







前言
C语句可分为以下五类:
- 表达式语句
- 函数调用语句
- 控制语句
- 复合语句
- 空语句
本章后面介绍的是控制语句。
控制语句用于控制程序的执行流程,以实现程序的各种结构方式,它们由特定的语句定义符组成,C语
言有九种控制语句。
可分成以下三类:
- 条件判断语句也叫分支语句:if语句、switch语句;
- 循环执行语句:do while语句、while语句、for语句;
- 转向语句:break语句、goto语句、continue语句、return语句。
分支语句(选择结构)
分支语句又叫条件判断语句有 if 、switch
一、 if 语句
1. if 语法结构代码演示
注意:
① 语句后面跟分号 ; 代表语句结束
② if(表达式)不能直接跟分号 ;, 不然语句会过不去,
③ 同理 else 和 else if 也不能直接跟,演示:
if(i == 1); //err不能直接跟
else; //err
else if(i>1); //err
if 语句三种语法形式演示:
① 输入一个数,判断其是否满18不满输出未成年,满则不打印
#include<stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
if (age < 18)
{
printf("未成年\n");
}
return 0;
}
② 输入一个年龄数判断,判断其是否满18(成年)
#include<stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
if (age < 18)
{
printf("未成年\n");
}
else
{
printf("成年\n");
}
return 0;
}
③ 输入一个年龄数,输出这个年龄数代表的年龄段
#include<stdio.h>
int main()
{
int age = 0;
scanf("%d", &age);
if (age < 18)
{
printf("少年\n");
}
else if(age >= 18 && age < 30)
{
printf("青年\n");
}
else if(age >= 30 && age < 50)
{
printf("中年\n");
}
else if (age >= 50 && age < 80)
{
printf("老年\n");
}
else
{
printf("长命百岁");
}
return 0;
}
2. 当一个 if 或者 else 或 else if 后面跟多个语句要加大阔号 { }
int main()
{
int age = 0;
scanf("%d", &age);
if (age < 18)
{
printf("未成年\n");
printf("打王者有防沉迷\n");
}
else
{
printf("成年\n");
printf("解除防沉迷\n");
}
return 0;
}
总结分析:
① 养成良好的代码风格是必要的,
② 我们可以从上面所示代码中可以看出我不管是一条语句还是两条语句我都加大括{ }号
③ 建议:不管语句多少都加大括号方便阅读理解
3. else的匹配:else是和它离的最近的if匹配的
接下来我们看一个代码,代码风格不好引起的阅读错误
#include <stdio.h>
int main() {
int a = 0;
int b = 2;
if(a == 1)
if(b == 2)
printf("hehe\n");
else
printf("haha\n");
return 0; }
当你看到这个代码时是不是感觉会打印 haha,没错我跟你一样,也以为是 haha ,
但实际结果却是
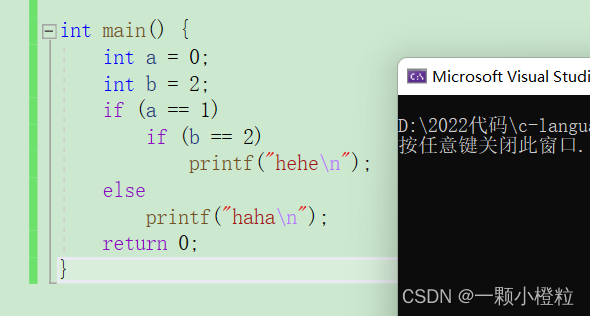
(1)结果:不打印
(2)为什么会不打印呢?因为else和最近的 if 的匹配成一条语句,
(3) 分析:当 a = 0 时判断a == 1 为假,后面的语句不执行直接跳出
我们改一下代码风格就能清楚的阅读理解到代码意思了
#include<stdio.h>
int main() {
int a = 0;
int b = 2;
if (a == 1)
{
/* if (b == 2)
{
printf("hehe\n");
}
else
{
printf("haha\n");
} */
}
return 0;
}
分析:
① 这个代码我把else匹配的 if 用注释框起来。
② 我把每一个 if 或 else 用大括号{ }包括起来,就很容易看出这个代码的结果为不打印,
③ 增加了可读性,所以一个良好的代码风格是必要的
4. 赋值 = 和 等于 == 的区别与纠正方法
你是不是也跟我一样有过 一个 = 误会成等于的意思所以常常写出这种代码;
比如我想看 a 初始化为10,然后 if 判断 a 等于 1 的结果,结果肯定是不打印,
但我们要是搞混了赋值和等于,它就会:
看代码:
#include<stdio.h>
int main()
{
int a = 10;
if (a = 1)//a被赋值成1
{
printf("haha\n");
}
return 0;
}
(1)结果:打印hehe
(2)为什么会打印hehe?,不应该是不打印吗?
① 因为我把原本判断条件是 a 等于 1,变成了赋值, 赋值就是把 a 的值改成1,1为真 所以打印hehe;
② 那不偏离我起初本意吗;所以我们要特别注意赋值和等于的区别,
③ 作为一个程序员必须对一个 = 和两个 == 非常警惕
(3) 但有时候就是搞混了编译器又不会报错,那咋办,我们可以这么写,就可以避免搞混啦
#include<stdio.h>
int main()
{
int a = 10;
if (1 == a)//把原本a == 1换过来
{
printf("haha\n");
}
return 0;
}
分析:
① 我们在判断的时候把 if 里面的常量 1 和变量 a 换了一下位置,在等于的下是允许的,
② 但我们这时候要想把赋值也这么做,就不行了,它会报错了,如图:
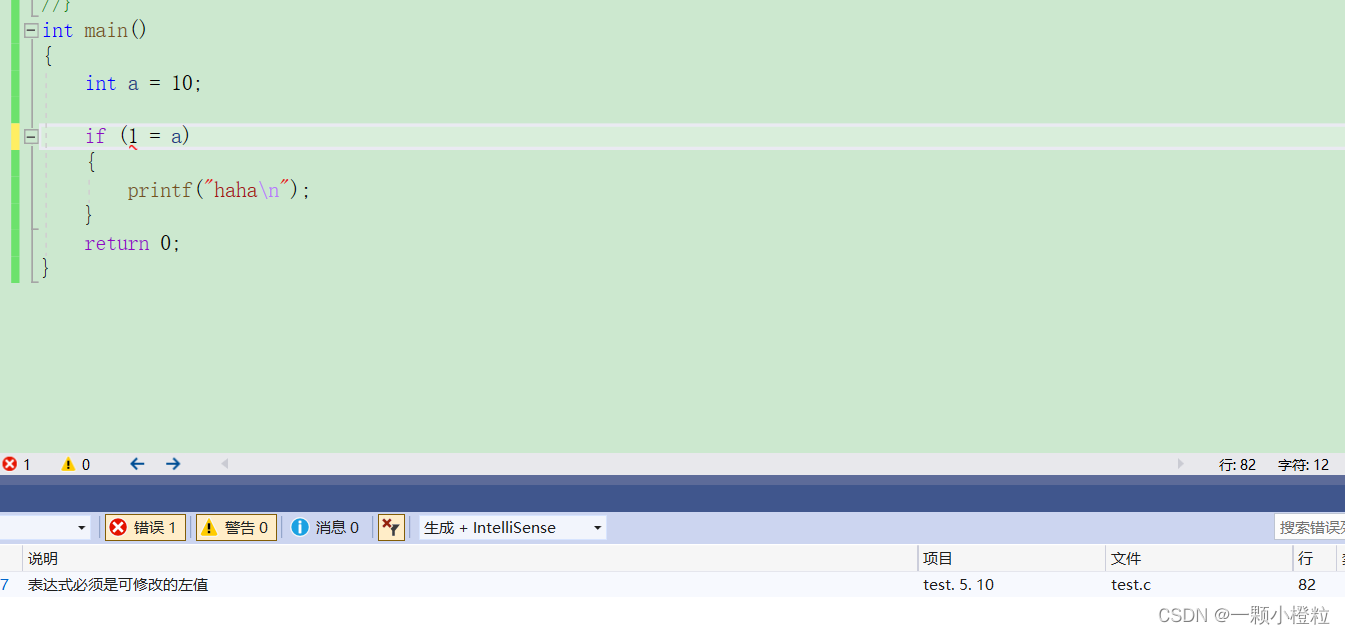
编译器瞬间报错,
分析:因为常量是不能改变的,a 被赋值给 1 ,改变常量 1 是不可以的
总结:当你写等于的时候就把 常量的值放左边,变量放右边,如 1 == a,这样写老师都夸你
5. 练习
(1) 判断一个数是否为奇数
#include<stdio.h>
int main()
{
int a = 0;
scanf("%d", &a);
if (a % 2 == 1)//左边是表达式,可不是变量
{
printf("奇数\n");
}
else
{
printf("不为奇数\n");
}
return 0;
}
注意:判断为表达式可不是变量不能写成 1 == a%2,这样写是错的
(2)输出1-100之间的奇数
#include<stdio.h>
int main()
{
int a = 0;
while (a <= 100)
{
if (a % 2 == 1)
{
printf("%d ", a);
}
a++;
}
return 0;
}
二、switch 语句
switch语句也是一种分支语句。
常常用于多分支的情况。
比如:
输入1,输出星期一
输入2,输出星期二
输入3,输出星期三
输入4,输出星期四
输入5,输出星期五
输入6,输出星期六
输入7,输出星期日
那我没写成 if…else if …else if 的形式太复杂,
int day = 0;
scanf("%d", &day);
if (1 == day)
printf("星期1\n");
else if(2 == day)
printf("星期2\n");
else if(3 == day)
printf("星期3\n");
else ....
这时候我们就可以用switch 语句来替代
1. switch的语法结构
switch(整型表达式) //括号里面放的必须是整型
{
case 整形常量表达式:
语句;
case 整形常量表达式:
语句;
case 整形常量表达式:
语句;
......
}
其中 case 整个 为语句项
这边我们要特别注意的是:
① switch 括号( )里面放的是整型表达式
② case 后面放的是整型常量表达式,字符也行,因为字符储存的是ASCII词
2. switch中的case 决定入口
#include<stdio.h>
int main()
{
int day = 1;
scanf("%d", &day);
switch (day) //day表示整型
{
case 1: //1为整型常量
printf("星期一\n");
case 2:
printf("星期二\n");
case 3:
printf("星期三\n");
case 4:
printf("星期四\n");
case 5:
printf("星期五\n");
case 6:
printf("星期六\n");
case 7:
printf("星期日\n");
}
return 0;
}
输入 5 的结果:
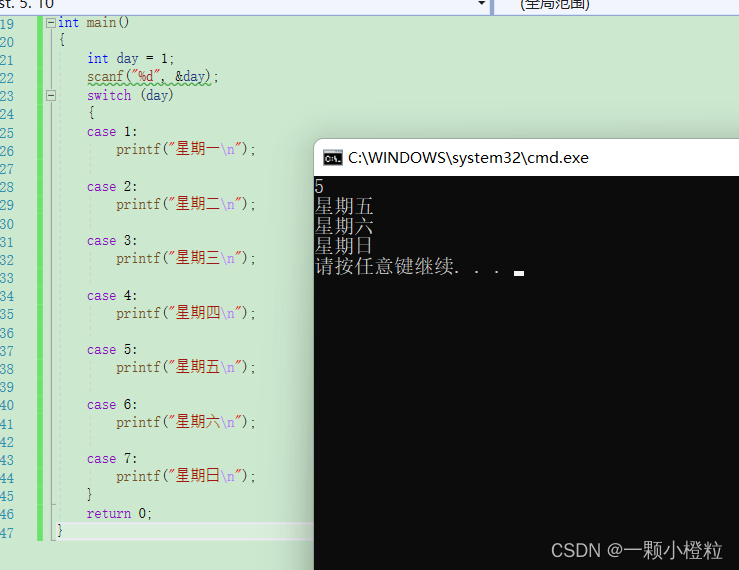
① case是决定入口的当我们输入5时他就打印case 5,case 6 …一直往下到结束,输入1也是同理从1开始一直往下
② 要想实现输入一个数就打印这个数对应的结果的话必须每一个语句项里语句上 break;
3. 在switch语句中的 break
#include<stdio.h>
int main()
{
int day = 1;
scanf("%d", &day);
switch (day)
{
case 1:
printf("星期一\n");
break;
case 2:
printf("星期二\n");
break;
case 3:
printf("星期三\n");
break;
case 4:
printf("星期四\n");
break;
case 5:
printf("星期五\n");
break;
case 6:
printf("星期六\n");
break;
case 7:
printf("星期日\n");
break;
}
return 0;
}
输入 5 的结果:
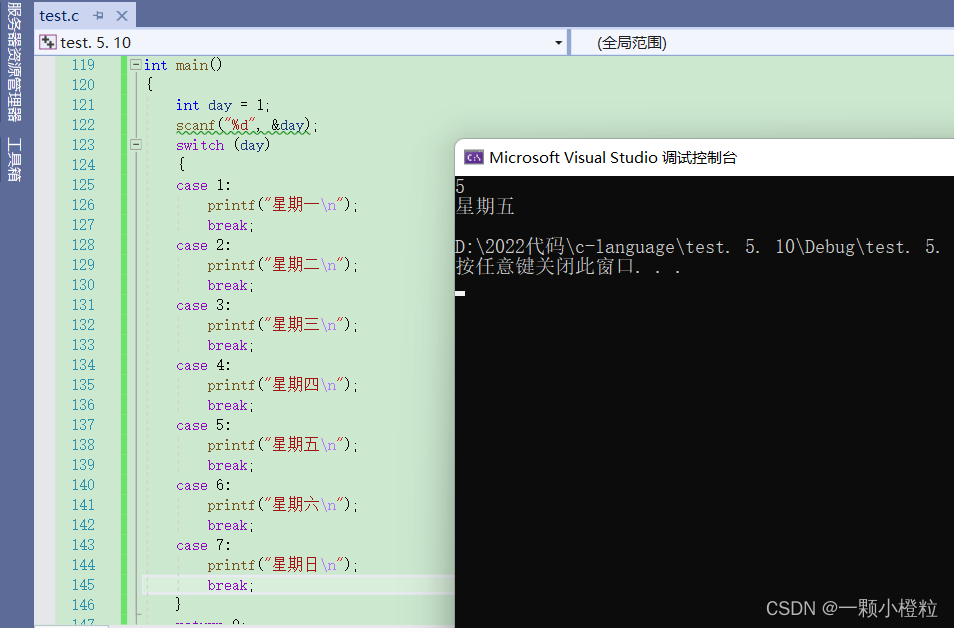
当程序运行遇到break就会直接跳出;所以berak有终止,跳出语句的效果
有时候我们的需求变了:
- 当输入 1 ~ 5,输出 工作日
- 当输入 6 ~ 7,输出 双休日
这个时候我们的代码就可以这样写了
#include<stdio.h>
int main()
{
int day = 1;
scanf("%d", &day);
switch (day)
{
case 1:
case 2:;
case 3:
case 4:
case 5:
printf("工作日\n");
break;
case 6:;
case 7:
printf("双休日\n");
break;
}
return 0;
}
输入1 打印的效果:
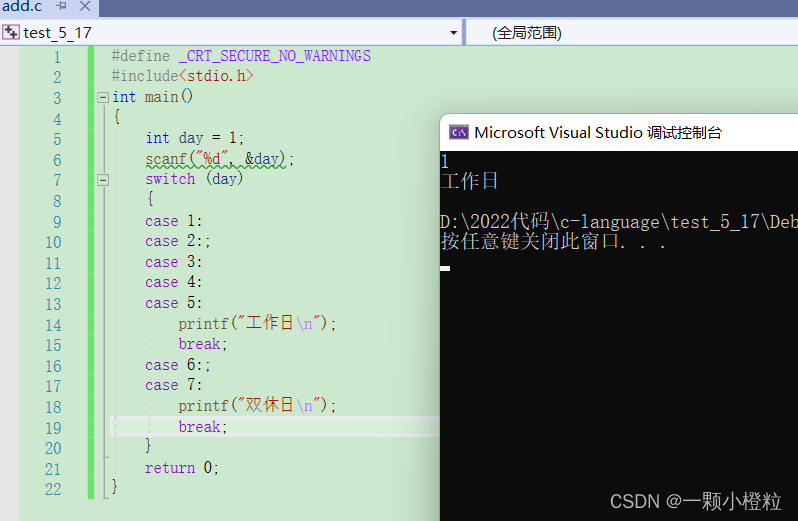
分析:输入1,他就会滑到 5 那边打印,然后跳出,同理其他也一样,但如果不在1~7的范围就会不打印
break语句 的实际效果是把语句列表划分为不同的分支部分。
编程好习惯
在最后一个 case 语句的后面加上一条 break语句。
(之所以这么写是可以避免出现在以前的最后一个 case 语句后面忘了添加 break语句)。
4. default 子句
如果表达的值与所有的case标签的值都不匹配怎么办?
