








1. Redis简介
Redis(Remote Dictionary Server)是一个开源的内存数据库,它提供了一个高性能的键值(key-value)存储系统,常用于缓存、消息队列、会话存储等应用场景。
- 性能极高:Redis 以其极高的性能而著称,能够支持每秒数十万次的读写操作24。这使得Redis成为处理高并发请求的理想选择,尤其是在需要快速响应的场景中,如缓存、会话管理、排行榜等。
- 丰富的数据类型:Redis 不仅支持基本的键值存储,还提供了丰富的数据类型,包括字符串、列表、集合、哈希表、有序集合等。这些数据类型为开发者提供了灵活的数据操作能力.
- 原子性操作:Redis 的所有操作都是原子性的,这意味着操作要么完全执行,要么完全不执行。这种特性对于确保数据的一致性和完整性至关重要,尤其是在高并发环境下处理事务时。
- 持久化:Redis 支持数据的持久化,可以将内存中的数据保存到磁盘中,以便在系统重启后恢复数据。这为 Redis 提供了数据安全性,确保数据不会因为系统故障而丢失。
- 单线程模型:尽管 Redis 是单线程的,但它通过高效的事件驱动模型(epoll)来处理并发请求,确保了高性能和低延迟。单线程模型也简化了并发控制的复杂性。
- 主从复制:Redis 支持主从复制,可以通过从节点来备份数据或分担读请求,提高数据的可用性和系统的伸缩性。
- 跨平台兼容性:Redis 可以在多种操作系统上运行,包括 Linux、macOS 和 Windows,这使得它能够在不同的技术栈中灵活部署。
相较于关系型数据库(MySQL)而言,由于Redis是在内存中的,所以速度更快,但是空间更小。
既然是在内存中,那如果是单机的程序,直接定义变量不是更快吗? - -确实是的
Redis在分布式系统中,才是最优秀的方法。
在分布式中,由于进程间具有独立性,那么内存中的数据就需要采用进程间通信的方式传递,所以,Redis就收基于网络通信,把内存中的变量交给其它进程/主机的
