






注:本文用的是Anaconda中的jupyter,故以Anaconda为例
本文是类似于学习笔记,若有错误欢迎批评指正,大家一起进步。
正文:
python中有一个库:netCDF4 ;用来专门处理nc数据的。
处理nc数据分为两大步。
1.首先下载netCDF4库。
1)打开Anaconda prompt(开始;找到anconda的文件夹点开,右键点击Anacoda prompt,点击以管理员身份运行)
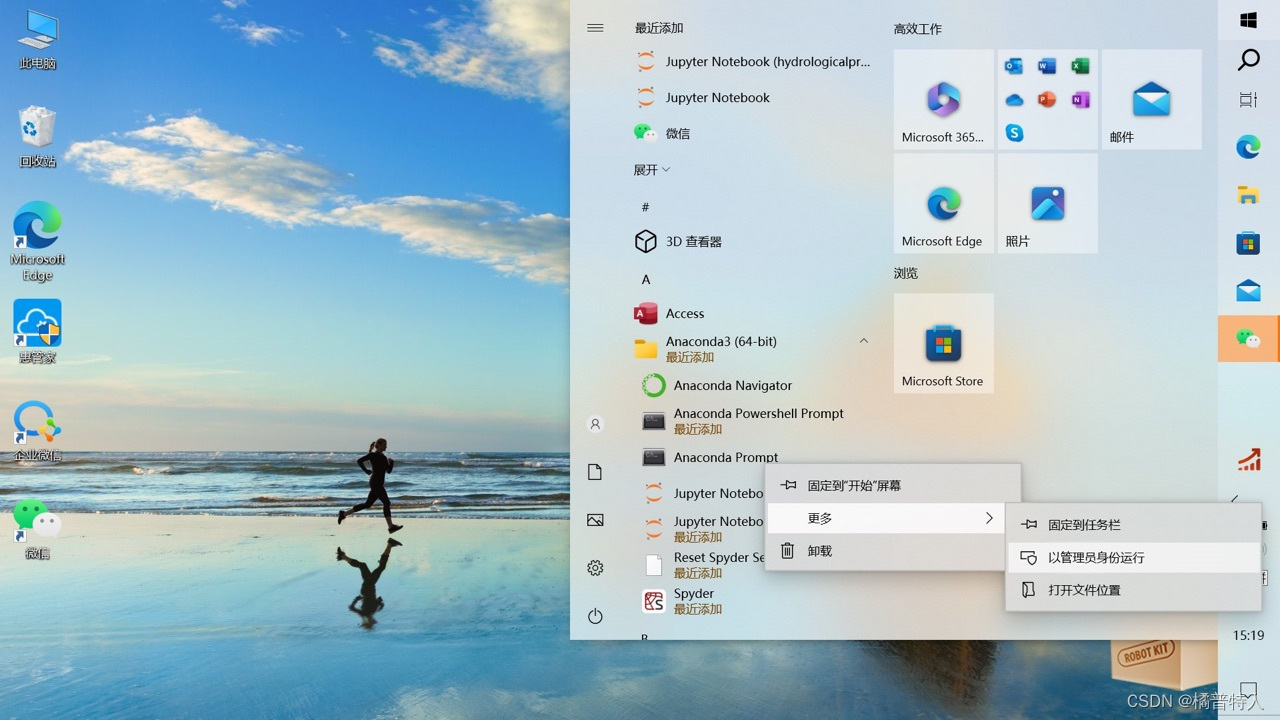
2)切换至你想要的环境。(如果没有虚拟环境直接跳过这一步)
打开Anaconda prompt后默认为base环境,此处最前面的括号是显示的是base,证明是base环境,
如果是想在拟定的虚拟环境中下载netCDF4,
输入:conda activate name(你创建的虚拟环境的名称)