其实也没什么,结构就是所有的语句都被跳过而已。
程序并不会终止,也不会报错,因为这种情况在C中并不认为是个错误。
但是,如果你并不想忽略不匹配所有标签的表达式的值时该怎么办呢?
你可以在语句列表中增加一条default子句,把下面的标签
default:
写在任何一个 case 标签可以出现的位置。
当 switch 表达式的值并不匹配所有 case 标签的值时,这个 default 子句后面的语句就会执行。
所以,每个switch语句中只能出现一条default子句。
但是它可以出现在语句列表的任何位置,而且语句流会像执行一个case标签一样执行default子句。
编程好习惯
在每个 switch 语句中都放一条default子句是个好习惯,甚至可以在后边再加一个 break 。
代码演示:
#include<stdio.h>
int main()
{
int day = 1;
scanf("%d", &day);
switch (day)
{
case 1:
case 2:;
case 3:
case 4:
case 5:
printf("工作日\n");
break;
case 6:;
case 7:
printf("双休日\n");
break;
//输入不匹配的数都会走到这打印
default:
printf("输入不匹配\n");
}
return 0;
}
输入 8 的结果:
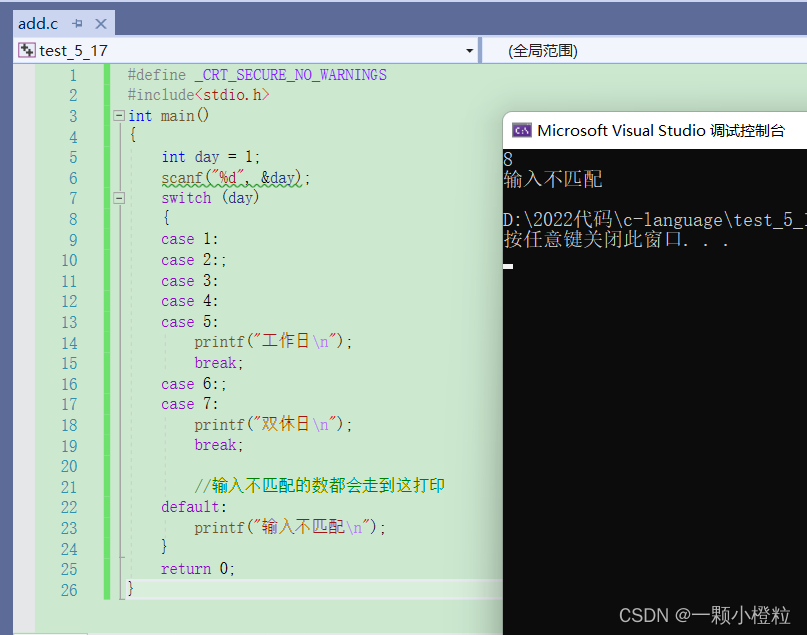
总结加分析:
① case语句的项只有到 7,而我们输入 8 以及 1~7 以外的数都是不匹配的,
② 这时就可以用 default 子句提醒一下,
③ 如果没加 default 的话,输入不匹配的数不会报错但不打印
5. 练习
int main()
{
int n = 1;
int m = 2;
switch (n)//n = 1进入
{
case 1:
m++; // 2 + 1 = 3,m = 3
case 2:
n++; //1 + 1 = 2 ,n = 2
case 3:
//switch允许嵌套使用
switch (n) //n = 2进入
{
case 1:
n++;
case 2:
m++; // 3 + 1 = 4
n++; // 2 + 1 = 3
break;
}
case 4:
m++; // 4 + 1 = 5
break;
default:
break;
}
printf("m = %d, n = %d\n", m, n);
return 0;
}
打印结果及分析:

从代码中我们可以看到switch是允许嵌套使用的
循环语句
我们生活有很多数要表示比如打印1~100,难道我们要一个个去定义输出吗,
显然很费劲,不可取;这时候就有了我们循环
循环语句有三种分别为:while 、 for 、do…while
一、while 循环
1. while 语句的语法结构和循环执行流程图
语法结构:
//while 语法结构
while(表达式)
循环语句;
循环语句跟 if 语句一样当我们多条语句时,必须加大括号
建议: while、for 后面跟一个大括号 { }
while 循环执行流程图
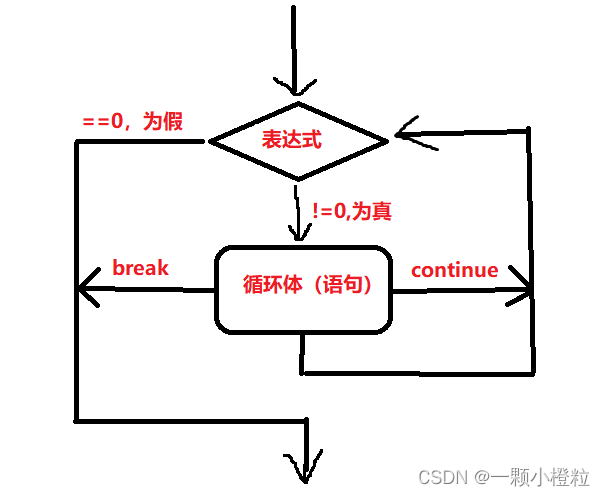
画的很丑,家人们见谅哈
表达式为 0 表示假 直接跳出不打印,
不为 0 表示真 就执行循环语句,然后循环
比如我们打印1~100的所有数
#include<stdio.h>
int main()
{
int i = 1;
while (i <= 100)//表达式不为0判断为真进入循环
{
printf("%d ", i);
i++; //打印的每一项都加1,
//加完的值返回到表达式继续循环打印直达100
}
return 0;
}
2. while语句中的break
上面说了分支语句中switch中的 break,那我们看看用在循环这个转向语句break是怎样的呢,我们来猜猜下面这个代码打印结果是什么
int main()
{
int i = 1;
while (i <= 10)
{
if (i == 5)
break;
printf("%d ", i);
i++;
}
return 0;
}
打印1 2 3 4 6 7 8 9 10 或者 1 2 3 4 5 6 7 8 9 10 吗?
我们一起来看一下结果吧
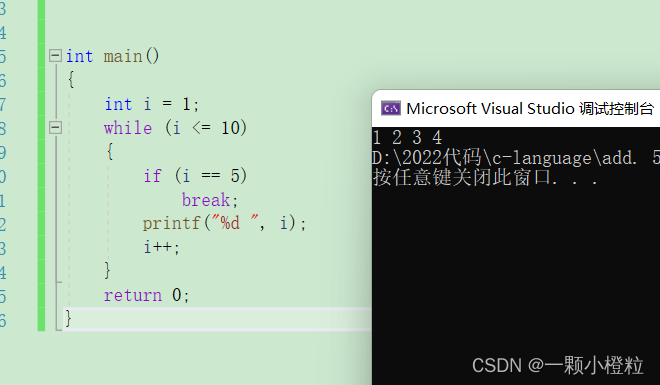
(1)为什么打印1 2 3 4 就不打印了呢
因为当运行时遇到break时就会跳过后面所有语句
(2)总结:
break 在 while 循环中的作用:
其实在循环中只要遇到 break,就停止后期的所有的循环,直接终止循环。
所以:while 中的 break 是用于永久终止循环的。
3. while 语句中的 continue
continue用在while循环又是怎样的呢?
我们在来看两个代码
int main()
{
int i = 1;
while (i <= 10)
{
if (i == 5)
continue;
printf("%d ",i);
i++;
}
return 0;
}
打印结果:
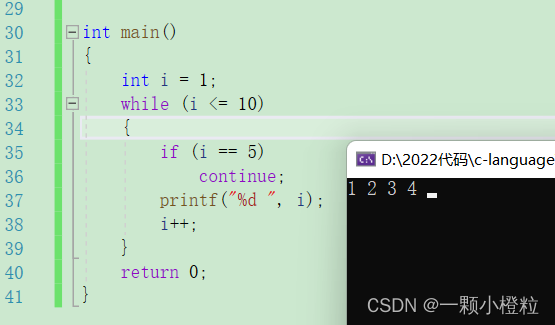
(1)打印结果:1 ~ 4后死循环
(2)分析:
① 我们可以看到 4 后面光标一直在闪烁,因为当我们打印到 5 时遇到continue,他就会跳过后面语句然后返回循环表达式判断,
② 此时 i == 5,返回值也是5,5<10进入循环遇见continue,然后返回循环判断,也是5,反反复复,所以死循环
(3)明白了这个,我们把 i++ 放在 if 判断前面会怎样,看代码:
int main()
{
int i = 1;
while (i <= 10)
{
i++;
if (i == 5)
continue;
printf("%d ", i);
}
return 0;
}
打印结果:
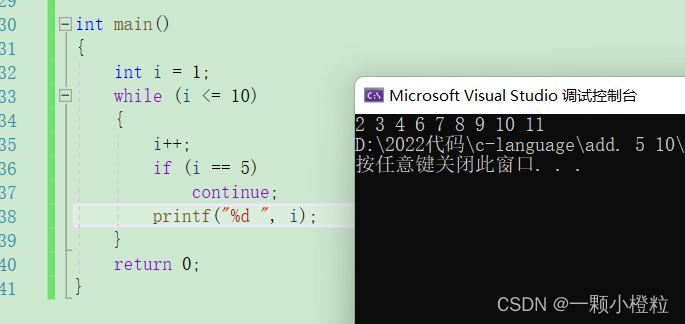
(1)这个结果大家想到了吗?为什么是 2~11 没有 5 ?
(2)分析:
因为 i = 1,进入循环遇到 i++,就为2,然后一直打印到 5 的时候遇到 continue,跳过后面语句来到循环判断,5<10为真进入循环遇到 i++ 变成 6 就不会遇到 continue,就一直打印到 11啦
(3)总结:
continue在while循环中的作用就是:
continue是用于终止本次循环的,也就是本次循环中continue后边的代码不会再执行,
而是直接跳转到while语句的判断部分。进行下一次循环的入口判断。
getchar 的特性
我们从代码中来认识一下两个新的函数;
getchar(获取一个字符)和 putchar(打印一个字符)
重点认识getchar(获取一个字符) putchar看一下我们就明白
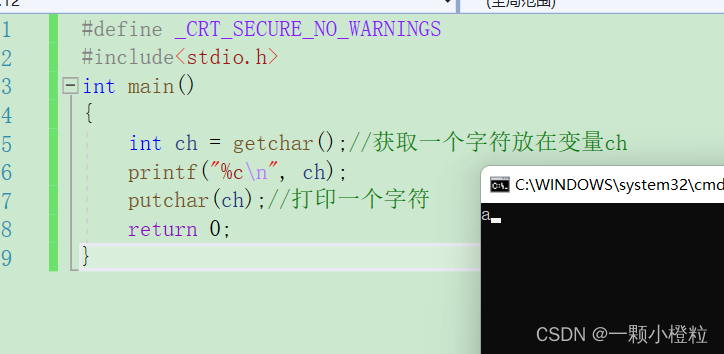
1.我们来了解一下gechar的特性,代码演示:
#include<stdio.h>
int main()
{
int ch = getchar();//获取一个字符放在变量ch
printf("%c\n", ch);
putchar(ch);//打印一个字符
return 0;
}
(1)为什么我们这边是 int 类型定义而不是char类型定义呢?