那什么是分布式呢?
2. 了解分布式
- 单机架构
只有一台服务器,这台服务器负责所有的工作
初期,我们需要利用我们精⼲的技术团队,快速将业务系统投入市场进行检验,并且可以迅速响应变化要求。但好在前期用户访问量很少,没有对我们的性能、安全等提出很高的要求,而且系统架构简单,⽆需专业的运维团队,所以选择单机架构是合适的。
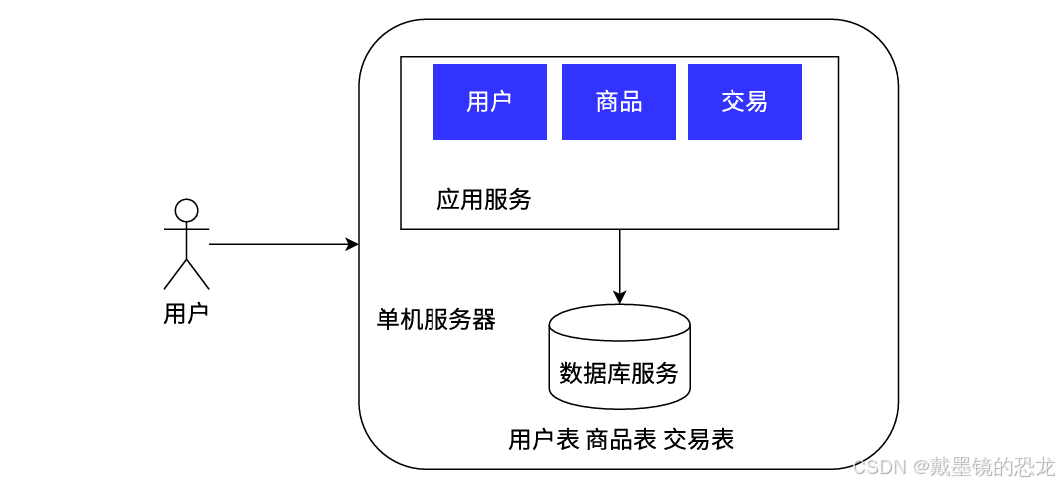
- 应用数据分离架构
随着系统的上线,我们不出意外地获得了成功。市场上出现了⼀批忠实于我们的用户,使得系统的访问量逐步上升,逐渐逼近了硬件资源(CPU、内存…)的极限,同时团队也在此期间积累了对业务流程的⼀批经验。
⾯对当前的性能压⼒,我们需要未⾬绸缪去进⾏系统重构、架构挑战,以提升系统的承载能力。但由于预算仍然很紧张,我们选择了将应⽤和数据分离的做法,可以最⼩代价的提升系统的承载能⼒。
一旦引入多台主机了,那么系统就可以称为“分布式系统”了(引入是万不得已的方法)
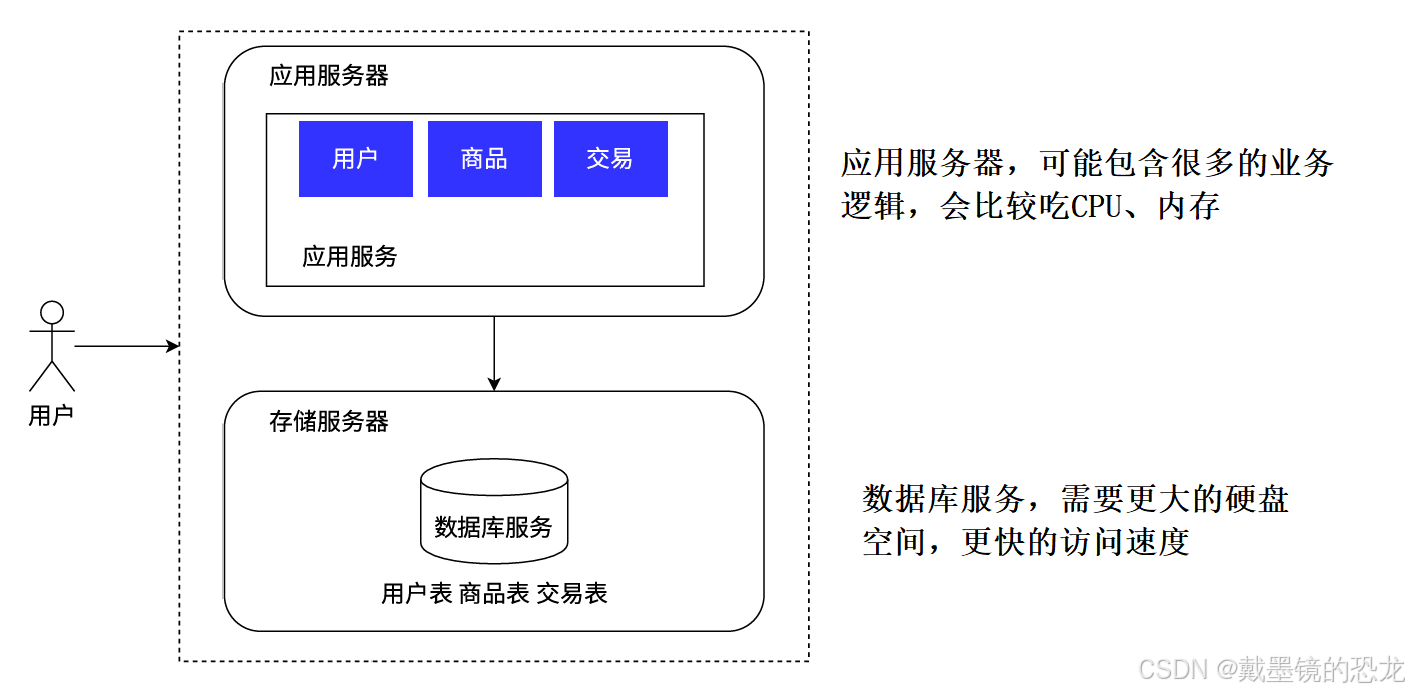
- 应用服务集群架构
我们的系统受到了用户的欢迎,并且出现了爆款,单台应⽤服务器已经⽆法满⾜需求了。我们的一台应⽤服务器首先遇到了瓶颈,摆在我们技术团队⾯前的有两种⽅案,⼤家针对⽅案的优劣展⽰了热烈的讨论:
-
垂直扩展(开源):通过购买性能更优、价格更⾼的应用服务器来应对更多的流量。这种⽅案的优势在于完全不需要对系统软件做任何的调整;但劣势也很明显:硬件性能和价格的增⻓关系是⾮线性的,意味着选择性能2倍的硬件可能需要花费超过4倍的价格,其次硬件性能提升是有明显上限的。
-
水平扩展(节流):通过调整软件架构,增加应⽤层硬件,将用户流量分担到不同的应⽤层服务器上,来提升系统的承载能⼒。这种⽅案的优势在于成本相对较低,并且提升的上限空间也很⼤。但劣势是带给系统更多的复杂性,需要技术团队有更丰富的经验。
