






Lucene功能
1.可扩展的高性能索引
2.强大、准确、高效的搜索算法
3.跨平台解决方案
适用场景
在应用中为数据库中的数据提供全文检索实现。
开发独立的搜索引擎服务、系统。
对于数据量大、数据结构不固定的数据可采用全文检索方式搜索。
任意 结构化搜索
全文搜索
分面
跨高维向量的最近邻搜索
拼写纠正或查询建议的应用程序架构
结构化数据搜索与非结构化数据搜索对比分析

1.需要的pom文件
<dependencies> <!-- Web依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- MySQL驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <!-- Mybatis-Plus --> <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-boot-starter</artifactId> <version>3.5.2</version> </dependency> <!-- 引入Lucene核心包及分词器包 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>4.10.3</version> </dependency> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>4.10.3</version> </dependency> <!-- 热部署 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> <optional>true</optional> </dependency> <!-- Lombok工具 --> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <!-- IK中文分词器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies>2.核心配置文件
#访问的端口 server.port=9000 spring.application.name=lunce spring.datasource.hikari.driver-class-name=com.mysql.cj.jdbc.Driver spring.datasource.url=jdbc:mysql://localhost:3306/es_db?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=UTC spring.datasource.username=root spring.datasource.password=0216 # 开启驼峰命名匹配映射 mybatis-plus.configuration.map-underscore-to-camel-case=true
3.job_info表对应的实体类
import com.baomidou.mybatisplus.annotation.IdType; import com.baomidou.mybatisplus.annotation.TableId; import com.baomidou.mybatisplus.annotation.TableName; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; @Data @AllArgsConstructor @NoArgsConstructor @TableName("job_info") public class JobInfo { @TableId(type = IdType.AUTO) private Long id; // id属性建议使用包装类定义 private String companyName; private String companyAddr; private String companyInfo; private String jobName; private String jobAddr; private String jobInfo; private int salaryMin; private int salaryMax; private String url; private String time; }4.mapper层
import com.baomidou.mybatisplus.core.mapper.BaseMapper; import com.lucene.demo.dommain.JobInfo; public interface JobInfoMapper extends BaseMapper<JobInfo> { }5.service层
接口
import com.lucene.demo.dommain.JobInfo; import java.util.List; public interface JobInfoService { JobInfo selectById(Long id); List<JobInfo> selectAll(); }实现类
import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper; import com.lucene.demo.dommain.JobInfo; import com.lucene.demo.mapper.JobInfoMapper; import com.lucene.demo.service.JobInfoService; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.stereotype.Service; import java.util.List; @Service public class JobInfoServiceImpl implements JobInfoService { @Autowired private JobInfoMapper jobInfoMapper; @Override public JobInfo selectById(Long id) { return jobInfoMapper.selectById(id); } @Override public List<JobInfo> selectAll() { List<JobInfo> ji = jobInfoMapper.selectList(new QueryWrapper<>()); return ji; } }
到这里我们的准备工作就算完成了,然后开始给大文件的数据创建索引