① 因为getchar是返回类型是 int,
② 我们用int类型既可以接收整型也可以接收字符,因为字符他对应的是ASCII码词存储的
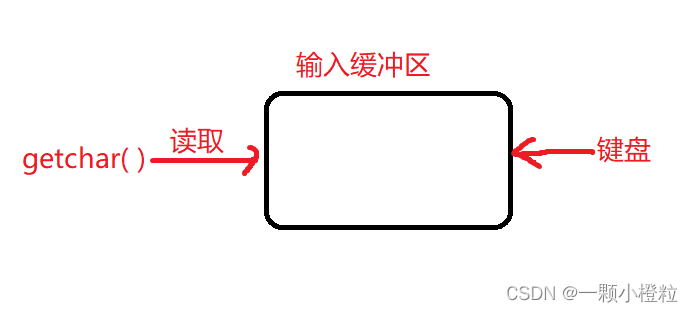
(2)我们来看一下程序开始运行流程图,
第一步:运行
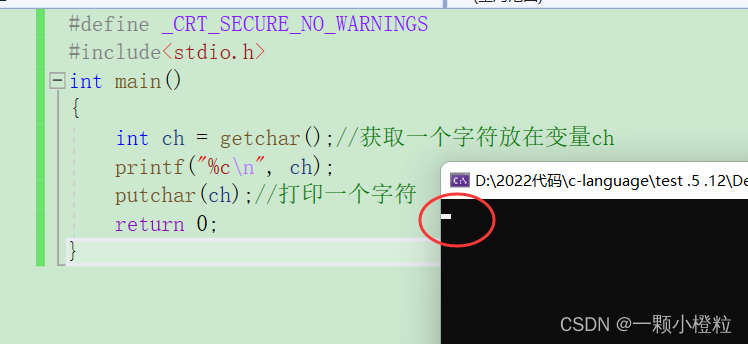
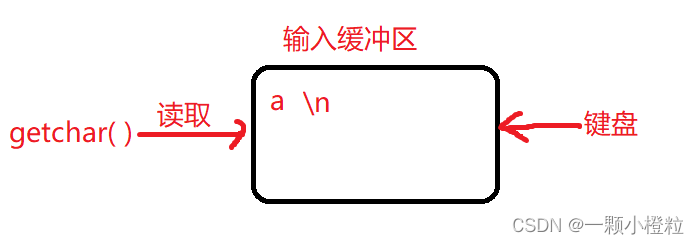
在运行出来的黑幕中,光标会一直闪 等待我们输入,此时 输入缓冲区 没有任何东西,等待我们键盘敲字符给他
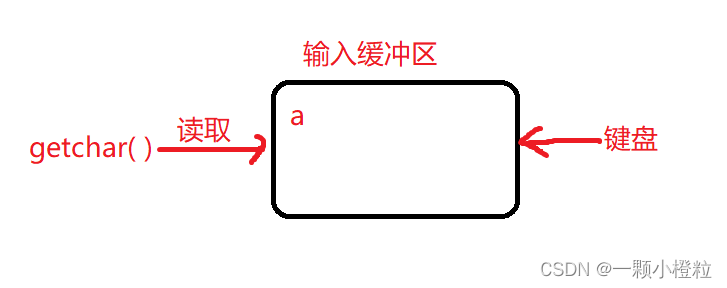
第二步:我们敲一个字符 a 给输入缓冲区
① 可以看到黑幕我们敲完 a ,此时输入缓冲区就有了字符 a ,
② 但黑幕还没有打印其他两个 a,因为我们还没有敲回车确认
第三步:我们敲回车确认,黑幕和输入缓冲区会发生什么变化,一起看一下吧
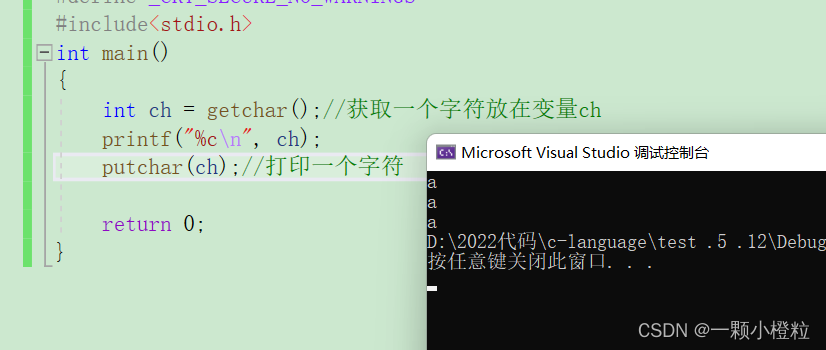
此时黑幕打印了两个a,光标自动换行到最下面,为什么会这样呢?
因为我们在敲回车键的时候,输入缓冲区会多一个 \n 换行字符,
而getchar只读取一个字符也就是a,\n 没办法读取,所以黑幕就自动换行了
明白了上面的getchar的特性,那我们就可以利用getchar特性结合循环来清理缓冲区
2. getchar 结合while循环清理缓冲区
#include<stdio.h>
int main()
{
int ch = 0;
while ((ch = getchar()) != EOF)//读取的字符不等于错误或者文件结束
{
putchar(ch);
}
return 0;
}
(1)gechar 读取的是一个字符,而while循环可以很好结合,让代码一直读取,直到文件结束或者错误
(2)EOF的本质是 (- 1),在 getchar 函数中表示文件结束或错误

(3)这边给上可以查所有函数以及关键字的官方网站
链接: www.cplusplus.com
里面有函数、关键字介绍及使用
我这边演示一个:getchar 函数的查法
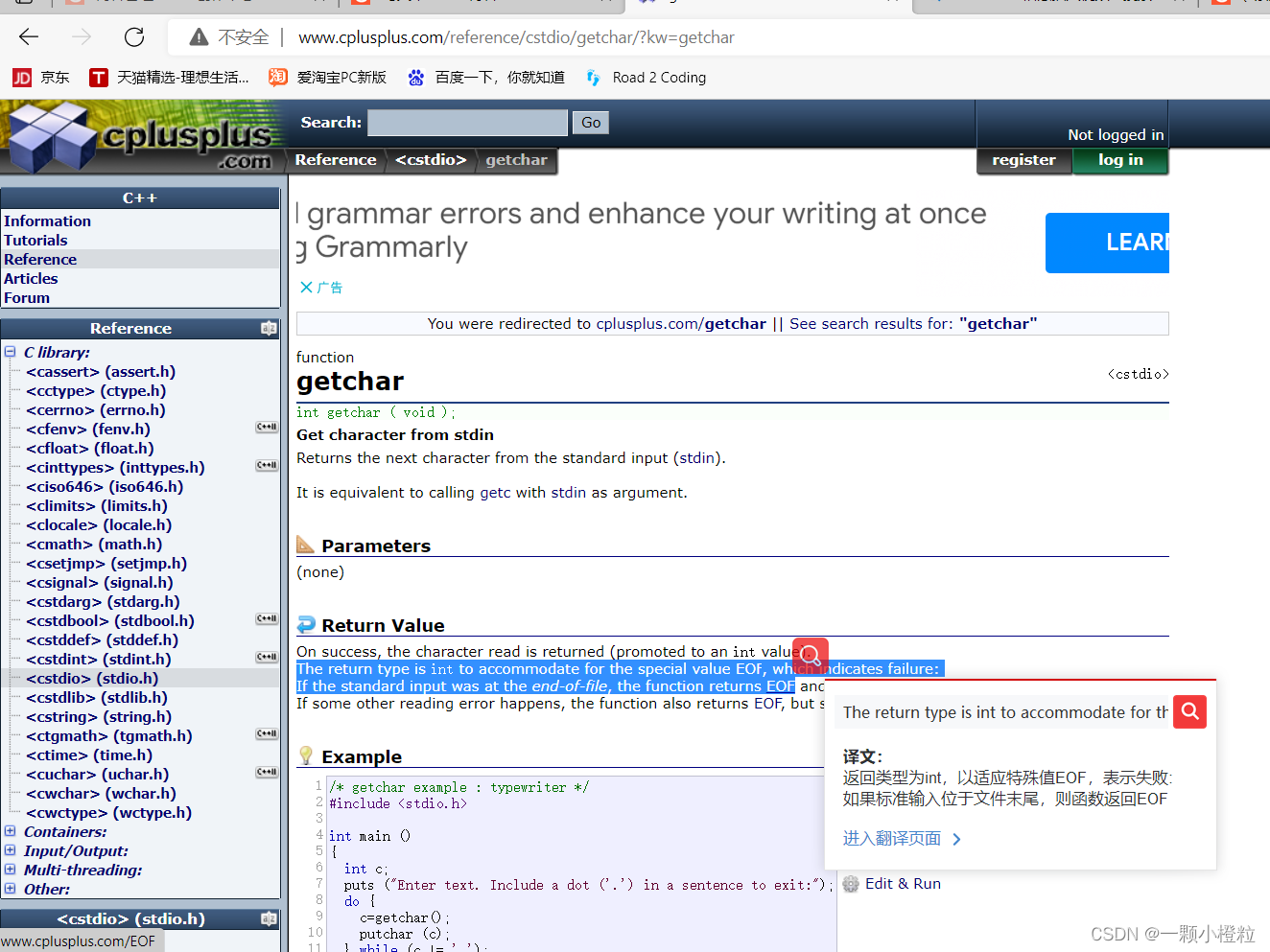
打开后链接搜素完后界面是这样的里面有函数的介绍和使用头文件等等,如果你跟我一样看不懂英文,建议电脑下载个有道词典,点哪翻译哪里
3. 清理缓冲区的使用
那我们明白了这个清理缓冲区,那它有什么用呢?
有些地方我们还真的必须用到它,
举个例子:我们输入一个字符串密码,然后再确认密码(Y/N),在打印对应的内容
#include<stdio.h>
int main()
{
char password[20] = { 0 };//给个空间为20的数组
printf("请输入密码:>");
scanf("%s", password); //数组名本身就是地址所以不用取地址
printf("请确认密码(Y/N):>");
int ch = getchar();//读取确认字符(Y/N)
if ('Y' == ch)
{
printf("Yes");
}
else
{
printf("No");
}
return 0;
}
看上面代码逻辑是不是没有错,我们来看看打印的结果是什么:
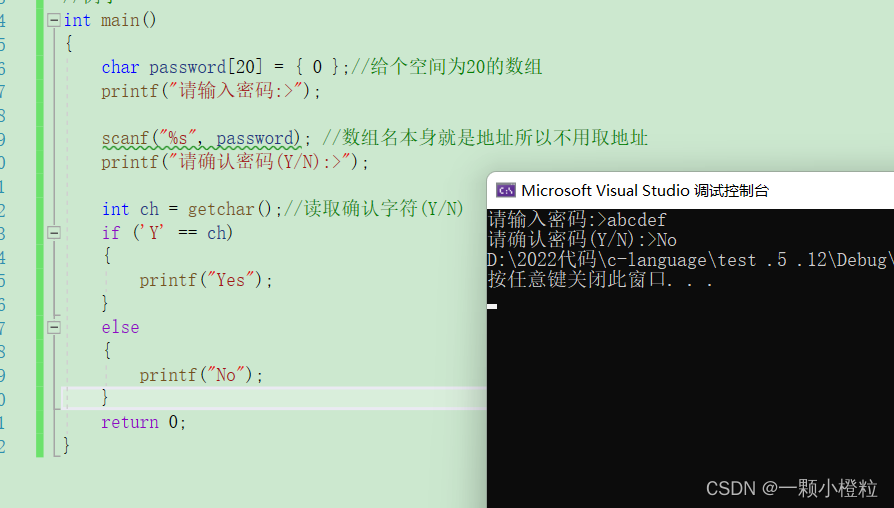
我们输入abcder这串密码,还没等我们确认他就已经自己打印No了
为什么呢?
(1)因为scanf 只获取了abcdef,而我们键盘要敲的时候要敲回车确认,
(2)此时输入缓冲区就多了个 \n ,所以 \n ,被getchar 读取了,
(3)导致 \n 不等于 Y,就直接打印No,
那聪明的你们肯定想到了确认密码前加一个getchar读取掉 \n 不就好了
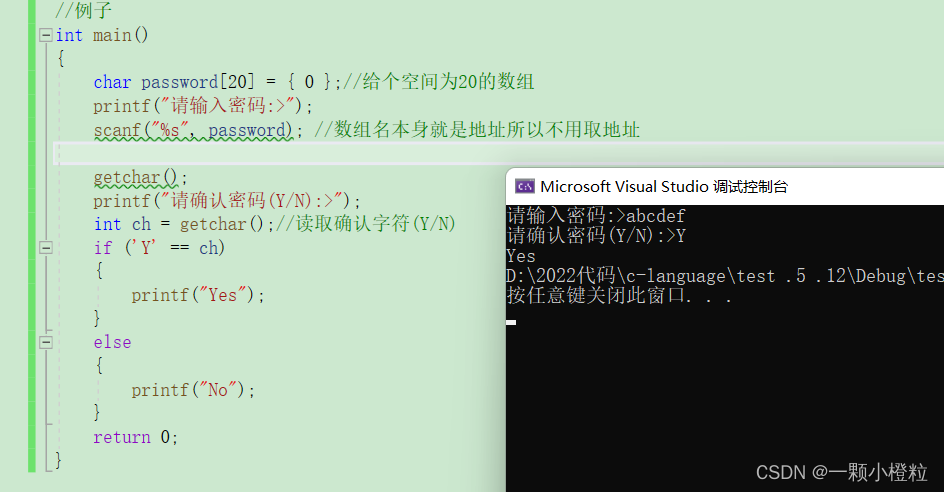
是可以了但我们要是输入这样的密码呢,比如 abc def,在密码中间给他加个空格它还能用了吗?