经过团队的学习、调研和讨论,最终选择了⽔平扩展的⽅案,来解决该问题,但这需要引⼊⼀个新的组件⸺负载均衡:为了解决用户流量向哪台应⽤服务器分发的问题,需要⼀个专⻔的系统组件做流量分发。
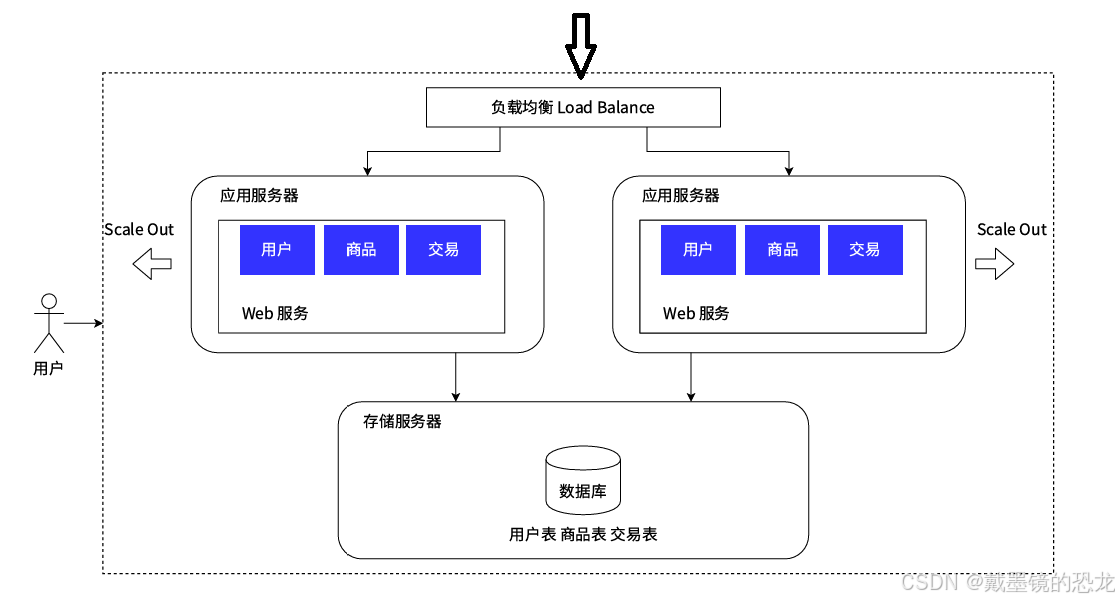
- 读写分离/主从分离架构
上面我们提到,我们把用户的请求通过负载均衡分发到不同的应⽤服务器之后,可以并⾏处理了,并且可以随着业务的增⻓,可以动态扩张服务器的数量来缓解压⼒。但是现在的架构⾥,⽆论扩展多少台服务器,这些请求最终都会从数据库读写数据,到⼀定程度之后,数据的压⼒称为系统承载能⼒的瓶颈点。
我们可以像扩展应⽤服务器⼀样扩展数据库服务器么?答案是否定的,因为数据库服务有其特殊性:如果将数据分散到各台服务器之后,数据的⼀致性将无法得到保障。
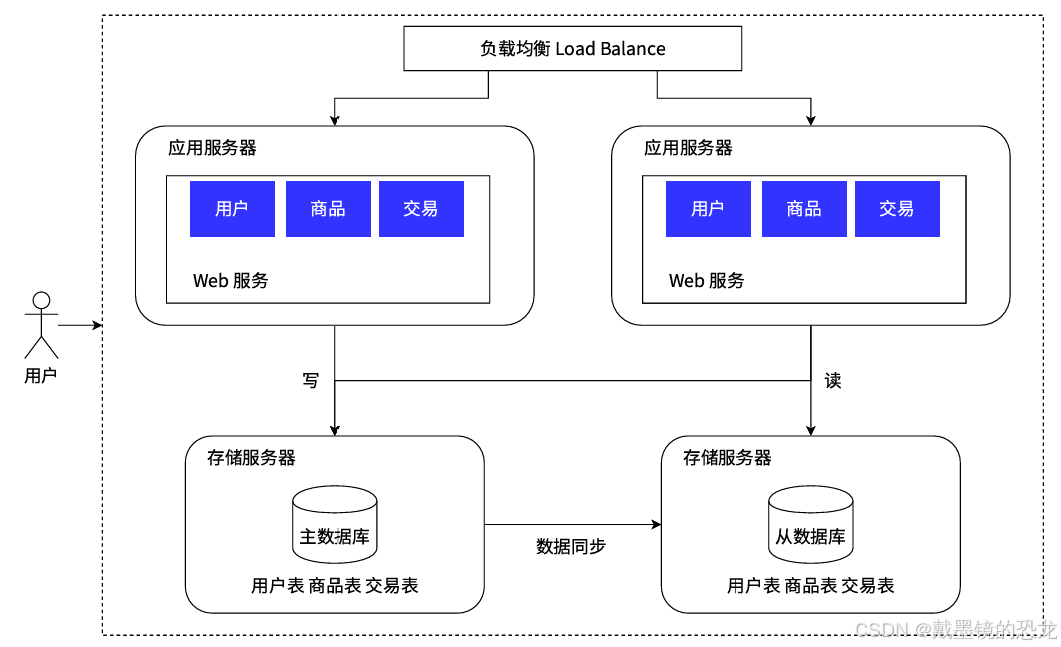
采⽤的解决办法是这样的,保留⼀个主要的数据库作为写⼊数据库,其他的数据库作为从属数据库。从库的所有数据全部来⾃主库的数据,经过同步后,从库可以维护着与主库⼀致的数据。然后为了分担数据库的压⼒,我们可以将写数据请求全部交给主库处理,但读请求分散到各个从库中。
- 引⼊缓存⸺冷热分离架构
随着访问量继续增加,发现业务中⼀些数据的读取频率远⼤于其他数据的读取频率。我们把这部分数据称为热点数据,与之相对应的是冷数据。
针对热数据,为了提升其读取的响应时间,可以增加本地缓存,并在外部增加分布式缓存,缓存热⻔商品信息或热⻔商品的html页面等。通过缓存能把绝⼤多数请求在读写数据库前拦截掉,大大降低数据库压⼒。其中涉及的技术包括:使用memcached作为本地缓存,使⽤Redis作为分布式缓存,还会涉及缓存⼀致性、缓存穿透/击穿、缓存雪崩、热点数据集中失效等问题。
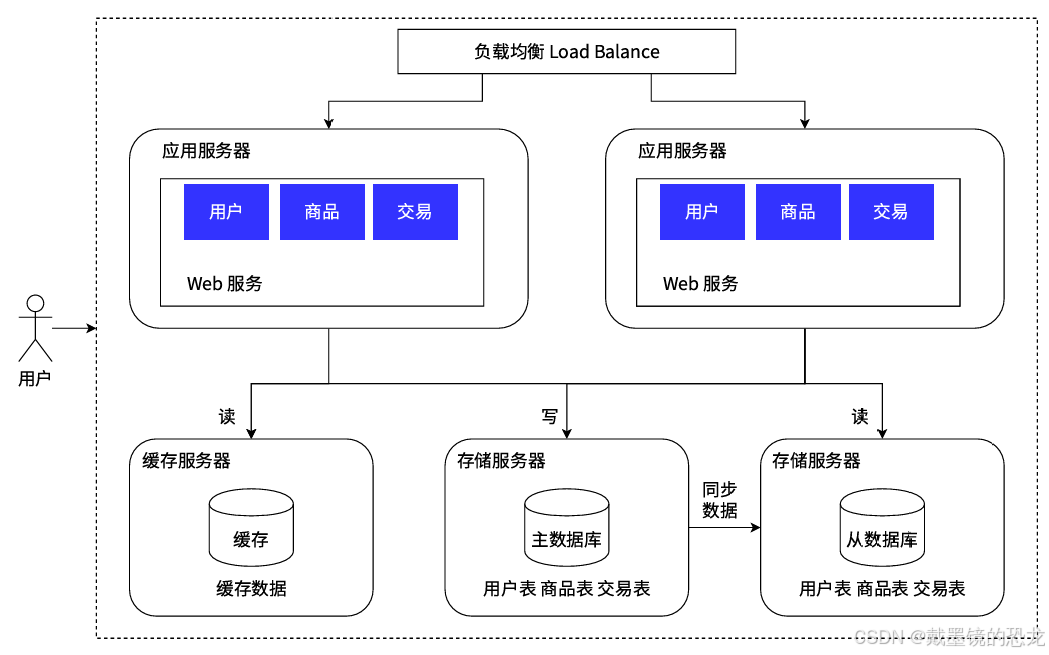
- 垂直分库
