






Flexus云服务器X实例购买
用优惠券之后0元!欢迎大家购买一个,动手跟我一起试试

探索未来算力新纪元 —— 华为云Flexus X实例的深度体验与启示
在云计算技术日新月异的今天,如何精准匹配并高效利用算力资源,成为了企业数字化转型中亟待解决的关键问题。华为云,作为业界的佼佼者,以其创新的“柔性算力”技术,推出了Flexus云服务器X实例,不仅重新定义了云服务的边界,更为我们打开了一扇通往未来算力世界的大门。通过此次深度体验,我将从评测使用、操作指南及场景应用三个维度,分享华为云FlexusX实例带来的惊喜与启示。
在云计算技术不断演进的今天,华为云Flexus云服务器X实例凭借其创新的柔性算力技术,正引领着云计算领域的变革。相比传统的固定规格云服务器,Flexus X实例提供了更加灵活的资源配置和智能调优功能,能够精准满足各种业务场景的需求。为了充分体验Flexus X实例的卓越性能,我们将选择部署Kafka和ZooKeeper这两个关键组件,深入探讨其在实际应用中的表现。Kafka作为高吞吐低延迟的消息队列系统,与ZooKeeper的分布式协调服务相结合,将帮助我们更好地理解Flexus X实例在处理高并发数据流和分布式应用中的优势表现。接下来,我们将详细评测这些组件在Flexus X实例上的实际表现,并提供操作指南和应用场景体验,以全面展现这款云服务器的强大能力。
一、评测使用体验与对比测试报告
初次接触华为云Flexus X实例,最直观的感受便是其无与伦比的灵活性。不同于传统云服务器固定的CPU内存配比,Flexus X实例允许用户自定义CPU与内存规格,如1:3、2:5等特殊配比,这种前所未有的自由度,让我能够根据实际业务需求,精准配置资源,避免了资源的浪费。
在性能测试环节,Flexus X实例的表现同样令人印象深刻。其基础模式下,GeekBench单核及多核跑分已达到业界同规格独享型实例的1.6倍,性能模式下更是超越了多个知名品牌的旗舰级云主机。更令人振奋的是,FlexusX实例内置的X-Turbo加速和大模型底层智能调度技术,使得MySQL、Redis、Nginx等关键应用的性能实现了质的飞跃,最高可达同规格实例的6倍,为业务的高速运行提供了坚实的支撑。
此外,与市场上其他云服务器产品相比,Flexus X实例不仅在性能上占据优势,其经济性同样不容忽视。通过动态业务画像规格优化,用户在迁移至Flexus X实例时,可节省高达30%的算力成 ,这对于成 控制意识强烈的企业而言,无疑是一大利好。
二、华为云Flexus X实例使用教学、操作指南
对于初次接触Flexus X实例的用户而言,一套详尽的使用教学和操作指南至关重要。华为云凭借其强大的技术实力和用户关怀,为我们提供了详尽的文档和视频教程,覆盖了从实例创建、配置调整、性能优化到安全加固等各个环节。
在实际操作中,我感受到了华为云平台的易用性和智能化。通过华为云控制台,我可以轻松完成FlexusX实例的创建与配置,并根据业务需求灵活调整CPU、内存等资源规格。同时,内置的智能应用调优算法和底层多重调优加速技术,使得FlexusX实例能够自动优化性能,确保业务的高效运行。
值得一提的是,Flexus X实例还支持热变配功能,即在不停机的情况下对CPU、内存资源进行规格调整,这一功能极大地提升了业务的连续性和稳定性,减少了因资源调整而导致的服务中断风险。
三、华为云Flexus X实例下的场景体验
为了更深入地了解Flexus X实例在实际业务场景中的应用效果,我特意在多个场景下进行了测试。首先是网络应用场景,Flexus X实例以其出色的网络性能和稳定性,为Web服务器和API服务提供了强有力的支持,确保了用户访问的流畅性和数据处理的高效性。
在数据库和虚拟桌面场景中,Flexus X实例的高性能和大容量内存,使得MySQL、Redis等数据库应用能够轻松应对高并发访问和海量数据处理的需求,同时为用户提供了流畅的虚拟桌面体验。
此外,在微服务、CI/CD等场景中,Flexus X实例的智能调度和加速功能,进一步提升了服务的响应速度和可靠性,为企业的快速迭代和持续交付提供了有力保障。
结语
通过此次对华为云Flexus X实例的深度体验,我深刻感受到了“柔性算力”技术带来的革命性变化。Flexus X实例以其灵活的资源配置、卓越的性能表现、经济高效的成 控制以及安全可靠的服务保障,为企业的数字化转型提供了强有力的支撑。我相信,在未来的算力世界中,华为云Flexus X实例必将成为众多企业的首选之选,共同推动云计算技术的蓬勃发展。
Zookeeper集群部署
简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
除了为Hadoop和HBase提供协调服务外,Zookeeper也被其它许多软件采用作为其分布式状态一致性的依赖,比如Kafka,又或者一些软件项目中,也经常能见到Zookeeper作为一致性协调服务存在。
Zookeeper不论是大数据领域亦或是其它服务器开发领域,涉及到分布式状态一致性的场景,总有它的身影存在。
安装
Zookeeper是一款分布式的集群化软件,可以在多台服务器上部署,并协同组成分布式集群一起工作。
- 首先,要确保已经完成了
集群化环境前置准备环节的全部内容 - 【node1上操作】下载Zookeeper安装包,并解压
# 下载
wget http://archive.apache.org/dist/zookeeper/zookeeper-3.5.9/apache-zookeeper-3.5.9-bin.tar.gz
# 确保如下目录存在,不存在就创建
mkdir-p /export/server
# 解压
tar -zxvf apache-zookeeper-3.5.9-bin.tar.gz -C /export/server- 【node1上操作】创建软链接
ln-s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper- 【node1上操作】修改配置文件
vim /export/server/zookeeper/conf/zoo.cfg
tickTime=2000
# zookeeper数据存储目录
dataDir=/export/server/zookeeper/data
clientPort=2181
initLimit=5
syncLimit=2
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888- 【node1上操作】配置
myid
# 1. 创建Zookeeper的数据目录
mkdir /export/server/zookeeper/data
# 2. 创建文件,并填入1
vim /export/server/zookeeper/data/myid