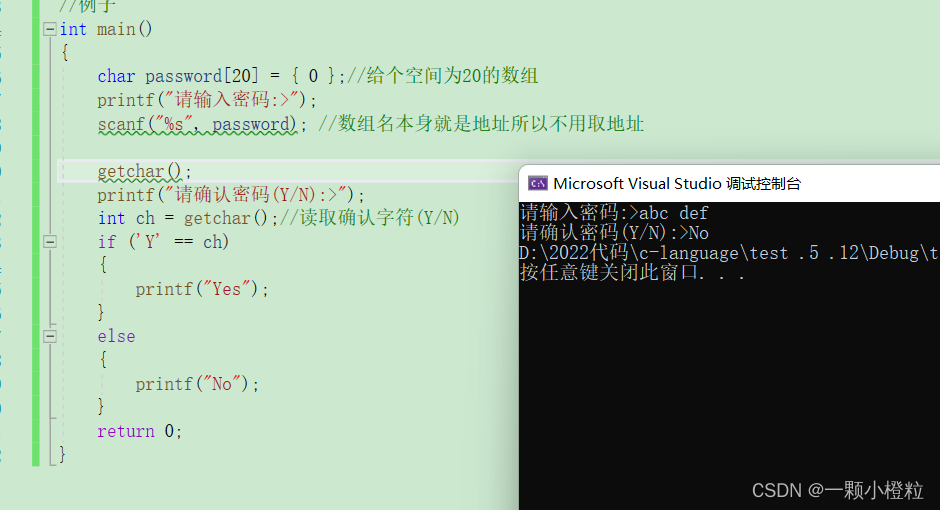
看瞬间不能用了,我给大家分析分析我们就明白了,
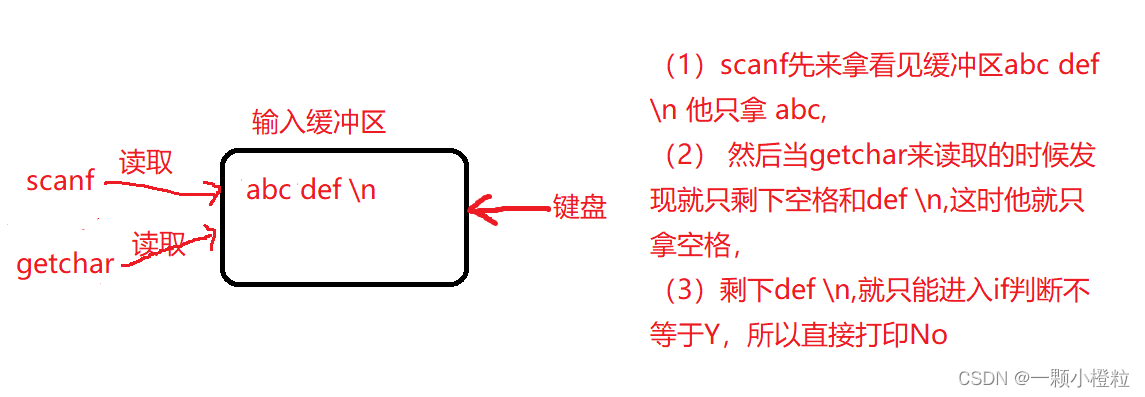
明白了这个那我们有什么办法让剩下的 def \n 被读取掉,
这个时候我们的 getchar 结合 while 就可以实现了,看代码:
int main()
{
char password[20] = { 0 };//给个空间为20的数组
printf("请输入密码:>");
scanf("%s", password); //数组名本身就是地址所以不用取地址
int i = 0;
while ((i = getchar()) != '\n')//一直读取直到读取的字符不是'\n'
{ //因为我们键盘按下回车键的时候就是‘\n’
;
}
printf("请确认密码(Y/N):>");
int ch = getchar();//读取确认字符(Y/N)
if ('Y' == ch)
{
printf("Yes");
}
else
{
printf("No");
}
return 0;
}
4. 打印数字字符(内含ASCII码词表)
看代码前我先献上ASCII码词表:
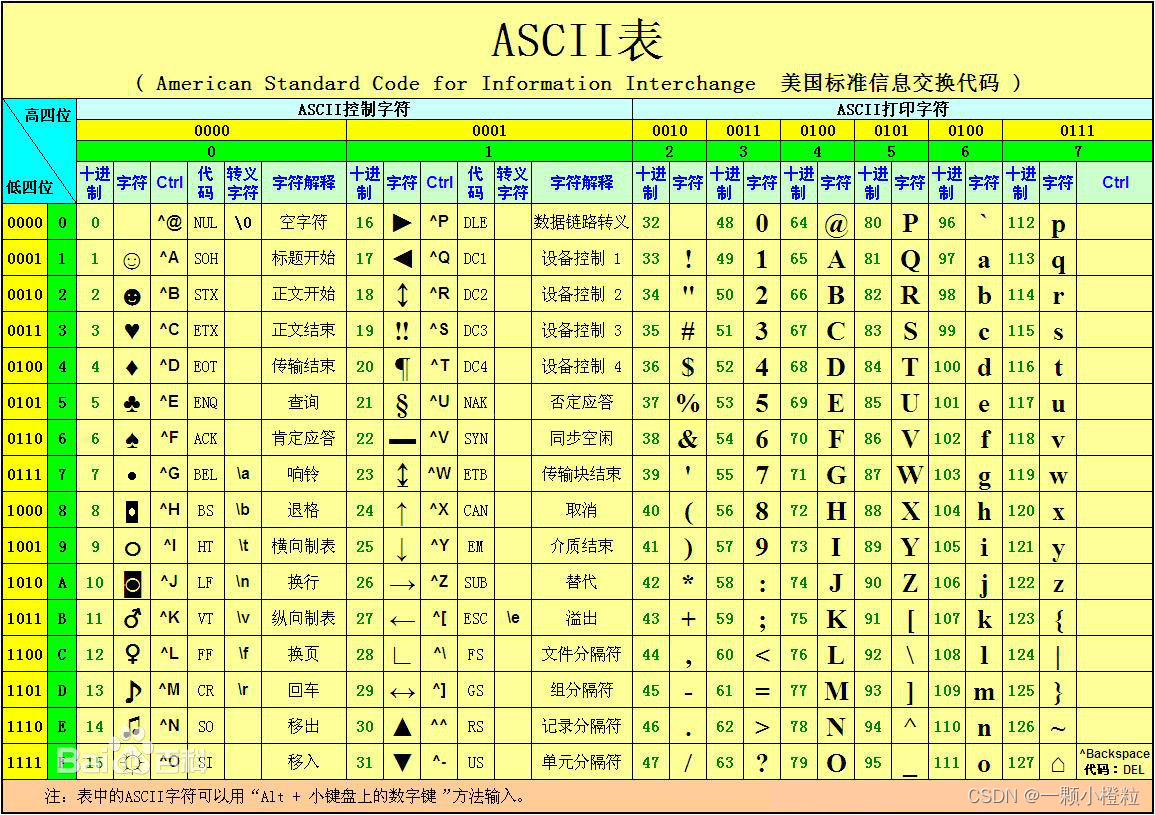
ok 有了这个表我相信我们看下面这个代码的时候会轻松许多
我们一起来分析一下下面这个代码在说啥吧:
#include <stdio.h>
int main()
{
char ch = '\0';
while ((ch = getchar()) != EOF)
{
if (ch < '0' || ch > '9')//只要一个为真就执行continue
continue; //也就是说我们要打印的话必须是字符0<ch<9这个范围
//因为这个范围为假可以跳开continue,打印
putchar(ch);
}
return 0;
}
打印结果:

(1)如果为真遇到 continue 然后就会跳过后面语句直接来到循环重新等待输入,我们这边输入 a,而 ‘a’ > ‘9’ 为真所以就不打印返回循环判断
(2)所以我们要打印只能输入在 ‘0’ <ch< ‘9’ 这个范围的字符,才能打印
(3)总结:这个代码只打印数字字符,跳过其他字符的
二 、for 循环
我们已经知道了while循环,但是我们为什么还要一个for循环呢?
for 循环是我们用的最多的循环,那他有什么特殊之处呢?
带着这个疑问我们回顾一下上面的while循环结构
#include<stdio.h>
int main()
{
int i = 1; //初始化,从1进入循环
while (i <= 10)//判断
{
printf("%d ", i);
i++;//调整
}
return 0;
}
初始化、判断和调整 是我们循环中非常重要的部分
我们可以看到while循环这三个部分隔的距离有点远
我们在来看一下 for 循环是怎么写的,两个代码对比一下
#include <stdio.h>
int main()
{
int i = 0;
//for(i=1/*初始化*/; i<=10/*判断部分*/; i++/*调整部分*/)
for(i=1; i<=10; i++)
{
printf("%d ", i);
}
return 0;
}
可以看到 for循环初始化、判断和调整三个部分放在了一起,而while三个部分放太远,对比之下 for循环就显得更好的去管控这三个部分,使用起来就更加方便了
1. for 语法结构和执行流程图
语法结构:
for(初始化部分;条件判断部分;调整部分)
{
循环语句;
}
执行流程图:
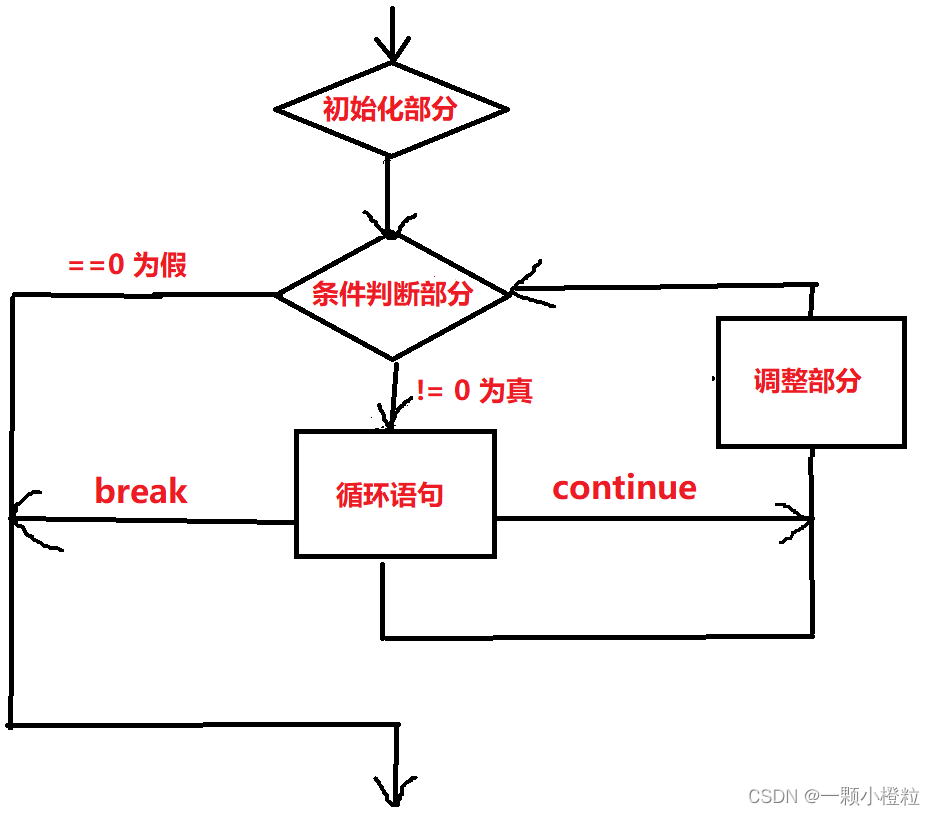
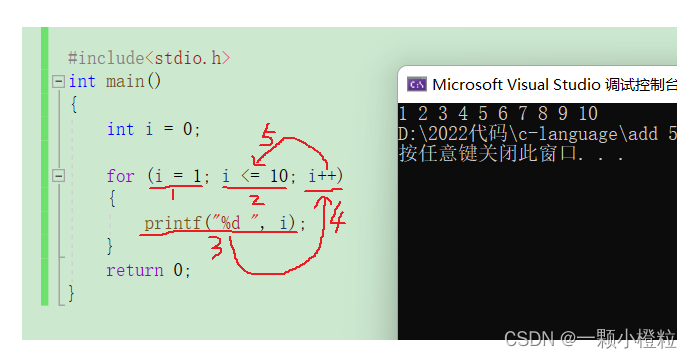
从代码流程中我们更加形象的了解到 for 循环的走向
刚开始是1-5,后面循环起来就是 2-5 直至结束
2. for 循环中的break和continue
我们发现在for循环中也可以出现 break 和 continue,他们的意义和在while循环中是一样的。
但因为他们语法结构是有区别所以还是有些差异:
(1)第一个 for 循环中的 break
#include<stdio.h>
int main()
{
int i = 0;
for (i = 1; i <= 10; i++)
{
if(i == 5)
break;
printf("%d ", i);
}
return 0;
}
打印结果:1 2 3 4,
分析:原因是当 i == 5 时遇到 break 就直接终止循环了,
所以不跳去 i++调整部分;所以就打印 1~4
(2)第二个for循环中的continue
我们把上面的代码的 break换成continue
看看会是怎样的结果
#include<stdio.h>
int main()
{
int i = 0;
for (i = 1; i <= 10; i++)
{
if (i == 5)
continue;
printf("%d ", i);
}
return 0;
}
打印结果:1 2 3 4 6 7 8 9 10
为什么没有 1~10没有 5 呢?怎么跟while循环不一样呢?
分析:因为当我们 i ==5 时,遇到continue它会跳过后面语句,来到调整部分也就是 i++ 那里,然后 5+1= 6 嘛就打印了直到打印到10
总结:while循环他遇到continue是直接来到判断部分,
而 for循环是来到调整部分,所以我们要区别开来
3. for语句的循环控制变量
建议:
- 不可在for 循环体内修改循环变量,防止 for 循环失去控制。
- 建议for语句的循环控制变量的取值采用“前闭后开区间”写法。
(1)不可在for 循环体内修改循环变量,防止 for 循环失去控制。
我们看一个在for循环体内修改变量会发生什么结果
#include <stdio.h>
int main()
{
int i = 0;
for (i = 1; i <= 10; i++)
{
printf("%d ", i);
i = 9;//把 i改成 9
}
return 0;
}
打印结果: 死循环10
分析:因为 i =1,打印1,下来 i 被改变成 9,再来到调整部分 i++,变成10
10 == 10满足判断条件,打印10,每次进入循环的值都被改变成9,
然后一直循环所以打印结果是 死循环10
如果把 i 的值改成不满足条件判断的话他就打印 1,因为只有初始化 1才满足条件打印
(2)建议for语句的循环控制变量的取值采用“前闭后开区间”写法
这个只是建议,还是根据自己习惯即可,不唯一,
我给个例子你们就明白什么叫“前闭后开区间”
比如我要打印数组元素:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
//下标 0~9
int i = 0;
for (i = 0; i < 10; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
“前闭后开区间”,说的是判断部分写成 i < 10,给我们感觉就是打印10个元素;
当然你也可以写成 i <= 9;一样的结果但 9 的话可能会给你错觉打印 9 个元素
当然这个“前闭后开区间”写法不是每一个都这么写
比如我要打印 100 到 200之间的数包含200,
#include <stdio.h>
int main()
{
int i = 0;
for (i = 100; i <= 200;i++)
{
printf("%d ", i);
}
return 0;
}
你要写成 i < 201,也对,但看起来怪怪的
总结:这边只是建议怎么去写还是根据自己来怎么舒服怎么写
4.一些特殊的for循环写法
(1)省略判断部分的后果
#include <stdio.h>
int main()
{
for(;;)
{
printf("hehe\n");
}
//for循环中的初始化部分,判断部分,调整部分是可以省略的,
//但是不建议初学时省略,容易导致问题。
//如果我们只省略判断部分会使判断恒成立,死循环
(2)省略初始化部分的后果(双层嵌套for循环)
双层嵌套for循环,它的打印的结果是什么,它又是怎么循环的?