随着业务的数据量增大,大量的数据存储在同⼀个库中已经显得有些力不从心了,所以可以按照业务,将数据分别存储。
一台存储服务器存不下了,那就引入多台。如果一个表太大,也可以对表进行拆分。(分库分表)
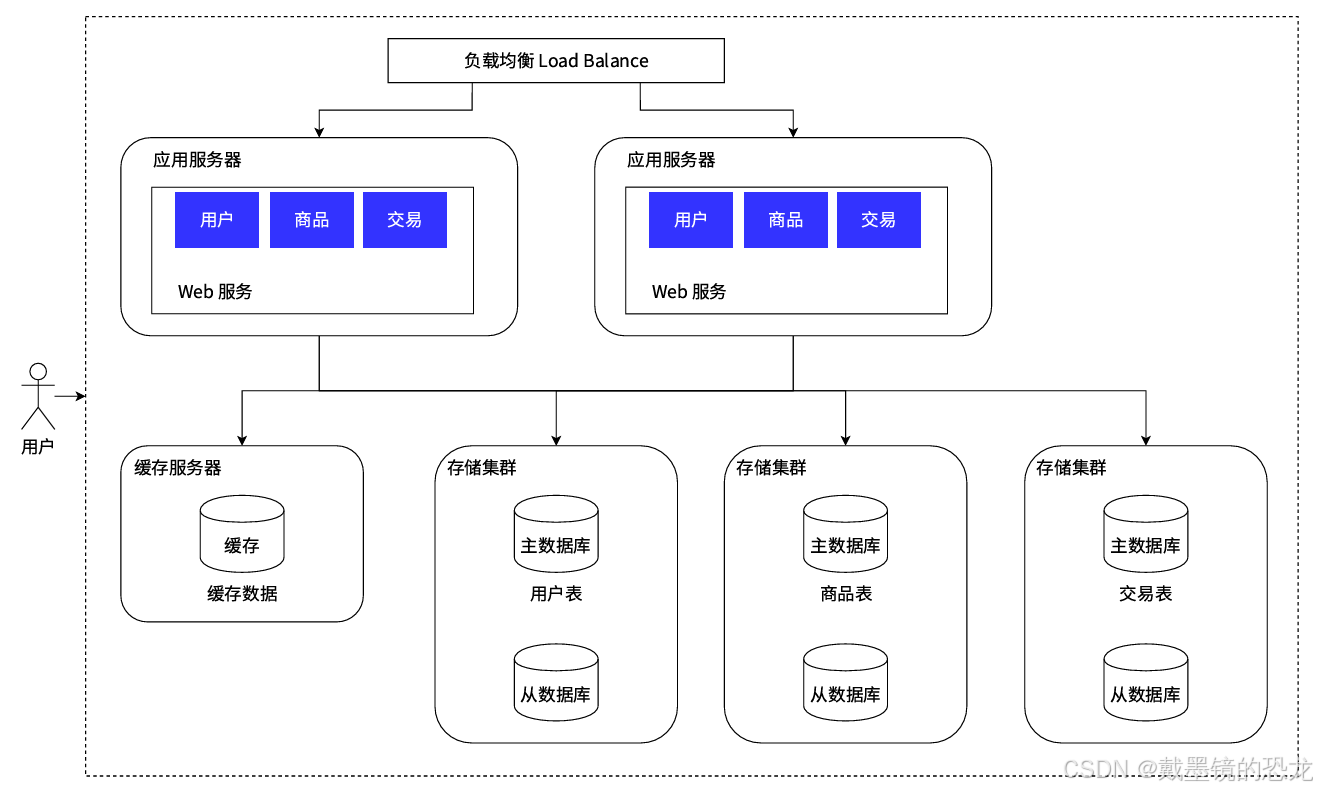
- 业务拆分⸺微服务
随着人员增加,业务发展,我们将业务分给不同的开发团队去维护(需要更多的人维护),每个团队独立实现自己的微服务,然后互相之间对数据的直接访问进行隔离,可以利用Gateway、消息总线等技术,实现相互之间的调用关联。甚⾄可以把⼀些类似用户管理、安全管理、数据采集等业务提成公共服务。
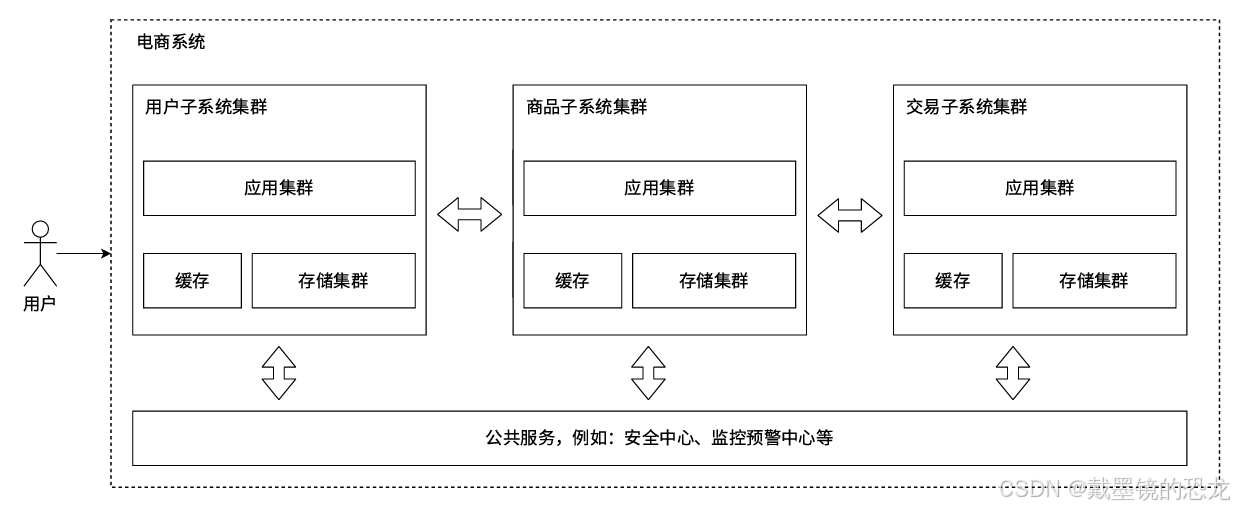
微服务的劣势:
- 系统的性能下降:拆出来更多的服务,多个功能之间要依赖网络通信(慢)。要想保证性能不下降太多,只能引入更多的硬件资源
- 系统复杂度提高,可用性受到影响
微服务的优势:
- 解决了人的问题
- 更方便功能的复用
- 不同的服务,可以进行不同的部署
3. Redis的特性
Redis 与其他 key-value 存储系统的主要区别在于其提供了丰富的数据类型、高性能的读写能力、原子性操作、持久化机制、以及丰富的特性集。
以下是 Redis 的一些独特之处:
- Redis主要通过“键值对”的方式在内存中存储组织数据的,是“非关系型数据库”。
- 丰富的数据类型:Redis 不仅仅支持简单的 key-value 类型的数据,还提供了 list、set、zset、hash 等数据结构的存储。这些数据类型可以更好地满足特定的业务需求,使得 Redis 可以用于更广泛的应用场景。
- 高性能的读写能力:Redis 能读的速度是 110000次/s,写的速度是 81000次/s。这种高性能主要得益于 Redis 将数据存储在内存中,从而显著提高了数据的访问速度。
- 原子性操作:Redis 的所有操作都是原子性的,这意味着操作要么完全执行,要么完全不执行。这种特性对于确保数据的一致性和完整性非常重要。