# 在文件内填入1即可- 【在node2和node3上操作】,创建文件夹
mkdir-p /export/server- 【node1上操作】将Zookeeper 复制到node2和node3
cd /export/server
scp -r apache-zookeeper-3.5.9 node2:`pwd`/
scp -r apache-zookeeper-3.5.9 node3:`pwd`/- 【在node2上操作】
# 1. 创建软链接
ln-s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为2- 【在node3上操作】
# 1. 创建软链接
ln-s /export/server/apache-zookeeper-3.5.9 /export/server/zookeeper
# 2. 修改myid文件
vim /export/server/zookeeper/data/myid
# 修改内容为3- 【在node1、node2、node3上分别执行】启动Zookeeper
# 启动命令
/export/server/zookeeper/bin/zkServer.sh start # 启动Zookeeper- 【在node1、node2、node3上分别执行】检查Zookeeper进程是否启动
jps
# 结果中找到有:QuorumPeerMain 进程即可- 【node1上操作】验证Zookeeper
/export/server/zookeeper/zkCli.sh
# 进入到Zookeeper控制台中后,执行
ls /
# 如无报错即配置成功至此Zookeeper安装完成
Kafka集群安装部署
简介
Kafka是一款分布式的、去中心化的、高吞吐低延迟、订阅模式的消息队列系统。
同RabbitMQ一样,Kafka也是消息队列。不过RabbitMQ多用于后端系统,因其更加专注于消息的延迟和容错。
Kafka多用于大数据体系,因其更加专注于数据的吞吐能力。
Kafka多数都是运行在分布式(集群化)模式下,所以课程将以3台服务器,来完成Kafka集群的安装部署。
安装
- 确保已经跟随前面的视频,安装并部署了JDK和Zookeeper服务
Kafka的运行依赖JDK环境和Zookeeper请确保已经有了JDK环境和Zookeeper
- 【在node1操作】下载并上传Kafka的安装包
# 下载安装包
wget http://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz- 【在node1操作】解压
mkdir-p /export/server # 此文件夹如果不存在需先创建
# 解压
tar -zxvf kafka_2.12-2.4.1.tgz -C /export/server/
# 创建软链接
ln-s /export/server/kafka_2.12-2.4.1 /export/server/kafka- 【在node1操作】修改Kafka目录内的config目录内的
server.properties文件
cd /export/server/kafka/config
# 指定broker的id
broker.id=1
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node1:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181- 【在node1操作】将node1的kafka复制到node2和node3
cd /export/server
# 复制到node2同名文件夹
scp -r kafka_2.12-2.4.1 node2:`pwd`/
# 复制到node3同名文件夹
scp -r kafka_2.12-2.4.1 node3:$PWD- 【在node2操作】
# 创建软链接
ln-s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=2
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node2:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181- 【在node3操作】
# 创建软链接
ln-s /export/server/kafka_2.12-2.4.1 /export/server/kafka
cd /export/server/kafka/config
# 指定broker的id
broker.id=3
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node3:9092
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181- 启动kafka
# 请先确保Zookeeper已经启动了
# 方式1:【前台启动】分别在node1、2、3上执行如下语句
/export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties
# 方式2:【后台启动】分别在node1、2、3上执行如下语句
nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties 2>&1 >> /export/server/kafka/kafka-server.log &- 验证Kafka启动
# 在每一台服务器执行
jps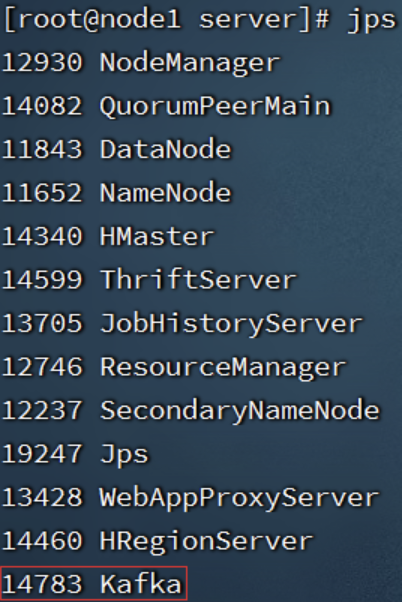
测试Kafka能否正常使用
- 创建测试主题
# 在node1执行,创建一个主题
/export/server/kafka_2.12-2.4.1/bin/kafka-topics.sh --create--zookeeper node1:2181 --replication-factor1--partitions3--topic test- 运行测试,请在FinalShell中打开2个node1的终端页面
# 打开一个终端页面,启动一个模拟的数据生产者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list node1:9092 --topic test
# 再打开一个新的终端页面,在启动一个模拟的数据消费者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic test --from-beginning














 1451
1451

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