我们来看一下代码:
//双层嵌套for循环
#include <stdio.h>
int main()
{
int i = 0;
int j = 0;
//这里打印多少个hehe?
for (i = 0; i < 3; i++)
{
for (j = 0; j < 3; j++)
{
printf("hehe\n");
}
}
return 0;
}
打印结果:
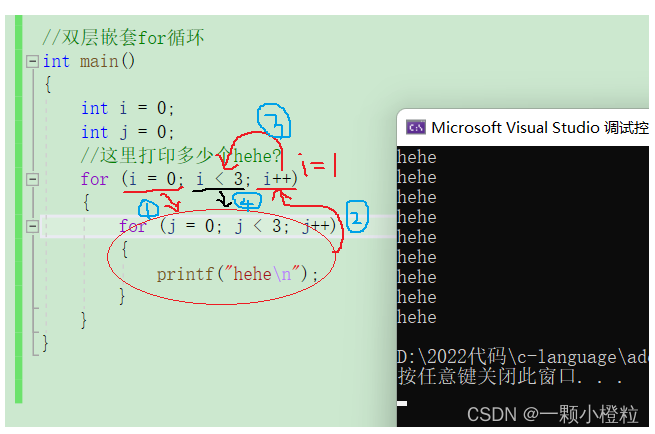
我们仔细数的话是打印结果是 9 个 hehe
▲ 上面代码过程分析:
① 当 i = 0 时满足条件进入第二层循环 j = 0,打印一个hehe,然后再返回到 j++,此时 j = 1,满足条件,打印一个hehe,再返回到 j++,此时 j = 2;满足条件再打印hehe,到这三个hehe了 ,然后再返回到 j++,此时 j = 3,不满足条件跳出,
② 来到第一层循环 i = 0 在经历一轮循环后,回到第一层的 i++,此时 i = 1;但还是以初始值 i=0 ,进入第二层循环以 j=0 开始打印3个hehe,
③ 然后又不满足条件 ,跳出来时 i =1经历了一轮循环,再返回到 i++,变成 2,再进入也是以初始值 i = 0进入第二层循环 j=0 开始又一轮打印3个 hehe,再返回到 i++时,i 变成 3 不满足条件退出循环
总结:双层for循环第一层循环一次,第二层全部循环一次(外层循环一次,内层for循环全部执行完成再进行外层一次循环)
当我们明白了双层嵌套for循环,如果我们把他的初始化部分省略掉,他会打印什么?
看图:
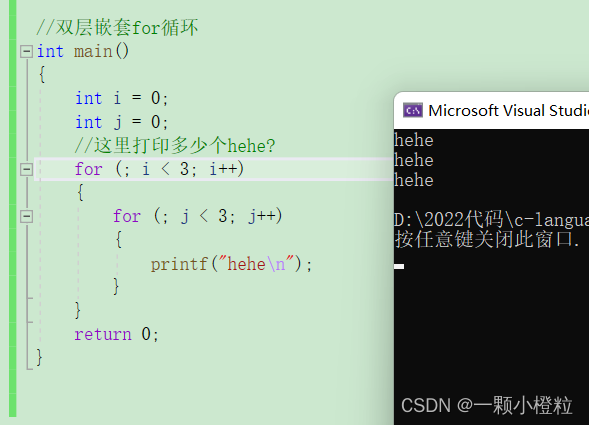
他就打印三个hehe,为什么呢?
分析:因为当 i = 0,进入第二层循环,打印3个hehe后,此时 j = 3不满足第二层判断条件,返回第一层发现 i 没有初始化,所以 i 的值是 j = 3时跳出来的值,为 3 不满足条件不打印,所以只打印3个 hehe
总结:不要随意去省略 for 循环的结构,容易出问题
(3)C99 和 C++ 才支持的写法
#include <stdio.h>
int main()
{
//把 int i = 1写入for循环里,有些 C语言编译器不支持
//因为它是C99才支持的语法,当然 C++就支持
for (int i = 1; i <= 10; i++)
{
printf("%d ", i);
}
return 0;
}
(4)使用多余一个变量控制循环
//使用多余一个变量控制循环
//允许多个变量控制循环
#include <stdio.h>
int main()
{
int x, y;
for (x = 0, y = 0; x < 2 && y < 5; ++x, y++)
{
//只有0和 1满足条件所以打印 2个hehe
printf("hehe\n");//打印 2个hehe
}
return 0;
}
5. 一道笔试题
//请问循环要循环多少次?
#include <stdio.h>
int main()
{
int i = 0;
int k = 0;
for(i =0,k=0; k=0; i++,k++)
k++;
return 0;
}
结果为不打印
分析:
因为判断部分 k = 0 是赋值而不是判断,所以不打印
如果把 k = 0 改成 k == 0;然后加打印的话就打印一次打印结果为0
总结:我们要成为一名合格的程序员就要时刻注意一个 = 和两个 == 的区别,高度警惕好吧
三、do…while 循环
do…while 循环就是不管三七二十一,一上来就执行
所以循环至少执行一次,使用的场景有限,所以不是经常使用。
1. do…while循环的语法结构和流程图
语法结构
do
循环语句;
while(表达式);
代码演示:
//用 do...while循环打印 1~10
#include<stdio.h>
int main()
{
int i = 1;
do
{
printf("%d ", i);
i++;
}
while (i <= 10);
return 0;
}
执行流程图
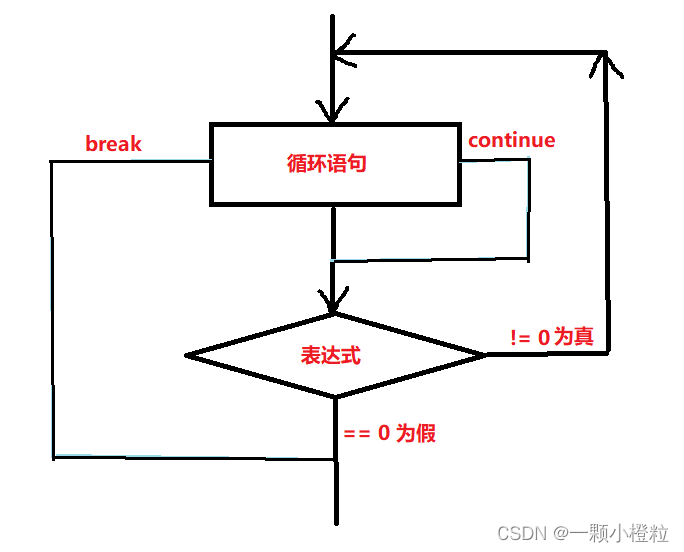
2. do…while 循环中的 break 和 continue
(1)do…while 循环中的 break
#include<stdio.h>
int main()
{
int i = 1;
do
{
if (i == 5)
break;
printf("%d ", i);
i++;
} while (i <= 10);
return 0;
}
打印结果:1 2 3 4
分析:当 i == 5 时 ,遇到 break 就终止循环了,所以只打印 1~4 ,
(2)do…while 循环中的 continue
#include<stdio.h>
int main()
{
int i = 1;
do
{
i++;
if (i == 5)
continue;
printf("%d ", i);
} while (i <= 10);
return 0;
}
打印结果: 2 3 4 6 7 8 9 10 11
分析:当 i == 5时,遇到continue,continue就跳过后面语句,来到while判断表达式 i <= 10这边;
5满足条件然后返回到 i++ 变成 6 不满足 if 判断条件,打印6,反复此过程直到打印到11结束。
总结:do…while 循环的 break 和 continue 跟在 while 循环中一样
练习
- 计算 n的阶乘。
- 计算 1!+2!+3!+……+10!
- 在一个有序数组中查找具体的某个数字n。(讲解二分查找)
- 编写代码,演示多个字符从两端移动,向中间汇聚。
- 编写代码实现,模拟用户登录情景,并且只能登录三次。(只允许输入三次密码,如果密码正确则提示登录成功,如果三次均输入错误,则退出程序。
1. 计算 n的阶乘
思路:我们先产生1 ~ n 的值,然后再用1乘以你 1 ~ n这个范围的值再输出这个结果
#include<stdio.h>
//计算 n 的阶乘
//1*2*3...*n
int main()
{
int i = 1;
int n = 0;
int ret = 1;
scanf("%d", &n);
for (i = 1; i <= n; i++)
{
ret = ret * i;//1 * i(在循环中不断增加的)
}
printf("%d\n", ret);
return 0;
}
这个代码是不考虑溢出的结果,比如32的阶乘的值就大于int的空间大小了
2. △计算 1!+2!+3!+……+10!
//代码1
//计算 1!+ 2!+ 3!+ …… + 10!
//计算 1 到 10的阶乘相加
#include<stdio.h>
int main()
{
int i = 1;
int n = 0;
int ret = 1;//初始化不能为0,不然内层循环语句
int sum = 0;
for (n = 1; n <= 10; n++)
{
ret = 1; //初始化1,防止内层循环累积效果
for (i = 1; i <= n; i++)
{
ret = ret * i;//每一个数的阶乘
}
sum = sum + ret;//把每一个数的阶乘加起来放在sum中
}
printf("%d\n", sum);
return 0;
}
分析:我外层循环一次i = 1进来内层循环,打印1的阶乘,然后放在ret中,
外层循环一次 i = 2 进来,打印 2 的阶乘放在ret中,依次内外层循环
然后 ret 相加的值放在sum中,最后 ret 必须初始化否则内层循环会有累积效果
这边我们不建议用双层或多层for循环写法,因为多层for循环会导致代码执行效率低,
所以我们这题也可以用一层for循环解决,看代码2
//代码2
#include<stdio.h>
int main()
{
int n = 0;
int ret = 1;//初始化不能为0,下面循环体的表达式就会都是0
//0乘以任何数都是0嘛
int sum = 0;
for (n = 1; n <= 3; n++)
{
ret = ret * n;//每一个数的阶乘
sum = sum + ret;//表达式右边sum会储存上一个数的阶乘 + ret是新的阶乘,这个表达式随循环更新
//把循环更新的每一个阶乘全部相加的结果放在左边的sum
}
printf("%d\n", sum);
return 0;
}
总结:经过这两个代码我从监控中得出了一个结果是:
for循环进行一次循环结束后在进入下一次循环时,它会保留上一次循环的值
3.在一个有序数组中查找具体的某个数字n(讲解二分查找)
//解决方法1:遍历所有数组元素查找
#include<stdio.h>