- 持久化机制:Redis 支持数据的持久化,可以将内存中的数据保存在磁盘中,以便在系统重启后能够再次加载使用。这为 Redis 提供了数据安全性,确保数据不会因为系统故障而丢失。
- 丰富的特性集:Redis 还支持 publish/subscribe(发布/订阅)模式、通知、key 过期等高级特性。这些特性使得 Redis 可以用于消息队列、实时数据分析等复杂的应用场景。
- 主从复制和高可用性:Redis 支持 master-slave 模式的数据备份,提供了数据的备份和主从复制功能,增强了数据的可用性和容错性。
- 支持 Lua 脚本:Redis 支持使用 Lua 脚本来编写复杂的操作,这些脚本可以在服务器端执行,提供了更多的灵活性和强大的功能。
- 单线程模型:尽管 Redis 是单线程的,但它通过高效的事件驱动模型来处理并发请求,确保了高性能和低延迟。
- 可拓展:Redis提供了一组API,支持在原有的功能上进行拓展。
- 支持集群(水平拓展):类似于上面讲的分库分表(引入多个主机,部署多个Redis节点,每个节点存储一部分数据)
- 速度快
- 数据存储在内存中
- Redis的核心功能都是比较简单的操作内存中的数据结构
- Redis使用了多路复用的方式(epoll)
- 使用的是单线程模型(减少了竞争开销)
4. Redis的安装与使用
4.1 安装
在 Ubuntu 系统安装 Redis 可以使用以下命令:
sudo apt update
sudo apt install redis
启动 Redis
redis-server
Redis安装好后,默认就会启动

Redis默认绑定127.0.0.1,修改Redis的绑定IP,在etc/redis目录中的redis.conf文件中
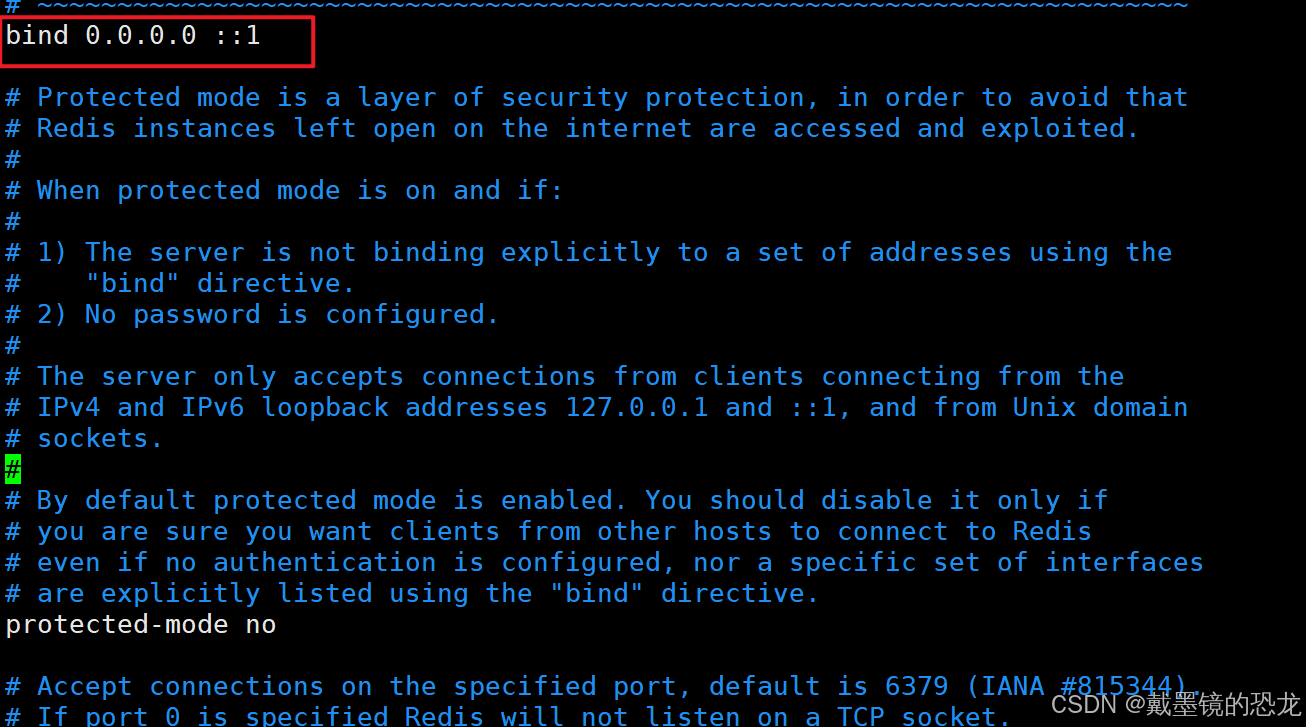
查看 redis 是否启动?