如此就成功切换至了拟定的虚拟环境。此处我的虚拟环境名称为hydrologicalprocess,可以看到最前面的括号变成了hydrologicalprocess
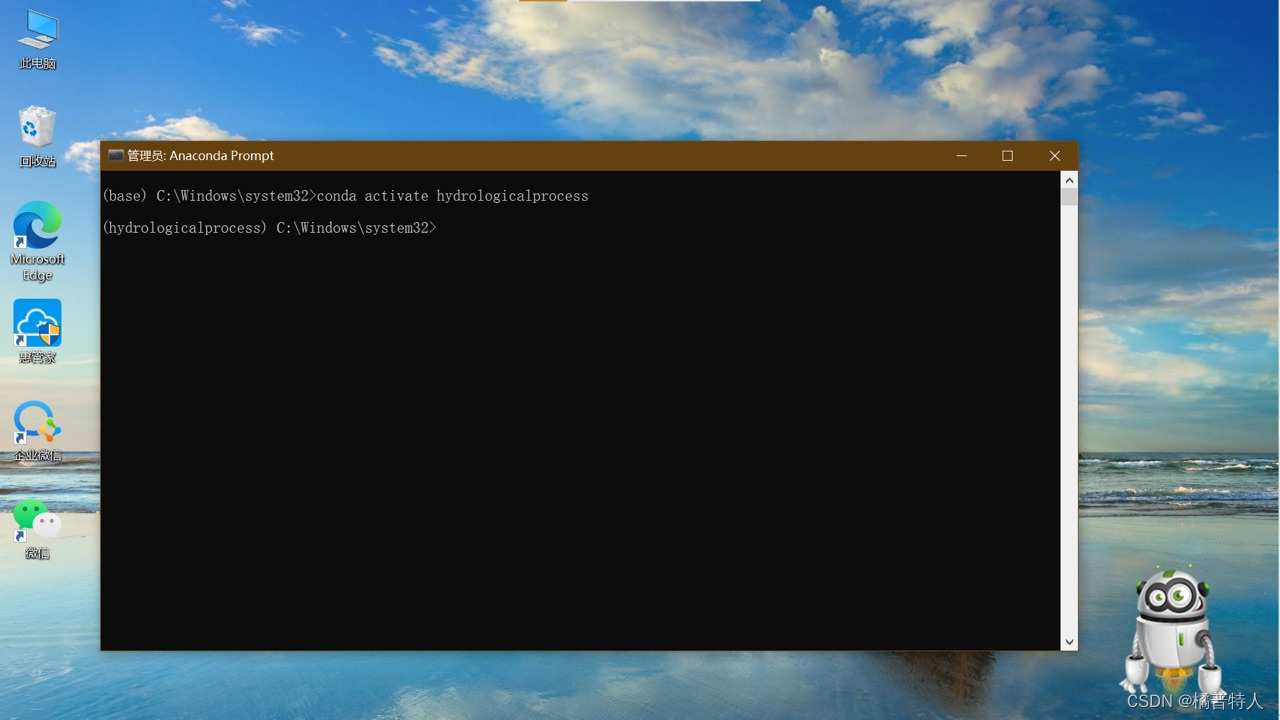
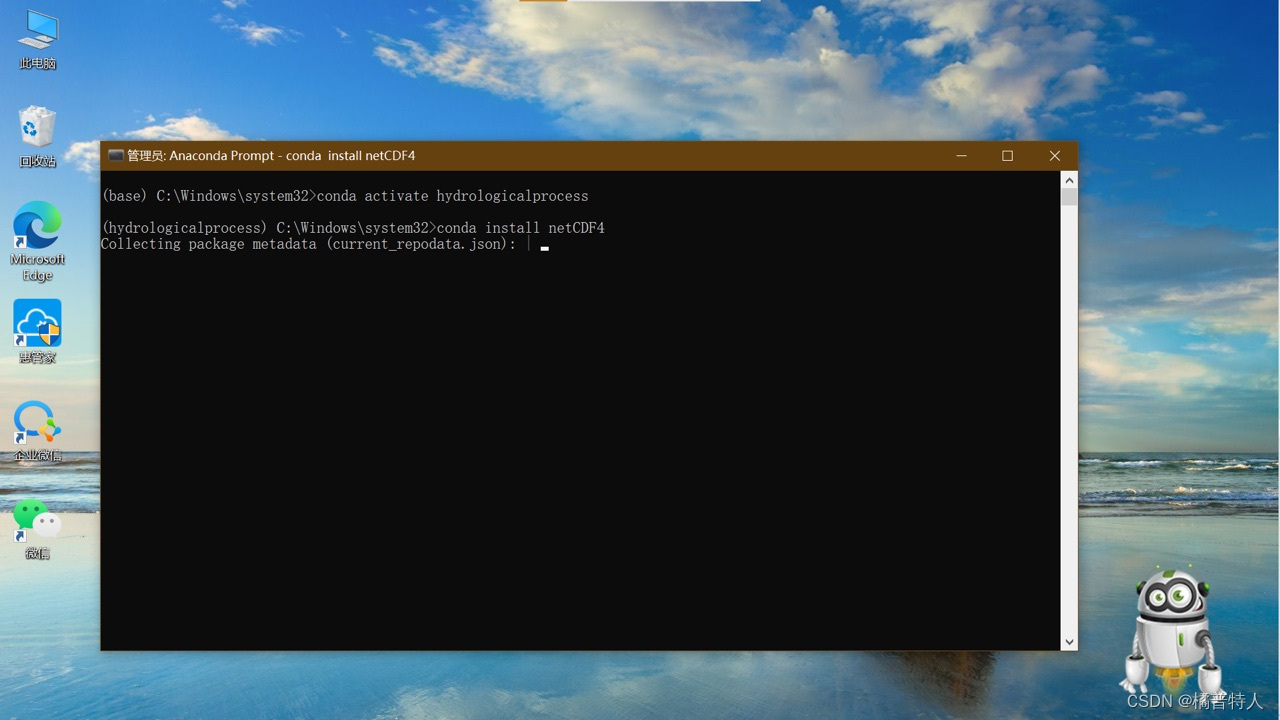
3)下载netCDF4库:
输入:conda install netCDF4
等待至成功下载,如果要点y/n就点y。
2.用Anaconda的jupyter来处理nc数据(一开始设定了虚拟环境的要记得跳转到虚拟环境)
1)首先将netCDF4库导入jupyter,还要导入其他一些库,如pandas,numpy,matplotlib。
(如果显示没有这些库的话,按上述安装netCDF4库的步骤安装pandas,numpy,matplotlib即可)