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7 ,8, 9, 10 };
int k = 7;//要找的元素值 7
int sz = sizeof(arr) / sizeof(arr[0]);//数组元素个数
int i = 0;
for (i = 0; i < sz; i++)
{
//数组下标等于我要找的元素时就找到了
if (arr[i] == k )
{
printf("找到了,下标是:%d\n",i);
break;
}
// i == sz;说明遍历数组元素一直i++,表明还没找到
if (i == sz)
{
printf("找不到\n");
}
}
return 0;
}
解决方法1,遍历所有数组元素查找,但有个缺点是效率低;
我们接下来再讲一个高效率的解决方法:折半查找法(二分查找)
比如我猜一双鞋的价格,你跟我说不超过300,
我猜150,你说小了,那我就猜150到300的中间数225,
你说大了,那我就猜225到300的中间数 262 …
我们每次这样猜,猜数值范围的一半,是不是大大减少了查找次数提高了效率,这就是二分查找法
上面口头表达很容易,但我们代码是怎么去实现这个二分查找法的
图示:
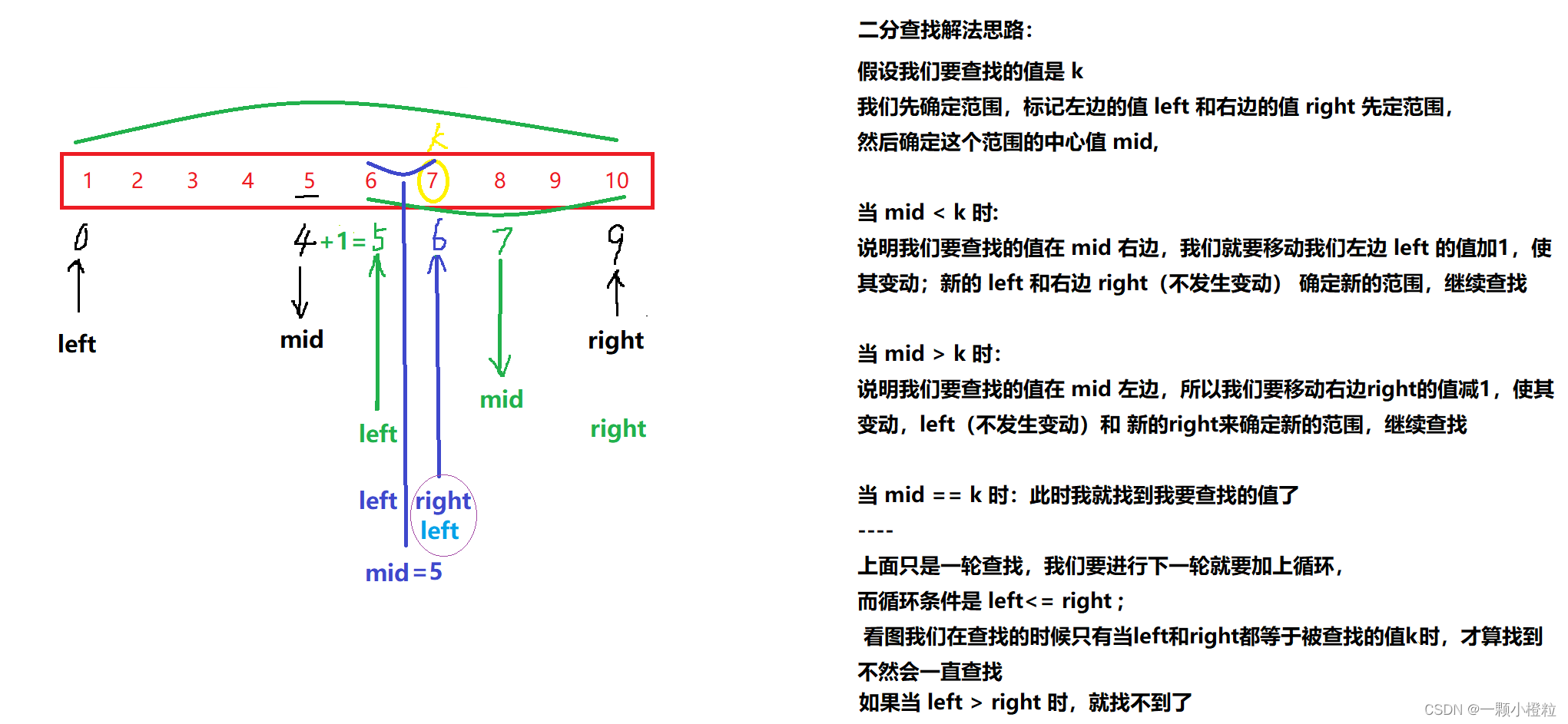
这边说一下为什么最后查找时 5 和 6 的中间值是 5,因为我们求的是整型;
他中间值本来是5.5也会成 5
有了二分查找的思路,那我们一起按照这个思路编一个代码把这题解了
吧
//二分查找法
#include<stdio.h>
int main()
{
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int k = 7;
int sz = sizeof(arr) / sizeof(arr[0]);//求元素个数
int left = 0;
int right = sz - 1; //数组是访问下标下标从0开始所以最右边得减1对应最右边元素的值
//比如最右边元素 10,下标就是 10—1 = 9
while (left <= right)
{
//int mid = (left + right) / 2; //求中间值方法1,不完美因为(left+right)的值有可能溢出,溢出中间值就不准确了
//求值值方法2,可以避免溢出情况,下面有图示
int mid = left + (right - left) / 2;
if (arr[mid] < k)
{
left = mid + 1;
}
else if (arr[mid] > k)
{
right = mid - 1;
}
else
{
printf("找到了下标是:%d\n", mid);
break;
}
}
if (left > right)//提醒找不到
{
printf("找不到");
}
return 0;
}
上面就是我们按照二分查找思路的代码演示,
要注意的是,我们查找的是有序数组,
我们的所需要的中间值mid和左右两边left、right 的都是访问数组下标
上面还补充了一点:我们求 mid 中间值(平均值)的方法会溢出,我们下面
给出另一种求法可以防止溢出,看图示:
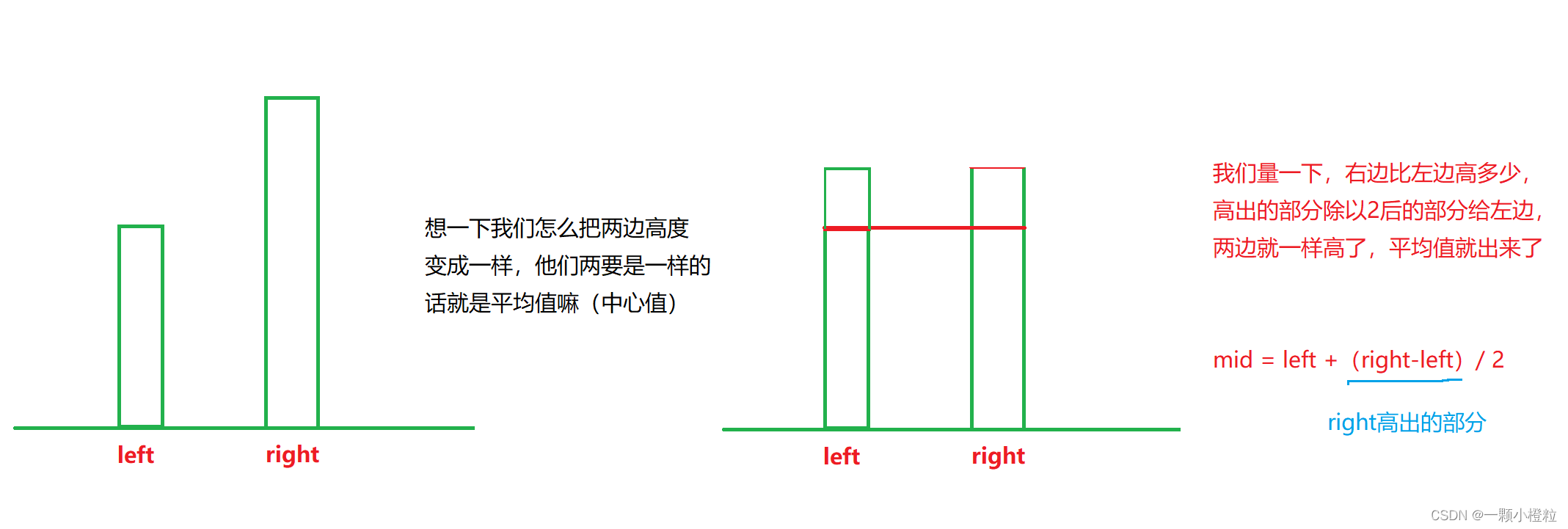
当我们 right 的值不会溢出,整个求法就更不会溢出
二分查找法总结:
我们所查找的值必须的有序的;
二分查找我们每一次查找就少一半,效率可谓是非常高
4. 编写代码,演示多个字符从两端移动,向中间汇聚。
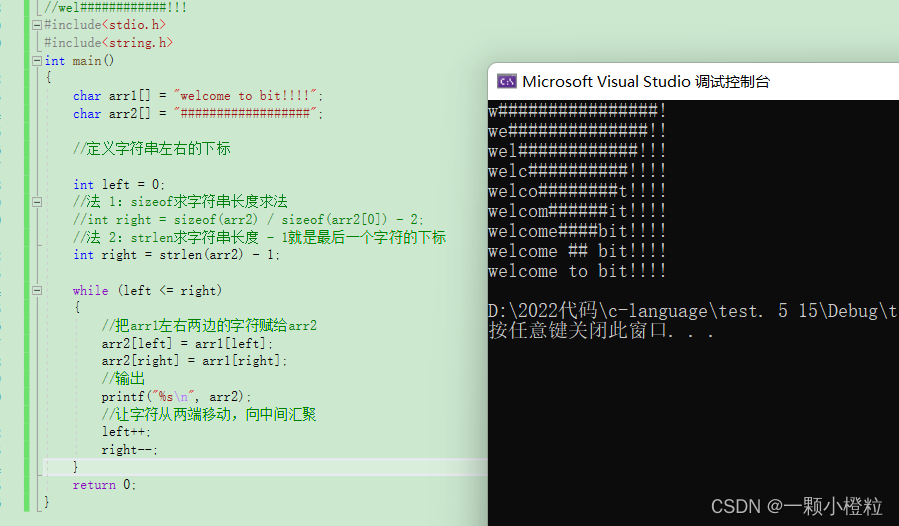
//演示字符串"welcome to bit!!!!"从两端移动,向中间汇聚
//welcome to bit!!!!
//##################
//w################!
//we##############!!
//wel############!!!
#include<stdio.h>
#include<string.h>//strlen的头文件
int main()
{
char arr1[] = "welcome to bit!!!!";
char arr2[] = "##################";
//定义字符串左右的下标
int left = 0;
//法 1:sizeof求字符串长度
//int right = sizeof(arr2) / sizeof(arr2[0]) - 2;
//法 2:strlen求字符串长度
int right = strlen(arr2) - 1;
while (left <= right)
{
//把arr1左右两边的字符赋给arr2
arr2[left] = arr1[left];
arr2[right] = arr1[right];
//输出
printf("%s\n", arr2);
//让字符从两端移动,向中间汇聚
left++;
right--;
}
return 0;
}
代码中我们求字符串长度有两种求法 sizeof 和 string;
他们的区别是怎样的呢?,为什么一个减 2,一个减 1呢?
char buf[] = "abc";
//下标 012
int right = sizeof(buf) / sizeof(buf[0]) -2;//法1
int right = strlen(arr2) - 1;//法2
分析:
假设我一个字符串是 “abc”,放在数组 buf 中;
我们知道字符串的结束标志是 ‘\0’ ,
我们sizeof 求一个字符串长度的时候,是包括 ‘\0’ 的,所以代码中数组 buf 的字符串 “abc” 长度是 4,而我们题目所需要的是字符串最后一个字符的下标,c 的下标是 2,所以我们用 sizeof 求法时要减 2
而我们strlen求字符串长度不包括‘\0’,所以求的 buf 数组的字符串"abc"长度就是3,我们所要的是下标c是2,所以要减1,才能得到最后一个字符的下标,
明白了这个我们上面那个字符串 “welcome to bit!!!” 也是一样的道理
打印效果:
我们运行他就瞬间打印,那我们不想他那么快打印,让他打印一次后隔一秒打印行不行,可以,看代码:
#include<stdio.h>
#include<string.h>//strlen的头文件
#include<windows.h>//Sleep的头文件
int main()
{
char arr1[] = "welcome to bit!!!!";
char arr2[] = "##################";
int left = 0;
int right = strlen(arr2) - 1;
while (left <= right)
{
arr2[left] = arr1[left];
arr2[right] = arr1[right];
printf("%s\n", arr2);
Sleep(1000);//延迟打印1秒
//1000是毫秒,换成秒就是1秒,
//Sleep函数调用,他的头文件是<windows.h>
//让字符从两端移动,向中间汇聚
left++;
right--;
}
return 0;
}
我们可以看到我在 printf 后面加上 Sleep 函数调用,就可以实现延迟打印,他的头文件是<windows.h> ;由于视频载不进来,这边就不演示打印效果啦,想看效果的直接把代码复制到自己编译器运行就知道啦!
那我们能不能让他直接在一行打印,然后两端向中间汇聚,不要冒那么多行可不可以,当然可以,看代码:
#include<stdio.h>
#include<string.h>//strlen的头文件
#include<windows.h>//Sleep的头文件
#include<stdlib.h>//system的头文件
int main()
{
char arr1[] = "welcome to bit!!!!";
char arr2[] = "##################";
int left = 0;
int right = strlen(arr2) - 1;
while (left <= right)
{
arr2[left] = arr1[left];
arr2[right] = arr1[right];
printf("%s\n", arr2);
Sleep(1000);//延迟打印 1秒
system("cls");//system是库函数,可以执行系统命令
//他的头文件是<stdlib.h>
//cls是清空屏幕的系统命令
left++;
right--;
}
printf("%s\n", arr2);//加一行输出可以保留打印最后的结果
//不加的话打印到最后啥都没有,因为被上面屏幕清空了