redis-cli
以上命令将打开以下终端:
redis 127.0.0.1:6379>
127.0.0.1 是本机 IP ,6379 是 redis 服务端口。现在我们输入 PING 命令。
redis 127.0.0.1:6379> ping
PONG
以上说明我们已经成功安装了redis。
重启redis服务器
service redis-server restart
查看redis的状态
service redis-server status
4.2 redis基本常用命令
redis也是一个C/S结构的程序,我们使用的是redis的客户端.
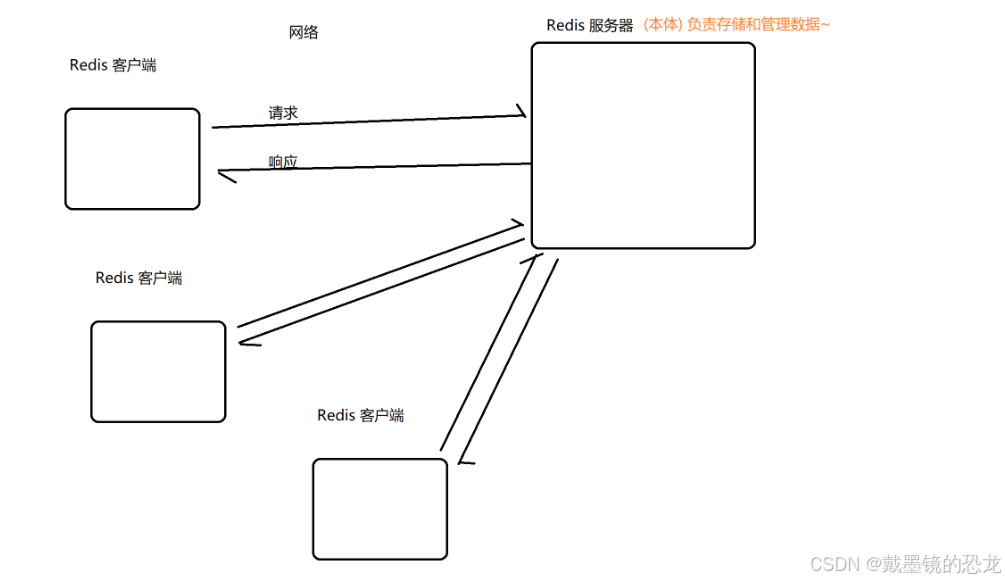
redis是不区分大小写的,并且是按照键值对存储数据的
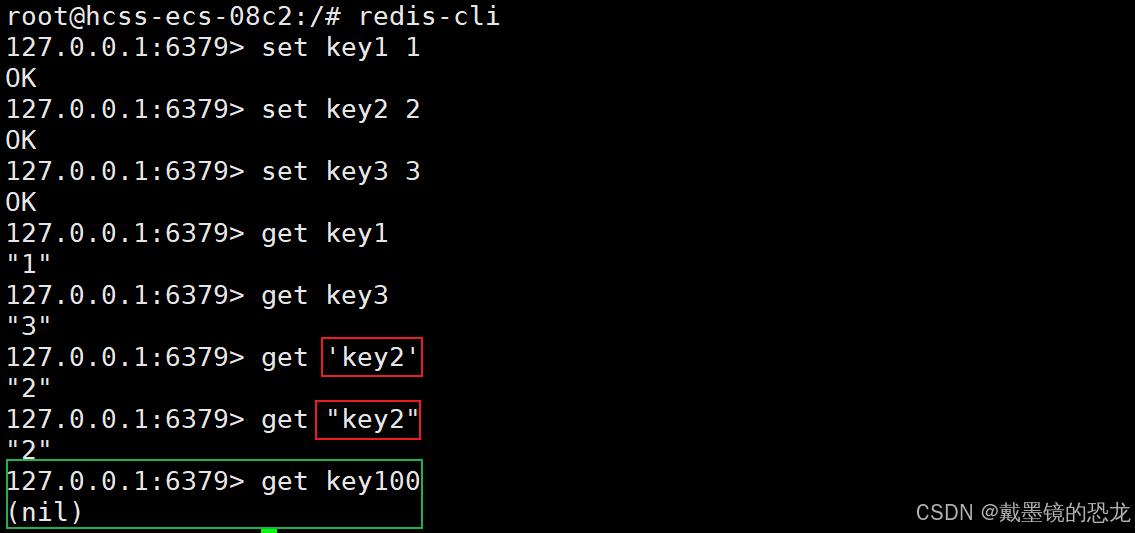
两个核心命令:
- get:根据key获取value,不存在则返回
nil - set:把key与value设置进去
其中,key与value都是字符串,但是使用的时候并不需要加引号(加上也可以)
Redis常用全局命令
