分类研究。数据集中包含 569
份样本数据,每个样本包含相关的
30
项特征数据,这些特征是通过对数字化图像中的细胞核进行分析而获得的。此外,每个样本都有一个对应的分类标签,表示细胞核是良性的还是恶性的 。
数据集可从 www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data/处获取
为更加清晰地分辨不同特征对于良性肿瘤与恶性肿瘤的取值差异大小,可先对数据值进行了标准化的初步处理,再通过绘制散点图展示了各个特征值不同特征值随着诊断结果的分布情况。
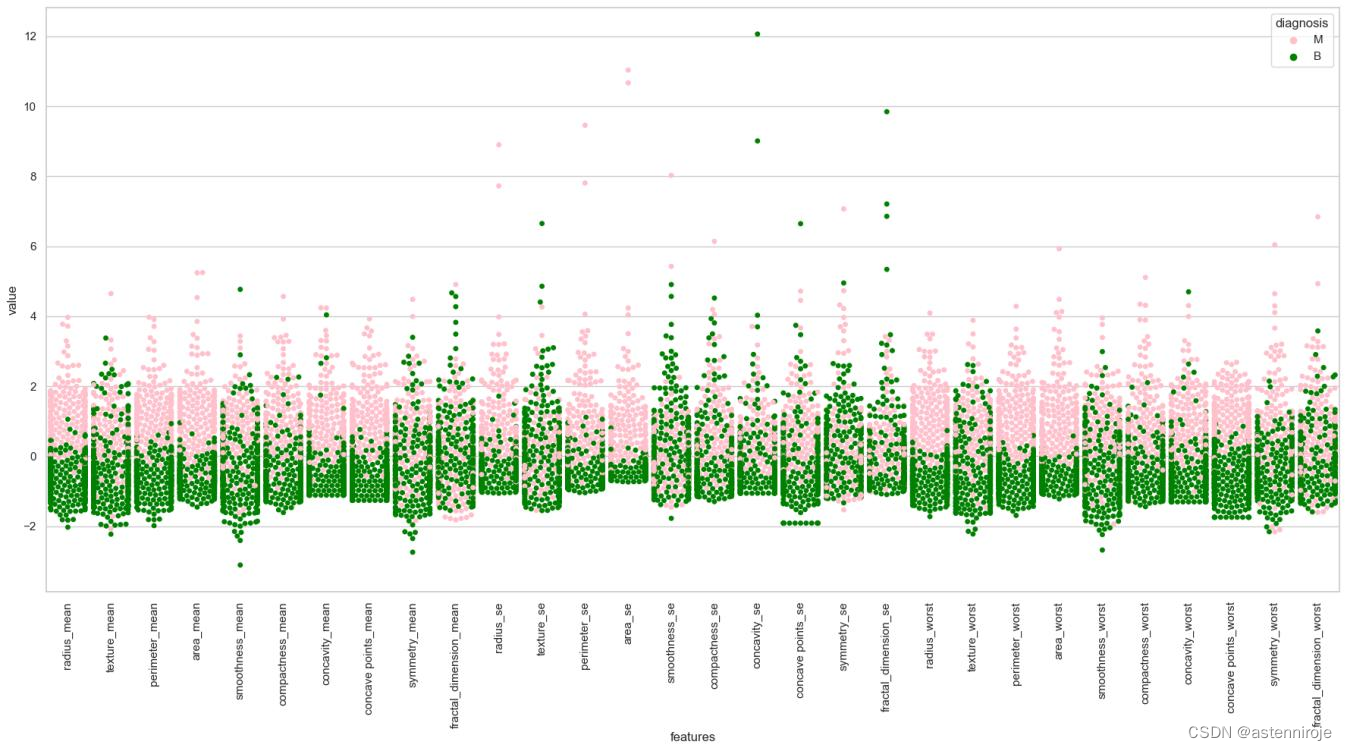
从中可以看出,在一些特征上良性肿瘤与恶性肿瘤表现出来的特征值的分布情况具有明显的差别,如半径、周长、面积、凹凸点数量等;而在一些特征值上恶性肿瘤数据和良性肿瘤数据混合,所以在使用该特征时很难进行分类,如平滑度、分形维数等。
三、算法设计
算法逻辑图如下:
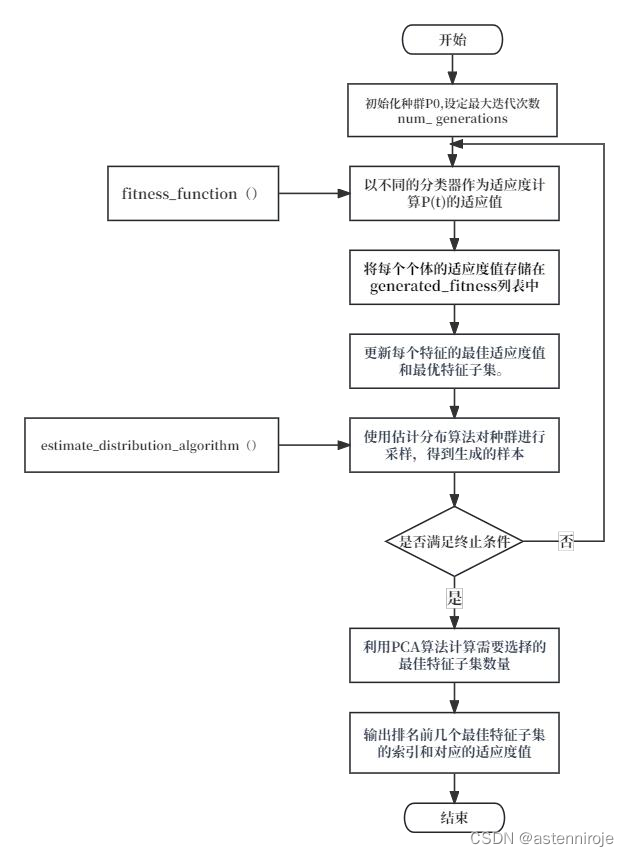
概率模型是
EDA 算法中的关键。本项目对比分析了不同概率模型在乳腺癌数据集上的特征选择效果,计算概率分布方法
estimate_distribution_algorithm()的具体代码找不到了,这里列出该
estimate_distribution_algorithm()
的算法执行过程的伪代码:


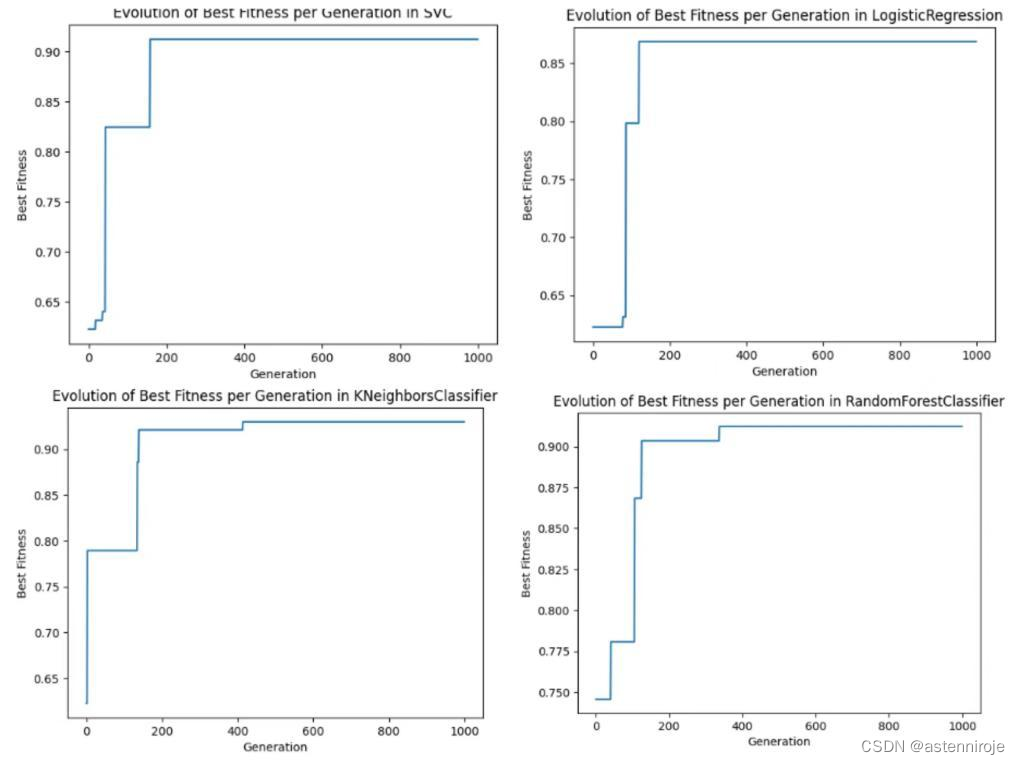
基于多项式分布模型,对比不同分类模型在乳腺癌数据集上的表现情况,如下图。
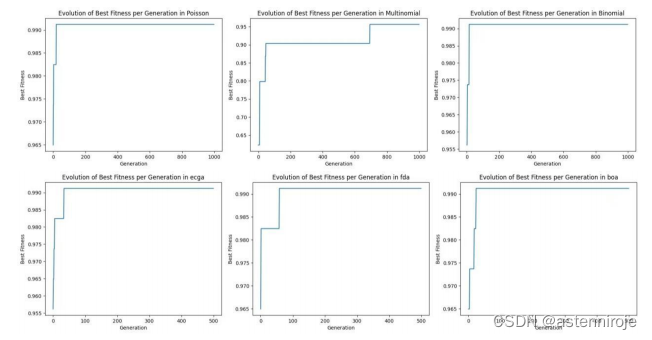
基于随机森林分类模型,对比
EDA
算法中不同概率模型在乳腺癌数据集上的表现情况,如下图。
四、实验总结
在本项目中,使用了
EDA
进化计算算法来辅助特征选择。算法通过生成随机样本并基于特征子集的表现来估计每个特征的重要性。这种方法优势在于能够利用模型的性能指标,例如分类准确率或回归误差,作为特征重要性的度量标准。通过迭代进化,我们可以发现在特定任务中,某些特征子集对于模型性能的贡献更大,这有助于提高模型的泛化能力。经过对比以上提出的特征选择方法,本文进行了反思与总结如下:
(
1
)综合以上算法得出的最佳特征子集,可以看出在原先的
30
项特征数据项 中 ,symmetry_worst
、
texture_worst
、
smoothness_se
、
texture_mean
、perimeter_mean、
area_mean
、
smoothness_mean
等数据对模型分类效果影响较大,与前文中数据探索性图表显示的分类效果相符合。
(
2
)在上述
6
种
EDA
算法中,
FDA
(因子化分布算法)、
BOA
(贝叶斯优化算法)与二项分布(Binomial
)模型在本项目中表现较好,适合此乳腺癌数据集上的特征选择。
(