return 0;
}
这边没有打印效果,想知道的家人,动动自己可爱的小手哈;
这边我们需要注意的是 system 函数和他的头文件<stdlib.h>
补充:系统命令很好玩的,粗略的介绍一下啥叫系统命令
我们windows系统上搜素cmd,然后就可以输入我们的系统命令了
图示:
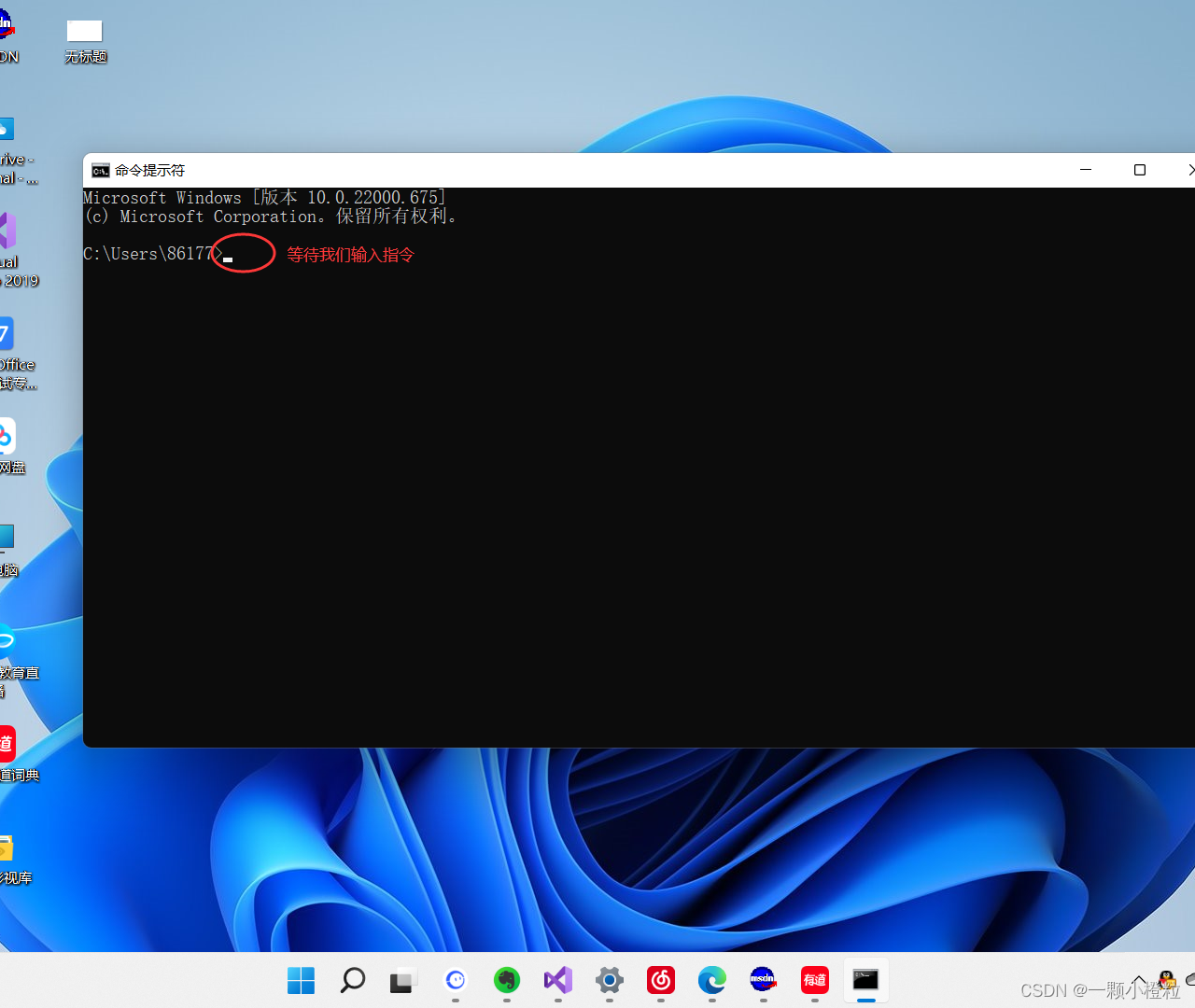
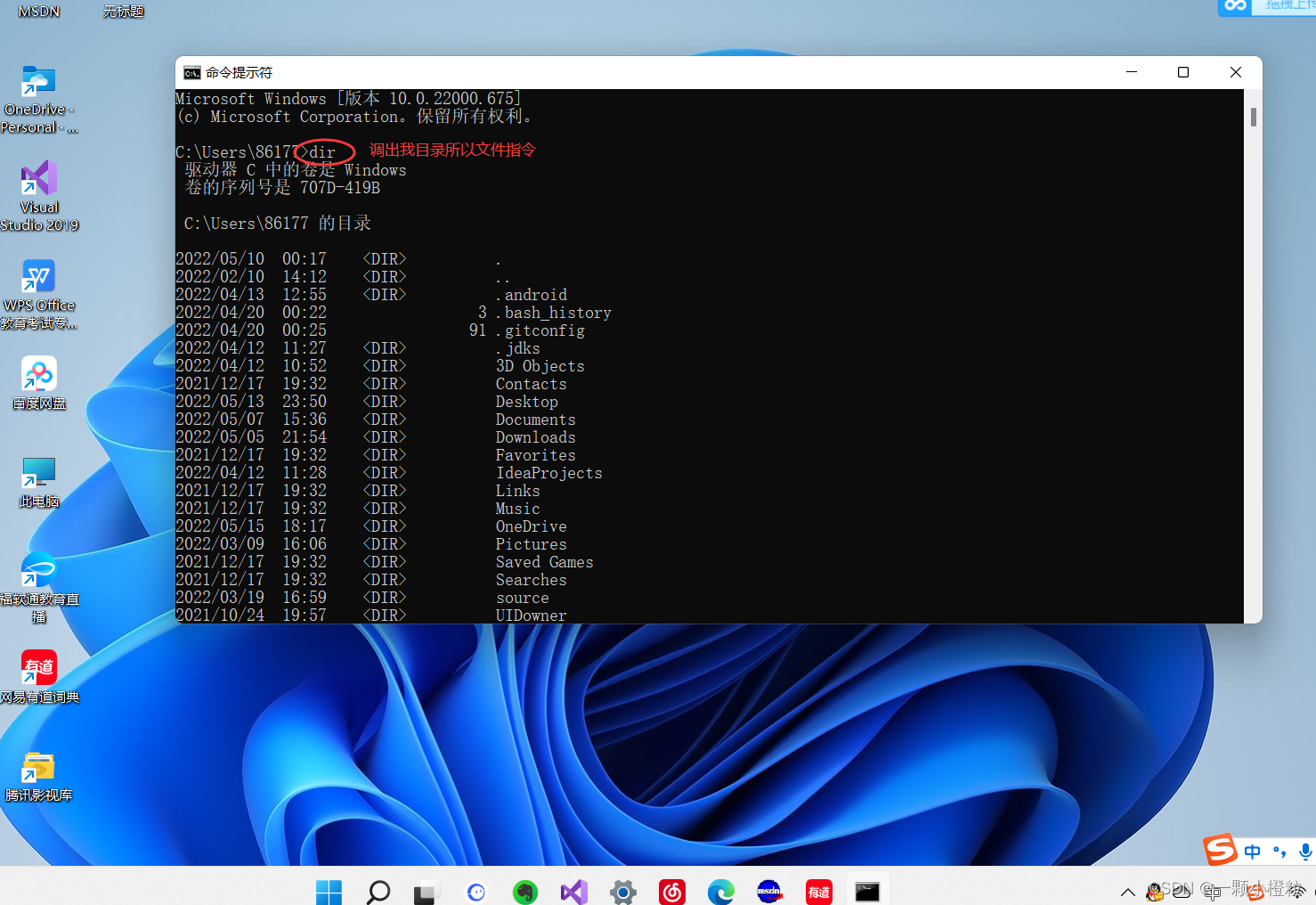
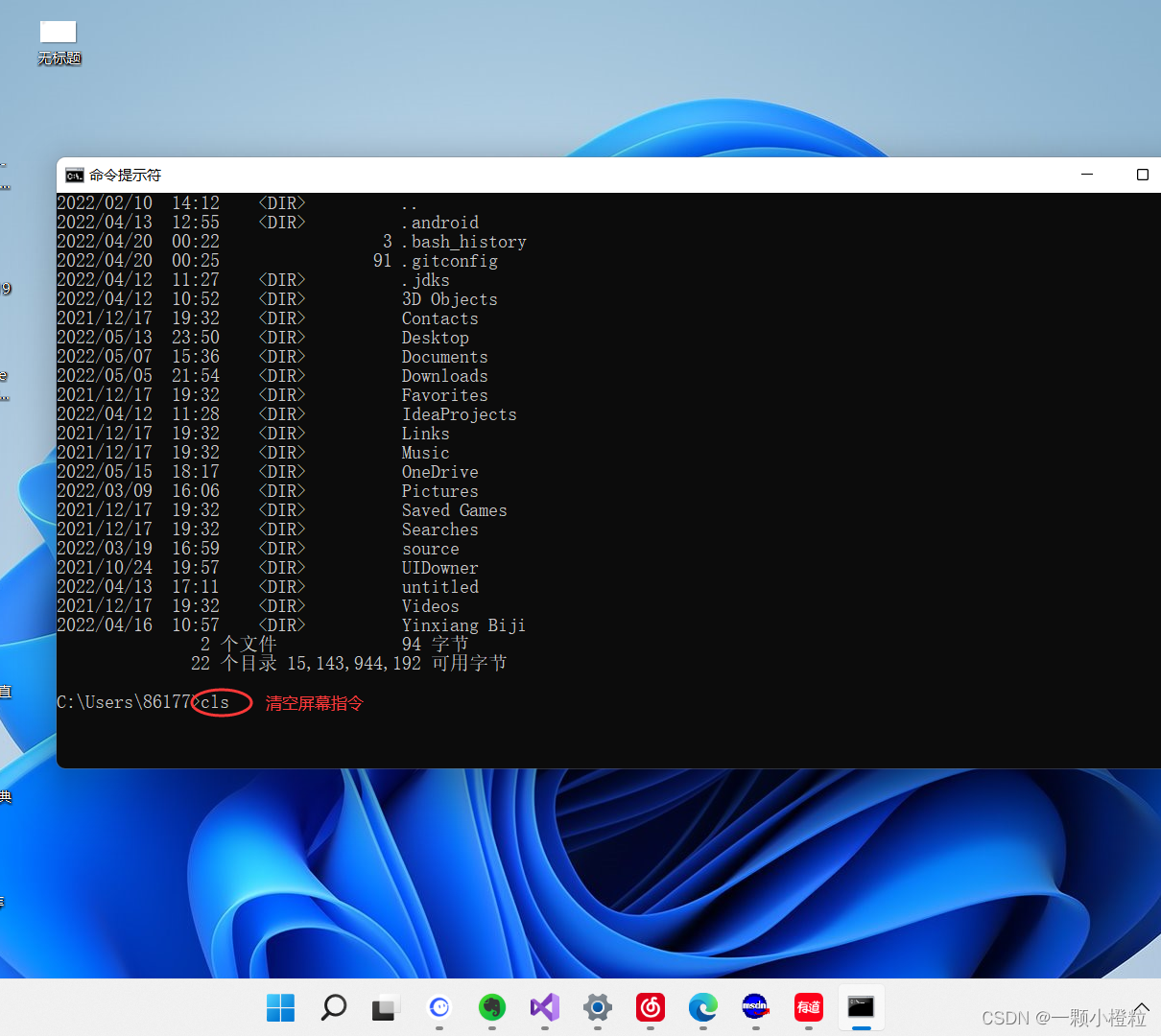
① 在windows搜索栏上搜素 cmd 关键词
② 打开 cmd 界面
③ 输入dir打开文件目录指令,然后再用cls清空屏幕
④ 然后再用cls清空屏幕
⑤ 回车看效果:
cmd系统命令有很多指令,我们可以在代码中用system函数去调用它可以产生很多好玩(整蛊)代码,文章最后有cmd整人小代码——关机程序;
这边就不多说了,预知下事,继续往下看!!!
5. 编写代码实现,模拟用户登录情景,并且只能登录三次。(只允许输入三次密码,如果密码正确则提示登录成功,如果三次均输入错误,则退出程序。
思路:得用循环产生3次密码;再判断密码正确或错误
//比较2个字符串是否相等,不能使用==,而应该使用一个库函数:strcmp
//如果返回值是0,表示2个字符串相等
#include<stdio.h>
#include<string.h>//strcmp的头文件
int main()
{
char password[20] = { 0 };
int i = 0;
//假设密码是字符串:abcdef
for (i = 0; i < 3; i++)
{
printf("请输入密码>:");
scanf("%s", password);//password是数组名,而数组名不用取地址,本身就是地址
//if(password == "abcdef") 错
//比较2个字符串是否相等,不能使用==,而应该使用一个库函数:strcmp
//如果返回值是0,表示2个字符串相等
//当输入的数组和密码相等时则登录成功
if (strcmp(password, "abcdef") == 0)
{
printf("登录成功\n");
break;
}
else
{
printf("密码错误\n");
}
}
if (i == 3)
{
printf("三次均输入错误,退出程序");
}
return 0;
}
这题我们需要注意的是:
当我们比较2个字符串是否相等,不能使用 == , 而应该使用一个库函数:strcmp,
如果返回值是0,表示2个字符串相等,如果不加 == 0 相当于没返回值,默认不相等;
strcmp 的头文件是<string.h>
6. 猜数字游戏实现
//开始猜数字的逻辑
//1.电脑产生一个随机数(1~100)
//2.猜数字
//猜大了
//猜小了
//直到猜对了,结束
#include<stdio.h>
#include<stdlib.h> //rand、srand 的头文件
#include<time.h> //time的头文件
void menu()//菜单函数
{
printf("********************\n");
printf("***** 1.play *****\n");
printf("***** 0.exit *****\n");
printf("********************\n");
}
void game()//开始猜数字的逻辑
{
int guess = 0;
//srand((unsigned int)time(NULL)); 用rand时必须调用srand,它的返回类型是无符号整型
//srand的调用如果一直调用(在循环里)的话,输入快的情况下产生的随机数会一样,所以我把他放在下面的主函数里
//rand生成随机数,生成的范围是 0到 RAND_MAX(可以转定义查看),也就是0到0x7fff 就是0到32767
//任何数模上100的范围都是0~99,按题要求0~100,所以加1
int ret = rand() % 100 + 1;
while (1)
{
printf("请猜数字>:");
scanf("%d", &guess);
if (ret < guess)
{
printf("猜大了\n");
}
else if (ret > guess)
{
printf("猜小了\n");
}
else
{
printf("恭喜你,猜对了\n");
break;
}
}
}
//时间戳就是会随着时间一秒一秒变化
int main()
{
//生成随机数不用反复调用,调用一次就行了,所以放在主函数里,不在循环里
//srand的调用()里放的是不停变化的值(时间戳)就可以产生不同的随机数
//time函数可以调用时间戳,NULL是空指针,返回值不储存
srand((unsigned int)time(NULL));
int input = 0;
do
{
menu();//函数:菜单(1/0)选择游戏的开始
printf("请选择>:");
scanf("%d", &input);
switch (input)
{
case 1:
game();//函数:1开始游戏后猜数字的真正逻辑
break;
case 0:
printf("退出游戏\n");
break;
default:
printf("选择错误,重新选择\n");
break;
}
} while (input);
return 0;
}
总结:
猜数字游戏实现并不难,这边需要注意的是他怎么生成随机数?
他需要调用的库函数是什么,头文件又是什么?是需要我们记忆的,
注意一下rand 的用法,srand 的调用一次就好,不用在循环里反复调用(注意放的位置,放在主函数里)
这边我们在代码中调用了两次自定义函数,其主要还是在看代码的时候,还是从主函数main里开始看,到自定义函数那边在看怎么写的自定义函数如菜单和开始猜数字的逻辑
goto 语句
C语言中提供了可以随意滥用的 goto语句和标记跳转的标号。
从理论上 goto语句是没有必要的,实践中没有goto语句也可以很容易的写出代码。
但是某些场合下goto语句还是用得着的,最常见的用法就是终止程序在某些深度嵌套的结构的处理过程。
例如:一次跳出两层或多层循环。
多层循环这种情况使用break是达不到目的的。它只能从最内层循环退出到上一层的循环。
1. goto语言最适合的场景如下:
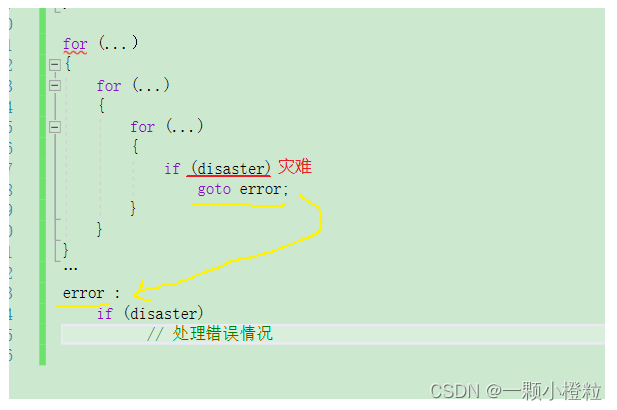
分析:
当多层 for 循环,遇到灾难时想要跳出来时,用break,要用很多个,比较麻烦,
这时goto语句就很好用了,goto去标记一个error,然后再把error放在我们想跳出去的地方,程序运行起来遇到goto就直接跳到标记error那边了,就跳出去了
2. 关机程序
既然实践中没有goto语句也可以很容易的写出代码,那我们用goto语句写一个关机程序,
这个关机程序跟我们上面说到那个cmd指令有关,很好玩,打完这个代码可以发给你朋友玩玩,你朋友会感激你的(正经)
这个代码实现的思路就是:
我们调用系统命令关机,然后再判断我们输入的内容(字符串)和我们想要让他打的内容是否相等,相等则取消关机,不相等则继续,直到60秒后还不相等就关机
比如我下面写的这个是我输入 我是懒猪,就取消关机,否则继续输入直到输入正确
不然60秒后就关机:
//goto 语句
//关机程序
//1. 电脑运行起来后,1分中内关机
//2. 如果输入:我是猪,就取消关机
//strcmp(比较两个字符是否相等,相等则返回 0)
//system(执行系统命令)
#include<stdio.h>
#include<string.h>//strcmp 的头文件
#include<stdlib.h>//system 的头文件
int main()
{
char input[20] = { 0 };
system("shutdown -s -t 60");//调用执行系统关机命令,-s为关机,-t为设置,为60秒
again:
printf("请注意,你的电脑将在60秒过后关机,请输入:我是懒猪,就取消关机\n");//提醒
scanf("%s", input);//等待我们输入,数组名不用取地址,其本身就是地址
//判断
if (strcmp(input,"我是懒猪") == 0)//比较两个字符是否相等
{
system("shutdown -a");//相等则取消关机
}
else
{
goto again;//不相等进入goto,
}
return 0;
}

分析:
当不相等时遇到goto,goto的标记 aging在提醒那边,意味着要是我们输入的不是“我是懒猪”,他会重新回到判断那边让我们重新输入,这听起来怎么跟循环这么像呢?