2)然后导入nc文件的路径,再用netCDF4的Dataset的功能读取数据
如图所示:上面的file1,file2,file3,file4是创建文件路径,即语法为:变量名=r'xxxxxxxx'(其中xxxxxx是指该nc文件存放的绝对路径)
下面的_1_2_3_4是用netCDF4库的Dataset的功能读取路径中的数据。语法为:变量名=nc.Dataset(上面创建的文件路径)
当然,你也可以合起来写,变量名=nc.Dataset(r'xxxxxxxxxxxxx')

看看是否读取到了数据:(像下面这样就是读取成功)
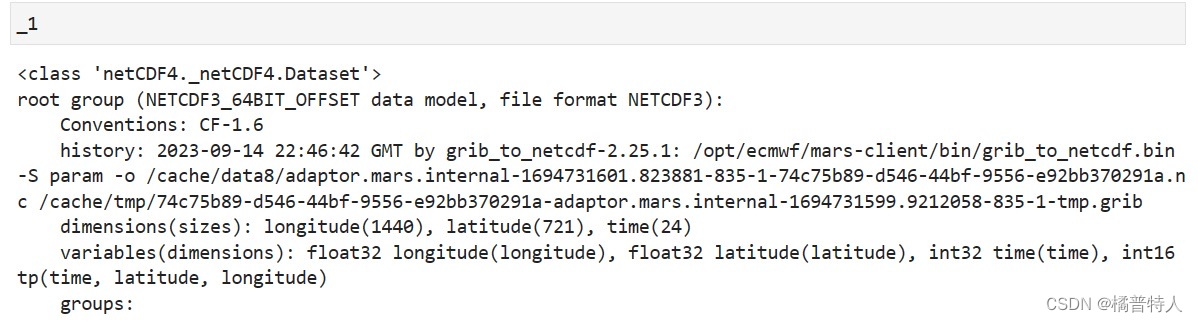
3)具体数值的提取。
由上图可知:_1数据里面有四个变量,(在上图variables那一行,后面跟着longitude,latitude,time,tp四个变量)
其中:longitude(longitude),latitude(latitude),time(time)都是一维数据,tp是三维数据(time,latitude,longitude)。
那如何提取这些数据的数值呢
一维数据的提取
由于笔者不太熟练,所以一般是一步一步来的
①查看文件的大体情况。
语法:变量名['xxxx'] 其中xxxx是上面看见的variables的名称,例如此处以longitude为例:
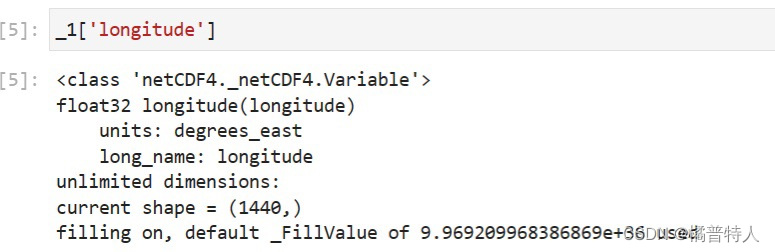
看倒数第二行的current shape可以看出它是个一维数据,并且有1440个数据。
②查看文件的具体数值:用切片的方法将其一一列举。
语法为:变量名['xxxxx'][:] 就是在①的基础上加上[:]
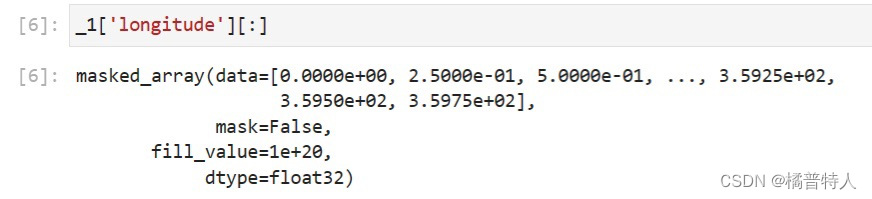
③提取文件的数据。
语法为:变量名['xxxxx'][:].data 就是在②的基础上加上.data
虽然②步已经显示出来了data数据,但是却没办法对其进行算术运算。
在②中可以看到该文件的数字数据都存储在data中(②里显示data=[。。。。。]),所以我们直接对它进行提取

多维数据的提取
步骤与上述一维数据的提取一样,只不过②中切片变成了多维
例如对三维数据'tp'进行提取(tp数据由time,latitude,longitude构成),语法为:变量名['tp'][:,:,:].data


提取出来数据后之后的的处理数据就按python平常的pandas,numpy处理即可。















 1068
1068











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