3)数据探索性分析对于联系紧密的特征数据集的特征选择问题效果欠佳对数据预处理的依赖性较小。
(
4
)迭代过程中发现种群收敛过快,每一个粒子在迭代了上百代后得出的适应度值相似度过高,需要引入一些随机性或多样性可以帮助搜索更广泛的特征子集空间,防止陷入局部最优。
(
5
)粒子适应度值相似度过高会导致最佳特征子集数量过多,需要对输出的特征子集数加以排序控制(此处用 PCA
算法确定主成分数量),以提高此特征选择方法有效性。
(
6
)在高维数据集处理上,
FDA
与
BOA
概率模型占用过多的时间和空间,训练符合多元正态分布与高斯混合模型的样本非常耗时,且存储高斯混合模型样本、均值向量和协方差矩阵占用较多空间。
(
7
)由于每次选择的粒子有随机性,所以得出的最佳适应度值效果不稳定。
(
8
)一些机器学习模型中的
feature_importances_
属性和系数(
coefficients
)相比于 EDA
算法更能解释模型对特征的重要性。
实验结果强调了特征选择在模型性能中的关键作用。选择合适的特征子集能够显著提高模型的性能和泛化能力,同时减少了模型训练和预测的时间。而使用进化计算算法来辅助特征选择,则进一步提高了选择的准确性和效率。通过这种方法,可以更快速地确定最优特征子集,避免了盲目地搜索所有特征组合的问题,从而在复杂的特征空间中找到更好的特征子集。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