首先我们要直到,redis支持很多的数据结构,也就是说,redis的key是字符串,但是value可以有很多类型(字符串、哈希、列表、集合等),操作这些数据结构就会有不同的命令。
redis的全局命令,能够搭配任意数据结构使用:
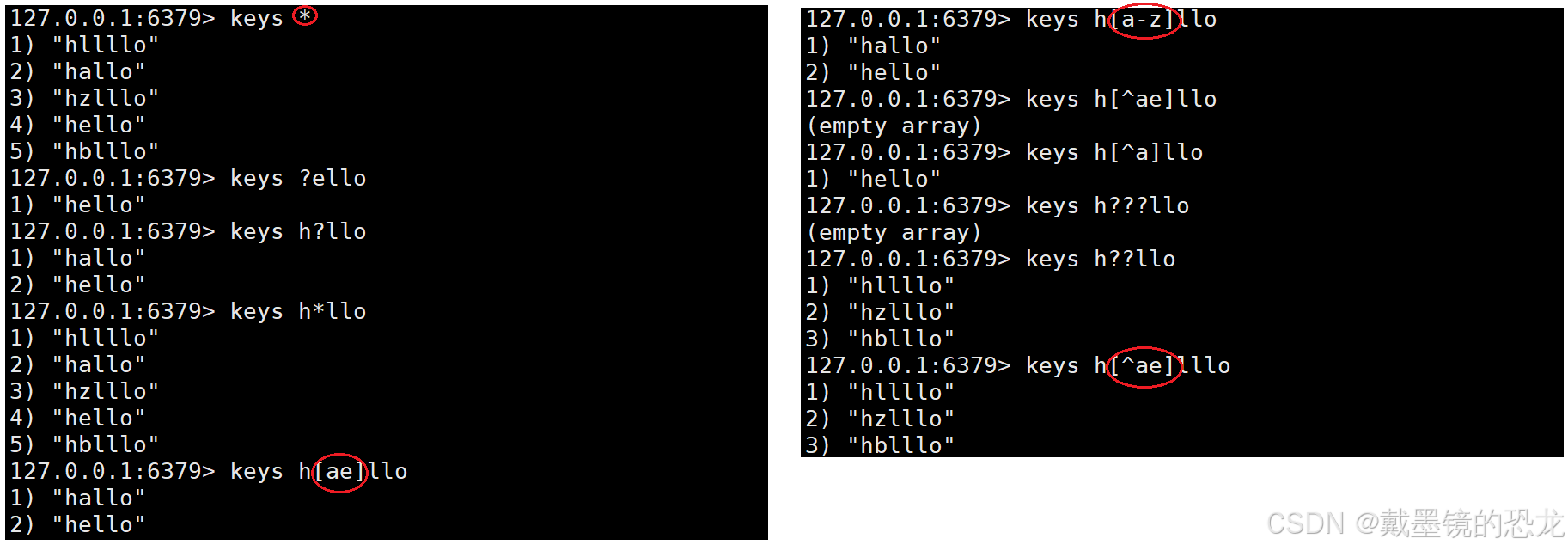
- keys:查询当前服务器所有满足样式(pattern)的 key
它也支持一些通配
- 任意多个字符:
*- 任意一个字符:
?- 指定的任意一个字符:
[ ]- 指定的一端字符区间:
[a-b]- 排除指定的字符:
[^e]
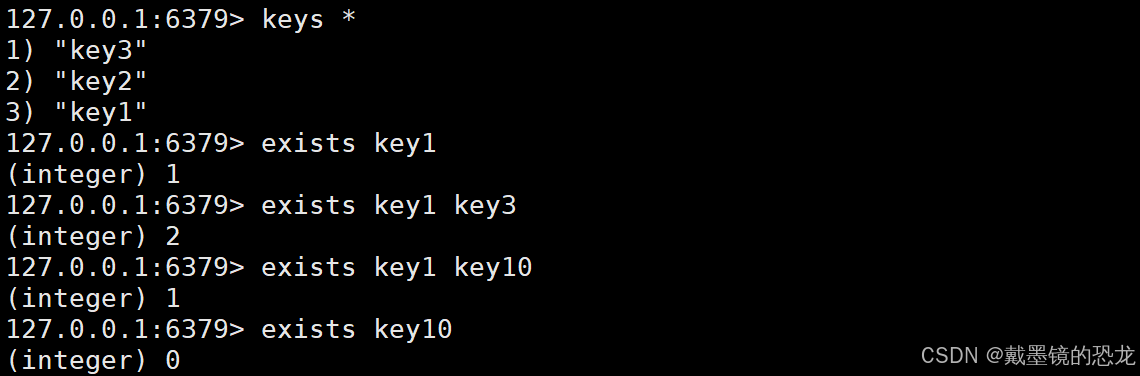
- exists:判断key是否存在(多个key使用空格分开)
返回所存在key的个数
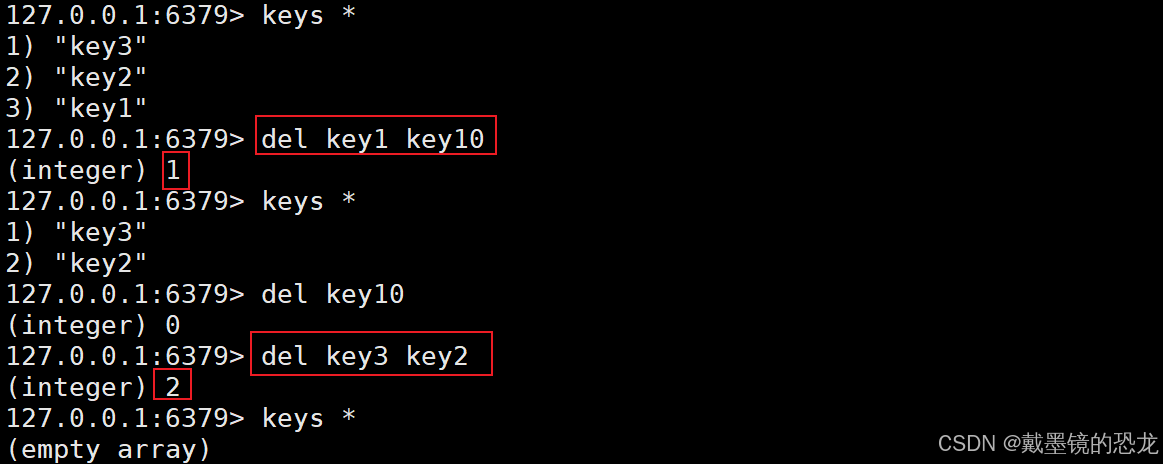
- del:删除指定的key
- expire:给key设置过期时间(单位是秒),超出时间,key自动删除。(
pexpire的单位是毫秒)
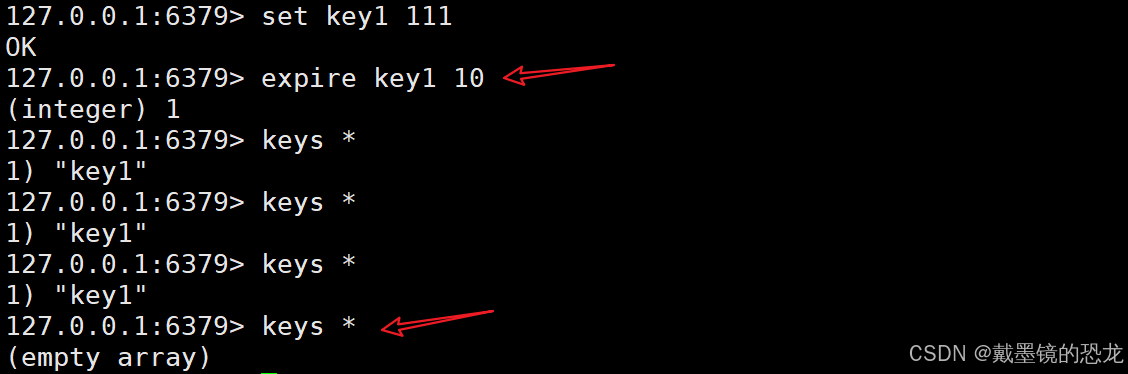
- ttl:查看key的过期时间 ,单位是秒(
pttl的单位是毫秒)