我们用循环的写法试一下,看看是不是一样的效果:
#include<stdio.h>
#include<string.h>//strcmp 的头文件
#include<stdlib.h>//system 的头文件
int main()
{
char input[20] = { 0 };
system("shutdown -s -t 60");//调用执行系统关机命令,-s为关机,-t为设置,为60秒
while (1)
{
printf("请注意,你的电脑将在60秒过后关机,请输入:我是懒猪,就取消关机\n");//提醒
scanf("%s", input);//等待我们输入,数组名不用取地址,其本身就是地址
//判断
if (strcmp(input, "我是懒猪") == 0)//比较两个字符是否相等
{
system("shutdown -a");//相等则取消关机
break;//取消关机就跳出循环
}
}
return 0;
}
经过我运行对比他俩的结果是一样的:
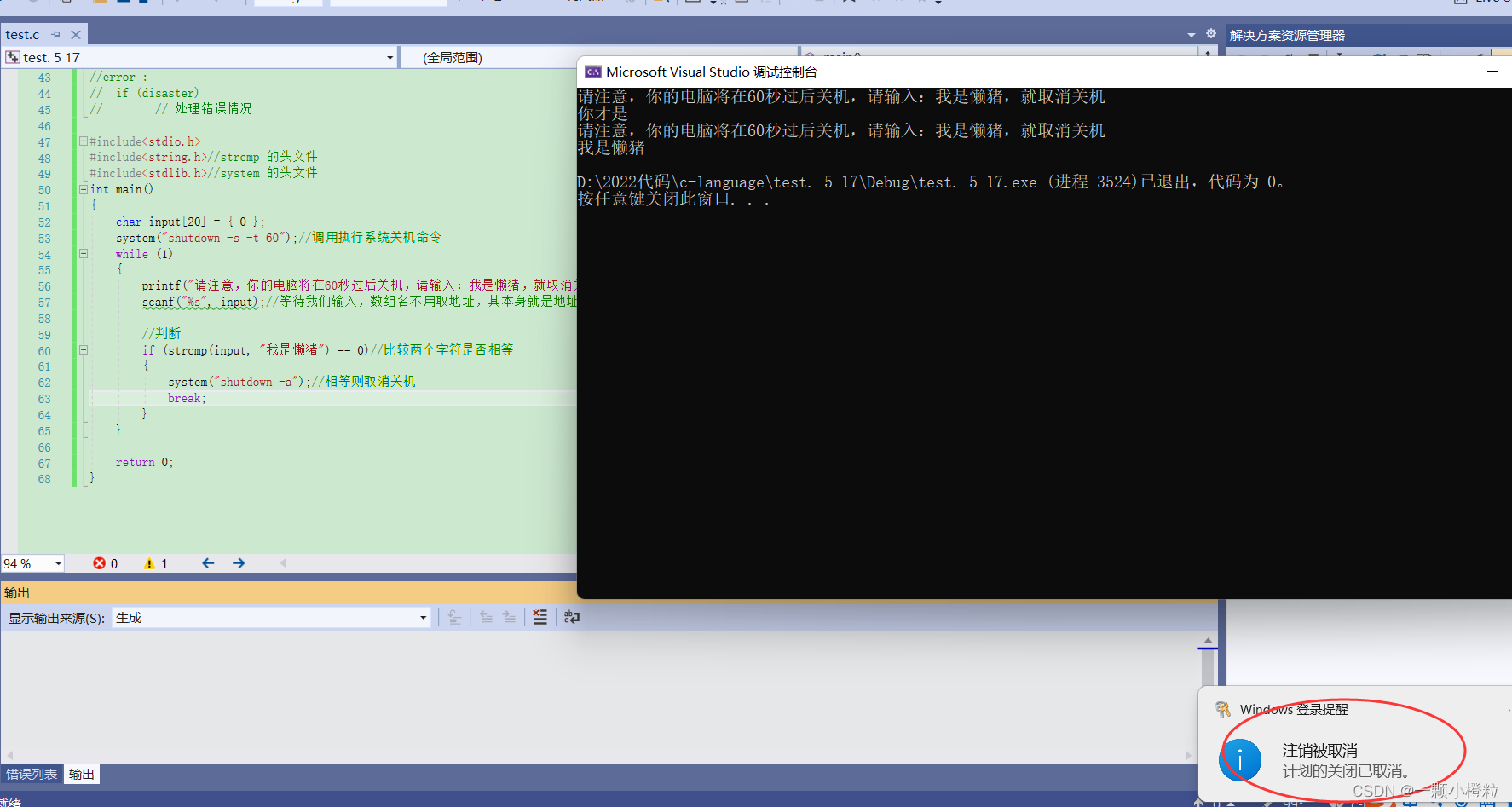
当我输入“你才是”,他就提醒我继续输入,当我输入“我是懒猪”,他就取消关机了,我要
是不输入“我是懒猪” 60秒后必关机就算关掉黑幕也会关机,这个程序你也可以改,把 if
里判断条件改成你想要让他(她)说的话,否则关机,你也可以改我代码中调用的关机指
令换成其他指令,这个指令就是cmd指令,你百度搜一下就有了,学完快去发给你最爱的
人吧,他(她)会感激你的(哈哈)
这边说一下怎么保存然后发给朋友玩:
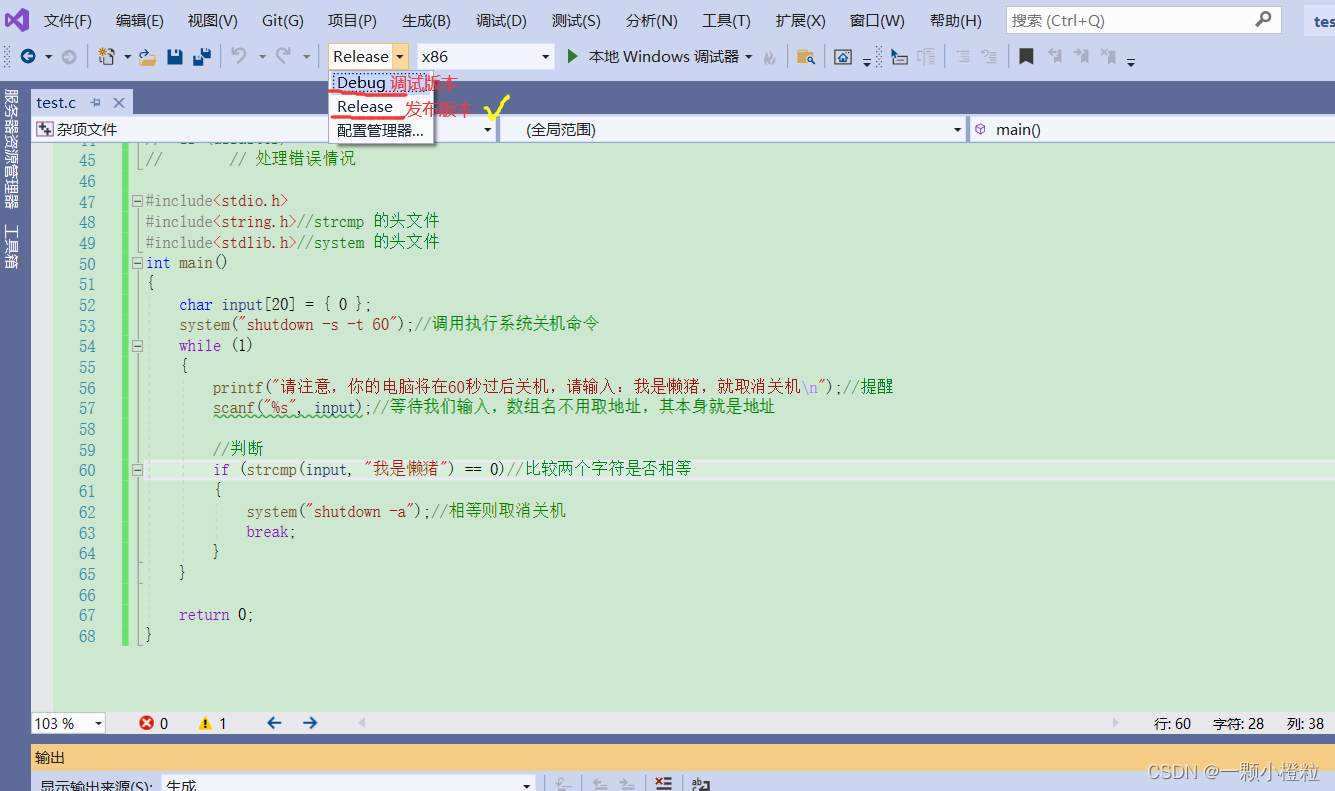
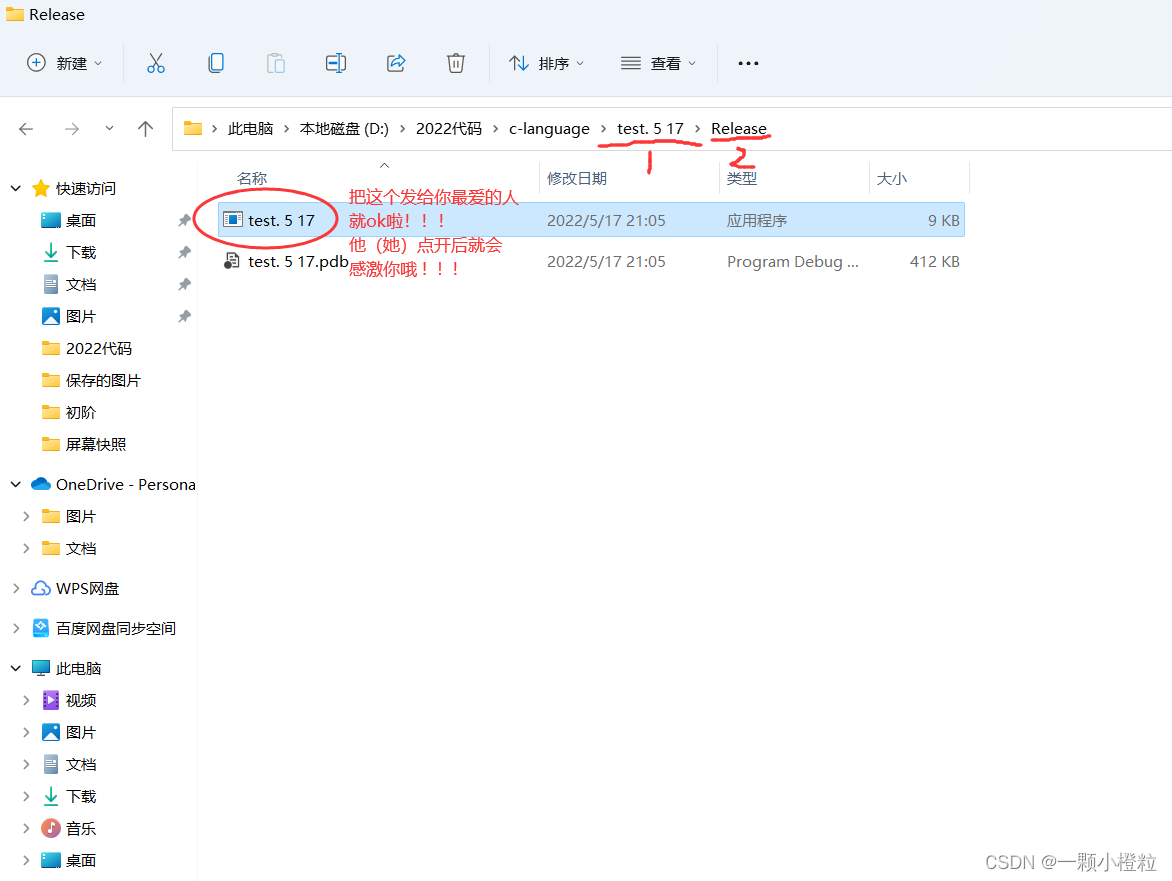
vs2019 编译器下演示:
.
① 首先把他调试版本改成发布版本
② 然后我们电脑储存这个代码的路径下就有了Release(发布版本):
这边我送上关于shutdown命令的扩展
链接: shoudown命令扩展
总结:goto语句最适合在多层循环中想跳出时使用,如果随意乱用goto语句将会产生很多bug!!!
这篇到这里就结束啦!
我们在这章学了分支语句、循环、gechar 的特性、二分查找法、猜数字游戏、关机程序,这边我最喜欢的就是cmd指令啦,没想到 c 语言还能这么玩,家人们有空一定要去玩一玩这个关机程序,没事改一下代码整一下(你懂吧)!如果你有更好玩的cmd整人代码,记得分享给我哦,本人可是很有兴趣呢(嘿嘿)
最后希望我这篇对你们的学习有所帮助,如果有帮助的话不妨动动可爱的小手,给个免费的赞,也算对我的学习上的一种鼓励,谢谢!!!
你们的支持是我最大的动力,加油,让我们成为更好的自己!!!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