@Test public void createIndex() throws IOException {//数据中查询数据,给其建立索引 //1.指定索引文件存储位置 Directory directory = FSDirectory.open(new File("D:\\1javaweb\\index")); //2.配置分词器,版本信息 // Analyzer analyzer =new StandardAnalyzer();//Lucene提供的标准分词器 Analyzer analyzer =new IKAnalyzer();//IK分词器 //指定版本 Version.LATEST最新版本 IndexWriterConfig config =new IndexWriterConfig(Version.LATEST,analyzer); //3.创建一个用来写入索引的数据的对象IndexWriter // 1). 索引写入目标文件的位置 2).按照哪一个标准分词器写出数据 IndexWriter writer = new IndexWriter(directory,config); // 删除指定目录下的所有索引数据 writer.deleteAll(); //4.从Mysql数据库中查询的数据交给Lucene写入到index目录下并创建索引 List<JobInfo> jobInfos = jobInfoService.selectAll(); //5.循环遍历集合 for (JobInfo jobInfo:jobInfos) { //创建文档对象 :Document是用来存储数据库中的一条记录 Document d =new Document(); //document中添加field(数据库字段信息):数据类型,取值 YES永久存储 NO只用一次 d.add(new LongField("id",jobInfo.getId(), Field.Store.YES)); d.add(new TextField("companyName",jobInfo.getCompanyName(), Field.Store.YES)); d.add(new TextField("companyAddr",jobInfo.getCompanyAddr(), Field.Store.YES)); d.add(new IntField("salaryMax",jobInfo.getSalaryMax(), Field.Store.YES)); d.add(new IntField("salaryMin",jobInfo.getSalaryMin(), Field.Store.YES)); d.add(new StringField("url",jobInfo.getUrl(), Field.Store.YES)); d.add(new StringField("time",jobInfo.getTime(), Field.Store.YES)); //将当前的document文档写入到 writer.addDocument(d); } //关闭资源 writer.close(); }
通过索引进行搜索,更加快速简便
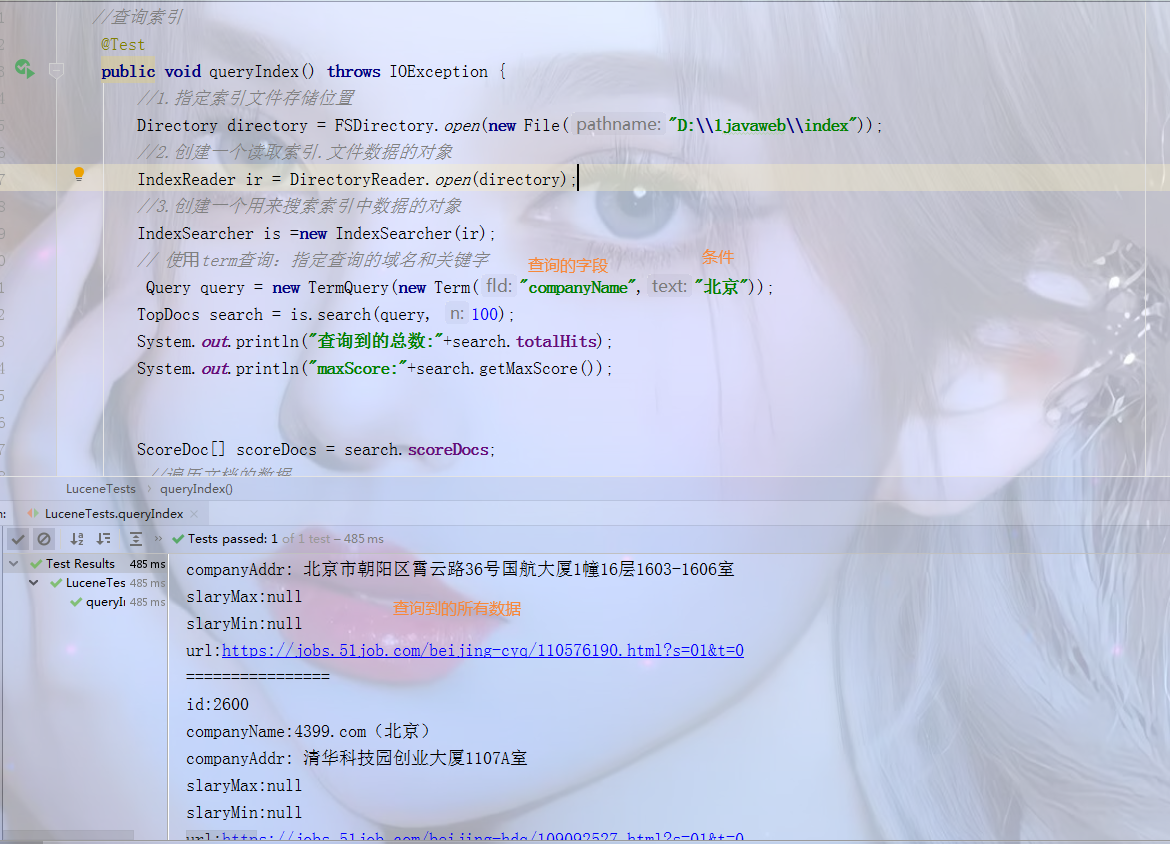
//查询索引 @Test public void queryIndex() throws IOException { //1.指定索引文件存储位置 Directory directory = FSDirectory.open(new File("D:\\1javaweb\\index")); //2.创建一个读取索引.文件数据的对象 IndexReader ir = DirectoryReader.open(directory); //3.创建一个用来搜索索引中数据的对象 IndexSearcher is =new IndexSearcher(ir); // 使⽤term查询:指定查询的域名和关键字 Query query = new TermQuery(new Term("companyName","京")); TopDocs search = is.search(query, 100); System.out.println("查询到的总数:"+search.totalHits); System.out.println("maxScore:"+search.getMaxScore()); ScoreDoc[] scoreDocs = search.scoreDocs; //遍历文档的数据 for (ScoreDoc scoreDoc : scoreDocs) { //获取id int docId = scoreDoc.doc; //根据id获取文档的对象 Document doc = is.doc(docId); System.out.println("id:"+doc.get("id")); System.out.println("companyName:"+doc.get("companyName")); System.out.println("companyAddr:"+doc.get("companyAddr")); System.out.println("slaryMax:"+doc.get("slaryMax")); System.out.println("slaryMin:"+doc.get("slaryMin")); System.out.println("url:"+doc.get("url")); System.out.println("================"); } }
对索引的解析
Index索引:在Lucene中一个索引是存放在一个文件夹中的
Segment段:按层次保存了索引到词的包含关系:索引(Index) => 段(segment) => 文档(Document) => 域(Field) => 词(Term)
即此索引包含了哪些段,每个段包含了哪些文档,每个文档包含了哪些域,每个域包含了哪些词。
一个索引可以包含多个段,段与段之间是独立的,添加新文档可以生成新的段,不同的段可以合并。
如上图中,具有相同前缀前件的属同同个段,图中共三个段
segments_8和segments.gen是段的元数据文件,也即它们保存了段的属性信息
Field的特性: 是否分词(tokenized) 拆分输入的关键词
是否索引(indexed) 用户查询条件的词作为索引
是否存储(stored) 将Field值保存在Document中
Field类 LongField:数值型代表 TextField:文本类型 IntField:数字类型 StringField:字符串















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