在 Redis 2.6 或更早版本中,如果key不存在,或者key存在但没有关联的过期,则返回-1
该命令从 Redis 2.8 开始,如果发生错误,则返回值会发生变化:
- 如果key不存在,则返回该命令。-2
- 如果key存在但没有关联的 expire,则返回该命令。-1
一个redis中存在很多的key,这些key中可能大部分都有过期时间,但是redis服务器怎么知道哪些key已经过期要删除了,哪些key没有过期呢?(经典面试题)
- 定期删除:每次抽取一部分进行验证过期时间,要保证抽取检查的过程足够快(因为redis的单线程的)
- 惰性删除:假设一个key已经过期了,但是还没有删除它,如果后面还有访问到该key,检测到key过期了,此时redis再将它删除,同时返回一个nil。
上述两种策略的效果一般,会有key残留;因此redis还提供了一系列的内存淘汰策略。
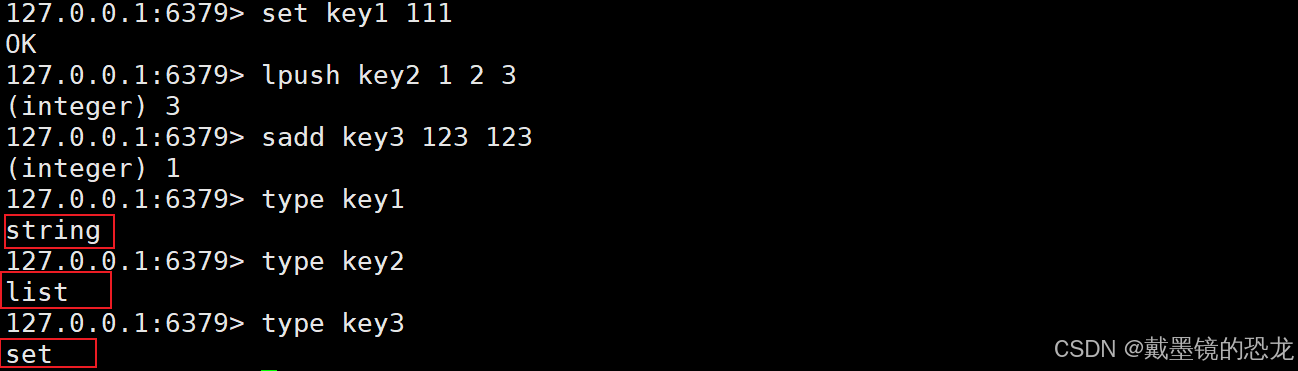
- type:返回key对一个你value的类型


















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









